
基于多维结构特征的硬件木马检测技术
2021-08-26 08:08严迎建赵聪慧刘燕江
电子与信息学报 2021年8期
严迎建 赵聪慧 刘燕江
(战略支援部队信息工程大学 郑州 450000)
1 引言
近年来赛博空间安全事件频繁爆出,使得信息安全问题再次受到了广泛的关注。集成电路作为信息产业的基础,其“自主可控”与“安全可信”是信息安全的根基。由于集成电路的先进性和复杂
收稿日期:2021-01-04;改回日期:2021-03-10;网络出版:2021-06-24
*通信作者:赵聪慧1024600921@qq.com性,第三方知识产权(Intellectual Property,IP)核,包括软核、固核和硬核等,大量应用在集成电路设计阶段来缩短产品的开发周期。然而,外购的IP核可能由境外、外资或者合资企业提供,一旦一个环节出现安全问题,将直接影响整个芯片的安全可信[1]。第三方IP核是恶意攻击者的理想藏身之所,黑盒设计中可能早已内置恶意电路,即硬件木马,如图1所示,它可于无声处泄露内部私密信息、篡改电路功能和升级系统权限等。此外,目前缺乏IP核的安全可信分析标准和行业规范,第三方IP核已成为硬件木马的“天堂”,进口的集成电路乃至自主设计的芯片的安全可信水平更加难以保障[2]。

图1 IP核安全隐患分析
硬件木马是IP核的主要安全威胁,如何检测硬件木马受到了国内外研究学者的广泛关注。目前安全性分析主要有形式化验证和木马特征识别两类方法。形式化验证方法评估IP核的属性违例情况来确定其可信任度,评估难度随着电路规模的增加呈指数级增长,验证边界是主要瓶颈,另外安全属性构建大多是“一事一议”,硬件木马类型繁多,构建的安全属性很难涵盖所有的硬件木马类型。硬件木马虽然种类繁多,但在结构上存在多个共性特征,因此,基于特征识别的硬件木马检测方法被广泛研究并成为主流方法。
具体来说,Oya等人[3]总结了9种木马特征并对每种特征赋予特定的分值,通过分值的高低来确定是否存在硬件木马。但该文并未阐述这些特征的性质及与硬件木马触发机制的联系。Yao等人[4]基于数据流图提出4种硬件木马特征,利用硬件木马特征匹配算法来检测硬件木马,并形成了检测工具FASTrust。然而基于数据流图的木马特征构建方法是从寄存器层面进行的,大量的组合逻辑被忽略,误识别率较高。Hasegawa等人[5]提出了LGFi,FFi,FFo,PI,PO等5种硬件木马特征,并利用支持向量机算法来训练并识别木马节点,然而在训练集中,硬件木马特征集较少,训练集分布并不平衡,即便是采用动态加权的支持向量机依然存在较大的误识别情况。Chen等人[6]计算待测电路中两级AONN门的分数,认为分数较高的门是硬件木马。该方法对单触发型硬件木马有效,然而对于多触发条件的硬件木马无能为力,且未考虑有效载荷电路及其功能。
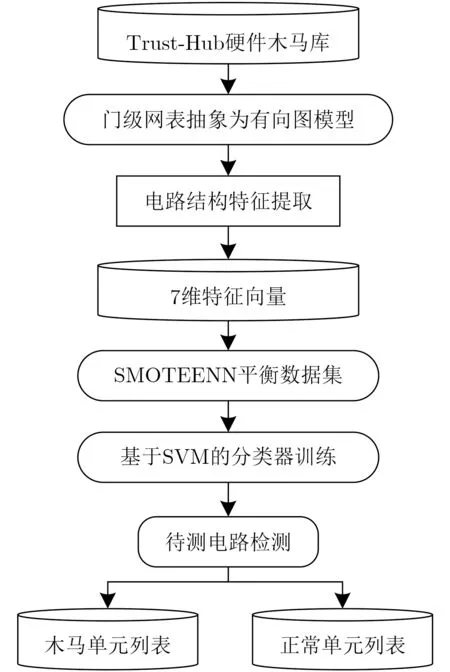
因此,本文构建了扇入单元数、扇入触发器数、扇出触发器数、输入拓扑深度、输出拓扑深度、选择器数量和反相器数量的硬件木马特征。另外,本文建立了基于图结构的电路分析模型,将门级网表映射为有向图模型,最终形成了网表简化分析流程。最后,提出广度优先搜索算法计算网表顶点的硬件木马特征值得分,利用基于最近邻不平衡数据分类算法(Synthetic Minority Oversampling Technique an d Ed it ed Near est Neighbor,SMOTEENN)的硬件木马特征扩展算法来解决木马特征数据集不平衡问题,借助支持向量机(Support Vector Machines,SVM)算法建立硬件木马检测模型并检测出IP核中的硬件木马。
2 基于有向图的门级网表抽象化建模算法
目前的IP核安全性分析方法大多基于门级网表开展研究,分析网表的状态是否存在违例情况或者提取网表中的隐藏性结构特征等,然而网表分析效率随着电路规模呈指数级增长,严重限制了验证范围。为了简化硬件木马分析效率,本文研究了门级网表的抽象化建模算法,将门级网表映射为有向图,形成利于分析的数据存储结构,大大提高了分析效率,降低了验证成本。另外,基于有向图可将硬件木马的行为级描述转换为可量化的数据指标,可扩展应用未知硬件木马检测,更具普适性。
2.1 门级网表的有向图模型
首先介绍有向图的基本概念。图是由顶点的有穷非空集合和顶点之间边的集合组成的。顶点vi和v j之 间的边有方向称为有向边

图2 门级网表等效电路图
将电路中所有的输入(I1,I2,I3,I4,I5和clk)、输出端口(O1,O2)和器件单元(N1,N2,···,N8)映射为有向图的顶点,组成顶点集V。将顶点之间的连线映射为有向图的边,每条边的弧尾为与该节点相连的上一级器件单元,弧头为与该节点相连的下一级器件单元,构成边集E={e1,e2,···,e18}。基于此映射规则,任何一个网表都可以映射为由顶点集V和边集E组成的有向图G=(V,E)。
2.2 基于十字链表的有向图数据存储
将门级网表映射为有向图后,需要存储有向图的顶点集V和边集E。邻接表是一种数组与链表相结合的存储方法,由于只存有关联的信息,不存在空间浪费的问题[9]。因此本文采用图的邻接表来存储有向图数据。具体来说,数组用来存储所有的顶点信息,链表用来存储顶点对应的边的信息。
在用邻接表来存储网表的有向图时,需统计各顶点链表中的结点数目,便可得到所有顶点的出度,但要获取各顶点的入度则需要遍历整个邻接表,或者为该有向图建立一个逆邻接表。为了同时计算有向图的出度和入度,本文采用将邻接表和逆邻接表相结合的十字链表,图3的十字链表结构存储如图4所示。其中,顶点表中的data存储可唯一表示该顶点的信息,firstin表示入边表头指针,指向以该顶点为终点的边,firstout表示出边表头指针,指向以该顶点为起点的边。边表中tailvex是指有向边的起点在顶点表的下标,headvex是指有向边的终点在顶点表的下标,headlink是指入边表指针域,指向终点相同的下一条边,taillink是指出边表指针域,指向起点相同的下一条边。

图3 门级网表的有向图模型
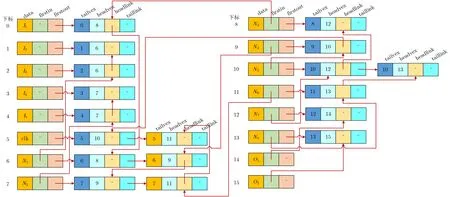
图4 有向图的十字链表结构
3 硬件木马结构特征模型
硬件木马的结构千差万别,类型丰富多样,然而硬件木马在触发和载荷方面具有隐蔽性,在功能方面具有恶意破坏性,因此可以提取出共性特征。本文分析了硬件木马库Trust_Hub[10]以及现有文献给出的多种硬件木马,提出了FAN_IN,FF_IN,FF_OUT,DPI,DPO,MUX和INV 7种硬件木马共性结构特征。
(1)扇入单元特征FAN_IN。硬件木马为了保证隐蔽性,通常会选择多个稀有逻辑值或者状态作为其触发条件,保证在测试验证阶段难以“误触发”,即硬件木马的触发逻辑输入个数较多。图5(a)为硬件木马RS232-T1400的结构,其触发部分是一个组合比较器,当多个条件同时满足时,硬件木马被激活,改变原有信号的值。图5(b)为图5(a)的有向图,触发逻辑包含4层扇入顶点,且扇入单元数量大于11。本文将从输入方向距离单元n 4层逻辑门的扇入单元总数FAN_IN作为判断硬件木马的结构特征。
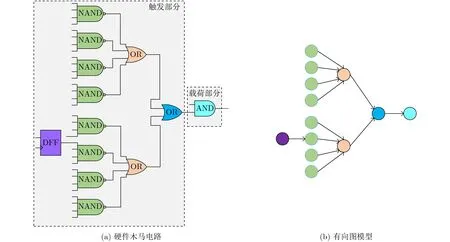
图5 RS232-T1400中的硬件木马电路及其有向图模型
(2)扇入触发器数FF_IN和扇出触发器数FF_OUT。触发器是时序电路的基本单元,由触发器组成的状态机的特定状态转移序列和计数器的计数值均可作为硬件木马的触发条件。图6(a)为RS232-T1200电路中的硬件木马电路部分,该木马电路的触发逻辑是一个时序比较器,当特定状态满足时,硬件木马被激活。触发逻辑的触发器单元较多,本文利用扇入触发器数FF_IN和扇出触发器数FF_OUT来量化触发器单元数量。图6(b)为RS232-T1200的有向图,本文以输入和输出方向距离单元4级逻辑门的触发器单元数目FF_IN和FF_OUT作为判断硬件木马的结构特征。

图6 RS232-T1200中的硬件木马电路及其有向图模型
(3)输入拓扑深度DPI和输出拓扑深度DPO。信息泄露型硬件木马常常复用电路的输出端来泄露母本电路内的关键信息,功能型硬件木马通常监测母本电路的输入端来激活特定序列。基本输入和基本输出或者距离基本输入输出非常近的电路节点可能是硬件木马节点。图7(a)为硬件木马RS232-T1300的结构,硬件木马的有效载荷输出作为母本电路的输出。控制母本电路的输出,当硬件木马被触发后,硬件木马的有效载荷控制母本电路的输出,并用来泄露母本电路的私密信息。因此,本文选择基本输入和输出的逻辑单元深度DPI和DPO作为判断硬件木马的结构特征。
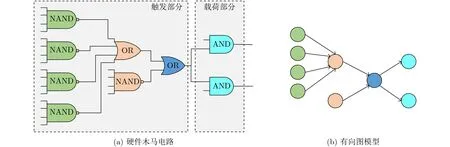
图7 RS232-T1300中的硬件木马电路及其有向图模型
(4)多路选择器数量MUX。为了避免在测试与验证阶段被检测输出,攻击者通常会选择特定输入逻辑序列或者内部状态值作为硬件木马的触发条件。因此,多路选择器在硬件木马触发逻辑中广泛应用,主要用来判断当前状态是否满足其触发条件,触发条件越苛刻,多路选择器数量就越多。图8(a)为硬件木马s15850-T 100的结构,当输入序列满足预设值时,硬件木马才激活,并选择内部信号n1936进行输出,从而达到泄露节点n1936状态的目的。本文选择单元n前后4级包含的多路选择器的数量作为判断硬件木马的结构特征。
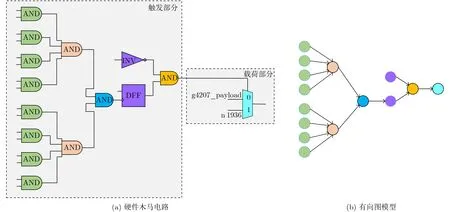
图8 s15850-T100中的硬件木马电路及其有向图模型
(5)反相器数量INV。对于降低性能型的硬件木马来说,通常选择环形振荡器作为硬件木马的载荷部分。当输入满足硬件木马的触发条件时,植入在关键路径上的有效载荷被激活,导致电路出现时序违例情况。因此,路径上的反相器链可作为硬件木马的结构特征。图9(a)为s35932-T 300电路中硬件木马结构的载荷部分,共由20级反向器、3级数选器以及1个与门组成,图9(b)为有向图模型。本文将单元n前后4级所包含的反相器数量作为判断硬件木马的结构特征。

图9 s35932-T300中的硬件木马电路及其有向图模型
基于上述讨论,本文共总结了7种和硬件木马密切相关的结构特征,具体描述如表1所示。
4 硬件木马特征提取与识别算法
本文利用门级网表抽象化建模算法将网表映射为有向图,基于表1的描述来计算各个顶点的硬件木马特征值得分,形成7维特征向量。硬件木马逻辑与母本电路逻辑的特征值存在差异,将硬件木马的检测问题转化为二分类问题,利用支持向量机来建立最优的分类平面并识别硬件木马特征,保证木马识别风险最小化和准确率最高。然而在分类器训练过程中,硬件木马的特征集数量远远小于母本电路,这种不平衡的特征集分布很容易导致建立的最优超平面并不准确,导致分类结果出现较高的误识别率。因此,本文提出了基于SMOTEENN的硬件木马特征扩展算法来扩充木马特征集。

表1 硬件木马结构特征描述
4.1 基于广度优先搜索的硬件木马特征得分量化算法
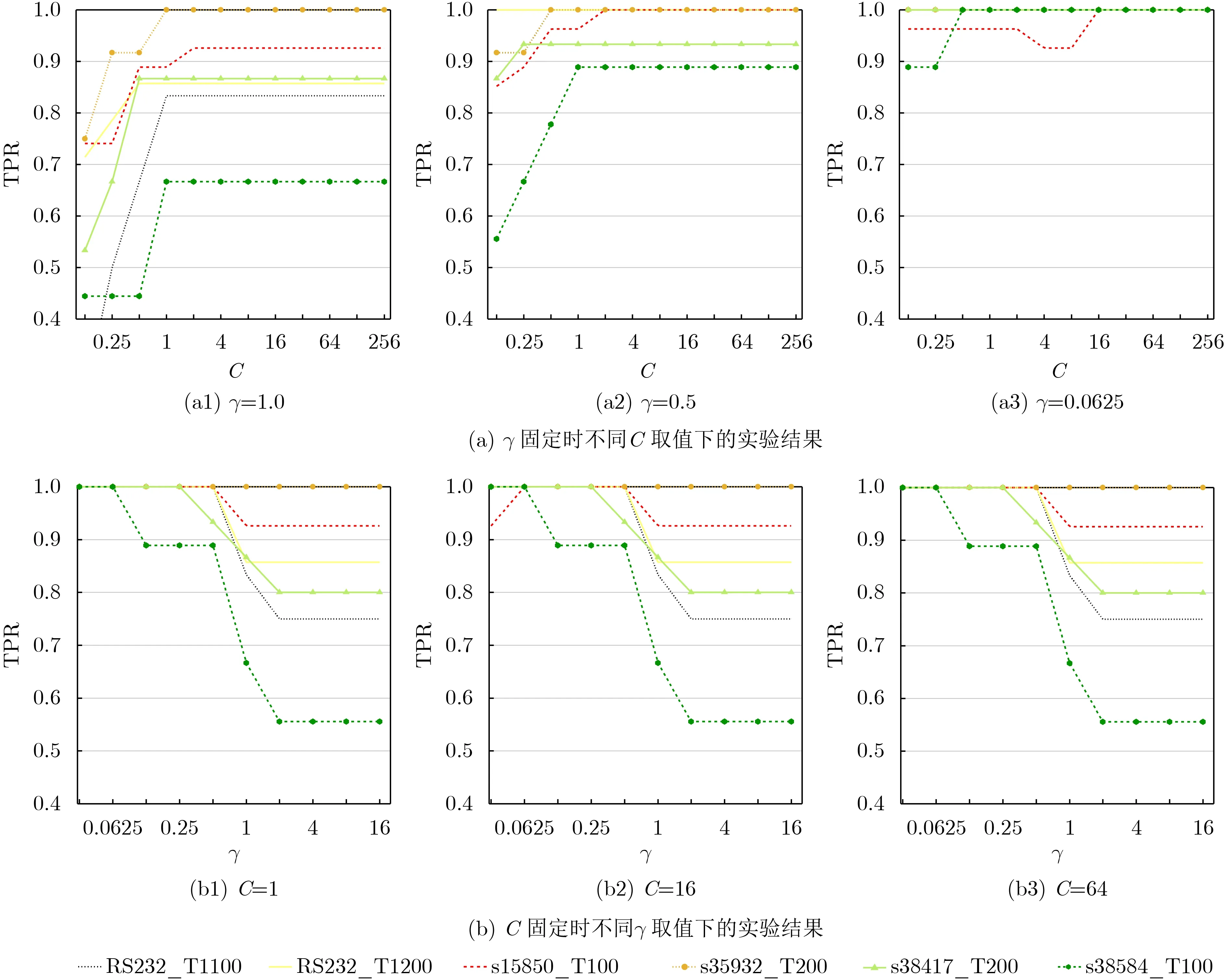
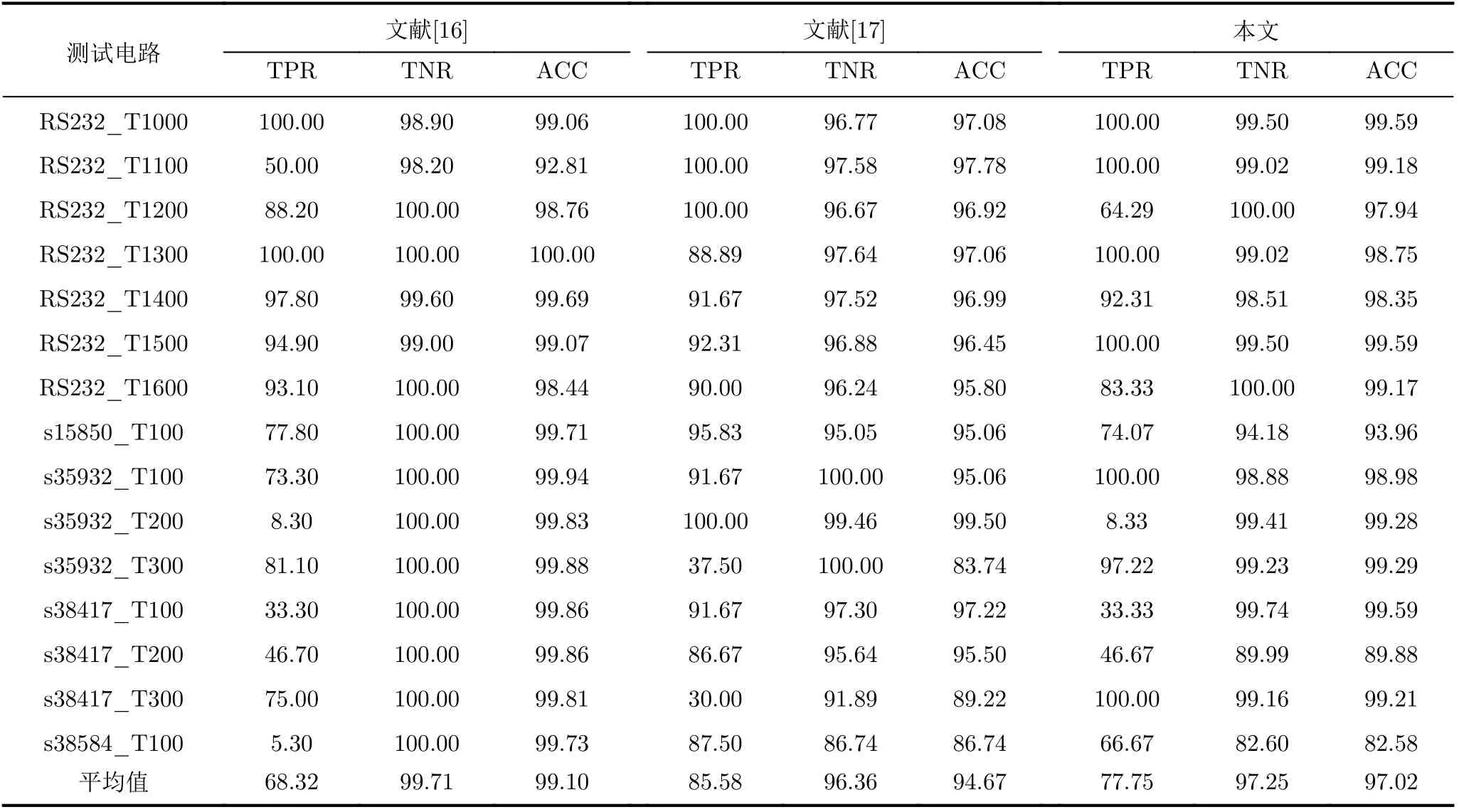
将待测电路网表转换为有向图模型后,依据硬件木马特征描述符对有向图顶点进行特征提取,计算出有向图所有顶点的硬件木马特征得分,具体过程如表2所示。G为门级网表的有向图,n为G中顶点个数,m为遍历层数。对于第i个 顶点vi,利用初始化函数intialize来初始化队列Q,入队列函数enquene将该顶点放入到队列Q中。当Q为非空集合且满足遍历层数条件(f 表2 基于广度优先搜索的硬件木马特征扩展算法 目前国内外文献仅公开了几十种类型的硬件木马,可建立的硬件木马特征样本非常有限。然而母本电路的规模庞大,特征样本数量较多,导致各类的训练集样本分布不够平衡。数据集的不平衡性可能会造成多数样本所属类的过度拟合,进而影响分类器的性能。在硬件木马检测中,任何可疑节点都不应该忽略,因此需要研究硬件木马特征扩展算法,对木马数据集进行过采样来扩充硬件木马特征集不足的短板,避免木马样本学习的不足。 SMOTEENN为过采样与欠采样相结合的采样技术,生成少数类样本后再利用数据清洗技术删除重叠样本,形成更利于正确分类的平衡数据集[11]。该算法是人工少数类过采样法(Synthetic Minority Oversampling TEchnique,SMOTE)和最近邻(Edited Nearest Neighbor,ENN)算法的结合,先利用SMOTE过采样技术生成新的少数类样本,获得新的数据集,对新数据集中的每一个样本使用K近邻法预测,若预测结果和实际类别标签不同则剔除该样本,最后形成平衡的数据集,将平衡后的数据集应用于分类器的训练,从而建立更加完善的分类模型。因此本文采用SMOTEENN算法对数据集进行预处理,以扩充硬件木马特征集。 支持向量机是一种基于统计学习理论的有监督机器学习算法,可以依据数据的特点建立自适应的分类超平面,相比其他算法来说,准确率更高[12,13]。因此,本文选择SVM算法建立分类模型,将硬件木马的检测问题转换为机器学习中的二分类问题,通过学习已知硬件木马和母本电路的特征向量,建立最优的硬件木马分类器,可以有效识别出硬件木马的特征。 SVM算法分为训练和测试两个过程。在训练过程,通过对已知硬件木马特征库的学习来建立分类模型。首先,根据硬件木马特征库构造特征向量集V={x1,x2,···,x k,x k+1,···,x n},其中木马特征向量集A={x1,x2,···,x k}, 母本电路特征向量集B={x k+1,x k+2,···,x n}。支持向量机把分类问题转化为寻找最大间隔超平面,这个最优分类超平面可表示为 其中,所有木马特征向量满足 母本电路特征向量满足 φ称为非线性不可分核函数,当正负样本线性不可分时,该函数可将输入特征向量x映射到高维空间,重新转变为线性可分的问题;ω是这个超平面的法向量,b是它的偏置截距。寻找最大间隔超平面的过程即是求解式(2)和式(3)的过程,调整ω和b的值,以最大化样本点到决策面距离。 同时,考虑到为了满足个别“离群点”的正确分类而对间隔距离造成的影响,本文引入了松弛变量ξ和惩罚因子C,最终转换为对以下最优化问题的求解 其中,yi为特征向量xi对应的样本标签。 在测试过程中,利用训练得到的最优分类超平面来验证待测样本x i的类号f(x i),决策函数如式(5)所示。若f(x i)为 1,则认为待测样本xi为硬件木马节点,否则为母本电路节点。 为了验证本文方法的有效性,本文选择Trust-Hub库中的15种硬件木马开展实验。对该15个测试电路进行统计分析,得到其电路规模以及木马结构和功能信息如表3所示。本文所选测试电路的规模涵盖了几百到几千门,而木马电路仅包含几到几十门,数据不平衡性非常严重,难以完全识别出所有的硬件木马特征,因此需要研究硬件木马特征扩展算法来优化分类器模型。 表3 木马电路的具体描述 本文的主要实现流程如图10所示。首先对门级网表进行分析,将电路图抽象为有向图模型并以十字链表存储有向图。其次,依据有向图模型,提取电路的结构特征,构造表征木马信号的7维特征得分值矩阵。再次,利用SMOTEENN算法平衡数据集,用平衡后的数据集训练SVM分类器,建立最优的分类模型。最后,利用训练好的分类器来验证待测电路是否存在硬件木马信号列表。 图10 基于SVM的硬件木马识别流程 为了评估本文所提出的硬件木马检测方法的有效性,本文选取真正类率(True Positive Rate,TPR)、真负类率(True Negative Rate,TNR)和分类准确率(ACCuracy,ACC)这3个常用指标,具体表示如式(6)、式(7)和式(8)所示[14]。其中,TP指被正确识别的木马单元数量,TN指被正确识别的正常单元数量,FP指正常单元被错误识别为木马单元的数量,FN指木马单元被错误识别为正常单元的数量。TPR表示正类样本的分类准确率,即硬件木马的检测率,TPR越高,木马检测效果越好;同理,TNR表示负类样本的分类准确率,即正常单元的检测率,如果TNR过低,说明误把大量正常单元归类为木马单元,导致误判率高;ACC表示所有样本的分类准确率,ACC越高,整体的分类效果越好[15] 在训练SVM分类器的过程中,本文使用的核函数是高斯核函数,该函数自带一个参数γ,γ和惩罚因子C是需要重点优化的参数,这两个参数直接关系到分类器的性能。遴选SVM参数是一个具有较大工作量的环节,本文按照60%/40%的比例随机划分为训练集和测试集,用训练出的模型对所有电路进行测试,以TPR为目标函数进行参数的调节。本文分别选取12个C值和10个γ值共120个C −γ组合共进行120次训练,1800次测试,将部分结果展示如图11所示。 图11展示了多个电路在C和γ一方取值固定,一方变化时的实验结果变化规律,由图11(a)可以看出,当γ取值固定时,从整体上来看,C的值越大,分类结果越好;同时由图11(b)可以看出,当C取值固定时,γ的值越小,分类结果越好。为了验证该规律的正确性,将s15850电路的实验数据展示如图12,可以得到同样的结果:当γ取一固定值时,横向观察各图,可以看出,C的值越大,分类结果越好;同时当C取一固定值时,纵向观察各图,可以看出,γ的值越小,分类结果越好。其中C是惩罚因子,C越高,说明在训练时越不能容忍出现误差,容易导致过拟合;γ是选择高斯核函数作为核函数后,该函数自带的一个参数,隐含地决定了数据映射到新的特征空间后的分布,γ值越小,支持向量越多,容易造成平滑效应,影响测试集的准确率。为了使SVM分类模型在得到较好的分类结果的同时具有更强的普适性,本文最终选取C=16,γ=0.0625作为本实验中SVM的训练参数。 图11 不同参数下SVM分类器的实验数据 图12 s15850电路在不同参数下的实验结果 在完成硬件木马特征扩展和分类模型参数的选取后,将本文方法应用于测试电路进行实验验证,该实验在个人笔记本电脑(Intel(R)Core(TM)i5-8265U CPU@1.60 GHz,8 GB RAM)上进行。由于硬件木马特征库的建立和分类器的训练均在前期准备工作中完成,且后续检测未知电路时不需重复执行该项工作,因此该段时间开销不计入总的时间开销,检测效率由待测电路的特征提取时间和分类器的分类时间共同决定。本实验中对15个测试电路进行检测,特征提取共用时42.6 min,分类器分类仅耗时4.5 s,即平均每2.845 min即可完成对一个木马电路的检测。最终的实验结果及与文献[16,17]的结果比较如表4所示。 表4 本文方法实验结果及与现有方法的比较(%) 可以看出,本文方法在半数以上电路中取得了90%以上的硬件木马检出率,达到了很好的检测效果。文献[16,17]所提出的硬件木马检测方法在现有的基于特征识别的硬件木马检测方法中处于领先水平,本文与之相比仍具有一定的优势。文献[16]在文献[5]的基础上进行了硬件木马特征的扩充,形成了目前为止较为完善的硬件木马特征集,但是却存在冗余特征过多的问题,平均木马检出率只达到68.32%。与文献[16]相比,本文在小幅牺牲TNR的前提下,将平均硬件木马检出率提升了13.80%。文献[17]同样利用SVM算法构造分类模型,本文TNR和ACC的表现均优于文献[17]所提方法,虽然文献[17]中方法的TPR高于本文,但其构造的分类模型在对不同电路分类时,采用的参数C和γ是不同的,这样做虽然可以提高实验结果,但对不同电路均须寻找最优参数,时间开销较大,并且会导致在检测未知电路时,没有一组固定的参数来进行分类模型的训练,从而难以应用到实际的硬件木马检测问题中。此外,文献[16,17]均未提及检测用时,本文方法执行一次分类任务只需2.845 min,是一种十分高效的硬件木马检测方法。综上所述,本文方法在现有方法基础上进一步提升了硬件木马检出率,检测效率高且具有良好的实际应用价值,是一种综合性能更好的硬件木马检测方法。 本文提出一种基于有向图结构的电路简化分析模型,并在此基础上提出了基于结构特征的硬件木马检测方法。通过将电路图抽象为有向图,简化电路结构分析过程,提取与硬件木马紧密相关的7维结构特征,利用SVM分类器建立分类模型实现硬件木马检测。由实验结果可知,本文方法在半数以上电路的TPR达到了90%以上,所有测试电路的平均TNR和ACC分别为97.25%和97.02%,实现了超高的准确率,且检测一个木马电路平均仅需2.845 min,具有极高的检测效率。与文献[16]的方法相比,平均硬件木马检出率提高了13.80%,与文献[17]的方法相比更具有实际应用价值,是一个综合性能更好的硬件木马检测方法。今后将继续分析电路结构,挖掘更多与硬件木马相关的结构特征,在现有基础上继续扩充硬件木马特征库,进一步提高硬件木马检测方法的通用性。
4.2 基于SMOTEENN的硬件木马特征扩展算法
4.3 基于SVM的硬件木马特征识别算法

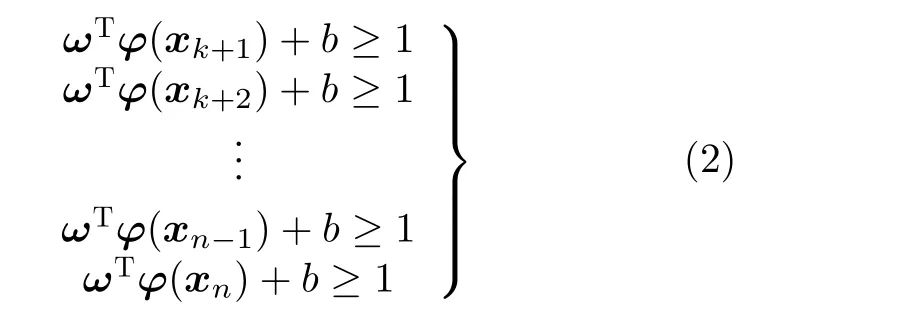

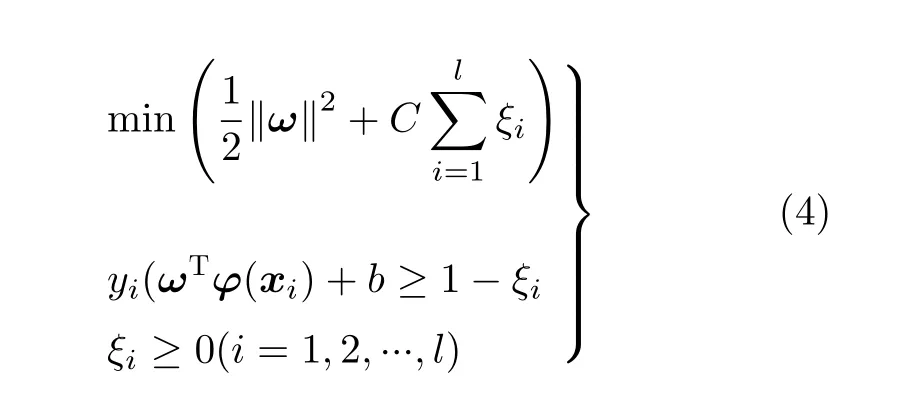
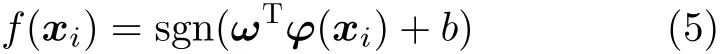
5 实验结果与分析




6 结束语
猜你喜欢
娃娃乐园·综合智能(2021年11期)2021-12-06
中等数学(2021年9期)2021-11-22
科普童话·学霸日记(2021年6期)2021-09-05
云南民族大学学报(自然科学版)(2021年3期)2021-06-24
读友·少年文学(清雅版)(2019年6期)2019-10-15
山东科学(2018年6期)2018-12-20
四川师范大学学报(自然科学版)(2018年4期)2018-07-04
创新作文(小学版)(2018年34期)2018-05-23
廊坊师范学院学报(自然科学版)(2017年3期)2017-10-11
山西大同大学学报(自然科学版)(2014年2期)2014-01-23
