
自适应伪随机序列混合网络隐蔽通道构建方法
2021-09-07 00:48:08戴睿,嵩天
计算机工程与应用 2021年17期
戴 睿,嵩 天
北京理工大学 计算机学院,北京100081
隐蔽通道利用通信双方所共用或已知的合法交互方式经过再次约定形成隐蔽性强的额外通信渠道,进而实现在合法通道上额外加载传输信息的目的。与一般通道或密码通道不同,隐蔽通道利用通道行为再造获得高隐蔽性和高安全性。
以网络协议为基础构建的隐蔽通道称为网络隐蔽通道。网络隐蔽通道可通过控制键盘中断时延窃取口令等隐私信息,还可以作为分布拒绝式服务攻击和网络蠕虫的数据回传工具,也用作网络攻击的协调指挥工具;相反,网络隐蔽通道也能够满足数据传输隐私、跟踪加密流量、跟踪VOIP呼叫等正当需求,构成有正面价值的积极应用[1-2]。在军事和情报领域,网络隐蔽通道更能够发挥关键作用。
现有的网络隐蔽通道根据通信双方使用的共享资源类型不同分为存储型、时间型、序列型和混合型4类。存储型将隐蔽信息直接写入协议具体字段,时间型通过改变协议的时间特征传输隐蔽信息,序列型使用协议的排列组合方式传输信息,而混合型则使用多种不同的通道传输隐蔽信息。
传统隐蔽通道固定使用协议的某种特征,方法单一,如直接将隐蔽信息写入TCP协议的字段中[3],或者使用相对固定的数据包延迟间隔[4]以及固定的字典序列[5],针对该类隐蔽通道,只要知道其共享资源位置,即可使用简单的统计方法检测,隐蔽性弱。因此,使用更为随机化的存储位置,如使用SSL协议的随机值字段[6],加入编码方法,如使用喷泉码[7]和格雷码[8],模仿合法流量的统计分布[9-10]等方法成为目前隐蔽通道设计关键要素,但是固定的共享资源、编码方法和使用模式仍会对合法流量产生较大的影响,从而可以被更高维度的检测方法,例如机器学习的方法检测。Anjan[11]、邵婧婕[12]、Xu[13]等使用多种共享资源构建混合隐蔽通道,但是资源种类单一,混合方法固定,无法自适应网络流量的变化且通用性不足。
因此,本文提出一种新的混合使用多种隐蔽通道的通用方法,可以将存储型、时间型、序列型隐蔽通道等多种隐蔽通道同时混合使用,有效分散隐蔽信息加入对合法流量的影响,且可通过改变隐蔽通道库中通道实现模块化扩展,同时通过量化不同隐蔽通道对合法流量的影响强弱,实时生成针对当前合法流量的随机通道使用序列,将隐蔽通道对合法流量的整体影响降至最优,有效提高混合后通道的隐蔽性;并将自定义性能指标引入隐蔽通道设计,根据不同的带宽要求,该混合隐蔽通道构建方法可以自主改变通道的混合使用方法,在当前带宽指标的前提下,以对合法流量影响最小的代价传输隐蔽信息,进一步提高通道隐蔽性。
本文根据该方法在实际网络环境中构建了完整的通信系统,确定通信双方的同步方法,规定理论带宽和实际带宽的计算方法,并使用支持向量机算法对其隐蔽性进行检测,完成对该型隐蔽通道性能的完整评估,实验证明,该通道隐蔽性强,可扩展,自适应,具有较强的实用价值。
1 方法框架
1.1 基本概念
本文提出的自适应伪随机序列混合隐蔽通道是利用网络流量本身所具有的随机性对隐蔽通道进行的再次隐蔽。
基于对网络流量的随机性、模式性和时变性的合理假设,提出本文方法。如图1所示,ALICE和BOB为进行隐蔽通信的双方,不同色块代表不同的隐蔽通道。首先,通过混合使用多种隐蔽通道,将单一隐蔽通道对网络流量的影响降低;其次,通过对窗口内网络流量的实时分析,量化各隐蔽通道所使用共享资源的随机性和分布性,确定该窗口内各类隐蔽通道的使用数量,并生成符合分布的随机使用序列;对于随机性强,且对共享资源分布性改变少的通道较多使用,随机性弱,且对共享资源模式改变大的通道少使用或不使用,可以有效利用网络流量本身的随机性,抹去隐蔽通道的使用痕迹,实现对隐蔽通道的再次隐藏。

图1 自适应伪随机序列混合隐蔽通道基本概念Fig.1 Basic concept of self-adaptive pseudo-random sequence hybrid covert channel
1.2 流程框架
如图2所示,该方法由隐蔽通道库、流量过滤、流量分析、序列生成、流量发送5个主要模块组成。隐蔽通道库由该方法所使用的隐蔽通道的单一使用方法组成,每一种隐蔽通道都具有唯一的使用编号,本文方法隐蔽通道库中有8种隐蔽通道,涵盖隐蔽通道的所有类型,具有一定的代表性。流量过滤模块主要截获过滤符合要求的协议流量,划分窗口,并获取窗口数据包中隐蔽通道库使用的各类共享资源的特征值。流量分析模块,根据共享资源的特征值量化计算出使用该资源通道的隐蔽性强弱。序列生成模块则根据各通道隐蔽性值,以及所规定的带宽性能要求生成混合隐蔽通道使用序列。流量发送模块根据生成的使用序列,对应库中隐蔽通道的使用编号,将隐蔽信息写入窗口中后续数据包中并发送。

图2 自适应伪随机序列混合隐蔽通道模型Fig.2 Self-adaptive pseudo-random sequence hybrid covert channel model
对连续的窗口数据包使用上述五个模块进行处理,则可以动态地适应网络流量的变化,使得隐蔽信息在不同时间、不同数据包以不同模式跳跃性存在,可以有效地提高隐蔽通道的隐蔽性。
2 自适应伪随机序列混合算法模型
2.1 隐蔽通道库
隐蔽通道库可以根据不同的使用场景和网络协议进行实时的更换、增加或减少,通过不同的组合,使最终生成的隐蔽通道性能在整体上达到预先设定的目标参数。因此,通过本文方法所获得隐蔽通道可自定义,可扩展,可升级。
该库中的隐蔽通道方法必须包含该通道的共享资源点位,数据输入及编码方法,以及数据包的写入和发送方法。本文选择TCP/IP协议栈上的8条隐蔽通道构建隐蔽通道库,涵盖存储、时间和序列型。
(1)存储型:针对TCP/IP协议栈,沈瑶[10]指出,TCP/IP协议中有10个字段是常用的隐藏载体,分别为服务类型、标识、标志位、片偏移、生存时间、初始序列号、发送序号、确认序号、TCP控制位、紧急指针。结合对合法流量的分析,发现IP协议的长度字段和TCP协议的端口字段都具有一定的随机性,可用来进行隐蔽通道的传输。
综上,本文选取IP协议的标识(IPID)16 bit,长度(IPLEN)8 bit(总长16 bit,仅使用8 bit),TCP协议的发送序号(TCPSEQ)32 bit,确认序号(TCPACK)32 bit,源端口号(TCPSPORT)16 bit,目的端口号(TCPDPORT)16 bit作为隐蔽信息的写入字段,构成6种隐蔽通道。
本文采用最基础的隐蔽通道写入方法,即不进行任何的编码和映射,直接将相应比特的隐蔽信息写入所选取的字段位置,该写入方法对合法流量影响最大,可更有效地观察到本文方法对隐蔽通道的抹平效果。
(2)时间型:使用数据包间隔延迟(IPD)作为共享资源,编码方法如下:

其中,ipdi为第i个数据包与第i-1个数据包的时间间隔,si为需要传送的第i位隐蔽信息比特,d为人为设定的时间,根据网络环境确定,解码方法为:

其中,ipdri为接收到的第i个数据包间隔。
(3)序列型:以4 bit信息为一组,将隐蔽信息映射到连续4个TCP数据包发送序号的大小排序中,映射方法如表1所示,其中1234代表TCP发送序号按照从小到大的序列(SQUENCE)进行发送。

表1 隐蔽信息与发送序列映射表Table 1 Covert information and transmission sequence mapping table
最终构建的隐蔽通道库如表2所示。

表2 隐蔽通道库Table 2 Covert channel library
2.2 流量分析
通道库中各类隐蔽通道所使用的共享资源随网络流量的动态变化而变化,不同共享资源的隐蔽性也不相同,所能承载的隐蔽通道数量也不同,因此需要对共享资源的隐蔽性进行实时量化计算,本文通过流量的熵值[14]和分布两个维度进行综合衡量。
将通过流量过滤模块收集的总长度为L的合法流量按照长度l划分为窗口流量:

在窗口流量si中,可认为网络流量具有一定的稳定性,共享资源的各项特征较为稳定,因此可以通过对窗口中一部分的流量分析结果来近似整体窗口流量的隐蔽特征,本文使用窗口流量中的前m长度的流量作为分析流量,剩余l-m长度的流量作为隐蔽信息的写入流量。

其中,C为隐蔽性计算函数,(c1,c2,…,ca)为隐蔽通道库中所对应序号的共享资源的隐蔽性值,a为隐蔽通道库的容量。
计算分析流量的隐蔽性值的基本思想是通过依次仅模拟通道库中的一种方法向分析流量中写入随机的隐蔽信息,再观察写入后的流量与合法流量的差异程度来衡量其隐蔽性。
分析流量中每种共享资源的特征值为(x1,x2,…,xm),对于存储型和时间型的隐蔽通道可直接使用共享资源的原始值(z1,z2,…,zm),对于序列型的隐蔽通道,使用共享资源前后的差值作为特征值,即:

记按照序列号为p的隐蔽通道方法写入随机隐蔽信息的分析流量为s'(m),p,其特征为(x'1,x'2,…,x'm)。
(1)熵值差异率计算:

其中,evrp(entropy variation rate)为序列号为p的隐蔽通道加载后流量与原分析流量的熵值差异率,差异率越小,该隐蔽通道对合法流量的随机性影响越小。
(2)分布差异率计算:

其中,dvrp(distribute variation rate)为序列号为p的隐蔽通道加载后流量与原分析流量的分布差异率,D为分布函数,分布差异率越小,该隐蔽通道对合法流量的分布影响越小,其基本思想来源于K-S检验[15]。
综合熵值差异率和分布差异率两个维度对该通道的隐蔽性进行量化:

其中,k为[0,1]之间的参数,用来自定义隐蔽性计算中对熵值和分布的偏重度,cp为序号为p的隐蔽通道在该分析流量中的隐蔽性值,代入式(4),得到写入流量的隐蔽性值,cp值越大,该通道隐蔽性越强。
2.3 序列生成
自适应伪随机序列混合算法根据生成的使用序列,决定当前使用的隐蔽通道种类,使用序列的特性,决定最终生成的混合通道的隐蔽性、带宽等整体特性。
伪随机使用序列生成的基本思想是根据当前写入流量的隐蔽性值,即通道对合法流量的影响强弱,来决定各通道使用数量的多少。同时,使用序列必须具有随机性来减少固定模式的数量,降低检测率,且满足一定的带宽要求,具体方法如下:
目前,序号为p的隐蔽通道CCp可以用3个维度的特征值来描述:

其中,bp为通道带宽,即单次使用该通道所能携带的隐蔽信息数量,cp为2.2节的隐蔽性计算结果,up为使用该通道所需的共享资源个数,对于本文的存储型隐蔽通道和时间型隐蔽通道,单次使用的共享资源个数均为1,而对于序列型隐蔽通道,单次使用的共享资源个数为4。
写入流量的长度为l-m,即为共享资源的总量为l-m个,设生成的随机序列中,每种隐蔽通道所使用的个数为(y1,y2,…,ya),必须满足:

则可令:

此时使用的共享资源个数与写入流量相等,即所有的写入流量都进行隐蔽信息的传输,在当前分布函数的条件下,此时写入流量携带的隐蔽信息比特BW最大:

隐蔽通道首要考虑因素是其隐蔽性,相同情况下,通道携带的隐蔽信息越多,对合法流量的影响越大,在多数情况下,并不需要隐蔽通道始终达到其最大带宽,通过设置带宽上限,减少共享资源的使用,人为降低带宽,进一步降低通道存在对合法流量的影响。
此时CCp可以用4个维度的特征值来描述:

其中,yp定义为该通道最大的使用次数。问题可转化为:

其中,np为序号为p的通道的使用次数,式(15)为目标函数,即在带宽上限和满足分布要求的情况下,如何确定各条通道的分布使其对合法流量的影响最低。
该优化问题可使用动态规划算法求解,将相同的隐蔽通道看成不同的通道,此时问题可看成个不同的隐蔽通道的使用问题:

列出状态转移方程:

其中,B(i,j)代表当前传输的隐蔽信息比特上限为j,前i个隐蔽通道所得的最优解,则有两种可能:
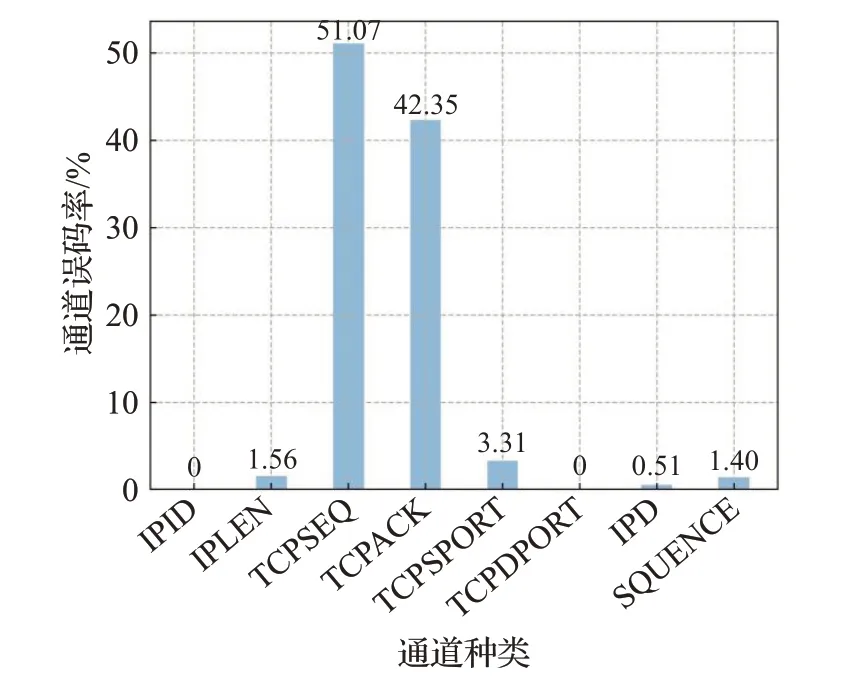
(1)信息比特数j比该通道的比特数小,j (2)信息比特数j比该通道的比特数大或相等,j≥bj,则可分为最优解含有第i个通道和不含有i个通道两种情况,取这两种情况的最大值即为最优解。 根据式(15)、(16)、(17)得各类隐蔽通道最终的使用数量情况: 其中,n0为传输原始流量的使用序号的个数,即默认发送原流量,不加载隐蔽信息。 根据使用数量结果,得到序列R的分布情况: 随机序列产生方法如下: (1)产生符合均匀分布的伪随机整数,满足r∈{0,1,2,…,a},再产生与之对应的同样符合均匀分布的伪随机数r'∈(0,1)。 (2)当r'≤P(r)时,则采纳r,否则,继续(1)。 由此得到最终的伪随机序列R,流量发送模块根据该序列从隐蔽通道库中选择相应序号的隐蔽通道进行信息写入并发送。 使用自适应伪随机序列混合隐蔽通道进行通信的双方必须共享或生成相同的伪随机序列、随机数种子及隐蔽通道库,接收方才可以根据该序列确定隐蔽信息的位置及其恢复方法。 图3展示了自适应伪随机序列混合隐蔽通道的通信流程图,通信双方的同步可以有以下两种方法: 图3 自适应伪随机序列混合隐蔽通道流程Fig.3 Self-adaptive pseudo-random sequence hybrid covert channel process (1)直接共享伪随机序列。即发送方在发送隐蔽流量前,直接通过其他安全渠道将本次窗口生成的伪随机序列发送给接收方,接收方直接可通过收到的隐蔽流量对照伪随机序列和隐蔽通道库来解码隐蔽信息。 (2)接收方实时计算。由于接收方也接收到了所有的窗口流量,在通信双方共享随机数发生器的种子和相应参数的前提下,可以使用发送方同样的方法恢复出随机序列。相比于方法(1),该方法预先共享的信息少,有利于提高通道的隐蔽性。 (1)理论带宽。计算平均单位长度的流量所携带的隐蔽信息的比特数,即本文方法中单个TCP数据包携带的隐蔽信息数量: (2)实际带宽。单位时间传送的隐蔽信息数量: 其中,t为数据发送时间,受网络环境、算法性能、计算机硬件影响较大。 本文使用基于协议行为的多维特征向量检测算法对生成的隐蔽通道进行检测,该方法使用支持向量机(SVM)算法,相比于传统的单一统计学检测方法,准确度更高。 该算法主要分为以下几个步骤: (1)数据标注与划分。以窗口大小为单位,收集一定量的合法流量和与之对应的隐蔽流量,并划分为训练集和测试集。 (2)特征预处理。针对不同隐蔽通道所使用的共享资源,按照式(5),生成中间数据集。 (3)特征提取。对不同的共享资源生成的中间数据集进行特征提取,生成如下形式的特征向量: 其中,Avg为中间数据集的均值,Var为方差,Ent为熵值,Lab为该特征向量的标签,即为合法流量还是隐蔽流量。 (4)SVM分类器。以高斯核作为核函数,使用获得的数据标签训练SVM分类器。 (5)测试。使用SVM分类器在测试集上进行测试,以分类的准确程度作为隐蔽通道隐蔽性的衡量标准。 本文在如图4所示的网络拓扑环境下进行数据传输实验。终端A与终端B位于北京同一个WIFI局域网内,服务器C选择位于上海的阿里云服务器。 图4 实验网络拓扑Fig.4 Experimental network topology 其中终端A为数据发送终端,进行流量分析,序列生成和数据写入与发送操作,终端B和云服务器C为数据接收终端,负责数据的接收和还原,基本配置与网络环境如表3,通过前期的网络测试,A到B和A到C网络质量均好,无丢包。 表3 终端配置参数表Table 3 Terminal configuration parameter list 测试流量选择终端A用户进行日常网络访问的TCP流量,总长度L为30 000个数据包,划分窗口长度l为300个数据包,分析流量长度m为100个数据包,时间型通道参数d选择为100 ms,待传输的隐蔽信息为预先产生的随机比特。 本实验主要考察方法所构成的隐蔽通道在测试流量下的带宽以及自适应性。 当偏重度k取0.5时,对100组窗口流量进行上述算法操作,记每组窗口流量不加带宽限制前,理论单个数据包所能携带隐蔽信息的最大值为理论最大带宽,序列生成后单个数据包所能携带的信息为理论序列带宽,以及此时系统单位时间传输的隐蔽信息数为实际带宽;并在对窗口流量增加每组窗口携带隐蔽信息为1 500 bit即单个数据包携带7.5 bit信息的限制条件下,记该通道的理论带宽为理论限制带宽和实际限制带宽,实验结果如图5上图所示。 图5 带宽自适应及流量复杂度Fig.5 Bandwidth self-adaptation and traffic complexity 可以观察到,随着窗口流量的变化,各组窗口的带宽也随之变化,反映了通道的自适应性。由于不携带信息的0序列通道引入,所以序列生成后的理论序列带宽始终小于理论最大带宽,但趋势相似。当引入带宽限制时,此时流量限制算法工作,隐蔽通道的理论限制带宽始终位于带宽限制线下,限制隐蔽信息写入,增加通道隐蔽性。 图5下图为根据窗口流量中目标IP数量确定的各窗口流量的复杂度,目标IP数量越多,终端与不同服务器的连接越多,可认为流量越复杂。可以观察到各组窗口的带宽趋势与流量的复杂度趋势高度一致,即越复杂的流量所能承载的带宽相对较高,这是由于高带宽的存储型通道受流量复杂度影响较大,而低带宽的时间型和序列型隐蔽通道受流量差异影响较小造成的。 图6展示了10组逐渐递增流量复杂度的窗口流量的带宽趋势图。流量复杂度与带宽前期呈正相关,但是当流量复杂度进一步增加后,相关性减弱,这是由于隐蔽通道的隐蔽性不仅与流量的复杂性相关,还与其共享资源的分布有关,流量复杂,但分布单一,也会影响该通道的带宽。 图6 流量复杂性对带宽影响Fig.6 Impact of traffic complexity on bandwidth 表4展示了将本文方法带宽与近期各类型的隐蔽通道带宽进行对比的结果(表中N、M均为通道参数)。SPSH-CC为本文提出自适应伪随机序列混合隐蔽通道,上标(1)为最大传输模式,(2)为限制传输模式。SSL-CC为杨皓云等[6]提出的利用SSL协议加密字段构建存储型隐蔽通道的方法。HYDPOI为Xu等[13]提出的在LTE-A协议上混合存储型和时间型隐蔽通道的方法。MSCTC为Archibald等[9]提出的一种拟合合法流量分布的时间型隐蔽通道。COCC为邵婧婕[12]提出的基于伪随机序列,混合多种时间型隐蔽通的方法。HBCC为沈瑶[10]基于频繁集项模仿合法HTTP流量的请求-流分布提出的序列型隐蔽通道。 表4 带宽对比Table 4 Bandwidth comparison 表4中本文方法数据为本算法作用于100组窗口流量的平均值,其他方法均为最大值,由此可见,除HYDPOI方法外,本文方法的最大传输模式和限制传输模式均高于其他方法,这是由于HYDPOI没有模仿合法流量且直接混合使用存储型隐蔽通道造成的。 图7反映了偏重度k值变化对单一窗口流量带宽的影响,当k值在取值范围内不断增大时,即更多地考虑熵值变化对通道的影响时,通道的理论序列带宽降低,因为带宽较低的时间型隐蔽通道在加入隐蔽信息后,对熵值影响不敏感造成的,因此通道中使用了更多的时间型通道。在带宽限制算法的作用下,k值的变化对理论限制带宽影响较少,始终在带宽限制上限附近,但是与之对应的实际限制带宽却明显下降,这是由于时间型隐蔽通道使用数量随k值变化逐渐增多,隐蔽信息发送过程中,需要消耗大量的人为延迟时间造成的。因此k值可以良好地反映单一通道对熵值和分布的敏感程度,本文采用0.5取值来平衡考虑共享资源熵值和分布改变对合法流量的影响。 图7 偏重度k对带宽影响Fig.7 Influence of parameter k on bandwidth 由于本文提出的隐蔽通道构建算法本身考虑了熵值差异和分布差异,因此传统的熵检测和分布检测对该型隐蔽通道无法做到有效检测,因此使用更为广谱的SVM分类器作为检测方法,并利用训练得到的SVM分类器,对测试集上的隐蔽流量和合法流量进行分类,使用该分类器的准确度,即正确分类的样本个数占总体样本数的比例,作为通道隐蔽性的衡量,准确率越低,表明隐蔽流量越接近合法流量,通道隐蔽性越高。 图8展示了仅使用隐蔽通道库中的一种通道进行信息传输与限制带宽为1 500 bit的自适应伪随机序列混合隐蔽通道的分类准确度的对比情况,可以发现,在单一使用的隐蔽通道中,存储型的隐蔽通道可以被准确分类,时间型和序列型的隐蔽通道分类准确度下降,隐蔽性较强,当使用本文方法进行通道构建后,分类器的准确度明显下降,除使用TCP目的端口的通道,其他通道均降至0.5左右及以下,这是由于该流量为普通用户上网WEB访问流量,主要下层协议为HTTP及HTTPS,目的端口单一,少量隐蔽信息的写入也会对信道影响较大造成的。 图8 单一通道与自适应混合通道分类准确度Fig.8 Classification accuracy of single channel and self-adaptive hybrid covert channel 不同的使用序列也会对产生的隐蔽通道隐蔽性造成影响,分别使用轮询序列(各类通道按顺序循环)、伪随机序列(各类通道按均匀分布随机使用)以及自适应伪随机序列构建混合隐蔽通道,并测量其在各共享资源上的分类准确度,并计算平均值,得到不同序列的平均分类准确度,如表5所示,相比与轮询和随机序列,本文方法所产生的自适应随机序列可使通道分类准确率大大降低,较好地提高了通道的隐蔽性。 表5 不同随机序列对隐蔽性影响Table 5 Influence of different random sequences on channel covertness 本实验主要考察SPSH-CC通道在不同的网络环境中,或者存在人为干扰条件下通道正确传输信息的能力,使用误码率作为其衡量标准。 表6展示了在不同的网络环境中多次使用SPSH-CC通道传输隐蔽信息,计算其误码率后取平均值的结果。可以看出,在延迟稳定、网络跳数少、无防火墙的本地环回网络和局域网中,该通道的误码率为0,而在延迟较高且不稳定,跳数较多,且存在防火墙等过滤系统的广域网中发生了一定的误码情况,通过定位发生误码的通道位置,发现该误码主要是由于云端服务器进行的端口转换操作导致的,使得使用源端口字段作为共享资源的隐蔽通道不能正确传输信息,同时,广域网环境中的包延迟较大,包乱序的情况也是出现误码的部分原因。 表6 不同网络环境对通道误码率影响Table 6 Influence of different network environments on channel bit error rate 图9展示了在一次误码率为0的本地局域网环境信息传输过程中,通过人为的干扰通道库中的任意一条通道后,SPSH-CC通道误码率情况。任意切断或者干扰库中一条或者多条通道都不能完全阻断该通道的信息传输,由于自适应伪随机序列算法的引入,干扰不同的通道对整体误码率影响不同,TCPSEQ和TCPACK通道的干扰能显著提高误码率,但是IPID和TCPDPORT通道的干扰对误码率没有影响,这是由于算法在此次传输中相关共享资源的强模式性而没有使用该通道造成的。 图9 干扰单一通道对误码率影响Fig.9 Impact on bit error rate with interference on single channel 本文提出一种新的使用自适应伪随机序列混合算法构建隐蔽通道的方法。该方法通过混合使用存储型、时间型、序列型隐蔽通道,并实时根据流量特征自适应地生成伪随机使用序列,使生成的隐蔽流量更加接近合法流量的特征,从而绕过监管设备进行隐蔽信息的传输。实验证明,该方法在具有良好的隐蔽性的同时,可以达到预期的带宽指标。由于隐蔽通道库和带宽限制的引入,该方法可扩展可自定义,具有十分强的实用性。下一步,将在本文的研究基础上,通过将隐蔽通道库中用来方法验证的简单隐蔽通道更新为隐蔽性更强的复杂隐蔽通道,研究更加细粒化的序列生成算法,进一步提高通道的隐蔽性,同时,研究能够准确识别该类隐蔽通道的对抗方法。

3 自适应伪随机序列混合方法构建
3.1 同步

3.2 带宽


3.3 检测

4 实验评估
4.1 实验环境及参数


4.2 带宽实验




4.3 隐蔽性实验
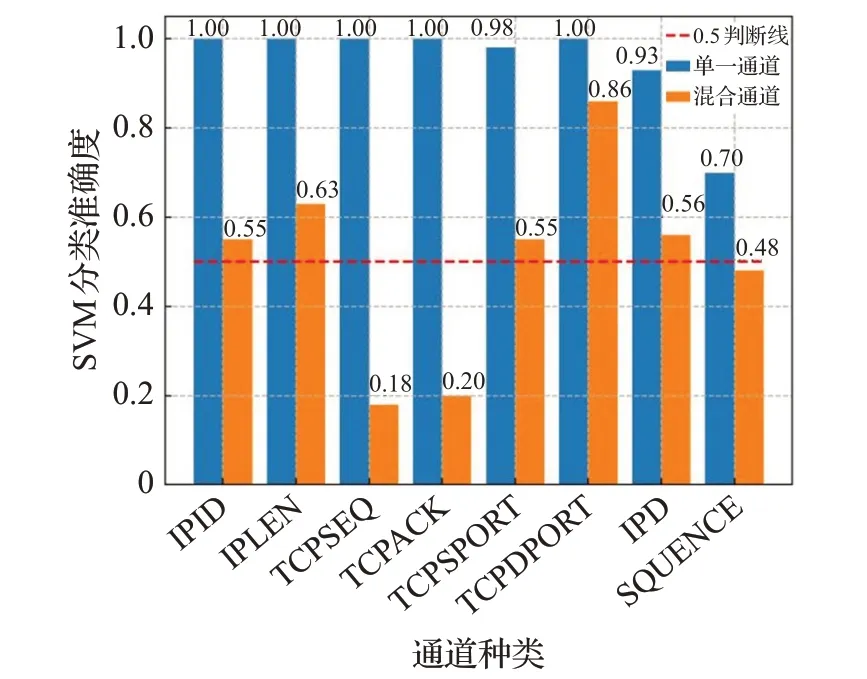

4.4 鲁棒性评估

5 总结
猜你喜欢
黑河学院学报(2021年1期)2021-01-16 19:40:27
公民与法治(2020年23期)2021-01-04 01:02:24
公民与法治(2020年3期)2020-05-30 12:29:56
广西警察学院学报(2020年2期)2020-05-29 09:01:10
中国外汇(2019年14期)2019-10-14 00:58:32
网络安全和信息化(2018年4期)2018-11-09 12:01:54
法制博览(2017年2期)2017-03-13 19:03:00
人间(2016年33期)2017-03-04 12:53:08
妈妈宝宝(2017年2期)2017-02-21 01:21:22
中国新通信(2014年11期)2014-09-11 19:27:52
