
基于对抗学习的开集域自适应分类
2021-08-26 08:40:18张庆亮朱松豪
南京邮电大学学报(自然科学版) 2021年3期
张庆亮,朱松豪
(南京邮电大学 自动化学院、人工智能学院,江苏 南京 210023)
目前,深度卷积神经网络被广泛用于解决许多计算机视觉任务,并显著提高了性能。但是,训练一个有效的深度卷积网络模型需要大量带标签的样本,这需要消耗大量的人力物力财力,因此通常难以获得这样的数据。这种缺陷阻碍了深度神经网络在图像任务中的进一步发展,尤其是在医学图像等标注样本极为稀缺的领域[1-2]。当标注样本稀缺时,来自分布不同但语义相关的数据集样本对模型训练很有帮助,但由于不同数据集的分布不同,直接用其进行训练会产生“域移位”现象[3]。为解决该问题,域自适应方法被广泛研究[4]。在域自适应问题中,将未标记的数据集称为目标域,已标记的数据集称为源域。在本文的设定中,目标域样本的标签信息完全未知,因此,可视为无监督问题。现有的域自适应方法大多属于闭集域自适应[5-9],即源域和目标域的类别完全重合,但在实际应用中,目标域样本可能是源域中未出现过的类别,即“未知类别”。这个问题被称为开集域自适应[10],如图1所示。由于“未知类别”的信息完全未知,因此开集域自适应比传统的闭集域自适应问题更具挑战性。
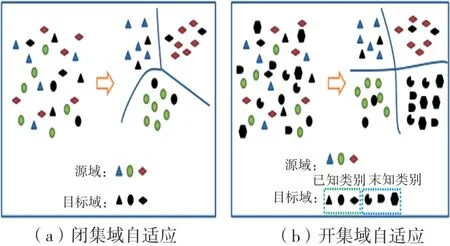
图1 两种域自适应
本文在文献[11]的基础上,提出了一个新的方法,使用了奇异值平衡策略和基于对抗思想的域对齐方法。文献[12]的研究表明,在迁移学习过程中,模型的迁移性得到增加,但同时也导致了奇异值分布的不平衡。深度网络在迁移学习过程中会损失一定的可辨别性,而模型的可辨别性越高,意味着预测的准确性越高。这种现象的内在原因是较大奇异值对应的向量决定了模型的可迁移性,同时迁移学习过程中会抑制较小的奇异值,惩罚对应的向量。然而,这些被惩罚的向量对模型的可辨别性也至关重要,因此,模型的可辨别性会下降。该文献通过抑制最大的奇异值来实现奇异值分布的平衡,从而在提高迁移性的同时尽可能确保较高的可辨别性。由于特征值的大小会影响模型预测的准确性,因此在保持奇异值平衡的同时,我们尽可能增加奇异值的大小。此外,本文通过设置合理的阈值,避免了目标域中未知类别的特征对齐;同时,通过对抗性训练实现源域和目标域中已知类别的特征分布对齐。在此基础上,源域和目标域同类别样本间的偏差进一步缩小,且模型的可辨别性进一步得到增强。
1 相关工作
1.1 闭集域自适应
在过去的几年中,域自适应已成为计算机视觉领域中一个非常火爆的问题[13]。通过域自适应,可以实现不同域之间的知识转移,从而减少大量不同域图像的标记成本。由于不同域间的特征分布不同,在源域上训练的分类器直接在目标域上进行测试,性能会有较大下降。解决该问题的一个有效方法是确保源域样本和目标域样本的分布尽可能相似,其目的是获取域不变特征。基于这种观点,对抗生成网络思想越来越多地应用于域自适应研究中[14]。对抗生成网络训练鉴别器来识别输入样本的真实性,并利用生成器生成假样本欺骗鉴别器。与之类似,近年来出现了许多采用对抗思想的域自适应模型,例如文献[15-18]提出的方法。在这些方法中,鉴别器用于区分图片是来自源域还是目标域,生成器用于特征提取。
虽然这些方法取得了很大成功,但它们最基本的假设是源域和目标域共享完全相同的类别,即闭集域自适应。一旦目标域中含有源域中未出现的类别,这些方法的性能会出现很大的下降。
1.2 开集域自适应
由于开集域自适应的设定更加接近真实场景,因此逐渐受到研究人员重视。开集域自适应的目标域中包含源域中不存在的类别,其最终目的是对已知类别进行正确分类的同时,识别出所有未知类样本。最近一些研究者提出了几种方法来解决该问题。例如,文献[10]通过每个目标样本的特征与每个源类别特征的中心距离,来确定目标样本是属于已知类别还是未知类别。文献[11]通过二分类对抗训练,实现未知样本的检测。文献[19]通过多二进制分类器实现未知样本的识别,并对齐两个域的特征分布。文献[20]使用支持向量机获得的概率值,实现目标域中未知样本的识别和剔除。文献[21]利用对抗生成网络生成未知类样本,并用其训练神经网络。此外,文献[22]从半监督学习中得到启发,提出了学生和教师两个子网络的自嵌入方法,在开集域自适应中也表现出了很好的效果。
2 改进方法
2.1 分类器训练
要解决开放集域自适应问题,须准确区分已知样本和未知样本;同时,也要对齐源域和目标域中所有已知类别样本的特征分布,以消除域间的偏差。
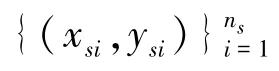
图2给出本文提出的域自适应方法,具体而言:首先,将样本输入由卷积神经网络和全连接层构成的特征生成器G中,其中fs、ft和fkt分别表示生成器G从源域、目标域和目标域中的已知类别提取的特征;然后,标签预测器将这些样本分为K+1个类别,其中K表示已知类别的数量,而第K+1个类别表示仅在目标域中存在的未知类别,同时利用p(xsi|ysi)=C{G(θg,xsi),θc}(θg表示特征生成器G的参数,θc表示分类器Cy的参数)表示每个目标域样本被识别为相应类别的概率;接下来,通过对抗训练获得域不变特征;此外,通过提高样本特征矩阵中较小的奇异值,提升对应特征向量的重要性,从而提高模型的可辨别性。
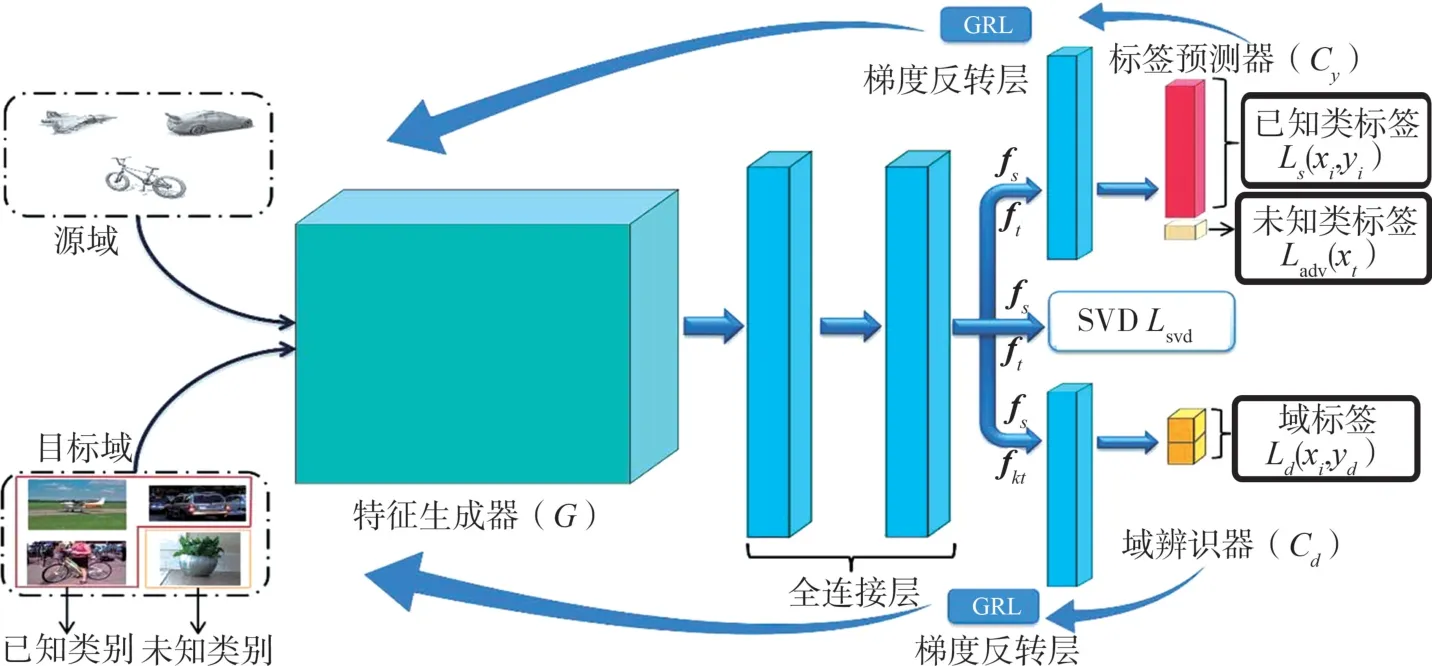
图2 本文提出的改进的域自适应方法
具体训练过程如下所述。首先,将源域中的带标签样本进行正确分类,此时源域中的分类损失函数LS应最小,对应的公式如下
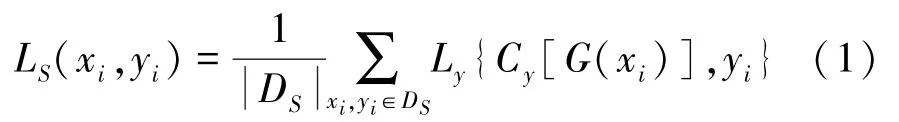

之后,在目标域中的已知类别和未知类别之间建立边界。类似于文献[11],这里将未知类别的概率设置为β用于训练分类器,并通过训练特征生成器提高分类器的性能。最终的输出可视为一个二分类任务,也即Cy识别的所有K个已知类别的概率之和,与第K+1个类别即未知类别的概率。二者通过对抗训练,相互博弈。具体来说,生成器通过增加或减小未知类别的概率使得K+1类的输出偏离β,从而增大分类器的误差,此时分类器需要使得第K+1类的输出概率接近β,以减小分类器误差。如果生成器选择增加未知类别的概率β,这意味着将样本识别为未知类别,否则识别为已知类别。通过上一步对源域中标签样本的训练,网络已具备了一定的辨别能力,经过多次迭代,最终可正确识别出未知类别。因此,Ladv使用二分类交叉熵损失,公式如下
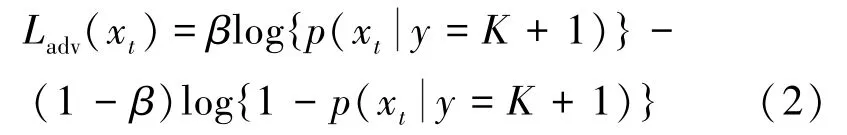
其中,xt表示目标域的样本,p(xt|y=K+1)表示样本xt属于第K+1个类别的概率,β为未知类设置的一个超参数,这里将β设置为0.5,以达到在目标域中分离未知类别样本的目的。
2.2 奇异值平衡
通过之前的研究,可以知道特征的可迁移性主要取决于较大奇异值对应的向量。对于域自适应,可迁移性的增加将导致奇异值分布的不平衡,这将对网络的可辨别性产生不良影响。此外,可迁移性的增强是通过牺牲其他相对较小奇异值对应的向量为代价实现的,这些向量具有不同的信息,对准确识别发挥着至关重要的作用。文献[23]通过最大化矩阵核范数提高了标签预测矩阵的可分辨性和多样性。本文中,通过使用奇异值分解获得较小的奇异值并增加它们,一方面减小对最大奇异值的影响,保持特征的可迁移性;另一方面相当于间接减小最大奇异值,平衡奇异值的分布,提高特征的可辨别性。对应的公式如下
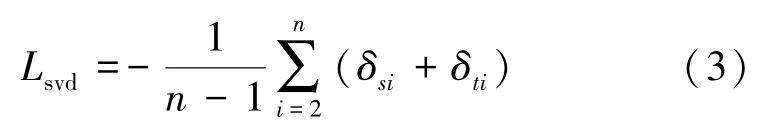
其中,δsi和δti分别表示源域特征矩阵fS和目标域特征矩阵ft中第i大的奇异值。例如,δs1为源域特征矩阵最大的奇异值,δsn则表示源域特征矩阵第n大的奇异值,n的取值一般为批训练大小。此外,由于源域和目标域的差异性,对源域和目标域单独进行奇异值分解操作。
2.3 域对齐
由于不同域中样本特征的分布不同,因此,提取两个域的共同特征变得至关重要,这也是实现域自适应的关键。基于对抗思想的特征对齐,通过特征提取器和域辨别器的相互对抗,学习到域不变特征。如果不考虑目标域中的未知类别,直接进行域不变特征的提取,最后强行将两个域的特征分布对齐,会造成已知类与未知类的不匹配,模型的性能会下降,造成负迁移。因此,要先对目标样本进行筛选,剔除其中的未知类别。具体而言,首先获得目标样本xt预测为各个类别,即K+1类的概率。如果概率最大的类别是已知类别,且概率值大于预设阈值P,则将该样本标记为目标域中的已知类别,对应的公式如下
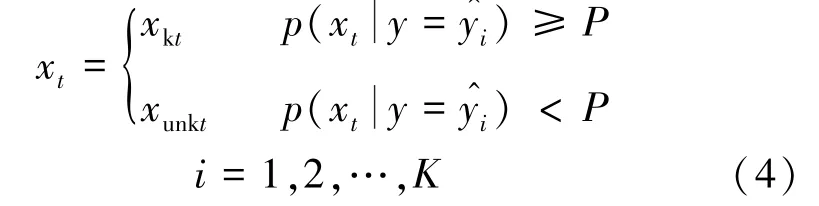
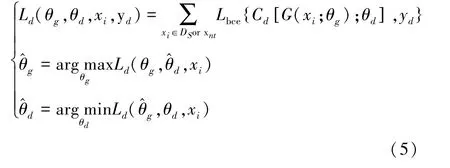
之后,将源域样本和目标域中识别为已知类别的样本输入特征生成器G,再将生成的特征输入给域标签鉴别器Cd。为获得域不变特征,特征生成器G需最大化域辨别误差Ld,域鉴别器Cd则要最小化域分类误差Ld,公式如下其中,Lbce表示二分类交叉熵损失,θg和θd分别表示特征生成器G和域标签鉴别器Cd的网络参数,训练样本xi来自源域或目标域中的已知类别xkt,yd表示相应的域类别标签(1或0)。 利用式(5)中的最后两个公式分别更新特征生成器的参数θg和域鉴别器的参数θd。 为有效计算梯度和更新参数,这里使用了梯度反转层。因此,网络最终的损失函数计算公式为
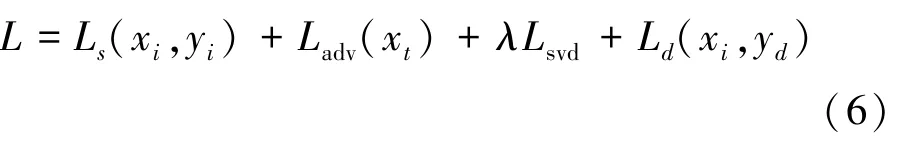
其中,λ设置为2。因此,网络参数的训练目标如下
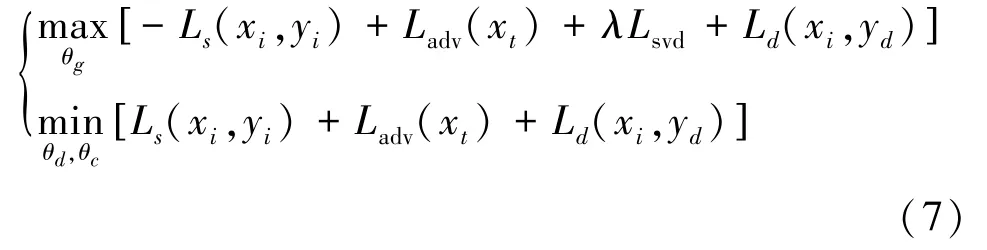
3 实验结果
利用Office-31和Visda-2017两个公开数据集评估本文所提方法的性能,并与其他一些最新的开集域自适应方法进行比较。为证明本文所提方法的有 效 性,分 别 使 用 AlexNet[24]、ResNet-50[25]和VGG[26]作为特征提取网络,并利用ImageNet[27]的预训练模型作为初始神经网络参数,同时在网络中加入批量归一化和Leakly-ReLU层。对于网络参数的更新,选用了带动量的随机梯度下降更新策略,学习率设为1.0×10-3,动量设为0.9。
此外,将所有类别的平均准确率表示为OS,已知类别的平均准确率表示为OS*,目标域中未知类的准确率表示为UNK。
3.1 实验介绍
Office-31[28]是域自适应领域的一个标准数据集。该数据集共有三个域:Amazon(A),Webcam(W)和DSLR(D)。它总共包含来自31个类别的4 652张图像,图3(a)展示了其中的一些图片样本。按照文献[10]提出的数据集划分,这里使用其中10个与Caltech数据集[29]重叠的类别样本作为已知类别样本;之后按照字母顺序,将第21至31类别样本作为目标域中的未知样本。由于本次实验目的是将目标域样本正确分类为10个已知类和一个未知类,因此这里丢弃了第11至20类别。为公正地评估本文所提方法的性能,这里采用了文献[11]中的实验设置。在该数据集上,使用Alexnet和Resnet-50作为网络的特征提取器,且将提取的特征输入两个全连接层后,分别送入标签预测器和域辨别器进行训练。由于Resnet-50具有更深的网络结构,因此表现出了更好的性能。实验结果如表1所示,这是600个epoch之后的结果。由于该数据集不同域之间的语义信息和分布比较接近,因此域间差异相对较小,准确率也较高。
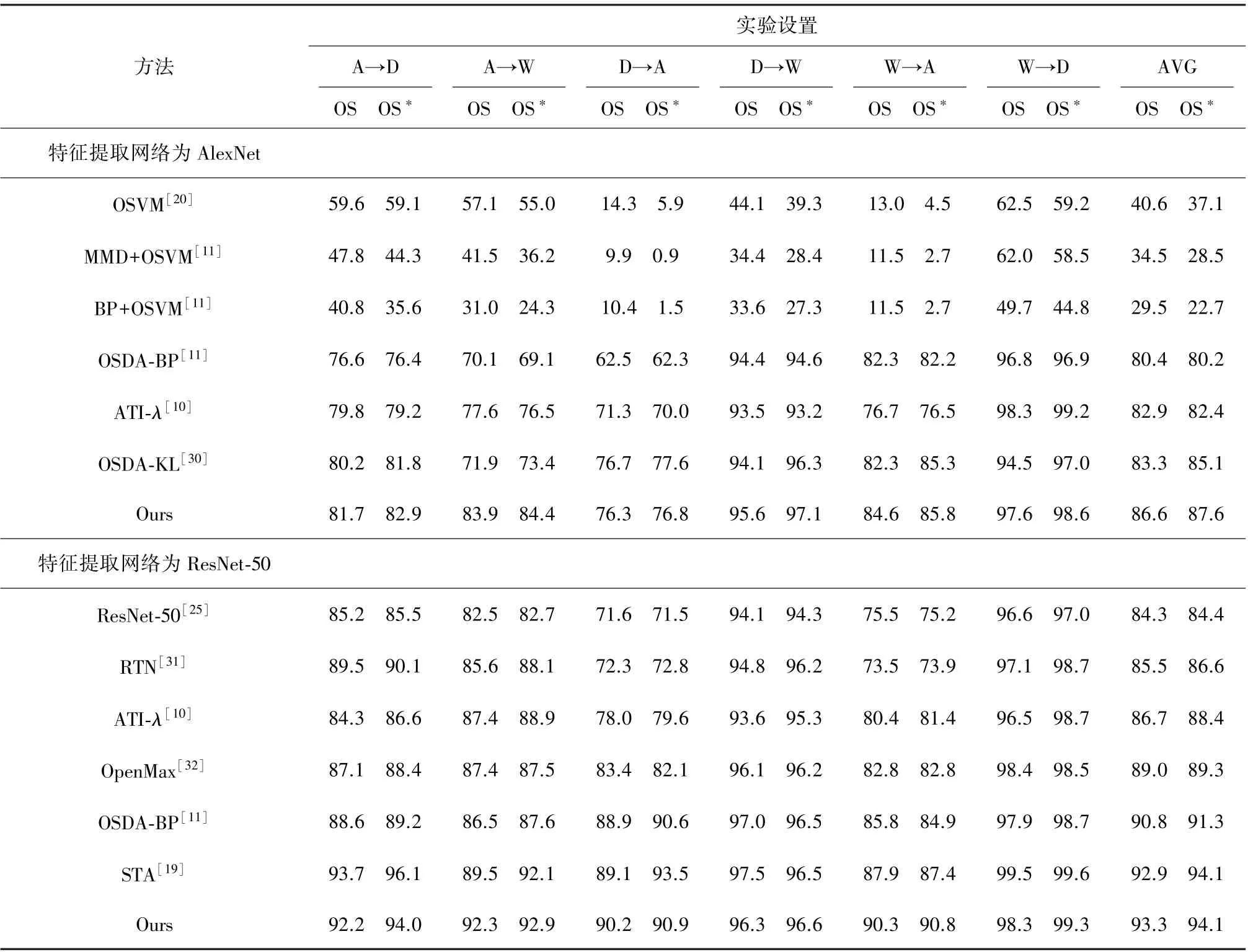
表1 Office-31数据集上的准确率 %
VisDA-2017[33]是一个大型的域自适应挑战数据集。该数据集共有两个域(合成域和真实域),每个域包含12个类别,其中,作为源域的“合成域”约有15万张图片,这些图片为从不同角度和不同光线对3D合成对象截取的2D图像,作为目标域的“真实域”约有5万张真实场景下的图片。图3(b)展示了其中的一些图片样本。根据文献[11]中的实验设置,这里将目标域中的六个类设置为未知类,且在训练过程中将源域中的这六个类别的图片剔除,不让它们参加训练。VisDA-2017数据集与实际应用场景更加吻合,该数据集具有更大的“域间距”,即可从语义相关的标记样本域中获取有价值的信息。实验结果表明,本文所提方法在总体性能上要优于其他一些方法。在本次实验中,由于训练样本较多,因此选择VGG作为特征提取网络(特征生成器)。VGG提取的特征会经过三个全连接层,然后进入标签预测器和鉴别器部分。在此次实验中,批训练大小设置为32。表2表示15个epoch之后的实验结果。
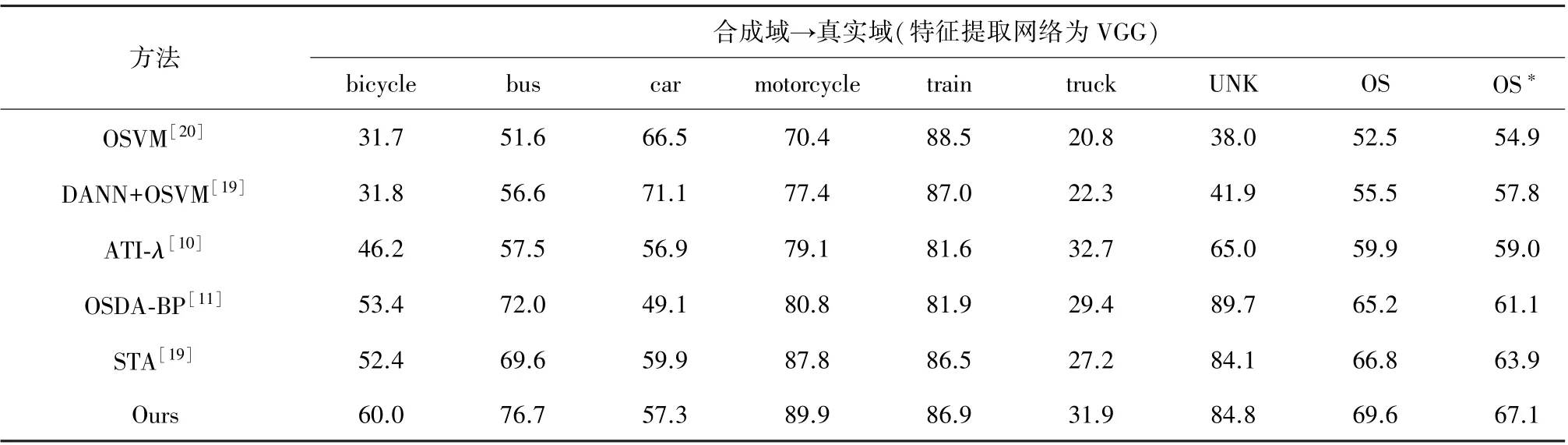
表2 VisDA数据集上的准确率 %
3.2 β的影响
本次实验也探究了β对实验结果的影响。不同的β值,OS、OS*和UNK的实验结果如图4所示。从图4所示结果可以清楚看到,随着β值的增大,OS和OS*不断减小,而UNK却在不断增大。未知类别的准确性和β值具有相同的趋势,这与文献[11]的结论是相似的。当β取0.5时,模型总体性能较为均衡。
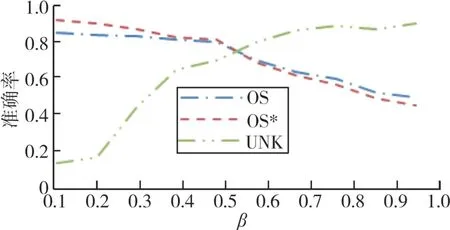
图4 不同β值下实验结果的变化(A→D)
4 结束语
本文通过使用奇异值平衡和基于对抗思想的特征对齐,提高了开集域自适应的性能。在样本特征矩阵中提升了较小的奇异值,以获得更多信息用于提高特征的可辨别性;同时,采用对抗学习的思想,对齐了源域和目标域中已知类别的特征分布,获得域不变特征。实验结果表明,本文所提方法可有效提高开集域自适应的性能。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
计算机技术与发展(2020年11期)2020-12-04 07:50:46
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
新校长(2016年8期)2016-01-10 06:43:59
电子与信息学报(2015年12期)2015-08-17 11:14:42
商事法论集(2014年1期)2014-06-27 01:20:42
电测与仪表(2014年15期)2014-04-04 12:05:20
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
