
基于特征选择和GA-BP神经网络的多源遥感农田土壤水分反演
2021-09-04 12:01赵建辉张晨阳王颖琳
农业工程学报 2021年11期
赵建辉,张晨阳,闵 林,李 宁,王颖琳
(1.河南大学计算机与信息工程学院,开封 475004;2.河南省大数据分析与处理重点实验室,开封 475004;3.河南省智能技术与应用工程技术研究中心,开封 475004;4.河南大学信息化管理办公室,开封 475004)
0 引 言
土壤水分对于植被生长、农业生产和生态系统循环具有重要影响。土壤水分监测在气象、水文、农业等多学科中发挥着重要的作用[1-2]。在现代农业中,土壤水分更是不可或缺的重要指标,全面监测土壤水分可以对农作物产量、旱情墒情和农作物长势起到指导和决定性作用。因此,研究农作物覆盖下的地表土壤水分分布情况具有重要意义[3-5]。
在现有土壤水分监测方法中,遥感技术已成为一种重要的监测手段,光学遥感和合成孔径雷达(Synthetic Aperture Radar,SAR)微波遥感在土壤水分监测中得到越来越多的应用[6-8]。韩玲等[9]使用ASAR双极化雷达数据,利用高级积分方程模型(Advanced Integral Equation Model,AIEM)模拟地表后向散射,提出一种组合粗糙度,构建土壤水分反演模型,并通过粒子群算法求解得到较为准确的土壤水分值。杨贵军等[10]使用 Radarsat-2全极化数据,将水云模型中植被参数改为雷达植被指数,构建改进的水云模型,得到精度较高的冬小麦覆盖下的地表土壤水分反演结果。王树果等[11]采用Sentinel-1 SAR数据和Landsat8多光谱数据,结合Oh模型、水云模型以及复型洗牌全局优化算法,发展了一种土壤水分、植被含水量和地表粗糙度协同反演方案,可以得到与地面实测情况较一致的反演结果。地表参数与植被指数、雷达后向散射系数之间存在不易描述的非线性关系,为了提高反演精度,往往导致土壤水分反演模型参数众多、结构复杂。神经网络具有极强的非线性拟合能力,并且可以自主学习,在解决土壤水分反演过程中的非线性问题时得到了越来越多的应用。韩颖娟等[12]从风云卫星中获取温度和波段信息,构建卷积神经网络反演地表土壤湿度,试验结果精度较高。郭交等[13]使用 Sentinel-1和Sentinel-2多源遥感数据,利用支持向量回归(Support Vector Regression,SVR)和广义神经网络(Generalized Regression Neural Network,GRNN)反演土壤水分,收敛速度快,精度高。余凡等[14]使用Envisat ASAR数据和TM数据,将双极化数据与光学遥感数据相结合,采用遗传算法(Genetic Algorithm,GA)优化的BP神经网络反演作物覆盖区土壤水分,反演结果与实际情况基本吻合。
在利用神经网络进行土壤水分反演时,选择合适规模的训练数据非常重要,过多的网络输入数据会导致收敛速度变慢,对反演精度产生负面影响。对特征集合进行降维可以有效提高预测准确性,以便于构造效率更高、消耗更低的预测模型。实现特征降维有特征选择和特征抽取 2种方式[15]。差分进化特征选择(Differential Evolution Feature Selection,DEFS)算法是一种行之有效的特征选择方法,可以从数据集中筛选出最优特征子集。Khushaba等[16]将DEFS技术应用于人类脑电图的分类,并与其他降维技术进行了比较,结果表明该算法在求解最优性、内存需求和计算代价等方面具有重要意义。主成分分析(Principal Component Analysis,PCA)是一种常见的特征抽取方法,可以将数据集映射到低维空间,对数据进一步压缩,剔除冗余数据。王雅婷[17]从Radarsat-2数据中提取12个极化特征参数,利用PCA方法进行降维处理,然后再进行支持向量回归建模,取得了较好的反演精度。
本文结合Sentinel-1微波遥感数据和Sentinel-2光学遥感数据,经过预处理后从中提取 21个特征参数,使用DEFS算法对特征数据进行筛选,得到一定数量的最优特征子集,之后使用PCA算法再次进行降维;然后构建经过GA算法优化的BP神经网络(简称GA-BP神经网络),使用经过特征降维后的数据集和部分实测数据对网络进行训练,并使用训练好的网络对研究区的土壤水分进行反演;最后利用实测数据对反演结果精度进行对比验证。
1 研究区与数据源
1.1 研究区概况
研究区位于河南省开封市祥符区,面积约900 km2,大致范围为 34°36'~34°51'N,114°30'~114°45'E,如图1所示。研究区为黄河冲积平原的一部分,地势平坦,属温带大陆性季风气候,冬季寒冷干燥,夏季高温多雨,平均海拔65 m,年平均气温14 ℃,年降水量628 mm,无霜期214 d。主要种植冬小麦、玉米、棉花等作物,其中冬小麦的生长周期为8个月,一般10月播种,次年6月收获。冬小麦在不同物候期的生物量和生物特征不同,地表土壤水分在不同时间、不同地点也有较大差异。试验处于冬小麦的出苗期、分蘖期和越冬期,这 3个物候期内冬小麦植株较小,植被高度及覆盖度均较低,地面植被覆盖情况变化不大,且农田已不再发生犁地、播种等影响地表粗糙度的田间活动。因此,本文针对这 3个相近的物候期进行统一建模和分析,使用这 3个物候期的遥感数据和地面实测数据进行神经网络训练、土壤水分反演与结果精度评价。
1.2 数据源及预处理
1.2.1 地面实测数据
土壤水分遥感反演研究中使用的地面实测土壤水分数据主要有两种来源,一种是来源于研究区内的地面观测站点或自动观测网络[11-12,17-18],此类实测数据获取方便且通常采集频率较高、采集数量较大,以此为基础开展的土壤水分反演研究中反演算法或反演模型的可选种类较多、选择空间较大;另一种是来源于传统的人工测量方法[5-6,13-14],在卫星过境日期依靠人工进行地面采样测量,此类实测数据往往获取困难且通常采集次数有限、采集数量较少,以此为基础开展的土壤水分反演研究中反演算法或反演模型的可选种类相对较少、选择空间相对较小。本文研究区内没有地面观测站点和自动观测网络,因此采用人工测量方法来获取地面实测数据,并开展基于小样本量实测数据的土壤水分反演研究。
在Sentinel-1A卫星过境的时间,同步进行3次野外实地考察和采样,现场采集土壤水分值和经纬度坐标。研究区地面共设置20个采样点,采样点分布如图1b和图1c所示。
3次采样共采集60组实测数据,去除2个异常点后,共有58组有效实测数据用于后续试验。野外采样过程中使用TDR350土壤水分仪测量农田表层土壤体积含水量,探针长度为3.8 cm,在每个采样点以十字测量法测5个点的土壤水分值,以 5个测量点的土壤水分平均值作为该采样点的最终土壤水分实测值。使用室外手持式集思宝UG905定位仪(定位精度1~3 m)定位采样点,选用WGS84坐标系记录采样点坐标。
1.2.2 遥感数据
本文使用欧空局(European Space Agency,ESA)提供的遥感数据,如表1所示。使用欧空局研发的哨兵应用平台(SentiNel Application Platform,SNAP)软件对所获取的SAR图像进行辐射定标、多视、Refined Lee滤波和地形校正等预处理操作。根据Sentinel-1A SAR图像获取日期和是否出现云雾雨等影响土壤水分大幅度波动的天气因素,选择相近日期的3景准同步光学图像作为试验数据。在SNAP软件中使用Sen2Cor插件对所获取的多光谱成像仪(Multi Spectral Image,MSI)图像进行大气校正等预处理操作。

表1 遥感数据Table 1 Remote sensing data
2 研究方法
2.1 特征参数提取
SAR通过向地物发射微波波束和接收回波信号来探测地物特性,波长、入射角和极化方式等雷达系统参数和目标地物的介电常数、物理结构等特征参数对雷达信息具有直接的影响,从雷达数据中提取可以表征地物特性的特征信息是雷达遥感反演的基础。
2.1.1 后向散射系数
土壤水分反演时主动微波遥感主要通过后向散射系数所反映的信息进行反演。依据采样点的经纬度,从预处理之后的 SAR数据中提取相应位置的入射角(θ)、VV极化后向散射系数()、VH极化后向散射系数()作为后续试验的特征参数。由于cos(θ)和sin(θ)与土壤湿度也存在一定的关系[18],并且在雷达入射角一定的情况下其后向散射系数仅与地表粗糙度有关[19],所以将cos(θ)、sin(θ)和也作为特征参数,并将加入其中,从 SAR数据中提取共计 9个与雷达后向散射系数相关的特征参数。
2.1.2 极化特征参数
极化分解可以将地物较为复杂的散射过程分解成若干简单的散射机理。通过极化分解的方式,可以从 SAR遥感数据中提取更多的特征参数[20]。对双极化Sentine1-1A数据采用H/A/α分解,对目标地物的相干矩阵或者协方差矩阵进行特征值分解,可以从中提取出表征目标散射极化程度的极化熵H,表征目标散射机理的平均散射角α,极化熵的补充参数—反熵A,以及可以表示该散射机制强度的特征值λ1和λ2[21-22],从SAR数据中提取共计5个极化特征参数。
2.1.3 植被指数及地表粗糙度
植被和地表粗糙度对地表散射信息具有直接的影响,土壤水分反演需要有效抑制植被覆盖和表面粗糙度的影响。光学遥感数据中可以提取的特征参数主要为植被指数。植被指数(Vegetation Index, VI)是2个或多个波长范围内的地物反射率组合运算,以增强植被某一特性或者细节。目前遥感领域提出的植被指数有100多种[23],受限于传感器类型和所用波段组合,不同的植被指数有不同的波段适用范围和应用领域。基于Sentinel-2A携带的多光谱成像仪所提供的多波段数据,结合本研究区的实际植被覆盖情况,本试验最终选取了土壤水分反演研究中常用的 6个植被指数[24-26],包括归一化差异植被指数(Normalized Difference Vegetation Index, NDVI)、归一化差异水分指数(Normalized Difference Water Index,NDWI)、比值植被指数(Ratio Vegetation Index, RVI)、水分胁迫指数(Moisture Stress Index, MSI)、水波段指数(Water Band Index, WBI)和融合植被指数(Fusion Vegetation Index, FVI)等,其计算公式如公式(1)至公式(6)所示。
式中ρ842、ρ665、ρ1610、ρ865、ρ945分别表示 Sentinel-2 数据中对应中心波长为842、665、1 610、865、945 nm的波段值。
使用Sentinel-1A数据计算地表组合粗糙度[27],如公式(7)所示,其中使用非线性最小二乘法和线性回归法拟合获得C波段的Av和Bv,如公式(8)和公式(9)所示。
式中Zs为组合粗糙度,Av和Bv是只与入射角有关的系数。
2.2 差分进化特征选择与主成分分析
在使用神经网络进行预测时,过多的输入数据可能会造成数据灾难,影响神经网络的学习,通常会采用特征选择和特征抽取这两种方法将数据降到更低维度,达到去除冗余数据的目的。特征选择是单纯地从提取到的所有特征中有依据地选择较为重要的部分特征作为训练集特征,被选择的特征可以大概表征全体数据的信息,特征在选择前后并不改变本身值的大小。而特征抽取的本质上是从一个维度空间映射到另一个维度空间,映射过程相当于一个黑盒,没有确定的筛选依据,而是借助数学工具来进行降维,特征抽取后的特征失去了本身的物理意义,相应特征值也会改变。
本文使用 DEFS算法[16]对所提取的特征参数进行初步筛选。算法的第一步是从初始种群生成新的种群向量;第二步是变异操作,随机选取群体中的两个不同个体,通过差分进化实现个体突变,将其向量差进行缩放后,对要变异的个体执行向量合成;第三步是交叉操作,变异向量与原始矩阵中占据该位置的原向量交叉,这个操作的结果称为试验向量。新群体中的相应位置将包含试验向量或原始目标向量,这取决于其中哪一个达到了更高的适应度;第四步是去除冗余,使用轮盘赌算法[28],通过与每个特征相关的分布因子计算单个特征的概率,来去除多余向量,获得新种群。特征分布因子fi由公式(10)给出:
式中α1、α2是常数,ε是为了避免出现分母为零的情况而设置的一个极小的数,PDi是从高于平均精度的子集中计算到的正分布因子,NDi则恰恰相反,是从低于平均精度的子集中计算得到的负分布因子。
本文利用PCA方法对特征参数集合进行降维。PCA是数据分析中的一种重要方式,可以将数据中主要的特征变量抽取出来,常用于机器学习中对高维数据的降维。PCA将高维数据集映射到低维数据集,同时尽可能地保留原有信息。高维数据集中,各向量具有相关性,低维数据集中则线性无关,这样便可以消除掉高维数据集中相互重叠的信息[29-30]。DEFS和PCA算法流程如图2所示。
2.3 构建GA-BP神经网络
BP神经网络已在许多领域得到广泛应用,但存在易陷入局部极小、依赖于设计结构等缺陷,有时无法找到全局最优值。遗传算法虽然不具备自学习能力,但具有全局寻优能力。因此,利用遗传算法对神经网络进行优化可以改善神经网络的缺点,既发挥了神经网络非线性映射能力和遗传算法的全局寻优能力,又加快了神经网络的学习速度,综合提高了整个预测模型的精确度和拟合能力[31]。GA-BP神经网络的构建流程大致分为2步:
1)构建BP神经网络模型
建立包括输入层、隐藏层和输出层的BP网络。确定每层神经元的个数、传递函数、BP网络的具体参数和训练次数。隐含层节点数s参照Kolmogorov定理[25]由公式(11)确定。
式中m为输入层个数,n为输出层个数。
2)使用GA算法优化BP神经网络
遗传算法优化 BP神经网络的目的是通过遗传算法得到更合适的网络初始权值和阈值。首先对需要选择的特征进行编号,将每个特征视为一个基因个体,使用初始化的BP神经网络的预测误差作为该个体的适应度值,通过选择、交叉、变异操作寻找最优个体,即最优的BP神经网络初始权值和阈值[32]。设置遗传算法的初始参数时,交叉概率和变异概率一般在0到1之间取值。
本文使用遗传算法优化BP神经网络具体流程如图3所示。
2.4 基于特征选择和GA-BP神经网络的土壤水分反演
为了消除冗余特征对土壤水分反演结果精度造成的影响,本文提出了一种基于特征选择和GA-BP神经网络的土壤水分反演方法,技术路线如图4所示,主要步骤如下:
1)对Sentinel-1和Sentinel-2数据进行预处理,从中提取前文所述的21个特征参数,并对所提取的特征参数进行编号,如表2所示。

表2 特征参数Table 2 Characteristic parameters
土壤湿度越大,后向散射系数与sin(θ)之间的相关性越高;土壤湿度越小,后向散射系数与cos(θ)之间的相关性越高[18]。在入射角一定的情况下,后向散射系数随体积含水量的增大而增大,为不同极化后向散射系数的4种组合方式。除反熵A与土壤水分呈负相关外,极化熵H、平均散射角α、特征值λ1和λ2与土壤水分都呈正相关[17]。6个植被指数均与植被覆盖程度呈正相关。
2)使用DEFS算法从21个特征参数中选出10个特征参数作为最优特征子集,包括NDVI、NDWI、WBI、FVI、α和H等参数。
在进行特征选择时,所选特征参数所含信息量要大,并且特征参数之间的相关性要小。在使用 DEFS算法选择最优特征子集的过程中,相关性较强的特征参数会因为相互之间存在重复的信息量而被去除掉,信息含量多且相关性较小的特征参数会予以保留。
3)使用 PCA方法对最优特征子集进一步降维。由于无法确定最合适的最优特征子集的个数,所以最优特征子集中仍可能冗余。使用PCA方法对特征值的累计贡献率进行计算,发现前 8个主成分可以包含原有数据集信息的99.99%左右,所以选择前8个主成分组成的特征矩阵作为后续的神经网络输入。
4)构建并使用 GA-BP神经网络对土壤水分进行反演。本文的样本数据量较小,而GA-BP神经网络可基于小样本数据进行训练和反演,经过调参后可以保证模型的训练和反演精度。将58个采样点实测土壤水分值随机分为两组,其中50个用于神经网络训练,8个用于有效性验证和精度评价。设置神经网络的各个参数:输入层个数为8;输出层为1;根据公式(11)计算出隐含层的个数为5;学习率为0.1;迭代次数为5 000。设置遗传算法的初始参数:迭代次数为 100;种群规模为 60;交叉概率为0.4;变异概率为0.1。
2.5 试验方案精度评价
为了验证本文所提方法的有效性,以河南省开封市祥符区冬小麦农田为研究区域,开展土壤水分反演试验,并以GA-BP土壤水分反演模型[14]作为参照,对方法性能进行了对比分析。
试验设置了3种方案:方案一采用GA-BP土壤水分反演模型,直接使用21个特征参数作为神经网络输入参数进行土壤水分反演;方案二在方案一的基础上增加了DEFS算法,先对21个特征参数进行特征选择,再使用GA-BP土壤水分反演模型进行土壤水分反演;方案三为本文所提方法,在方案二的基础上再增加PCA方法,对DEFS特征选择后的最优特征子集进行进一步降维优化,再使用GA-BP土壤水分反演模型进行土壤水分反演。采用偏差(Bias)、均方根误差(Root Mean Square Error,RMSE)、无偏均方根误差(unbiased Root Mean Square Error,ubRMSE)、决定系数R2共4个评价指标对反演精度进行评价。为了降低试验结果偶发性,试验结果均为多次试验后求取的平均数。
3 结果与分析
表3为不同试验方案反演结果精度对比,图5为不同试验方案土壤水分反演结果与实测值对比。由表3和图5试验结果可以看出,本文所提方法的反演值和实测值更为接近,Bias、RMSE和 ubRMSE比方案一、方案二更小,同时R2更高。并且在方案二中,仅使用 DEFS算法进行特征选择后也比方案一的反演结果精度更高。本文方法反演结果的决定系数为 0.789 3,均方根误差为0.028 7 cm3/cm3,相比单纯使用GA-BP神经网络,加入DEFS和PCA之后决定系数提高了0.215 7,同时均方根误差降低了0.029 5 cm3/cm3。试验结果表明,本文所提方法可以有效去除多余特征参数,提高土壤水分反演精度。
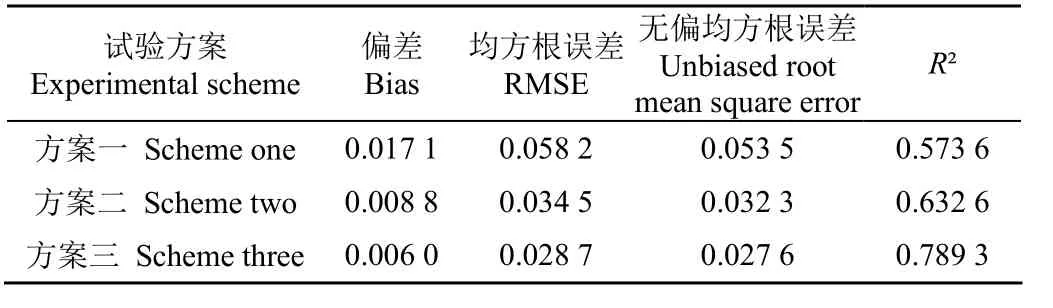
表3 反演结果精度对比Table 3 Accuracy comparison of inversion results
使用本文所提方法获得的研究区农田土壤水分反演结果如图6所示,其中为了去除非农田区域对土壤水分反演的影响、更好地显示土壤水分分布情况,试验中滤除了建筑、道路、河流等非农田区域,如图6中白色区域所示。结果显示2019年10月18日土壤水分反演值整体较高,均值为0.155 cm3/cm3,主要是由于10月上旬研究区多次降雨,土壤比较湿润。10月30日研究区土壤水分反演值均值为0.136 cm3/cm3,比10月18日略低,与10月下旬天气晴朗关系较大。2019年12月29日反演结果整体较干旱,均值为0.070 cm3/cm3,主要是因为入冬后温度有时会降到 0 ℃以下,低温会导致土壤含水量降低,寒风也会助长土壤水分的蒸发。经分析可知,这 3个日期的土壤水分反演结果与实际天气情况比较吻合。此外,3个日期的采样点土壤水分实测数据均值分别为0.162、0.136和0.065 cm3/cm3,反演结果与采样点实测土壤水分值频率分布较为一致,进一步验证了本文所提方法的有效性。
4 结 论
本文基于Sentinel-1和Sentinel-2多源遥感数据,提取了21个与土壤含水量相关的特征参数,经过差分进化特征选择(DEFS)和主成分分析(PCA)算法对特征参数进行筛选和降维后,结合地面实测数据,使用 GA-BP神经网络反演土壤水分,并探讨了DEFS和PCA算法对土壤水分反演精度的影响,主要结论如下:
1)不同特征参数所含的信息存在不同程度的重复和冗余,DEFS算法可以去除掉相关性较大、重复性较高的特征参数,保留信息含量多且相关性较小的特征参数。
2)在使用GA-BP神经网络反演土壤水分的过程中,多余的特征参数会影响土壤水分反演结果的精度,组合使用DEFS和PCA算法可以剔除冗余特征参数,有效提高反演精度。本文方法反演结果的决定系数为 0.789 3,均方根误差为0.028 7 cm3/cm3,相比单纯使用GA-BP神经网络,加入DEFS和PCA之后决定系数提高了0.215 7,同时均方根误差降低了0.029 5 cm3/cm3。
虽然本文试验考虑了地表粗糙度,但由于缺乏地面实测粗糙度数据,所以试验中参考已有研究成果使用了从SAR数据中提取的地表粗糙度参数,这可能会影响反演精度。此外,相比于本文所用的双极化SAR数据,全极化SAR数据中包含更多与土壤湿度相关的信息,可以提取更多的特征参数,使用全极化SAR数据有可能会进一步提高反演精度。在今后的研究中,可以考虑针对以上因素对试验进行改进。
猜你喜欢
农业工程学报(2022年10期)2022-08-22
农业工程学报(2022年5期)2022-06-22
舰船科学技术(2022年10期)2022-06-17
水土保持学报(2022年3期)2022-05-26
现代农村科技(2021年11期)2021-11-05
现代电子技术(2016年23期)2017-01-12
电子技术与软件工程(2016年22期)2016-12-26
电脑知识与技术(2016年25期)2016-11-16
科技视界(2016年20期)2016-09-29
电脑知识与技术(2016年15期)2016-07-04
