
一种基于深度学习的网络流量细粒度分类方法
2021-08-26 08:40:18董育宁
南京邮电大学学报(自然科学版) 2021年3期
孔 镇,董育宁
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
网络流量分类是网络研究的一个重要分支[1]。随着网络视频需求的增加,正确分类网络视频服务类型,对网络资源管理和提升服务质量有着重要意义。根据思科白皮书显示,到2023年,视频流量将占所有网络流量的82%[2]。由于视频业务对带宽以及延迟抖动的要求都比较高,所以网络拥塞现象会变得严重,从而给网络管理带来不小的挑战[3]。因此,对视频流量进行细粒度分类能够帮助互联网服务商(ISP)根据不同的视频质量需求提供有区别的网络资源配置,从而保证服务质量(QoS)[4]。然而,众多新应用的出现以及网络加密技术和动态端口的应用,对网络流量分类产生了极大的挑战[5]。
当前,网络流量分类方法主要可以分为:基于端口、基于深度包检测(DPI)[6]、基于传统机器学习(ML)[7]的分类方法,以及基于机器学习中最新的深度学习(DL)[8]方法。由于越来越多的应用采用动态端口号,以及流加密技术的普遍使用,前两种分类方法不再有效。传统ML的网络流量分类方法可以避免前两种方法的不足,主要有SVM[9]、随机森林[10]、k均值[11]和高斯混合模型[12]等算法。 该分类方法基于这样一个事实:不同的应用在进行网络通信时会有不同的流行为特征,根据这些特征就能够对其进行分类[13]。然而,由于不同的应用,其特征不尽相同,因而挖掘这些特征需要一定的领域知识和大量的时间[14]。因此,传统ML分类方法在特征设计和选择方面有着新的挑战[15],而这些问题直接影响分类效果[16]。最近,DL在许多方面取得了成功[17],特别是卷积神经网络(CNN)在图片分类方面的应用,它能够自动地从原始数据中学习到特征,这一特点使得其自然地弥补了传统ML的缺点[18]。因此,CNN开始被应用于网络流量分类中,并得到了不错的结果[19]。然而,使用有效载荷数据作为模型输入的方法无法处理加密流量。因此,有必要研究采用其他信息,如文献[20]使用了单向流统计信息。但该方法得到的信息不充分,会影响分类效果。针对此问题,本文提出一种改进方法,使用流的双向信息以及交叉信息作为CNN输入,以期改善对网络流量细粒度分类的效果。
本文所说的细粒度分类,是将同一大类业务(例如,视频业务、音频业务等)进一步分为子类业务(如,将视频业务细分为不同分辨率的视频流等)[21]。目前,对网络流量的细粒度分类面临着诸多挑战,这是由于各子类之间存在许多相同或相似的特征;例如,同一视频业务上不同分辨率的数据在协议、端口号、加密方式等方面是相同的。目前似乎较少见用DL进行网络流量细粒度分类的文献报道。
本文通过对采集的网络视频流量进行分析,并针对视频流量多采用加密处理的特点,提出了一种适用于CNN的数据处理方法。它只使用数据包相关的特征,例如包到达时间、包大小、包的方向等。然后将这些信息映射为图片,并将得到的图片训练以及测试CNN,得到细粒度分类结果。本文分类的视频数据集包含3种不同分辨率的点播和直播视频数据,共6个子类:点播480p、720p、1 080p,和直播480p、720p、1 080p。视频流量数据采自中国主流视频网站,包括哔哩哔哩视频(https://www.bilibili.com),腾讯视频(https://v.qq.com),优酷视频(https://www.youku.com),斗鱼直播(https://www.douyu.com)和虎牙直播(https://www.huya.com)。同时,为了验证该方法的性能,同样使用了“ISCX non-VPN”数据集实现粗粒度分类,该数据集包含4种网络业务类型,包括语音通话(audio),视频通话(video),文字聊天(chat)和IP语音(VoIP)。表1和表2给出了这两个数据集的详细信息。本文旨在不进行特征设计的前提下实现对网络流量的细粒度分类。实验结果表明,本文所提的方法相比于现有方法,具有较高的分类准确率。本文的主要贡献有以下3点:

表1 视频数据集信息

表2 “ISCX non-VPN”数据集[22]信息
(1)提出了一种扩展特征信息的方法。与已有的方法不同,本文方法所生成的图片中包含了双向流的信息以及交叉信息。这些信息转化为图片形状反映出来。
(2)避免了特征设计过程。以生成的图片为输入,使用CNN模型进行分类;相比于传统ML方法,它不仅能够自动寻找特征,还能自动更新特征。
(3)本文方法对不同粒度的网络流量分类任务都有较好的表现。相比于已有方法,本文方法在粗分类和细分类上都具有优势。
1 相关工作
Qin等[15]提出了一种避免特征设计的网络流量分类的方法,通过计算双向流数据包中有效载荷大小分布概率函数(PSD),并使用Renyi交叉熵计算PSD与某一应用的相似性,从而达到分类目的。在DL方法研究方面,Wang等[23]将数据包的头部信息和有效载荷信息转化为图片并用CNN模型进行正常和恶意流量的分类,取得了较好的结果。在文献[24]中,Wang等应用同样的方法对包括VPN与non-VPN在内的12类使用1D-CNN进行分类,并指出,使用1D-CNN比使用2D-CNN的分类效果要好。Lotfollahi等[25]使用了类似的方法,区别在于他们是基于包级别的;他们使用IP头部信息和前1 480比特的负载信息,基于1D-CNN和栈式自动编码(SAE)模型进行分类。Lim等[26]将有效载荷转换为比特序列,并把每4比特分为一组再转换为十进制数作为图片像素的大小,实验表明使用有效载荷信息越多,CNN模型的分类效果越好;这是由于使用的有效载荷信息越多,CNN模型得到的信息越多。在文献[27]中,作者使用统计特征与包特征相结合的方法对QUIC协议的流量进行了分类。他们首先使用统计特征和随机森林算法区分出Google Hangouts流量,然后使用CNN模型对其余流量进行分类,包括Google play music,YouTube等。
上述方法都是基于有效载荷信息,对于某一应用来说,由于其字节结构相同,这就可能导致过拟合问题[20]。因此,Salman等[28]提出了一种新的数据表示方法,把网络流的相关信息数值化,并将数值化的信息作为图片的像素值,生成RGBA图片;这些信息包括:数据包到达时间间隔(t),数据包大小(s),协议(p)和流的方向(d)。Shapira等[20]使用单向流的相关信息生成了图片,将包到达时间和数据包大小归整到1至1 500,作为图片像素点的坐标,将在该时间间隔内,具有同样大小的包的数量作为像素值,从而生成1 500×1 500的图片。每张图片包含60 s单向流的数据包信息。
CNN[29]已广泛应用于图像分类。由于CNN具有权值共享和平移不变形的特性,相比前向反馈的神经网络,相同层数的CNN有更少训练参数。一个典型的CNN包含5部分:输入层,卷积层,池化层,全连接层和输出层,如图1所示。卷积层的输出叫做特征图,它是由前一层与卷积核卷积之后再通过激活函数映射得到。常用的激活函数有ReLu函数,Sigmoid函数等。卷积层后的池化层能够减少参数数量并降低网络的计算复杂度。例如,平均池化的输出是矩阵邻域内所有值的平均。CNN的输出层通常为SoftMax函数,它的输出是范围为0至1的K维概率分布向量;向量中的值代表某一类分类得到的分值。
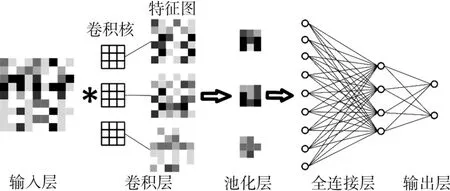
图1 CNN结构图
将带有标签的图片读入CNN后,通过后向传播算法(通常是梯度下降算法[30])不断调整网络的权重以使得代价函数达到最小,是CNN训练的基本过程。另外,在训练过程中通常会使用dropout技术和L2正则化技术以避免过拟合问题。
受以上研究启发,本文提出了一种新的将流量数据表示为图片的方法。它利用双向流的相关信息生成图片,图片包含了4部分,分别为上下行数据流信息和交叉信息,这些信息通过图片上像素点的位置以及像素值大小来表示。然后将生成的图片使用CNN模型进行分类。
2 本文方法
2.1 数据集
使用的数据集包括视频数据集和“ISCX non-VPN”数据集。视频数据集(见表1)是通过Wireshark(https://www.wireshark.org/#download)软件采集得到;时间为2019年2月和2020年1月,总数据量约50 GB。其中,每一类数据都在两个以上的应用上采集。“ISCX non-VPN”数据集(见表2)是New Brunswick大学Gerard Drapper Gil团队采集的一个公开数据集,本文使用了其中的4类网络流量数据。
2.1.1 数据预处理
首先,从采集的PCAP格式文件中提取出双向数据流。所谓流,就是五元组相同的数据包的集合,即源IP地址,目的IP地址,源端口号,目的端口号,协议都相同。其次,去掉不相关流数据和控制流。最后,将数据流分段为60 s[20,22]的子段文件,保存在相对应的类别中。
2.1.2 图片生成
本文生成的图片包含4部分特征信息:上下行特征信息和交叉特征信息;每一部分都是基于数据包大小,方向以及到达时间的二维直方图在图片上的表示。
首先,提取双向流包的相关信息(包到达时间,包大小,包的方向)组成向量[t,s,d]。其次,根据数据包的方向将数据包大小以及数据包到达时间规整到1至750或751至1 500之间。具体来说,将当前包到达时间减去第一个包到达时间得到的数值进行规整,如果是下行包的到达时间,则规整到1至750(即60 s映射为750),如果是上行包的到达时间,则规整到751至1 500(即60 s映射为1 500)。同样地,将下行包大小规整到1至750,将上行包大小规整到751至1 500。由于最大传输单元为1 514,因此,对于下行包大小是1 514,则被规整为750,上行包大小是1 514,则被规整为1 500。然后,将规整后的包到达时间和包大小作为坐标,统计在相同的时间间隙内具有同样包大小的数据包数量,作为该坐标位置上的像素。最后每60 s的数据生成一张图片。这样,每张图片就包含了4部分,分别为下行数据包到达间隙内下行包的统计,上行数据包到达间隙内上行包的统计,下行数据包间隙内上行包的统计以及上行数据包间隙内下行包的统计,其中后两种为构建的交叉信息特征。图示2显示了将流量数据转化为图片的示意图。表1、表2中列出了每一类别所得到的样本数量。
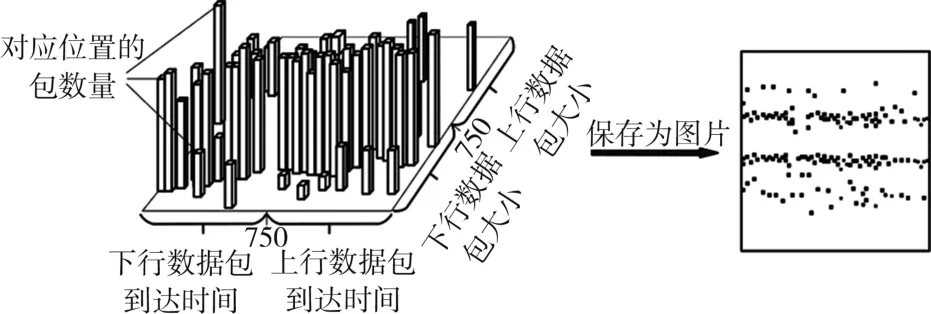
图2 数据表示为图片示意图
2.1.3 可视化分析
图3给出了生成的图片样例,从图上可以看出,每张图片有4个各不相同的部分。需要说明的是,图上黑色像素点表示像素值在1至255之间,白色像素点表示像素的值是0,它表示在相应的时间间隙内没有任何包到来。实际上,对视频数据集中所有类的样例图,都能明显地看出各类之间的差异;这是由于每一种网络服务在服务器与客户端通信时都会有不同的行为表现,显示在图片上就是不同类别得到的图片的纹理风格有较大的区别。例如,对于直播和点播来说,其下行数据包大小规整后都广泛分布于1至750之间(即图片上半部分)。但是,相同时间内直播数据包数量要远远多于点播的数据包数量,表现在图片上就是图片上半部分直播的像素点要比点播的更稠密。另外,视频数据集中每一类的流量数据都是在不同的应用中采集的,从图片中可以看到,同一类别中不同应用的数据所生成的图片有较大的相似性。同时,也注意到,同种视频服务不同分辨率之间也有相似性;这是由于对于点播视频服务来说,虽然分辨率不同,但在服务器与客户端通信时具有相似的行为特征,即当缓冲器满时,就停止下载数据,当缓冲器空闲时,数据开始下载。然而,尽管如此,不同分辨率之间仍然有较大的区别,比如数据量多少,同一时间间隙中的包的数量等。这些区别通过本文方法转化为图片后,在图片上都能够通过像素点的位置及像素值大小反映出来。

图3 生成的图片样例
通过以上分析可知:对于不同类别的数据生成的图片,它们之间都有较大的差异性;对于同一类别来自不同应用的数据生成的图片,它们又有较高的一致性;这使得对视频流量进行细分类成为可能。另外,对比文献[20],本文方法得到的图片中包含了更多的特征信息,不仅增加了上行数据的流信息,而且增加了上下行的交叉信息,所以有理由相信本文方法能得到最优的结果。
2.2 CNN结构
本文旨在通过将网络流量数据转化为图片并应用简单的CNN模型对网络流量进行分类。本文使用的模型共7层,其输入是前文所述方法得到的1 500×1 500的图片。接下来是卷积层—池化层—卷积层—池化层—卷积层的结构(分别记为CONV1,POOL1,CONV2,POOL2,CONV3)。卷积核大小为5×5,使用ReLU作为激活函数。初始学习率设置为0.05,本文采用最大池化技术,其每个单元与特征图上的2×2的邻域相连接。卷积-池化计算之后,使用flatten函数将特征图转换为一维向量接入两层的全连接网络。最后,使用SoftMax函数作为输出层。另外,为了防止过拟合,在训练阶段使用了dropout技术,丢弃率为0.5以及L2正则化技术,权重衰减系数为0.99。
将得到的图片按照10∶1的比例随机分为训练集和测试集,并使用TensorFlow平台搭建CNN模型对图片进行训练和测试,并保存训练过程中结果最好的模型。本文方法的流程图见图4。
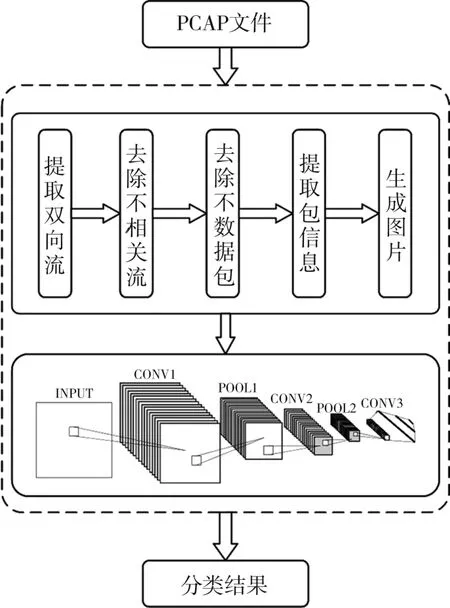
图4 本文方法流程图
3 实验结果与分析
本节介绍实验结果并与已有文献方法进行对比。实验电脑配置为64位Windows10操作系统,英特尔酷睿I5-1035G1 CPU,16 GB内存。使用基于TensorFlow平台上的Keras库搭建CNN模型。
3.1 实验叙述
为了验证本文方法的分类效果,使用“ISXC non-VPN”数据集[22]和视频数据集进行分类实验,并与文献[20]与[24]方法进行性能对比。另外,分别选择了30 s,45 s,60 s,75 s的包序列生成图片,探究不同时间尺度生成的图片对分类结果的影响。
3.2 评价标准
准确率(acc),精准率(p)、和f1测度(f1)是分类问题中常用的评价标准,定义如下:准确率用来描述分类器总体的表现,精准率用来评价分类问题中每一类的分类情况,f1测度常用来衡量分类器的性能。
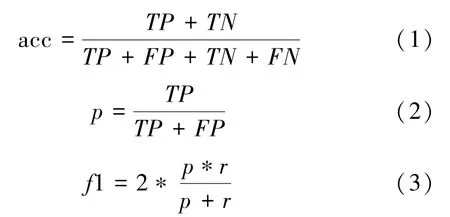
3.3 实验结果
3.3.1 对不同粒度网络流量分类效果对比
对本文方法以及文献[20]、[24]方法在两个数据集上进行粗粒度(ISXC non-VPN)和细粒度(Video)分类实验。表3给出了3种方法的总体准确率比较。表4和表5分别给出了不同数据集上的精准率和f1测度。为了更好地评估不同方法的分类效果,图5和图6分别给出了不同方法得到的混淆矩阵。

图5 不同方法在视频数据集上得到的混淆矩阵

图6 不同方法在“ISXC non-VPN”数据集上得到的混淆矩阵

表3 不同方法的acc(均值±标准差)比较 %
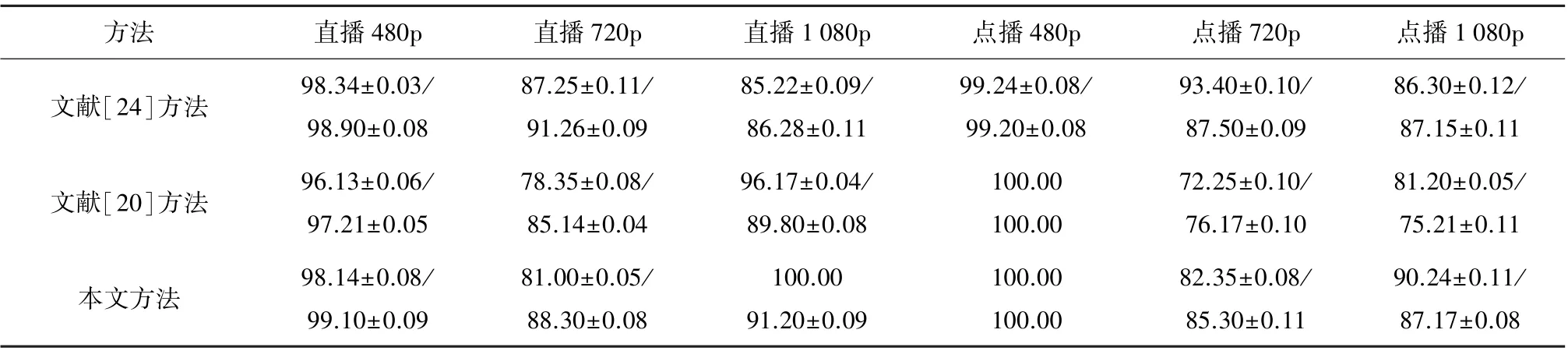
表4 不同方法在视频数据集上p和f1(均值±标准差) %

表5 不同方法在“ISXC non-VPN”数据集上p和f1(均值±标准差) %
3.3.2 不同时间尺度生成图片的表现
为了探究使用不同时间尺度生成的图片对于细粒度分类的影响,我们对视频数据集分别使用30 s,45 s,60 s和75 s的流数据生成图片并训练和测试。图7给出了不同时间尺度得到图片的分类准确率。
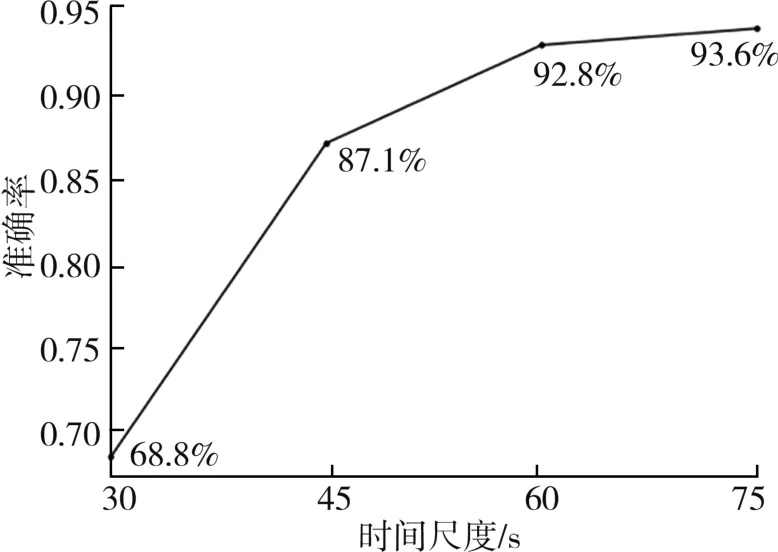
图7 不同时间尺度的细粒度分类准确率
3.4 结果讨论
从表3中可以看出,就总体准确率而言,本文方法较其他两种方法有所改善。其中,对于粗粒度分类,本文方法的分类准确率达到了98.58%,较文献[24]方法提高了6.3%,比文献[20]方法提高了2.86%;对于细粒度分类,本文方法比文献[24]方法略有改善,而相比于文献[20]方法,则有明显提高(4.7%)。这是由于相比文献[20]方法,本文方法所生成的图片中包含了更多的信息。首先,本文方法生成图片时加入了上行流信息,而文献[20]方法只使用单向流信息。图8给出了视频流数据集的不同类中,上行包到达时间的累计密度函数(CDF)曲线,它反映了样本本身的特征分布。从图中可以看出,不同类别中上行数据包到达时间分布不同;因此,加入上行数据能够增加各类之间的差异度。其次,本文方法的图片中包含了交叉信息,包括对在下行包间隙内出现的上行数据包统计以及在上行数据包间隙中出现的下行数据包的统计。这些有效信息的加入,对原始数据有了更细致的描述,对于提高分类器的性能有帮助。因此,相比于文献[20]方法,本文方法提高了分类准确率。文献[24]方法使用包头部信息以及部分有效载荷信息,虽然头部信息包含了网络连接时的特征,但这也使得分类结果与其密切相关。因此,与细分类相比,在进行粗分类时,本文方法与文献[20]方法准确率都有明显的提升,而比文献[24]方法却略微下降。这是由于“ISXC non-VPN”数据集中每一类有多个数据来源,并且每一个数据来源由不同的用户采集得到,这就使得数据包的头部信息存在较大差异,而文献[24]方法分类又依赖这些信息,因此使得其粗分类结果反而低于细分类。
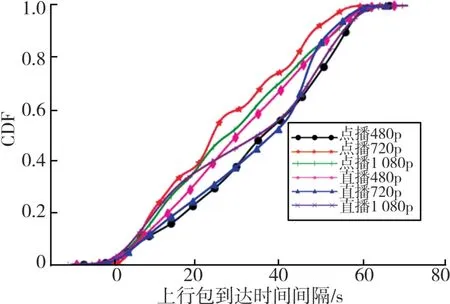
图8 视频流数据集上行流中包到达时间间隔的CDF曲线
通过表4给出的精准率和f1测度可以看出,本文方法的细分类结果要优于文献[20]方法;这表明加入了上行特征确实能够提高分类表现。值得注意的是,在直播和点播720p上,文献[24]的表现好于本文和文献[20]方法。通过对数据和数据源研究发现,斗鱼直播网站对于同为标注720p的视频,其帧率有所不同(有的帧率为30帧,有的为40帧),这就导致了同一分辨率下40帧时得到的数据量(包括相同时间间隙内数据包的数量,数据包的大小等)要多于30帧时得到的数据量,从而使本文方法在分类直播720p时,准确率有所下降。通过图5(c)的混淆矩阵可以看到,有相当比例的直播720p样本被错误分成了直播1 080p,这也印证了本文猜想。而文献[24]方法未受此影响。类似地,由于点播720p中有些数据来源为腾讯视频(见表1),而腾讯视频采用的是动态帧率,这同样造成了本文方法对点播720p识别率低的问题。另外,从混淆矩阵中看到,文献[20]和文献[24]方法中存在直播样本错分为点播样本以及点播样本错分为直播样本的情况,而本文方法得到的混淆矩阵则不存在这种情况,这也反映了本文方法相比于文献方法存在优势。从表5中看到,3种方法对audio,chat和VoIP类都能够较好地识别,在video类上,文献[24]方法表现较差(75.8%),通过图6(a)的混淆矩阵看到,有较多的video被错误分成了audio。由于Gil团队没有给出所采集数据的详细说明,因此,无法对此进行详细分析。不过,文献[24]在文中也指出了对non-VPN的分类结果并不理想。
从图7可以看到,选择不同时间尺度所生成的图片对视频数据细分类的影响较大,特别是当时间尺度比较小时,分类效果一般。图中30 s生成的图片得到的准确率仅有68.8%。而增大时间尺度能明显提高分类准确率;当时间尺度大于60 s时,分类准确率趋于平稳。这是由于,对于视频流量来说,在较短的时间内,服务器与客户端之间数据传输还没有达到平稳状态,网络波动比较大,因此较短时间内的数据分类结果不理想。
综上,可以得到以下结论:对于不同的分类任务,相比于文献[20]方法,本文方法对图片中的特征信息做了扩展,包含了上下行流信息和交叉信息。可以认为,文献[20]方法所得图片中的信息只是本文方法所得图片中的一部分,因而不如本文方法好;对于使用有效载荷信息以及包头部特征作为输入来说,其分类效果与数据包的内容紧密相关,这种方法易受网络环境影响。因此文献[24]方法粗分类的表现反而比细分类略微下降。另外,在无法获得有效载荷信息的情况下,文献[24]方法是无效的,这也使得该方法泛化性能较差。相比之下,本文方法只使用了数据包的统计信息,因而更具有一般性。同时,对于视频流量来说,较短时间内流数据可能会达不到平稳状态而影响结果。
4 结束语
面向未来多样化和精细化的网络服务,需要更优化的网络资源分配机制和服务质量保证。因此,需要对网络流量进行细分类。本文提出了一种适用于网络流量细分类的方法;它把数据包特征转化成图片的形式,应用CNN模型对网络流量进行分类。实验表明,该方法对于网络流量粗分类和细分类都能取得较好的结果。本文方法相比于基于传统ML的流分类方法,能够自动地寻找特征,省去了特征设计和提取环节。此外,DL方法还能够根据新类别的出现或者网络技术的改进自动地更新特征,从而不需要再次设计特征。同时,相比于其他基于DL的网络流量分类方法,本文方法在只使用数据包统计特征基础上对数据进行了扩充;相比于使用有效载荷信息的DL方法,避免了隐私和安全问题。
通过实验发现,面对动态帧率时,本文方法存在不足。下一步,将改进此方法以适应动态帧率下的流量细分类。同时,对于视频流量来说,由于受网络影响较大,需要较长时间的数据来进行分类,今后将研究改进措施。另外,我们也注意到,使用DL方法的计算复杂度较高,且增加新类时无法对参数进行局部调整,因此需要网络重新学习,这增加了工作量。因此,今后可以考虑在计算量与分类效果之间寻找平衡以及其他DL模型对网络流量细分类的应用。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22 09:52:26
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
微型电脑应用(2021年3期)2021-03-31 08:56:46
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
网络安全和信息化(2018年4期)2018-11-09 12:01:54
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
北京航空航天大学学报(2017年7期)2017-11-24 05:27:28
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
中国新通信(2014年11期)2014-09-11 19:27:52
河南科技(2014年23期)2014-02-27 14:18:43
