
基于Word2vec 的信息窄化测度及影响因素研究
2021-09-05 05:56翔靳
吉林大学学报(信息科学版) 2021年3期
徐 翔靳 菁
(同济大学 艺术与传媒学院,上海 200000)
0 引 言
社交媒体带来信息的丰富性、便捷性的同时,也伴随着信息的窄化和局限性等异化现象。Sunstein[1]提出信息茧房的概念,即人们将自身桎梏于像蚕茧一般的茧房中,获得自身偏好的窄化信息。美国Pew研究中心[2]在2010年指出:互联网的一个主要忧虑就是人们会使用新科技使自己退却到狭窄的兴趣中,而那些偶发的新闻资讯有越来越少的趋势。英国Ofcom[3]研究表明这种焦虑在加剧。Gossart[4]认为社会化媒体中的信息茧房问题的危害仍有被低估的风险。就在学者们由于信息窄化问题而忧心忡忡时,也有部分学者认为信息视野窄化问题可能存在被夸大的风险。Flaxman等[5]认为,一方面社交媒体推荐新闻比个人访问行为具有更强烈的意识形态隔离,另一方面并没有充足证据表明社交媒体中的信息偶遇现象有所减少,社交媒体造成了更多了解相反观点的机会,即选择性接触的弱化。Moler等[6]研究表明,协同过滤算法推荐系统产生了比人工编辑把关更高的多样性。Bakshy等[7]在对1 010万Facebook用户的分析中发现,很难断定社交媒体用户是否由于在线而看到更少或更多的党派信息,用户而不是算法更应该为单一意识形态并且为“活在自己的世界”负责。
笔者对典型社交媒体之一的新浪微博展开实例分析,核心问题为微博的使用者,对微博使用程度的加深,是否会伴随其内容、信息视野的窄化现象,如果有,则这种窄化如何受到使用因素的影响。在抓取新浪微博7 825个有效样本及其数千万条帖子的基础上,对帖子内容进行向量化转换和客观计算,对于微博用户的信息窄化现象和效应进行测量及影响因素分析。
1 关于社交媒体信息窄化的回顾与分析
目前较多的文献对于信息窄化的相关理论诸如回音室效应、过滤气泡、意识形态隔离、群体极化、同质化、多样性等问题进行了验证与梳理。有研究将信息视野的窄化与群体同质化、观念壁垒的构筑相关联。Lawrence等[8]发现博客链接中的意识形态隔离,跨党派产生实质交流的机会很少。Himeboim等[9]通过Twitter上跨意识形态的接触程度描述10个有争议的政治话题,结果发现了高度自我联系的子群。Colleoni等[10]则通过机器学习和社会网络分析相结合的方法分析了Twitter上的政治同质性,认为社交媒体的回音室效应和公共领域功能同时存在。Conover等[11]使用聚类方法分析超过25万条推特消息,表明政治信息的转发网络和评论网络出现了隔离结构。高度模块化的社群图被分隔为簇状,这种簇状连接被认为是同质化甚至群体极化。Jacobson等[12]从党派竞争和选民投票的在线讨论角度测量了意见气候中过滤气泡的影响。他们发现带有政治色彩新闻媒体的信息资源重合率比较少,这意味着社交媒体上的政治讨论基于政治倾向,可能存在话语壁垒。而信息视域问题中的多样性常常被解读为意识形态上的交叉曝光,这种交叉曝光既包括话语层面的主题内容的多元,甚至包括语气(tone)极性[13]的不同,比如客观主观、正向负向情绪的二分。Nguyen等[14]则将内容的多样性表示为标签基因,从个体差异角度通过计算两部电影的欧氏距离对过滤气泡程度进行量化。
网络中的同质性、用户选择性、内容推荐和协同过滤、回音室效应等传播现象和机制的研究,为用户信息窄化的形成机理提供了有益参考。社交网络的用户存在着同质性的关系[15]。研究者采用LDA(Latent Dirichlet Allocation)方法描述用户兴趣,提出了支持Twitter中同质性存在的证据。用户避免接触异质性的个人,在同质性的接触的过程中使自己已有的观点不断强化。同质性网络中会带来某些信息传播速度加快[16]。研究发现,用户属性之间的趋同性与信息扩散之间存在相互作用[17]。Twitter用户间主题兴趣越相似则信息越容易在两个用户间扩散[18]。
随着数字和社交媒体的兴起,人们的信息环境通过社交网络的构建而进一步个性化。Gripsrud等[19]提出,社交网络的兴起、信息的碎片化和移动端的私人化,或许正逐步导致个人信息获取的窄化。选择性曝光不仅会使人们曝光于和预先态度相一致的信息,也使人们从政治中逃避和转向于娱乐信息[20]。结合用户个体特征层面,研究者从信息传播者个人特质、情境特征和用户的话题参与度、确定性偏好[21]、用户防御动机[22]、信息语境[23]、用户与话题的相似度等角度,探讨了其对网络用户信息窄化、信息过滤和信息局限性之间的作用关联。Bessi[24]对facebook中数万用户和超过300万条评论的分析认为,传播者人格特质和特定性格特征影响他们在facebook回音室中的参与。社交媒体中的话题在扩散上具有偏向性,这可能会作用于受众的内容偏向及其结构。用户在社交网络中的受众规模和他们关注主题的多样性之间存在着关联。
2 研究设计与研究方法
2.1 关于信息窄化的操作化界定与计算
为研究微博讨论中的信息窄化效应,首先需对信息窄化的内涵进行界定。本研究界定了在两个层面上的信息窄化:随着用户在微博使用中卷入程度的加深,首先,用户发布内容的自我相似度提高,在和自己先前发布内容进行比较的用户维度上,其发布的重复内容增多,自我差异化的程度降低;其次,用户发布内容的信息丰富度和类别均衡度降低,信息本身的类别分布和主题分布上,从更广泛地涉及到多种类型而转向更为偏移于少数局部类型。
需说明的是,本研究的对象是用户所发布、生产的内容,而不是其接收、阅读的内容。原因其一是用户所言、所说,与其所阅读、所关注的内容一样,也反映用户在信息、内容的宽窄与视野幅度;越是信息窄化的用户,其信息世界所言、所述同样也局限在相对狭窄的范围;其二是统一采用内容生产作为尺度,这些对象的采集更为便利和客观,不像用户所感、用户关注范围那样存在着一定程度的模糊性、或难以充分获得性,可使用统一的标准对这些明确可见的发布内容进行测量,提高测量的客观性与效度。
为描述信息动态分布情况,本研究将各个用户所抽的3 000条帖子,按发布时间顺序排序后,分为发布时间新和旧的两半,则单个用户的这两半帖子各有1 500条。划分两个时间切片,是因为(后半-前半)的结果,可以有效地体现用户在一段时间内的自我差值,计算简洁清晰。同时这些差值进行配对样本t检验,具有统计学意义。
2.1.1 内容之间的自我相似度、自我重复度提高
如回音室效应定义,较为封闭的系统中信息重复传播会使人们的观念不断放大,人们由此对那些反复传播的观念越来越深信不疑。这表明相似或重复的内容出现比率的提升意味着人们信息视野的窄化,个体发布内容越来越不关心外界的声音,而越来越转向内向型生长。因此,将内容的自我相似度、重复度视为测量窄化的维度之一。用主题相似度和语义相似度,描述自我重复度的提升与信息视野的窄化。
M1语义相似度(基于word2vec词嵌入方法的计算)
词向量(词嵌入)通过无监督训练方式将文本数据转化为低维实数向量,将语义、语法信息经过语言模型训练,投射到若干维的向量空间中。其结果不受文本的特征稀疏和知识库更新速度的制约,让意义相关或相似的词语在距离上更接近[25]。Word2vec是一种经典而重要的词向量/词嵌入方法,基于简单的MLP(Muti-Layer Perception)神经网络,训练速度快,效果也较理想。本研究运用Word2vec神经网络语言模型[26-27]计算每句的词向量,然后对帖子中每个词向量,等权平均后得到句子向量。需要说明的是,由于现有的中文语料库对于社交媒体文本训练的针对性较弱,自行训练采用26 GByte的中文语料库进行word2vec的词向量训练,内容来源包括媒体新闻库、网络论坛帖子、经典名著文本等。
一些研究表明,与使用递归或卷积的更为复杂的模型相比,基于简单词嵌入的架构表现出更好的性能[28-29]。Shen等[30]的研究直接将简单词向量模型(SWEM:Simple Word Embedding base Model)与现有的递归和卷积网络进行了比较,结果表明,在大多数情况下,SWEM表现出更高的性能。
在得到所有帖子句向量在300维空间中的分布后,基于余弦相似度和类平均法的衡量方式,采用

的方法计算前一半或后一半的i条帖子内部的总体相似度、自我雷同情况,与前文相同,该值S值越大,表明总体上帖子相互的相似、相近度越高。对每个用户的帖子,根据S得到其在前后两半时间中的差值S′。该差值S′越大,表明新一半内容的自我相似度、自我重复度比旧一半的更高,也即更趋于窄化。
2.1.2 信息、内容在类别分布上的丰富度降低
从内容维度出发评价用户发布信息的丰富度、多元度,文本蕴含的信息越丰富,涵盖语义越广泛,越说明用户并没有陷入信息窄化情况中。反之如果信息丰富度下降,也可以一定程度上说明信息视野的窄化。
M2类别丰富度(基于k-means聚类和香农熵的计算)
在对文本进行句向量处理后,利用k-means聚类方法识别帖子所属的内容类别。k-means算法是一种典型而常用的无监督聚类算法,具有算法思想简单、收敛速度快、局部搜索能力强等特点。通过k-means对文本分类的方法,已经广泛应用于新闻自动分类、热点词汇挖掘等领域。还有学者强调应用于文本聚类的基于词性和词共现的特征选择方法[31]。
将所有的23 475 000条样本帖子根据其word2vec的向量,基于k-means方法聚为150类,从而计算得到每个用户在150类内容上的分布概率,然后通过香农熵计算每条帖子蕴含的信息丰富度,计算方法为

通过新一半减旧一半的香农熵的差值,反映用户在内容的类别丰富度的变化态势。这个差值越大,则表明新一半内容较旧一半内容的分布均衡程度越高;反之亦然。
结合上述内涵,基于对用户所发布的内容的计算与考察,基本假设及其子假设如下:
H:用户随着微博使用程度的增加,存在着信息窄化的现象与趋势;
H1:用户随着微博使用程度的增加,用户内容的自我相似度提高;
H1.1:用户对于微博的使用程度,与其发布内容在语义上的自我相似度(基于word2vec句向量的计算),呈显著的正相关关系;
H2:用户随着微博使用程度的增加,用户的内容丰富度降低;
H2.1:用户对于微博的使用程度,与其发布内容在语义上的主题均衡度(基于word2vec句向量的聚类),呈显著的负相关关系。
2.2 用户使用程度
用户所卷入社交网络的程度不同,与其发布帖子的文本特质变化可能存在某种关联,因此笔者需要将用户进行分层,探究不同用户群体的社交网络使用程度。按照卷入不同,可以分成使用度、活跃度、影响度3个层面。
一是用户对微博的接受、跟进的历史情况和卷入程度,用用户在微博的注册时长表示。二是用户在微博这个媒介空间中有充分的使用频率、活跃性以及在此媒体中的实际使用行为。用以下微博平台自身的官方指标进行衡量:1)用户的微博账户等级;2)用户的微博账户经验值;3)用户的关注者数量。三是还需要考量用户的使用效果。本处采取用户的最为直观可见的指标之一—— 粉丝数进行衡量。这也体现用户的影响力。微博空间中高度的卷入、对其他用户有吸引力的内容、有效的社交网络行为、活跃的投入等使用因素,都与其可能获得的粉丝数、影响力之间存在着关联。
上述3个层面,是分别递进的层面,最先的媒介接触和媒介卷入(注册时长)→媒介使用的活性(微博账户等级、微博账户经验值、关注者数等)→媒介使用的实际效果和使用影响(粉丝数)。选这3个方面的维度及其可操作性的指标,也具有较好经验直观性、非黑箱化的易理解性。
2.3 样本选择和抓取
首先,课题组运用开源网页文本抓取工具“八爪鱼”,以及自行用python和selenium编写的动态网页抓取程序,抓取了10 037位用户及其发布的34 892 987条微博帖子,以及这个用户的个体指标,包括用户的注册日期、微博账户官方经验值、微博账户等级、关注其他账号数量、粉丝数量等原始数据。数据抓取完毕的时间是2018年11月,经过一年对大规模数据的清洗、分析和反复论证得到研究结果。采用python编程语言,对抓取到的内容、数据进行文本清洗、预处理。由于每个用户抓取到的帖子数量不一致,统一对每个用户随机选取3 000条帖子。最后剩下的发微博数大于或等于3 000的用户数量为7 825个。
对用户指标的连续性数值进行分箱化,增强结果的宏观稳定性。集中于对微博用户的分层,将样本按照不同指标分成30个层级。按照指标值的大小序号,分为同等用户数量的30个层级,每个层级的默认用户数为int(7 825/30);部分指标不足以分30层,则保留合并相同的值到同一层。
这种对用户的分层分析,对用户群从定序尺度进行分析,而非定距或定比尺度,规避不同指标量纲的不统一、差异过大等问题,并增强结果的稳定性。其外,定序尺度的分层级有助于对用户样本进行相等人数规模的分层,从而避免人数过多或过少的层之间的不均衡,使不同层次之间的比较标准更为统一。同时也增强社交网络用户在更大尺度上的整体效应和结构,寻求更为宏观尺度的结果,减少个体的过大随机噪音和扰动。
用于分析和分层的指标如表1所示。各用户层级的分布广泛和覆盖均衡,所抽取得到的用户及其分层分析,具有良好的覆盖面和代表性。微博账户等级、经验值指标下,层级不满30层是由于某一层内差异化的数量过少,此情况下,数值相同的样本尽管数量可能比其他一些层多,但依然分到同一层,所以会调整、减少分层数量。
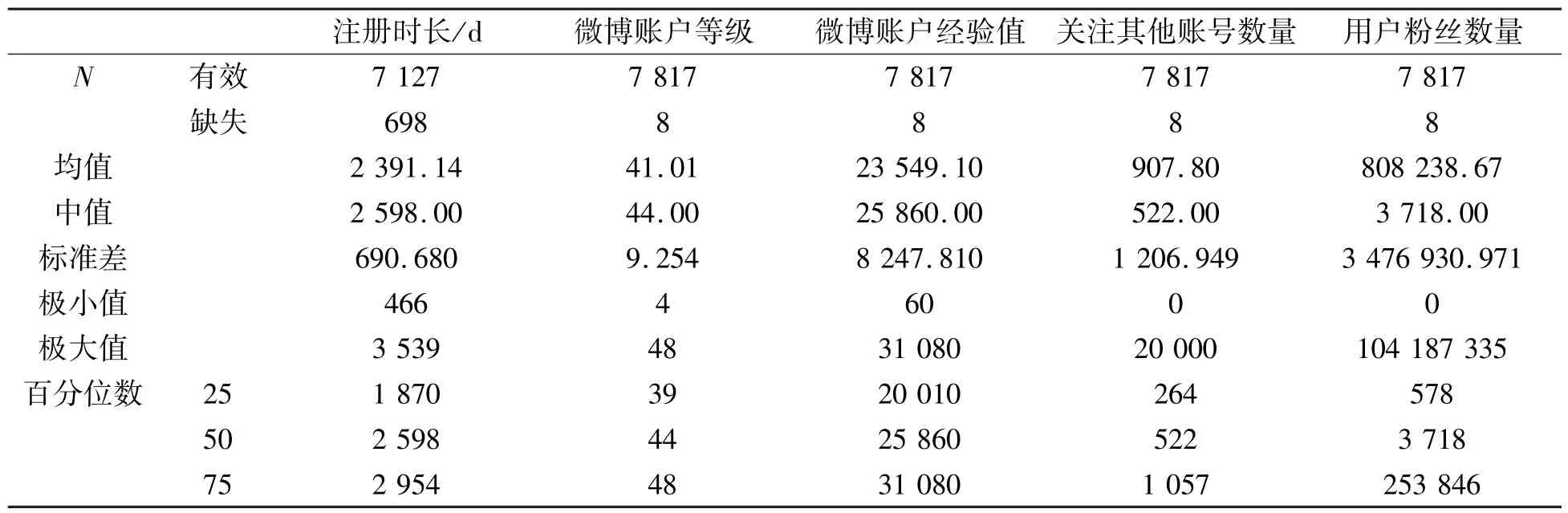
表1 微博样本用户分析的各指标Tab.1 Indicators in users analysis in Sina Weibo samples
3 分析结果
从前文所阐述信息窄化的内涵及其界定方法出发,围绕自我相似度和信息丰富度两个层面进行,集中于H1、H2及其各自的子假设。
为描述动态维度的信息视域变化,采用的方法是将帖子按照用户发布内容的时间顺序分为前后两半,经过将较新一半的发布内容计算结果减去较旧一半发布内容的计算结果,得到的差值是否显著大于0将被视作较新和较旧结果产生明显变化的重要分野。需要说明的是,统一较新和较旧的数据量口径都设置为1 500条,同一用户同样数据量在发布内容在纵向时间上的比较排除了其他干扰,更具有可比性与科学性。
3.1 信息自我相似度的动态测量结果及其与用户使用层级的相关性
本部分是对H1的检验。
语义相似度与用户使用层级的关联。首先,计算用户帖子的语义相似度,并继而计算得到新旧一半帖子的差值。在对Word2vec_CBOW句向量结果按照贴子发布时间分布后,从较新减去较旧的差值表现看,用户随着使用层级的增加,自我相似度的上升趋势甚至更加明显(见图1)。
图1 用户新旧文本内部相似度的差值与其微博使用指标Fig.1 The difference between the individual similarity of the user's new and old text and its Weibo usage indicator
将这种趋势进行统计学的相关性检验,语义相似度与用户对社交网络的使用程度产生了更加强烈的关联(见表2)。用户活跃程度与自我语义相似度的关联甚至达0.91,产生了较为强烈的线性拟合结果。说明用户在社交网络中的使用程度与所发布信息的自我相似度之间,的确存在显著乃至较强的线性正相关。

表2 用户新旧文本内部相似度的差值与其微博使用指标的相关分析(word2vec)Tab.2 Correlation analysis of the difference between the individual similarity of users'old and new texts and their Weibo usage indicators(word2vec)
3.2 信息丰富度的动态测量结果及其与用户使用层级的相关性
本部分是对H2的检验。
类别丰富度与用户使用层级的关联。对信息丰富度的检测,使用较新发布内容与较旧发布内容差值比较的方法,发现通过k-means聚类结果得到的类别丰富度差值中,位于0以上的结果多在图2中的子图左侧即用户使用层级的前半段,这种情况下表示新发布内容类别比旧的内容更加丰富、更为广泛和均衡。但随着用户使用层级的增加,逐渐出现和增多0以下的结果,即新发布的信息丰富度、广泛和均衡程度不如较旧的帖子。图2描述了用户层级增加与新旧两半计算结果差值变化曲线之间的关系;新的信息其丰富度不如旧发布内容的丰富度的情况,多存在于社交媒体使用层级较深的用户之中。

图2 用户新旧文本聚类后信息丰富度差值与其微博使用指标(word2vec与k-means聚类)Fig.2 The difference in information richness of users'new and old texts after clustering and their Weibo usage indicators
线性相关关系的统计检验显示(见表3),Word2vec方法得到的帖子向量,经k-means聚类后查看香农熵值以衡量文本包含的信息丰富度,结果比较显著地说明,随着用户使用的层级增加,用户的信息发布类别熵值呈现比较明显的下降趋势,负相关系数甚至达到了-0.92,这与信息视野窄化中的丰富度降低相对应。

表3 用户新旧文本聚类后信息丰富度差值与其微博使用指标的相关分析(word2vec与k-means聚类)Tab.3 Correlation analysis between the difference in information richness of users'new and old texts and their Weibo usage indicators after clustering(Word2vec and k-means clustering)
4 结 论
1)通过神经网络词向量、大规模的统计文本挖掘、前后折半t检验等多种新方法的复合使用,测量和分析微博使用中的信息窄化现象,通过主题分布和信息类型的不同维度,对信息窄化从动态变化角度出发而测量新旧差值的配对表现。新方法的使用在关于社交网络的信息窄化的实证分析中,有一定的新意,以及针对本问题的切实有效性。2)不是一般性地验证微博用户是不会发生信息窄化,而是在检验信息窄化存在的基础上,明确地聚焦于社交网络的媒介使用与这种窄化的关系。3)未从智能推荐和算法、社会网络等常见角度探讨用户的信息窄化,而是明确分析社交网络使用度、活跃度、影响度的现实指标所伴随的信息窄化,而这些具体的指标有助于更为清晰而明确地掌握社交网络使用和用户信息窄化的关系及其作用程度。
H1、H2均显著地通过了检验。这种窄化具有系统性和稳定性的效应机制。各个子假设的分析结果一致地显示,微博的使用日趋加深中,伴随着用户信息视野趋于窄化的现象。主要体现在用户其自我相似度的增加以及信息丰富度的降低两方面。随着用户使用社交网络程度的增加,它与信息窄化程度的相关关系显著,在部分指标下其斯皮尔曼相关系数达到了0.9以上。

表4 用户信息窄化和微博使用程度的关联性—— 以皮尔森相关系数为例Tab.4 The correlation between information narrowing and the degree of Weibo usage:taking Pearson's correlation coefficient as an example
5 结 语
笔者通过Word2vec和k-means两种方法对社交媒体文本进行挖掘,以自我相似度和信息丰富度两个层面刻画信息窄化的程度,通过区分时间轴上的新旧文本,以动态维度衡量用户生产内容中的变化。结果表明上述两个层面体现的信息窄化均和用户的社交网络使用度、活跃度、影响度等使用程度指标具有显著关系。社交网络带来大量的信息汪洋,信息茧房聚焦点,多数是作为被动接受的受众如何被局限和束缚,例如推荐算法、过滤气泡等各种因素的作用。然而从单纯的受众层面转向更为复杂的使用者层面,同样也潜藏着在信息增长中的张力与悖论。将用户的微博使用程度作为影响因素与其信息窄化程度建立联系进行考察显示,不仅作为被信息世界所包裹的受众角色存在着信息茧房的风险;具有一定主动性的使用者而非单纯意义上的受众,同样也存在着这种社交网络用户茧房化、信息窄化的现实态势。
猜你喜欢
航天工业管理(2020年9期)2020-12-28
高师理科学刊(2020年2期)2020-11-26
军事运筹与系统工程(2020年1期)2020-09-11
廉政瞭望(2019年5期)2019-06-10
中成药(2017年6期)2017-06-13
小雪花·成长指南(2016年11期)2016-12-07
系统工程与电子技术(2016年2期)2016-04-16
电子科技(2015年11期)2015-03-06
安徽工业大学学报(自然科学版)(2014年4期)2014-07-11
小品文选刊(2009年7期)2009-05-25
