
人工智能在新药发现中的应用进展
2021-09-07 09:31黄芳杨红飞朱迅
药学进展 2021年7期
黄芳,杨红飞*,朱迅
(1. 杭州费尔斯通科技有限公司,浙江 杭州 310051;2. 吉林大学基础医学院,吉林 长春 130021)
众所周知,一款新药从研发到上市平均需要花费10年以上的时间以及投入高昂的资金,然而仅有10%的新药能被批准进入临床研究,最终只有更小比例的药物分子获批上市。曾有投资人将新药“从实验室进入临床试验阶段”形容为“死亡之谷”。
人工智能(artificial intelligence,AI)现在还处于起步阶段。AI起初被大规模应用于医疗影像,然后逐渐渗透到药物研发领域。近年来,越来越多的AI企业投资AI+新药研发赛道,以及海外人才的回归,给中国AI+新药研发注入一股新力量。从医疗领域全景来看,AI尚未介入很多细分领域,还需要更长的时间、更系统化的解决方案。要实现AI在医疗领域的全面落地,需要不断优化升级AI系统,提升AI的智能化和个性化。虽然AI在医疗健康领域处于起步阶段,但普及到各细分领域的潜力巨大。
AI能够实现在生物医药产业自上游到下游的投入使用,且虚拟筛选、靶点发现等部分应用场景已经能够为企业带来实际收益。新型冠状病毒肺炎(COVID-19)疫情发生后,越来越多的生物医药企业和研究机构通过将其业务与AI结合来完成创新突破,在新药开发、生产运营,甚至商业战略中都有所应用。AI技术在生物医药领域中的应用涉及药物研发、医学影像、辅助治疗、基因治疗等方面,药物研发在全球医疗AI市场中的份额最大,占比达到35%。靶点发现与筛选成为AI+新药发现中最为热门的应用领域,AI通过深度学习技术快速发现药物与疾病,以及疾病与基因间的连接关系,进而缩短靶点发现周期。在化合物合成方面,AI可通过模拟小分子化合物的药物特性,在较短时间内挑选出最佳模拟化合物进行合成试验,大幅提高化学合成路线设计速度,以降低操作成本。
目前,AI算法模型被诸多学者提出,随着药物研发数据的高速累积和数字化转型,以及AI技术的加速发展,决策树(DT)、随机森林(RF)和支持向量机(SVM)等机器学习模型以及深度神经网络(DNN)、卷积神经网络(CNN)和循环神经网络(FNN)等深度学习算法逐渐被应用于药物发现领域。本综述主要介绍机器学习和深度学习方法在药物发现领域的应用进展以及相关企业。
1 人工智能技术与算法模型简介
新药研发是一个漫长且高投入的过程,高通量筛选、药物基因组学等技术加速了药物开发,引领其步入大数据时代,药物发现大数据可用“十个V”来描述,即:数量(volume)、速度(velocity)、品种(variety)、准确性(veracity)、有效性(validity)、词 汇(vocabulary)、场 合(venue)、可 视 化(visualization)、波动性(volatility)以及价值(value)[1]。基于数据库在药物发现不同阶段的应用和相关性,可将其分为6类:1)全面化学分子库,如Enamine、PubChem和ChEMBL;2)药物/类药化合物库,如DrugBank、AICD和e-Drug3D;3)收集药物靶标,包括基因组学和蛋白组学数据的数据库,如BindingDB、Supertarget和Ligand Expo;4)存储通过筛选、代谢和功效研究获得的生物学数据的数据库,如HMDB、TTD、WOMBAT和PKPB_DB;5)药物毒性数据库,如DrugMatrix、SIDER和LTKB基准数据集;6)临床数据库,如ClinicalTrials.gov、EORTC和PharmaGKB[1]。
AI领域中的自然语言处理、机器学习、深度学习、知识图谱、计算机视觉等相关技术,有助于解决药物研发领域的痛点。这些技术、算法模型在蛋白结构及蛋白-配体相互作用预测、药物靶点发现、活性化合物筛选等新药发现环节均已得到广泛应用[2–6]。各环节常用的AI方法详见图1。
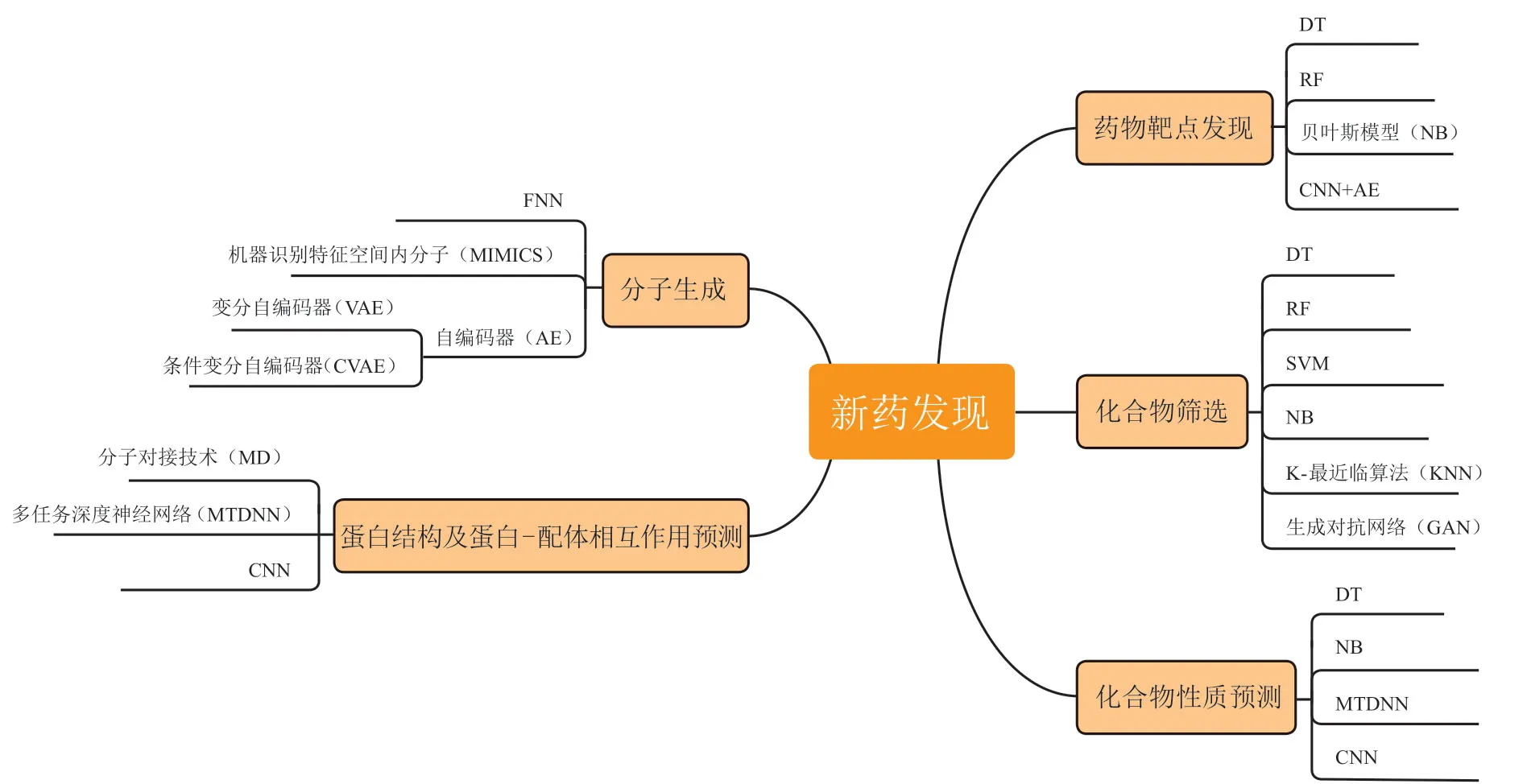
图1 新药发现各环节常用的人工智能技术Figure 1 Artificial intelligence techniques used in all aspects of new drug discovery
2 人工智能在药物发现中的应用
2.1 药物靶点识别
靶点是新药研发的基础。当前,药物研究的竞争主要集中体现在药物靶点研究上,早期药物靶点确定对研发项目成功至关重要。
DT算法是一种常用的机器学习算法,具有条理清晰、程序严谨、定量与定性分析相结合、方法简单、易于掌握、应用性强、适用范围广等优点。RF算法是一种基于Bagging的集成学习方法,可处理分类、回归等问题,RF分类器通过将许多DT结合来提升分类的正确率。目前,DT、RF分类器可用于预测药物靶点,Costa等[7]构建了一个基于DT的分类器,通过该分类器预测与疾病相关的基因,最后发现了多种转录因子在代谢通路和细胞外定位中的调控作用。Kumari等[8]通过自助法采样提升了RF算法的稳定性,成功从潜在靶点中筛选出最有可能获得成功并应用于临床的靶点。Zeng等[9]开发了deepDTnet深度学习方法,该系统嵌入了15种类型的网络,包括化学、基因组、表型和细胞网络,可以将最大的生物医学网络数据集成在一起,通过异构网络中的深度学习对已知药物进行靶标识别,以加速药物的重新利用、减少药物开发中的障碍。Madhukar等[10]提出BANDIT(Bayesian ANalysis to determine Drug Interaction Targets)可以准确预测药物与特定靶标的相互作用,不仅可用于识别多种多样的小分子的特定靶标,而且可用于区分同一靶标上的不同作用模式。
机器学习还可以预测肿瘤对药物的反应。Iorio等[11]研究了全基因组基因表达、DNA甲基化、基因拷贝数和体细胞突变数据对药物反应的影响。该研究组通过3种不同的分析框架,即方差分析、逻辑模型和机器学习算法(弹性网络回归和RF)来定义“癌症功能事件”(cancer functional event,CFE)对药物敏感性预测的贡献。Iorio等的研究成果可帮助新药研发工作者更好地利用肿瘤细胞系来了解哪些药物将为哪些患者提供最有效的治疗。
2.2 化合物高通量筛选
化合物筛选是指通过规范化的实验手段,从大量化合物中选择对某一特定靶点具有较高活性的化合物的过程,该过程需要较长的时间和成本。AI可以通过对现有化合物数据库信息的整合和数据提取、机器学习,提取与化合物毒性、有效性相关的关键信息,从而大幅提高筛选的成功率,降低研发成本和工作量。
李瑾[12]利用化合物活性分类方法ENS-VS构建蛋白质和配体亲和力模型ComplexNet,用于预测初步筛选出的小分子与靶标蛋白的结合强度,进行精细筛选。筛选过程分3步:首先,通过集成SVM、朴素贝叶斯及DT这3种分类算法将蛋白质-配体相互作用特征和配体结构进行特征融合,解决活性化合物与非活性化合物样本数量严重不平衡的问题以及提高靶标蛋白的适用性、稳定性;其次,通过Spark大数据平台实现ENS-VS方法的并行加速,提高活性化合物筛选的执行效率;最后,基于DUD-E标准数据库针对靶标已知的活性化合物数量和是否出现新的靶标蛋白特性分别构建蛋白家族特异性模型、靶标特异性模型与通用模型。实验结果表明,ENS-VS方法能有效提高活性化合物筛选的命中率,并且可与任意分子对接程序联合使用,对提高基于结构的虚拟筛选方法的成功率具有极其重要的意义。Wu等[13]利用生物信息学和结构基因组学的方法系统分析了新型冠状病毒(SARS-CoV-2)基因编码的蛋白,将其作为主要或潜在的药物治疗靶点,并将SARS-CoV-2基因序列与SARS-CoV和MARS-CoV等冠状病毒进行了比对,通过AI计算机虚拟筛选方法发现一些具有抗病毒、抗菌和抗炎作用的临床药物和天然产物对上述靶蛋白表现出较高的亲和力,为COVID-19的治疗提供了新的可能。SVM分类模型能够处理小数据集中的高维变量,还可以处理分类和回归问题,其分类效果强于DT与RF这2种机器学习方法。Poorinmohammad等[14]通过建立SVM分类模型对人类免疫缺陷病毒(HIV)多肽进行分类,预测准确率达到96.76%。SVM用MATLAB编写的svm源程序可以实现SVM分类或提取,用于化合物库的虚拟筛选,有学者通过组合SVM和分子对接方法自动筛选化合物库,显著提高了活性化合物的命中率和富集因子,节省了计算资源[15]。
细胞活力测定、细胞信号通路分析和疾病相关表型分析这3种基于细胞表型的方法常被用于筛选先导化合物。结合了AI技术的表型筛选更加高效,适用于更为复杂的病理生理过程,且能在细胞水平利用表型改变来筛选新化合物[16]。SVM、RF或贝叶斯等机器学习技术已被成功应用于药物发现阶段的化合物筛选环节。Cyclica开发了名为“Ligand Express”的云端蛋白质组学筛选平台[17],该平台使用生物信息学和系统生物学技术将药物与蛋白的互动关系呈现为图像,利用AI对小分子化合物进行全面评估,帮助改善药物活性、预防药物副作用,以及发现能与小分子化合物结合的新靶点,制药科学家正在积极利用该平台探索药物发现新领域。SVM和朴素贝叶斯模型已成功应用于哺乳动物雷帕霉素靶蛋白(mTOR)抑制剂的虚拟筛选。Narain等[18]通过AI贝叶斯神经网络推断方法分析转移性前列腺癌(PC-3)细胞蛋白质组数据,生成每个特定因子的独特概率模型,再根据功能变量子网的Burt约束度量排名找到潜在的前列腺癌生物标志物Filamin-A和Filamin-B等。中国科学院上海生命科学研究院陈洛南教授团队利用AI克服了区分疾病样本和正常样本的分子生物标志物覆盖率低和假阳性率高的问题,确定了基于多维数据复杂疾病的网络标志物及动态网络标志物筛选方法[19–20]。
2.3 预测药物的吸收、分布、代谢、排泄和毒性
预测药物的吸收、分布、代谢、排泄和毒性(ADMET)是药物设计和药物筛选中十分重要的方法。过去,药物ADMET性质研究以体外研究技术与计算机模拟等方法相结合,研究药物在机体内的动力学表现。目前市场上有数十种计算机模拟软件,包括ADMET Predicator、MOE、Discovery Studio和Shrodinger等,该类软件现已在国内外的药品监管部门、企业[如晶泰科技(XtalPi)、Numerate等]和科研院所得到了广泛应用。为了进一步提升ADMET性质预测的准确度,已有生物科技企业探索通过DNN算法有效提取结构特征,加速药物的早期发现和筛选过程。例如晶泰科技通过应用AI高效地动态配置药物晶型,完整地预测一个小分子药物所有可能的晶型,大大缩短了晶型开发周期,更有效地挑选出合适的药物晶型,减少了研发成本[21]。普林斯顿大学化学系的Abigail G. Doyle教授与默克公司的研究人员合作,利用RF算法对氨基化反应条件进行优化,准确预测具有多维变量的Buchwald-Hartwig偶联反应收率,结果表明,RF算法可以利用高通量实验获得的数据来预测多维化学空间中合成反应的性能和化学反应收率,该机器学习算法模型将会在药物发现领域被广泛应用[22]。
严重药物不良反应是新药开发过程中导致失败的关键因素。王昊[23]通过构建贝叶斯网络预测模型进行药物不良反应的预测,结果发现该模型对导致呼吸困难发生频率在1%以上药物的预测准确率可以达到86.76%,机器学习模型能够作为有效工具在药物发现阶段对其进行安全性评估。毒性是新药研发的一项重要指标,在药物发现阶段排除毒性大的化合物对于新药研发相当有利。Goh等[24]构建了CNN毒性评估模型,将其用于预测分子的各种性质如毒性、活性和溶解性等,与多层感知机深度神经网络(MLPDNN)相比,发现CNN在活性与溶解度的预测方面表现更优异。
2.4 蛋白结构及蛋白-配体相互作用预测
靶点发现是新药研发的关键,而蛋白质功能分类研究有助于深入理解靶点蛋白特征,是解决药物靶点发现难点的有效途径。随着AI、大数据等技术的迅速发展,蛋白质功能预测已成为蛋白质功能注释的重要手段,也成为药物靶点发现领域的前沿问题[25]。序列同源性比对、CNN等多种计算方法被应用于蛋白质功能预测研究,方法论是同源蛋白具有相似功能[26]。
谷歌DeepMind团队开发出的AI产品Alpha-Fold2,可根据氨基酸序列准确预测蛋白质结构,预测结果已接近实验数据的水平,且预测的准确度可与冷冻电子显微镜(cryo-EM)、核磁共振或X射线晶体学等实验技术媲美[27]。谷歌DeepMind开发的AlphaFold[28]深度学习系统可以快速预测SARS-CoV-2的蛋白质结构,为COVID-19疫苗设计提供有价值的信息,而使用传统的实验方法获得蛋白质结构可能需要数月时间[29]。洪嘉俊[30]通过基于CNN的蛋白质二进制编码表示策略构建了蛋白质功能预测模型,结果表明,CNN预测GO家族蛋白的准确率在66% ~ 98%之间,显著高于SVM、概率神经网络(PNN)和KNN这3种机器学习方法,表明CNN模型在真实世界中具有很好的假阳性控制率。由于目前的细菌Ⅳ型分泌系统效应蛋白(T4SE)预测方法存在假阳性率高等缺点,洪嘉俊针对T4SE和非T4SE数据特征分别建立了T4SE的CNN预测模型,通过采用与Bastion4方法完全相同的建模数据集进行评估,基于蛋白质二级结构特征、位置特异性评分矩阵和序列One-hot编码技术这3种方式建立的模型预测准确率分别为95.6%、98.9%和96.7%,效果显著高于Bastion4,表明CNN模型可以用于T4SE的注释,且可以很好地控制假阳性率。
DNN在蛋白结构预测、蛋白质-配体相互作用预测方面也有应用。AlphaFold利用高效训练的DNN从主序列中预测蛋白质的性质,通过DNN预测氨基酸对之间的距离和相邻肽键之间的φ - ψ角,探索蛋白质结构的微观结构,以找到与预测相匹配的结构[31]。Ragoza等[32]使用CNN对蛋白配体复合物构建打分函数,通过打分函数评价蛋白-配体相互作用,该打分函数在蛋白-配体预测和虚拟筛选中的打分表现比AutoDock Vina更好,但是也存在实际计算的结果可能会远大于实验观察值的偏差问题,因此CNN在该方面的应用还有一定的改进空间。刘桂霞等[33]基于DNN构建蛋白质相互作用预测框架,预测框架在酿酒酵母蛋白质数据集上的准确率达到95.67%,精确度达到96.38%,该预测框架可以解决较高假阳性率和假阴性率的问题,整合蛋白质特征数据;张丽娜[34]提出基于多源特征的提取策略,利用集成学习方法构建蛋白质-配体相互作用预测模型,该方法的敏感性和Youden指数均优于单分类器预测模型,可以有效解决数据不平衡问题。Cunningham等[35]基于6个常见的球形蛋白结合域(PBD)家族构建了HSM模型,其能准确预测跨多个蛋白质家族的PBD-肽相互作用的亲和力,HSM具有较高的灵活性,适用于在疾病中对突变的PBD和肽进行建模,以及基于肽的药物的设计。
2.5 分子生成
AI可以通过对海量化合物或药物分子的学习获得化合物分子结构和成药性方面的规律,再根据规律生成很多自然界从未存在过的化合物,将其作为候选药物分子,有效构建拥有一定规模且高质量的分子库。高质量的小分子库是药物研发人员一直关注的问题,研究者们利用深度学习技术设计了变分自动编码器(VAE)、生成对抗网络(GAN)、自回归模型(如PixelRNN和PixelCNN)等不同的分子生成模型。
Yang等[36]提出基于分子片段的AI分子设计新算法,该算法模型是基于带约束的Transformer神经网络架构SyntaLinker,可以快速自动生成满足特定链接段约束条件的大量新颖的分子结构。神经网络SyntaLinker由多个注意力机制(attention)模块构成,SyntaLinker利用其编码层和解码层对输入的分子片段结构序列进行处理,将分子片段自动连接起来,且结合约束信息,填充链接段,从而生成一个完整的分子。未来这种基于片段连接的分子设计算法能被用于实际的药物开发项目中,为药物化学家提供更多具有启发性的化学结构。曲晋慷[37]对新型药物设计方法进行创新,提出通过深度分子生成模型DGMM、深度迁移分子生成模型 T-DGMM、深度强化分子生成模型 R-DGMM这3种模型生成潜在抗HIV活性分子,以扩增潜在抗HIV活性分子库。DGMM基 于 MLSTM、SRU、QRNN这3种 循 环单元进行构造可以生成结构有效、新颖且性质无偏的分子;T-DGMM通过搭建抗HIV活性预测模型 AAPM可以生成潜在抗HIV活性分子,扩增潜在抗HIV活性分子库;R-DGMM采用基于策略梯度的强化学习方法REINFORCE搭建模型,生成抗HIV药物利匹韦林的相似物,适用于潜在抗HIV活性分子库扩增。谭小芹[38]基于循环神经网络建立了分子生成模型,进行多靶点GPCR分子库的自动设计,再对生成的分子进行活性、可合成性、类药性等多方面评估过滤,最终得到了具有潜在治疗精神疾病活性的候选化合物。同时,基于序列到序列(Seq2Seq)模型建立分子生成模型,该模型可以生成一个基于骨架的虚拟分子库,然后通过激酶谱预测模型对分子库进行虚拟筛选,最终筛选得到可抑制细胞中促炎因子的表达和盘状结构域受体家族成员 1(DDR1)自磷酸化的化合物。
在分子设计领域,生成模型还处于起步阶段,其面临着以下挑战:1)如何提高模型的泛化能力;2)如何提高对真实数据进行推断的能力;3)如何提高生成新分子的能力。此外,分子生成模型的性能难以评估。如何建立基准以便于量化比较模型性能,而非通过预测分子溶解度或药物相似性等方法进行比较仍充满挑战[39]。
3 全球人工智能新药发现企业及市场规模
伴随AI技术的迅猛发展,新药研发工作者希望通过AI技术解决医药行业痛点,包括降低药物的研发成本、缩短其研发周期、控制新药研发风险,在此基础上,一批AI企业相继出现。
国内外多家AI企业与药企开启了深度战略合作模式,利用其自主设计的人工智能技术平台助力制药企业进行新药研发(见表1)。
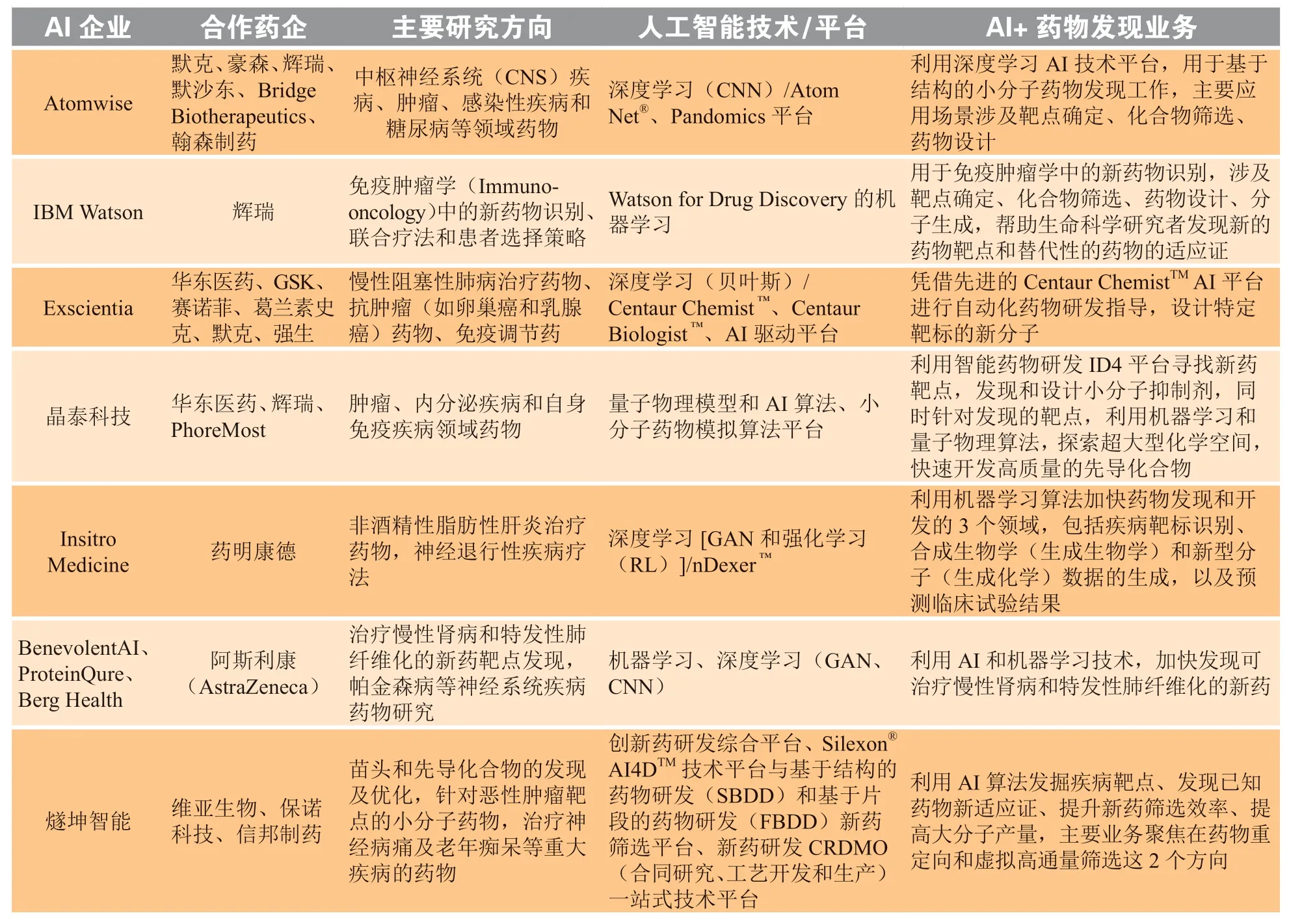
表1 人工智能企业与制药企业在新药研发领域的战略合作Table 1 Strategic cooperation between artificial intelligence enterprises and drug manufacturers in the field of new drug research and development
基于AI技术的药物设计公司Atomwise拥有的AtomNet®是第一虚拟药物发现平台,其核心技术是CNN。Atomwise已与多家制药公司开展约1 000个项目,主要包括肿瘤、传染病、神经系统疾病、心血管疾病、免疫性疾病、内分泌系统疾病、COVID-19等领域的药物研究。
晶泰科技以AI、量子物理、量子化学及云计算为核心,推动AI赋能的数字化药物研发新基建,为创新药研发增效提速。晶泰科技AI药物发现平台,在分子生成、虚拟筛选、高精度活性预测等AI+药物发现的关键环节具有独到的技术优势,能实现超大型化学空间的探索,百万级的新分子结构生成及全面、综合的成药性、活性、ADMET等性质的评估,完成高质量的先导化合物开发和临床前候选化合物开发。
伴随药物研发数据的高速累积和药企数字化转型,以及AI技术的加速发展,AI在新药发现的应用日益增多,其优势也得到突出体现。互联网数据资讯网(BCC)数据显示,AI在医疗健康产业所有应用场景中,新药发现的市场规模与增长速度均占据第一位,预计2024年市场规模将达到31.17亿美元,年均复合增长率(CAGR)为40.7%;根据大观研究(Grand View Research)的最新报告,到2027年,全球AI+药物发现的市场规模预计将达到35亿美元,CAGR为28.8%(见图2)。
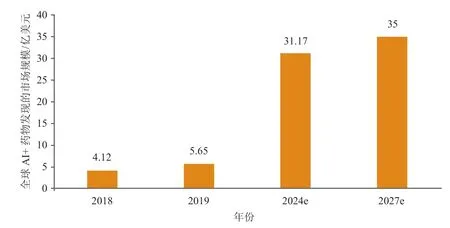
图2 人工智能在新药发现领域的市场规模Figure 2 Market size of artificial intelligence in new drug discovery
火石数据库资料显示,国内从事AI+药物发现的企业有晶泰科技、深度智药、云势软件、望石智慧等,主要分布在北京(7家)、上海(4家)、杭州(2家)和深圳(2家)等地(见表2);但总数较少,不足20家。
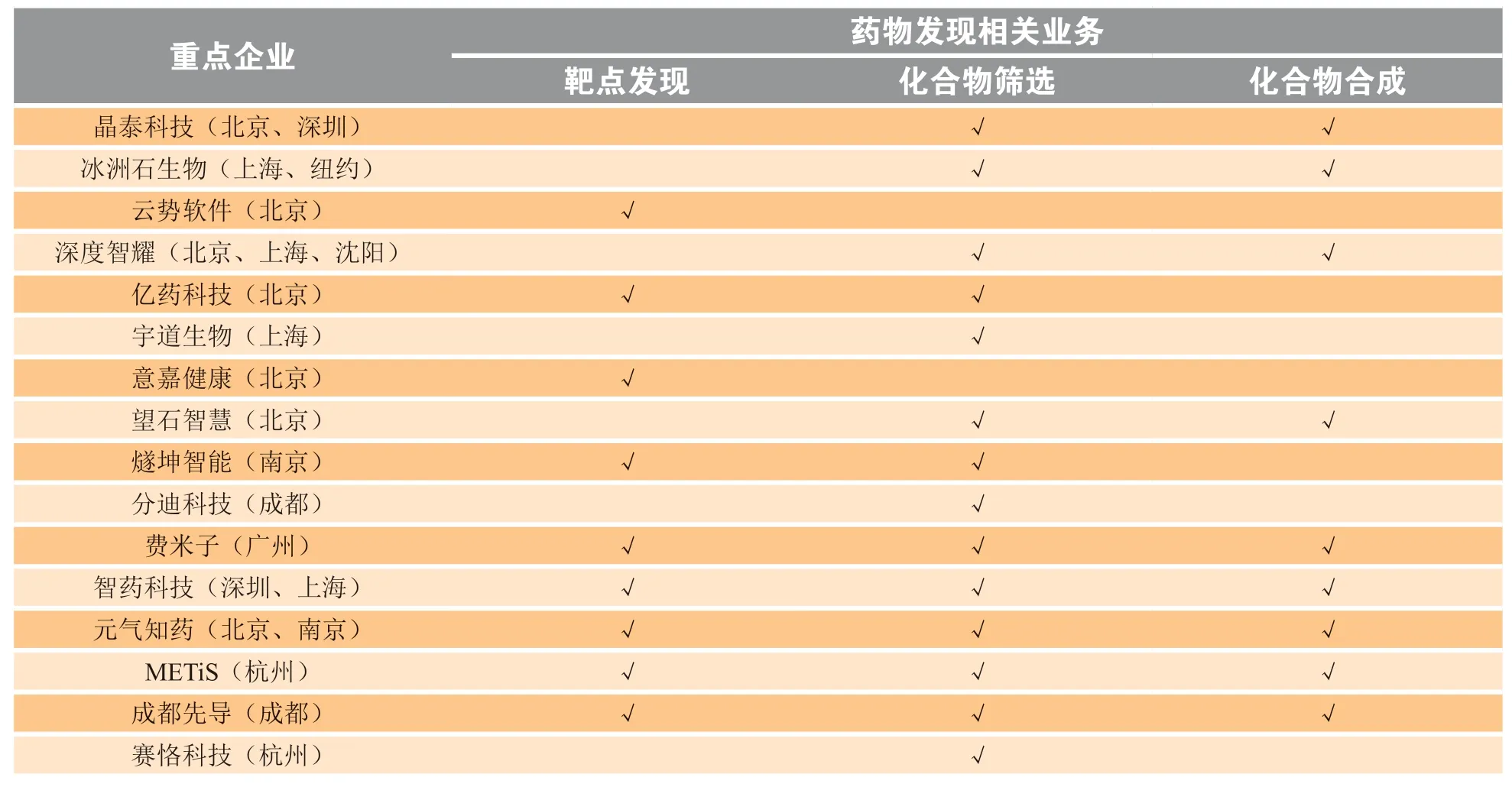
表2 国内主要从事AI+药物发现的公司及其业务布局Table 2 Major domestic companies applying artificial intelligence in drug discovery and their business layout
2015—2020年,我国药物发现CRO市场CAGR达到28.2%,2020年市场规模约为131.5亿元;预计未来5年,创新药研发速度不断加快,我国药物发现CRO市场仍将保持快速增长态势,到2025年市场规模将达到385.2亿元。
4 人工智能应用于新药发现的机遇与挑战
受DNN或递归神经网络(RNN)技术快速发展的影响,AI技术在药物靶点发现、化合物合成、化合物筛选、晶型预测、药理作用评估、药物重定向、新适应证开发等多个场景中应用广泛,应用优势也愈加凸显。TechEmergence研究报告显示,AI可以将新药研发的成功率从12%提高到14%。此外,AI在化合物合成和筛选方面可节约40% ~ 50%的时间,每年为制药行业节约260亿美元的化合物筛选成本[40]。基于此,药物研发领域数字化转型加速,各大制药公司都在迫切寻找能够缩短新药研发周期、有效提高研发成功率、开发有竞争力的创新药物的解决方案。
AI在新药研发中的应用面临政策瓶颈、人才匮乏、技术壁垒、数据质量不确定等方面的挑战。第一,从政策瓶颈来看,新技术的引进改变原有药物研发模式,而现在尚无针对性的政策指南出台。第二,从人才壁垒来看,高端复合型人才缺失较严重,限制创新发展。未来需要国家出台相关人才政策,培养复合型高端人才。第三,从技术壁垒来看,自然语言、知识图谱以及知识问答、分析决策和语义搜索等需要较大提升。第四,从数据质量挑战性来看,AI模型基于数据学习,数据学习导致了结果的不确定性,新药研发系统工程加上AI双系统的不确定性也会导致新药研发结果的不确定性。近年来,出现了一些来源于临床相关模型的高通量数据,例如用于高通量测试的异质细胞系统及其参数(3D细胞模型中的细胞间相互作用和渗透性)和患者衍生的测试系统,这些系统产生的数据将来可能会对药物发现产生重大影响;但当前阶段,可用于AI挖掘的数据仍相对较少,需要生成足够大量的数据才能真正在上述系统里使用[41]。
5 结语与展望
尽管在多数情况下化学数据可大规模获得并成功用于配体设计和合成,但这些数据并不能满足AI药物发现的需求,且大量可用于模型建立的测定数据(如小分子的各种体外物理化学性质)也并不能很好发挥作用。因此,未来需要更多的高质量化合物数据进行AI研究,包括化合物的体外活性/毒性指数,以及正确剂量/药代动力学数据等。在后期阶段,还需要化合物在动物模型中的药效和毒性数据。此外,我们还需要更有效地进行临床试验,以获得高质量化合物临床数据。
AI分析药物在体内活性时的数据非常有限,使得计算机不能很好地做出决策,主要影响因素有:第一,没有一个可以比较的基准;第二,可选择的化学结构非常多;第三,在化学领域验证药物的有效性非常难,实验中使用数据往往具有稀疏性和保密性的特性。
值得一提的是,大量描述化学特性的数据能够使计算机生产相应的配体,但配体发现不等于药物发现。在未来,我们需要更多了解药物的生物学特性,了解它们在人体内的一系列反应。此外,临床成功率比时间和成本更重要,我们需要让更多高质量候选化合物进入临床,更好地验证靶点,以及选择合适的患者进行临床试验,提高临床成功率,从而生成有用的数据,从本质上推动AI+药物发现领域的进展。
猜你喜欢
中国合理用药探索(2022年1期)2022-11-26
体育科技文献通报(2022年3期)2022-05-23
安徽医科大学学报(2022年4期)2022-05-12
华人时刊(2022年1期)2022-04-26
世界中医药(2021年22期)2021-01-03
中学化学(2017年6期)2017-10-16
中学化学(2017年6期)2017-10-16
中学化学(2017年2期)2017-04-01
试题与研究·高考理综化学(2016年3期)2017-03-28
祝您健康(1991年5期)1991-12-29
