
基于LSTM的钢铁厂清循环系统浓缩倍数与腐蚀速率预测
2021-08-31 00:52张雯莹代英宸张云龙
冶金动力 2021年4期
张雯莹,代英宸,张云龙
(1.上海应用技术大学理学院,上海 201418;2.宝山钢铁股份有限公司能源环保部,上海 200941)
前言
钢铁是人类赖以生存的重要物质之一,我国粗钢产量已多年稳居世界第一位。同时,钢铁行业也是典型的高耗水行业,其中主要用水形式为循环冷却水。所谓循环冷却水即冷却水通过生产设施,带走其中的热量,从而保证生产正常运行,升温后的冷却水通过冷却设施及净化系统处理后,继续重复送入设备使用。循环冷却水系统可分为敞开式与密闭式两种,其中敞开式循环冷却水系统又可进一步分为清循环系统和浊循环系统,经过生产设施后,水质未发生明显变化,仅温度上升的为清循环系统;经生产设施后,水质发生明显变化,需要进一步净化处理的为浊循环系统。钢铁厂清循环系统主要用户包括:高炉风口、加热炉炉体、轧机设备以及换热设备等。
循环冷却水形式的最大意义在于循环使用、减少水耗,由于循环水的不断重复利用,水中盐类容易浓缩,使循环水水质不断恶化,从而产生腐蚀、结垢、粘泥等水质异常,进而影响设备寿命与安全、经济。早期,学者通过对特定参数计算来判断循环水水质的倾向性,如Langelier、Ryznar、Puckorius 指数等[1]。随着近年来人工智能,特别是神经网络模型的不断发展,众多学者利用神经网络模型分析并预测循环冷却水腐蚀这类多输入、非线性问题。如Suleiman 等人[2]首先利用神经网络研究了CO2腐蚀预测;曹生现等人[3]通过改进后小波神经网络对腐蚀速率进行预测;董超等人[4]利用改进后的LSSVM模型对腐蚀速率进行预测。
由于清循环系统浓缩倍数与腐蚀速率,受到季节性环境影响较大,如气温变化对循环水热负荷与蒸发损失的影响;丰水期、枯水期对补水水质的影响等,浓缩倍数与腐蚀速率事实上具有一定的时间序列属性。因此,本文提出基于长短期记忆网络(Long Short Term Memory Network,LSTM)的钢铁厂清循环系统浓缩倍数与腐蚀速率预测。通过对浓缩倍数的有效预测,能够有针对性地根据当前预测浓缩倍数指导循环水系统补排水量,降低水耗;通过对腐蚀速率的有效预测,建立此类常规分析具有滞后性数据的软测量方法,尽早采取水质控制措施,使循环水系统始终保持在最佳状态。
1 LSTM神经网络简介
LSTM 神经网络由Hochreiter 等人[5]于1997 年提出,典型的LSTM 神经网络由输入层、隐藏层、输出层构成。LSTM 神经网络具有记忆功能,记忆单元结构如图1 所示,前一时刻的信息存储在记忆块中的记忆单元中,输入门(Input Gate)代表此刻的输入信息,遗忘门(Forget Gate)代表此刻丢弃的信息,输出门(Output Gate)代表最终网络输出的信息。每个时刻LSTM 单元通过遗忘门、输入门、输出门接收当前数据输入xt、上一隐含状态ht-1和记忆单位状态Ct-1。由于LSTM 神经网络隐藏层中采取了门控机制,能够有效解决传统循环神经网络(Recurrent Neural Ne twork,RNN)信息之间的依赖关系时间跨度过长而导致造成学习能力下降的问题[6]。
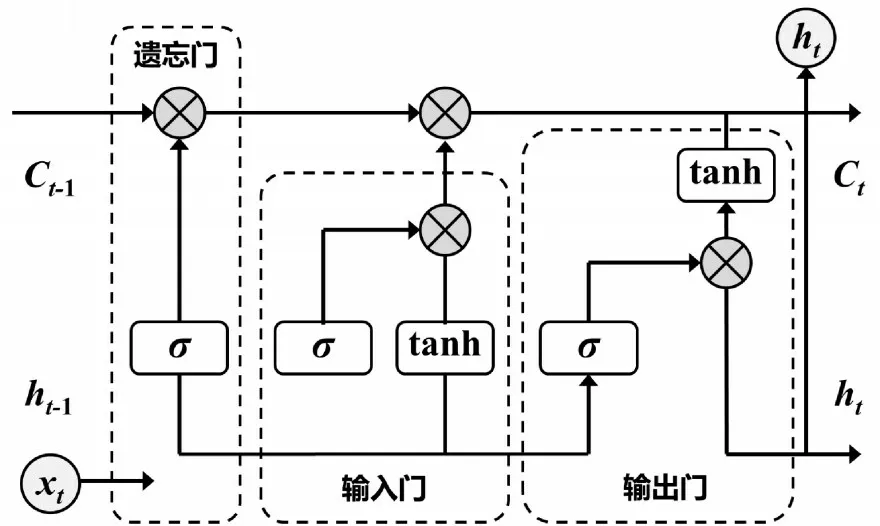
图1 LSTM记忆单元结构图
(1)遗忘门——删除记忆单元中的部分信息ft:
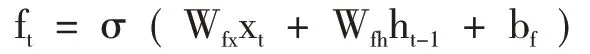
(2)输入门——将新信息储存到新记忆单元Ct:
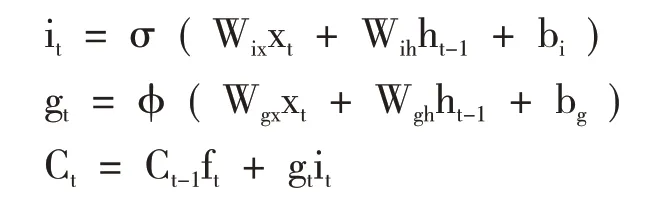
(3)输出门——输出记忆单元中的部分信息。

上述式中:W——相互间的权值矩阵;
b——对应的偏置;
σ、φ——分别为sigmoid 激活函数和tanh 双曲正切激活函数;
ft、it、gt、ot、Ct、ht——分别为遗忘门、输入门、输入节点、输出门、记忆单元状态和隐含状态的输出结果。
2 LSTM预测模型的建立
2.1 数据来源与预处理
试验数据采用某钢铁厂清循环系统2014 年1月至2019 年12 月水质监测数据及月度浓缩倍数与腐蚀速率数据,典型数据经过归一化后如表1所列。

表1 清循环系统水质监测数据、浓缩倍数与腐蚀速率(经过归一化处理)
某清循环系统采用磷酸盐+锌盐+聚丙烯酸类的复配缓释阻垢体系,日常水质监测数据指标包括:pH值、电导率、钙、碱度、可溶性铁、磷酸根、硫酸盐、铝、氯化物、镁、溶锌、悬浮物、浊度等。
为充分利用数据,本文所建立的预测模型输入量为上述13 项主要清循环系统水质监测指标的月度均值与离散程度(即标准偏差),输出量为清循环系统月度浓缩倍数与腐蚀速率。
主 成 分 分 析(Principal Component Analysis,PCA)是一种通过正交变换将各输入变量之间关联的复杂关系进行简化分析的方法,能使高维变量以一个较高的精度转换成低维变量,从而降低神经网络计算运行负荷。原始输入数据共有26 个输入变量,经过主成分分析(图2),以原始数据信息累计贡献率85%以上为目标,提取前10 个主成分作为LSTM神经网络模型的输入。
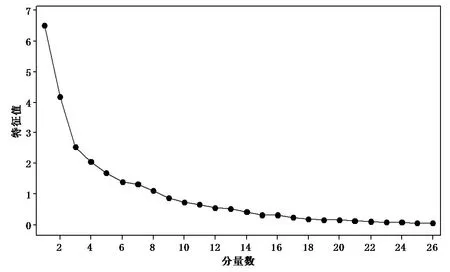
图2 清循环系统水质监测数据的碎石图
2.2 基于TensorFlow的LSTM神经网络模型构建
试验程序采用开源语言环境Python 3.7 编写,基于深度学习链接库Keras 2.3,底层依赖Tensorflow 2.2 框架,训练过程中使用均方误差MSE 作为损失函数、采用Adam 优化算法更新权重与偏置。试验程序采用两层LSTM 构建的循环神经网络,两层神经元数量依次为32、16。LSTM 模型的学习率为0.01,批处理大小为128,最大迭代次数为100 次,激活函数为ReLU。
试验程序利用2014 年1 月至2018 年12 月60 个月度清循环系统浓缩倍数与腐蚀速率数据为训练集(2016 年12 月由于系统年修、数据剔除)、2019 年1 月至12 月12 个月度清循环系统浓缩倍数与腐蚀速率数据为测试集。经过反复调参和迭代分析,预测结果与精度如图3、4和表2中所列。
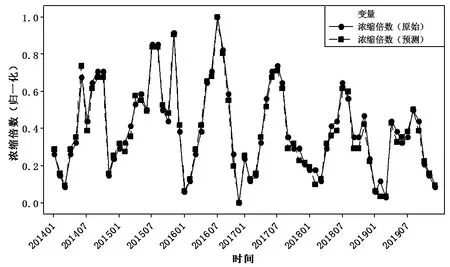
图3 浓缩倍数原始数据与LSTM神经网络预测数据对比图
其中,LSTM 神经网络模型对于清循环系统浓缩倍数与腐蚀速率都有较高的预测准确度,其中浓缩倍数预测的准确程度高于腐蚀速率。其原因在于,清循环系统浓缩倍数仅受到热负荷挥发、补排水量等因素的影响,相对原因比较单纯,因此预测精度能达到较高水平;而清循环系统腐蚀速率不仅容易受到本身水质的影响,更重要的是其缓释阻垢控制的影响,故预测精度稍低于浓缩倍数,但在清循环系统工业运用过程中,其预测精度已属于较准确的范围。

图4 腐蚀速率原始数据与LSTM神经网络预测数据对比图
2.3 模型比较
进一步选取BP、RNN神经网络对清循环系统浓缩倍数与腐蚀速率进行预测,以比较各预测模型之间的差异(表2)。
由表2 可知,BP 神经网络对于清循环系统浓缩倍数与腐蚀速率预测准确度都较差,其原因在于BP神经网络模型在训练过程中未考虑到浓缩倍数与腐蚀速率实际具有一定的时序变化趋势,其仅通过输入相关变量的变化进行预测,因此BP神经网络模型预测确度程度显著低于RNN和LSTM模型。

表2 LSTM神经网络对于浓缩倍数与腐蚀速率的预测准确度及其与BP、RNN模型的比较
由于RNN 模型在训练过程中容易出现信息之间的依赖关系时间跨度过长造成的梯度消失或梯度爆炸问题,通过本次模型比较准确性结果可以看出,LSTM 模型应用于预测浓缩倍数与腐蚀速率之类具有一定的时序变化数据是三者中最优的模型。
3 结语
浓缩倍数与腐蚀速率的模拟预测对于钢铁厂清循环系统运行与管理具有很高的指导作用,不仅能够有效减少系统水耗,更重要的是在于及时发现循环水系统水质趋势,及时采取措施,避免问题扩大。LSTM 神经网络模型对于清循环系统浓缩倍数与腐蚀速率都有较高的预测准确度,其中浓缩倍数预测的准确程度稍高于腐蚀速率。与BP、RNN神经网络相比,LSTM 模型应用于预测浓缩倍数与腐蚀速率之类具有一定的时序变化数据是三者中最优的模型。
猜你喜欢
小学生学习指导(中年级)(2022年9期)2022-09-30
石油化工建设(2020年1期)2020-08-24
建材发展导向(2019年10期)2019-08-24
当代水产(2019年1期)2019-05-16
当代水产(2019年3期)2019-05-14
数学大王·低年级(2018年8期)2018-09-03
电子制作(2018年14期)2018-08-21
能源(2016年2期)2016-12-01
新高考·英语进阶(高二高三)(2016年4期)2016-09-19
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
