
基于改进YOLOv3网络的车牌检测算法
2021-09-07 02:12江祥奎
西安邮电大学学报 2021年3期
江祥奎,刘 洵,李 红
(西安邮电大学 自动化学院,陕西 西安 710121)
车牌检测(License Plate Detection, LPD)算法是将图像识别技术应用于车牌的识别,对图片的车牌区域进行定位并识别,提供给交通网络,从而实现监控、跟踪以及自动收费等功能。目前,国内的车牌检测算法已广泛应用在高速公路电子收费、停车场管理等领域[1-4]。然而,交通场景下拍摄的图片照明度低、车牌目标小、车辆行驶速度快,以及工业摄像机抓拍的图像容易出现动态模糊、分辨率低等问题,直接影响了最终的识别效果。国外的车牌检测技术开始于20世纪80年代,通过提取车辆牌照的特征信息实现车牌识别[5],主要应用于自动驾驶、车联网等方面。但是,在环境复杂的交通场景中,检测算法常常会在提高检测速度的同时降低了检测精度[6-7],动态模糊情况下的检测精度还有待提升。
车牌检测算法主要有基于灰度图像的检测算法、基于彩色图像的检测算法、基于多特征融合的检测算法和基于深度学习的检测算法等4种类型。基于灰度图像的检测算法是通过边缘、纹理和投影等特征信息检测车牌,该类算法运算量小,但在复杂背景下识别率低[8-9]。基于彩色图像的检测算法利用国内车牌通常是蓝底或黄底的特征与周围环境进行区分,该类算法检测速度较快,但背景颜色与车牌底色相近时,对检测结果有一定影响[6-7,10]。基于多特征融合的检测算法通过融合两种及以上车牌特征,在一定程度上减少了复杂环境对检测结果的影响[8,11-13],但该类算法的训练过程较为复杂。基于深度学习的检测算法通过机器学习训练模型,利用训练得到的模型对车牌进行检测。该类算法包含了多层次特征提取结构,能够提升检测算法的准确率,但在图像模糊情况下的检测精度仍有待提高。典型算法有Faster R-CNN(Region-CNN)算法和YOLO(You Only Look Once)系列算法[14-16]。
针对基于深度学习的检测算法对交通环境下车牌检测精度不高的问题,拟提出一种基于“YOLOv3+ResNet”网络,且在超分辨率重建数据集下进行训练的车牌检测算法。首先,对模糊图像进行超分辨率重建,利用深度递归残差网络(Deep Recursive Residual Network,DRRN)学习低分辨率的图片信息,通过残差学习与低分辨率进行矩阵相加,得到高清结果。其次,采用无区域提名的网络结构,以满足网络实时性要求。最后,将网络结构与分类网络相结合,并根据分类网络的损失曲线和精度曲线,选取较好的一种,以期算法应用于车牌检测时取得较好的检测结果。
1 基于深度学习的车牌检测算法
基于深度学习的车牌检测算法常用的网络是卷积神经网络(Convolutional Neural Networks,CNN)及以CNN为基础扩展的区域提名网络和无区域提名网络。
基于Faster R-CNN的车牌检测算法属于典型的区域提名算法,其先利用选择性搜索的方法,在待检测图片上选择若干个车牌区域候选框,然后提取候选框内的特征信息,使用分类器识别并分类,最后,通过非极大值抑制算法对候选区域进行筛选。Faster R-CNN网络因受两阶段算法的限制,其检测速度难以满足实时检测的要求[17]。
基于YOLO的车牌检测算法属于无区域提名算法,是由GoogleNet改进而来,其采用回归的方式输出预测目标物体的类别和边界框,检测速度快,满足交通场景下实时检测的要求。YOLOv3是YOLO的改进算法,其简化了池化层和全连接层,只用卷积核实现特征图的维度缩减和维度变换,具有较好的特征提取能力[18]。YOLOv3的网络结构如图1所示。
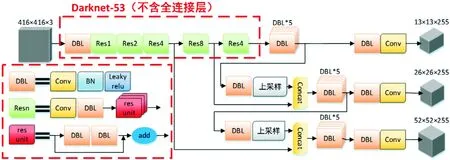
图1 YOLOv3网络结构
YOLOv3网络采用预测框标注目标,用置信度体现预测框中有目标的概率。预测框的置信度的计算表达式为
(1)
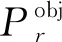
YOLOv3采用多任务损失函数学习类别特征和位置信息,主要包括位置损失Lloc、置信度损失Lcon和类别损失Lcls等3部分。对输入为M×M的图像,划分为N×N个网格后,每个网格中的预测框数为B、输出向量维数为5B+c,其损失函数的具体形式为
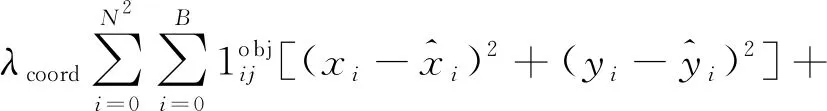
(2)

相比于Faster R-CNN网络,YOLOv3的检测速度有较高的提升。同时,为了保证模型训练时损失下降的更快,YOLOv3借鉴了Faster R-CNN的anchor机制,采用对原始数据集进行聚类,以生成更准确的目标预测锚框。每个边界框的特征图输出为
Y=N·N·B(5+c)=
N·N·B[(tx,ty,tw,th,C)+(p1,p2,…,pe)]
(3)
其中:tx、ty、tw和th为预测输出的结果;p1,p2,…,pc为c个类别对应的条件概率输出。tx、ty、tw和th和真实预测框bx、by、bw和bh的转换关系如图2所示。图2中的pw和ph分别为预测锚框设定的宽和高。YOLOv3通过评测预测框得分筛选出有目标的候选区域进行预测,抛弃目标背景,减少网络迭代次数。
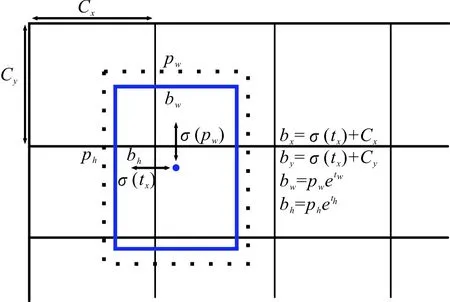
图2 YOLOv3预测框坐标转换示意图
2 改进YOLOv3的车牌检测算法
2.1 超分辨率重建
DRRN通过重建一张模糊的图片可生成一张较为清晰的图片,因此,使用DRRN对包含车牌信息的图片进行重建,可得到图片的高清结果。DRRN共包含52个卷积层,将插值后的图像作为输入,进行特征提取,使用16个残差递归层进入循环递归模块,进行非线性映射,权重在残差单元中共享。最后,使用一个卷积层进行超分辨率重建,以获得最终的结果。DRRN采用残差学习,减轻了训练深层网络的难度,通过递归学习控制了模型参数,增加了深度,多路径结构的递归块改善了梯度爆炸或消失的问题。DRRN简略模型如图3所示。
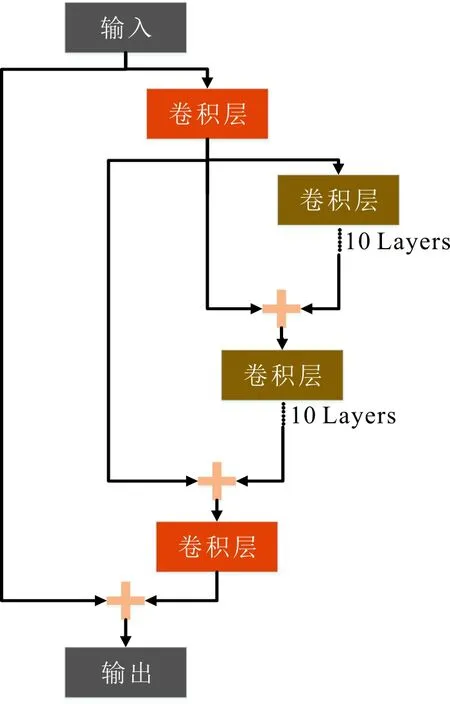
图3 DRRN简略模型
DRRN训练原始数据的具体步骤如下。
步骤1使用像素大小为400×400 px的窗口去完全覆盖车牌标注,加入一个窗口中心坐标的随机偏移量,使得偏移后的窗口仍满足完全覆盖车牌目标。
假设窗口大小为wwin×hwin,车牌框大小为wlabel×hlabel,车牌框中心位置为(xc,yc),则窗口中心位置[20]的x轴的随机偏移范围为
y轴的随机偏移范围为
步骤2使用双线性差值方式缩小裁剪的窗口尺寸,并结合原窗口尺寸作为一组低分辨率和高分辨率的训练对。为了增强网络对车牌的信息学习能力,对缩放倍数加入随机性,将所有缩放后的图片重新设置到200×200 px大小作为低分辨率输入。
步骤3使用一个反卷积层对原图进行尺寸扩张,再通过一个卷积层生成高分辨率结果。
在数据预处理阶段引入DRRN对VOC 2012数据集进行增强,原始数据及网络输出的对比如图4所示。
从图4中可以看出,利用超分辨率重建技术,能够有效提升图片清晰度,使模糊的车牌变得清晰,边缘和纹理特征增强,有利于后续算法检测。

图4 超分辨率重建前后对比
2.2 分类网络选取
ResNet网络又被称为残差神经网络,分为卷积结构、残差结构、池化及全连接结构。车牌检测算法首先通过卷积核对车牌图像进行卷积以及最大池化处理,然后分别对残差结构进行3~6次的残差操作,最后扁平化车牌的特征向量,对网络进行平均池化和全连接处理。图5给出了卷积块结构和ResNet的残差块结构对比。可以看出,使用残差块进行运算的参数量比直接进行卷积的参数少很多。在YOLOv3网络基础上引入ResNet模块,可以提取车牌更高层次的语义信息,降低网络参数,有效避免网络退化问题。
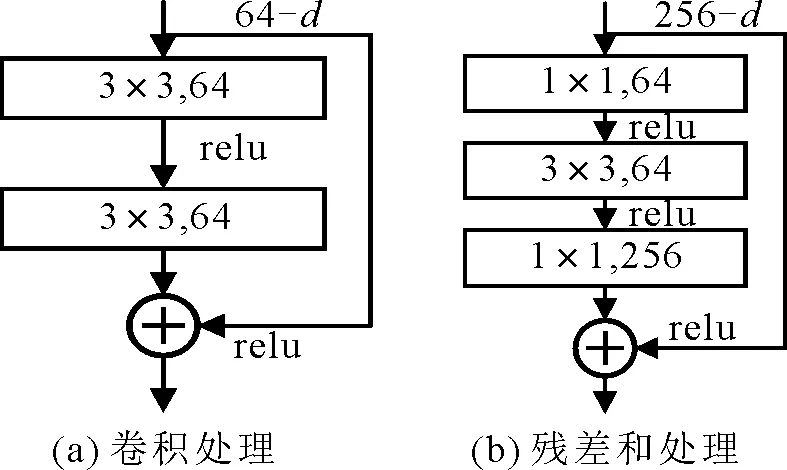
图5 卷积处理与残差处理的参数量对比
分别对比AlexNet、VggNet16、VggNet19、GoogleNet、ResNet50和ResNet101等分类网络在20次迭代训练过程中的损失函数和精度,结果分别如图6和图7所示。
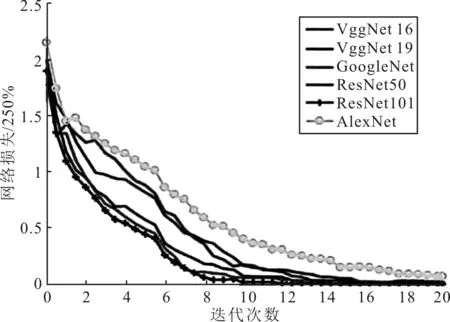
图6 网络损失函数对比
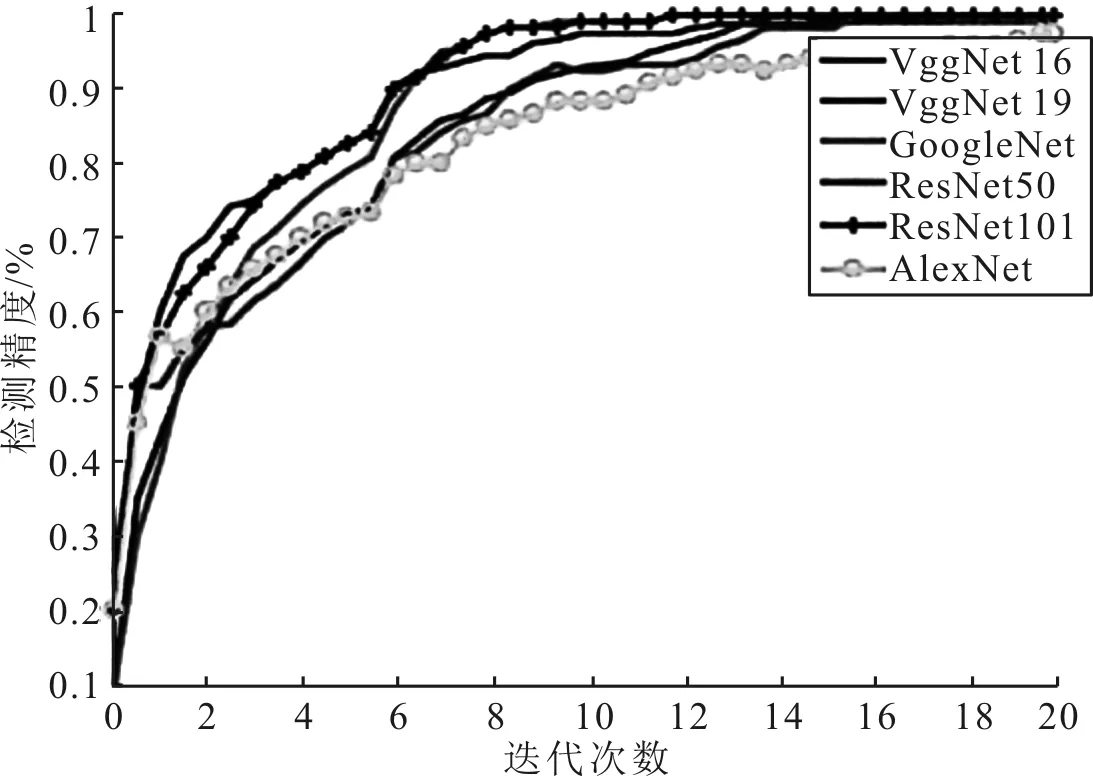
图7 网络精度对比
从图6和图7中可以看出,ResNet101的收敛速度最快,AlexNet、VggNet16、VggNet19收敛速度较慢,VggNet19和ResNet101的准确率较高,AlexNet的准确率较低。由此可以得出,ResNet101网络的预测结果较好,且其运算成本较低,因此,可在YOLOv3框架中结合ResNet101网络进行车牌检测。
3 实验分析
3.1 实验环境
实验环境为Windows GF940X,采用VOC 2012车辆数据集中的两万余张图片,分为训练集和测试集。所用语言为Python 3.5,计算架构为CUDA 9.0,设置网络的初始学习率为0.001,学习率衰减为0.96,网络层结构为[0.5 1.0 2.0]。
3.2 实验对比
3.2.1 不同算法的车牌检测对比
为检验算法检测车牌时能否满足实时性要求,对比基于Faster R-CNN网络、基于YOLOv3网络和改进YOLOv3网络的车牌检测算法在VOC 2012数据集上的计算量和检测速度,结果如图8所示。
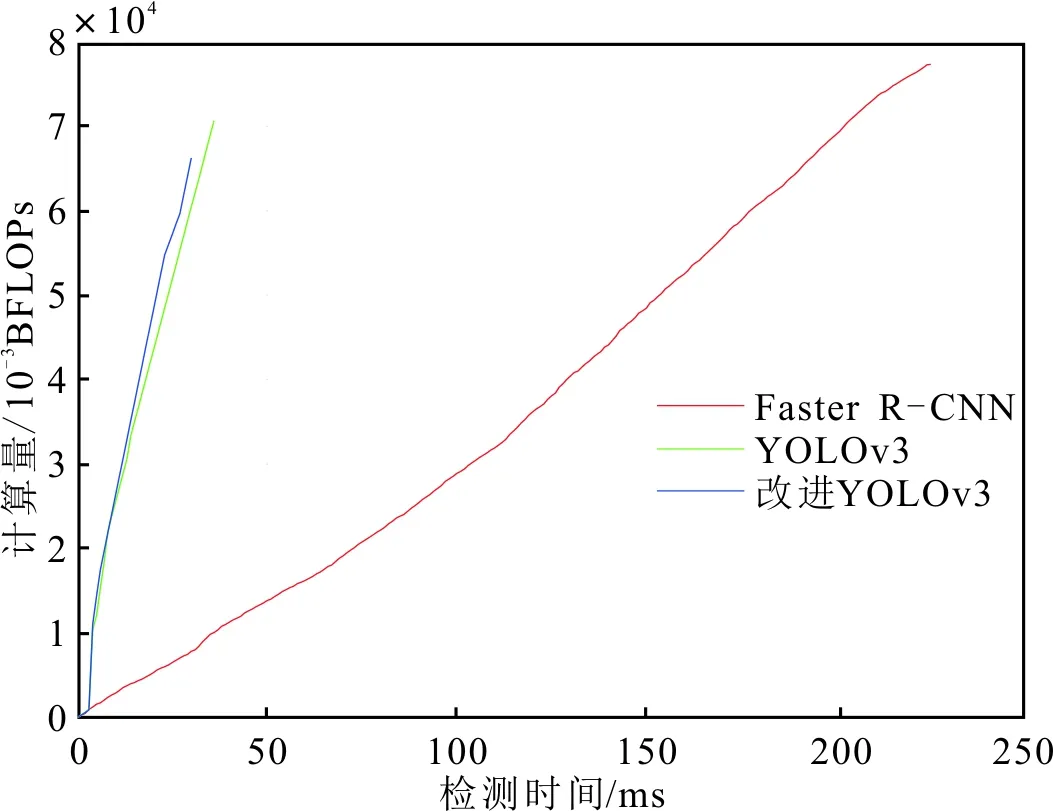
图8 不同网络的计算量和检测速度对比
从图8中可以看出,Faster R-CNN算法的计算复杂度和检测时间相比YOLOv3算法和改进YOLOv3算法均高出很多,而改进YOLOv3算法相比于YOLOv3算法,计算量有小幅缩减。
3种不同网络在VOC 2012数据集上的性能对比如表1所示。
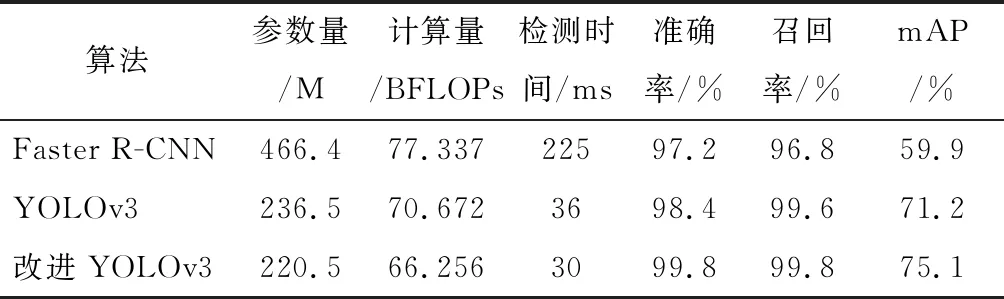
表1 不同网络在VOC 2012数据集中的性能对比
由表1可以看出,在VOC 2012数据集中,Faster R-CNN算法的平均检测时间为225 ms,YOLOv3算法和改进YOLOv3算法的平均检测时间分别为36 ms和30 ms。对图片中的车牌实时性检测时间要求不超过60 ms,因此,改进YOLOv3算法满足实时性要求。另外,YOLOv3算法的检测速度比Faster R-CNN算法提升了84%,计算量缩减了8.6%,而改进YOLOv3算法的计算量又比YOLOv3算法缩减了6.7%,且准确率、召回率及mAP值均比YOLOv3算法有所提升。
3.2.2 不同算法在复杂场景下的车牌检测对比
在VOC 2012的基础上选取具有图片像素低、模糊、车牌难以辨认及目标量大等特点的图片数据集VOC-HD,分别对比YOLOv3算法和改进YOLOv3算法的检测性能,结果如表2所示。可以看出,改进YOLOv3算法的检测准确率比YOLOv3算法提升了16.7%,精确率提升了10.9%,召回率提升了9.4%,特异度提升了22.2%,mAP值提升了10.2%。
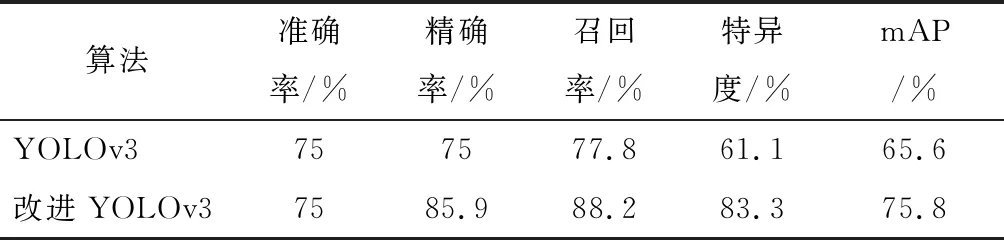
表2 两种算法在VOC-HD数据集下的性能对比
3.2.3 改进算法在重建数据前后的车牌检测对比
为检验超分辨率技术对改进YOLOv3算法的影响,特利用DRRN在VOC-HD数据集基础上进行重建,得到VOC-SR数据集,改进YOLOv3算法在VOC-HD数据集和VOC-SR数据集中的检测效果,如图9所示。

图9 改进YOLOv3算法在不同数据集中的检测效果
改进YOLOv3算法在VOC-HD数据集和VOC-SR数据集下的检测性能对比如表3所示。可以看出,改进YOLOv3算法在VOC-SR数据集上的召回率和特异度相比于在VOC-HD数据集的结果有明显提升,mAP值提升了13%。

表3 改进YOLOv3算法在不同数据集下的性能对比
4 结语
考虑到交通场景下车牌模糊难以检测,提出了一种改进YOLOv3网络的车牌检测算法。利用DRRN对模糊图像进行超分辨率重建,学习低分辨率的图片信息,得到了高清结果。采用YOLOv3无区域提名的网络结构,满足了车牌检测的实时性要求,并将其与预测性能较好的ResNet网络相结合,使得在交通场景下的车牌检测准确率进一步提高。实验结果表明,改进YOLOv3算法对小目标车牌的检测效果较好,对重建后数据的车牌检测效果较好。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
北京大学学报(自然科学版)(2022年1期)2022-02-21
动漫界·幼教365(中班)(2021年4期)2021-05-23
北京航空航天大学学报(2020年10期)2020-11-14
家庭影院技术(2020年2期)2020-03-25
北京航空航天大学学报(2019年9期)2019-10-26
小猕猴智力画刊(2017年5期)2017-05-25
科技创新导报(2016年32期)2017-04-22
CHIP新电脑(2016年3期)2016-03-10
微型计算机(2009年4期)2009-12-23
