
侧向碰撞风险对交织区汇合行为的影响
2021-08-28 07:06:12李根翟伟朱兴贝杨晟邬岚
交通运输系统工程与信息 2021年4期
李根,翟伟,朱兴贝,杨晟,邬岚
(南京林业大学,汽车与交通工程学院,南京210037)
0 引言
交织区是高速公路主要的瓶颈路段,而大量的汇合行为是引发交通流紊乱、造成通行能力下降的主要原因之一。研究高速公路交织区汇合行为并构建准确的汇合模型,不仅能够提升微观交通仿真模型的精度,更能够为辅助驾驶技术和自动驾驶技术提供理论支撑。
汇合决策模型由Gipps 提出,该模型是一种基于规则的模型,结构简单、易于应用,被广泛引用于微观交通流仿真软件中,但该模型假设条件较多,与实际驾驶行为差异较大[1]。此后国内外学者采用效用理论[2]、元胞自动机[3]、马尔可夫[4]、模糊逻辑[5]等理论对汇合决策行为进行分析和建模。近几年,不少学者将机器学习、深度学习等算法应用于汇合行为研究中。Xie 等[6]使用深度信念网络和长短期记忆神经网络建立基于深度学习的数据驱动换道决策模型;杨达等[7]结合社会力跟驰模型与换道模型建立驾驶员主动换道决策行为模型;谷新平等[8]基于贝叶斯优化算法的支持向量机建立换道决策行为模型。但这些研究都是将汇合行为视为一个瞬时决策事件,忽略了长达数秒的车辆汇合过程。Charisma等[9]开发了从入口匝道合并的加速决策组合模型,考虑合并计划选择、间隙接受、目标间隙选择对车道变换的影响。Zheng等[10]考虑驾驶员反应时间和最小间距的变化,分析车道变换对驾驶员行为自身的影响,虽然研究本身考虑了反应时间作为研究参量,但并没有考虑车道变换对周围车辆的影响,忽略了汇合决策的过程是复杂多变的;孙剑等[11]利用分类回归树建立汇合决策模型,考虑不同汇合行为对汇合过程的影响。邓建华等[12]利用改进双车道元胞自动机的换道规则模型,考虑不同空间占有率下不同车道分隔方式对换道行为的影响。但以上研究均未考虑汇合车辆与周围车辆的碰撞风险,特别是侧向碰撞风险对汇合行为的影响。同时,神经网络等机器学习算法能够有效提高汇合模型精度,但其“黑箱”特性令研究者无法研究其行为机理;分类回归树尽管能够得到汇合行为规则,但容易受到数据微小波动的影响,从而导致过拟合现象。
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是一种基于分类回归树的集成算法,通过惩罚系数等参数的设置能够有效防止模型过拟合,同时GBDT继承了分类回归树挖掘数据内部机理的特性,能够深入挖掘数据的内部机理。以往的研究表明GBDT 应用于汇合决策行为研究能够取得良好的效果[13]。因此,本文采用GBDT的方法对高速公路交织区汇合车辆的加速度进行研究,深入挖掘各解释变量与汇合加速度之间的潜在非线性关系,同时本文引入横向碰撞时间指标分析侧向碰撞事故风险对汇合行为的影响。
1 梯度提升决策树
梯度提升决策树(GBDT)是一种基于树的集成学习技术,主要采用集成学习boosting 的基本思想,通过迭代一系列可叠加的回归决策树模型,在迭代过程中不断对模型进行优化和提升,最终形成一个集成模型。GBDT 在每次迭代时通过最小化损失函数来逼近真实值,最后将每次迭代建立的决策树所得结论累加起来得到最终的预测结果。
如图1所示,给定具有N个训练样本的数据集,其中,xi为训练样本的输入变量,yi为训练样本的目标变量,hm为目标变量的基函数,ρm为最佳下降梯度步长,m为第M个决策树。GBDT 的目标是让输入变量xi映射到目标变量yi的损失函数最小,即

图1 GBDT集成学习流程图Fig.1 GBDT integrated learning flow chart


式中:δ为Huber-M 损失函数的一个参数。当δ~0时,Huber 损失会趋向于均方误差(MSE);当δ~∞时,Huber 损失会趋向于平均绝对偏差(MAD)。为了有效估计参数,采用梯度增强的方法,计算每棵树的负梯度值,即

利用每棵树的负梯度值作为训练数据进行回归拟合,将训练好的M-1 棵树的预测结果与第1颗树进行叠加,即

式中:η为学习率;γJM为第M棵树第J个叶子节点的值;nodes per tree(·)为每棵决策树的结点;N为训练样本数量。
最后,通过均方误差(MSE)、平均绝对偏差(MAD)和R值作为模型性能的评价指标,定义为

2 数据描述与分析
交织区指行驶方向相同的两股或多股交通流在没有交通控制设施的情况下,沿着相当长的路段进行交叉。根据道路结构和交叉形式,交织区一般可以分为A、B、C 这3 种类型。本文主要研究的是A型交织区路段的汇合行为,采用的数据集为美国联邦公路局提供的Next Generation Simulation(NGSIM)数据。本文选取高速公路US-101 路段上采集的汇合车辆轨迹,该路段全长640 m,包含5条目标车道,1 条辅道以及两个匝道出入口。本文研究两个匝道之间的交织区,如图2所示,该数据集采集于2005年6月15日7:50-8:35,包括车辆的加速度、速度、位置、车型、车头间距、车头时距等参量,时间精度为0.1 s·frame-1,原始数据集每0.1 s提供一个数据样本,本文采用对称指数移动平均滤波器(sEMA)对车辆的加速度和速度进行处理,即每1 s 对这些数据样本进行算术平均,以消除检测误差[14]。
如图2所示,影响交通流汇合加速度的因素主要有汇合车辆与周围车辆的速度差与距离差,然而汇合过程中汇合车辆难免会和周围车辆产生交通事故,尤其受到与目标车道领车的影响最大,因此猜想汇合车辆在汇合过程中与目标车道前车是否会发生侧向碰撞风险,在此考虑将汇合车辆与目标车道前车右车身线的碰撞时间作为影响因素引入模型中,如图3所示。

图2 US-101路段以及汇合过程车辆布局Fig.2 US-101 section and vehicle layout in merging process
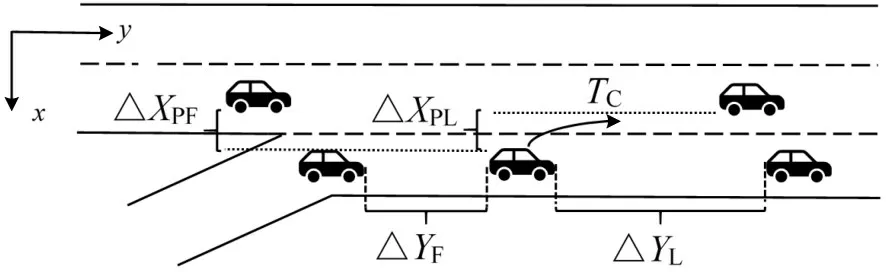
图3 影响变量参数确定Fig.3 Affect variable parameter determination

式中:TC为汇合车辆与目标车道前车右车身线的碰撞时间;ΔX为横向距离差;Vx为汇合车辆的横向速度;Ax为汇合车辆当前时刻的加速度。
在汇合过程中,汇合车辆的加速度一般会受到目标车道和辅道车辆的影响,汇合车辆会根据周围车辆和自身的相对速度和相对距离对驾驶速度进行调整。根据文献[14-15],本文将驾驶员反应时间定为1 s。表1 为所选取的影响变量的描述以及当前时刻影响变量和1 s后汇合加速度之间的相关性系数,可以发现,所有影响变量与汇合加速度都存在显著的相关性。

表1 汇合加速度与各变量之间的相关性系数Table 1 Correlation coefficient between merging acceleration and variables
3 模型的建立与结果
3.1 模型的建立
本文采用美国Salford 公司开发的数据挖掘软件Salford Predictive Modeler(SPM)建立GBDT 模型,GBDT 模型通过添加决策树实现减少训练误差,这将会导致模型过于接近训练样本数据,出现过拟合现象,为了降低过拟合现象,需选择最优的决策树数目,同时,在每一次迭代过程中,需训练一个弱决策树来改进模型,通过随机采样获得新的训练数据集和新的特征向量,利用新的训练数据集和新的特征向量进行拟合。因此,在构建GBDT模型时,所有决策树都将被限制为生长到相同大小,GBDT 模型的表现是由学习率η,属性采样数Sa,二次抽样Sfrd,树的复杂度J以及决策树数目M这5 个参数决定。为了防止过拟合现象,需选择最佳参数组合,本文采用五重交叉验证,选取NGSIM中的车辆轨迹数据对模型进行训练,将高速公路US101路段上的车辆轨迹数据划分成5个相等的子集,每个子集被用作测试数据,剩余子集用于训练模型,将学习率设定为Auto模式,η会根据样本数量随机定义,取值在[0.00,0.05]可以保证拟合的最佳效果;Sa会根据随机采样获得新的数据集,Sfrd会根据随机采样获得新的特征向量,新树会根据新的数据集和新的特征向量进行拟合,本文将其值分别设定为7 和0.6;SPM 软件可以根据目标函数自动确定决策树数目M,从而确定取值设置在5000;树的复杂度J选择均方误差(MSE)、平均绝对偏差(MAD)和R2作为评价标准。如表2所示,树的复杂度反映影响变量之间未知的交互作用,树的复杂度越高,影响变量之间的交互作用就会越高,同时不仅会降低计算速度,还会降低模型的泛化能力,根据以往的研究,本文将树的复杂度设置在10以内。

表2 树复杂度的确定
Table 2 Determination of tree complexity
为获得最佳参数组合,决策树复杂度在10 的时候误差和偏差值最小,再根据数据集的数量对模型进行反复测试,最终确定参数最优组合如表3所示。

表3 GBDT参数设定Table 3 GBDT parameter setting
3.2 模型结果分析
根据高速公路US-101路段上获得的车辆信息及交通流特征,从横纵向距离差、速度差以及加速度等交通参数选取10 个候选变量,将1 s 后的汇合加速度作为预测变量构建GBDT模型。此外,本文还根据文献[16]构建了基于视角的刺激-反应模型(VASR)对模型精度进行对比。如表4所示,GBDT模型在两项评价指标上都优于传统的刺激-反应模型。图4 选取编号为2990 和10864 的车辆对两种模型的预测值和实际值进行对比,发现GBDT模型能够更好地反应车辆加速度在换道过程中的动态变化。
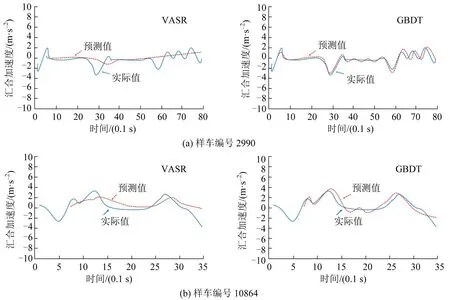
图4 随机选择样车的预测结果与实际汇合加速度的比较Fig.4 Comparison between predicted results of randomly selected sample cars and actual combined acceleration

表4 不同模型预测精度对比Table 4 Comparison of prediction accuracy of different models
相比于以往研究,本文侧重于考虑汇合车辆汇合过程中的安全性,将汇合车辆与目标车道前车右车身线的碰撞时间TC作为汇合过程的安全评价指标,分析侧向碰撞时间对汇合加速度的影响程度。由表5 可以发现:在引入侧向碰撞时间之后,模型的精度也会有所提升,说明侧向碰撞时间对汇合过程是存在安全影响的,而且该变量的引入能够让GBDT模型更加适用于汇合决策执行。

表5 GBDT模型不同影响变量精度对比Table 5 Comparison of accuracy of different influencing variables of GBDT model
各影响变量对汇合加速度影响的相对重要性如图5所示,其中,ΔVPL对汇合加速度的影响最大,TC、VM、ΔYL对汇合加速度也存在显著的影响,重要性超过了10%。通过影响变量的相对重要性分析可以发现,侧向碰撞时间TC对于汇合加速度的影响占据着重要的位置,表明侧面碰撞事故风险是汇合车辆驾驶员调整加速度的重要依据。

图5 影响变量的重要性Fig.5 Importance of influencing variables
为了进一步探索影响变量对汇合加速度的影响,建立重要性超过10%的影响变量对汇合加速度的偏效应,如图6所示,图中偏效应可以理解为在其他变量取均值并保持不变时,单个影响变量对汇合加速度的影响。
由图6 可以发现:重要性排在前4 的解释变量对汇合过程中汇合车辆加速度的影响存在着较强的非线性关系,汇合车辆与领车之间的速度差呈现较强的负相关,尤其是与目标车道领车的速度差,汇合加速度会随着速度差的增加而加快下降,当与领车的速度差ΔVPL达到2 m·s-1的时候,汇合车辆才会开始减速;新引入的变量,即侧向碰撞时间TC也是和汇合加速度呈现负相关,但有趣的是在TC值达到30 s的时候,与汇合加速度的偏效应变成了线性的下降趋势,到70 s 的时候逐渐趋于平缓,说明当汇合车辆与目标车道领车的碰撞时间达到30 s的时候,驾驶员会认为这时候的车辆汇合相对安全从而降低减速的幅度,直到70 s的时候确认安全,将速度变成匀减速,但汇合车辆在汇合过程中依旧处于减速状态;汇合车辆的速度也对汇合加速度有一定的影响,其中汇合加速度与汇合速度呈现正相关,汇合速度在[6,8]m·s-1处波动较大;相比于前三者,距离差对于加速度的影响相对比较平缓,处于上下波动,但也呈现下降的趋势,汇合车辆在相距40 m 的时候才会开始减速,在[80,95]m 处会出现减速不稳定。

图6 影响变量对预测结果的偏效应Fig.6 Partial effect of influencing variables on forecast results
4 结论
本文利用梯度提升决策树(GBDT)构建交织区汇合加速度模型,引入侧向碰撞时间TC对模型进行预测和偏效应分析。测试结果表明:GBDT模型相比于基于视角的刺激-反应模型(VASR),具有较高的预测精度;在所采用的影响变量中,汇合车辆与目标车道领车的速度差ΔVPL对汇合加速度的影响最大,其次是侧向碰撞时间TC;引入侧向碰撞时间TC可以有效优化模型的均方误差(MSE)、平均绝对偏差(MAD)和R2这3个指标值,说明侧面碰撞风险是汇合车辆调整加速度的重要依据,能够让GBDT模型更加准确预测车辆的汇合加速度。
猜你喜欢
卫星应用(2021年11期)2022-01-19 05:13:02
北京航空航天大学学报(2021年4期)2021-11-24 01:12:56
科学大众(2021年9期)2021-07-16 07:02:50
中国交通信息化(2020年11期)2021-01-14 03:30:34
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
光学精密工程(2016年3期)2016-11-07 09:03:52
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
通信电源技术(2016年1期)2016-04-16 04:57:35
西北工业大学学报(2015年1期)2016-01-19 03:29:56
