
卷积神经网络在图像识别中的应用研究综述
2021-08-24 03:06盖荣丽蔡建荣王诗宇
小型微型计算机系统 2021年9期
盖荣丽,蔡建荣,王诗宇,仓 艳,陈 娜
1(大连大学 信息工程学院,大连 116622) 2(中国科学院大学,北京 100049) 3(中国科学院 沈阳计算技术研究所,沈阳 110168)
1 引 言
作为计算机视觉领域的一个重要分支,图像识别研究始于上个世纪40年代,60年代随着人工智能的出现而得到了迅速发展.在过去的几十年间,图像识别的应用领域已经覆盖了军事、安全、生物医学、农业、自动化等人类社会生活的许多方面.传统的图像识别方法有:反向传播算法[1]、贝叶斯分类法[2]等.这些传统的识别方法主要提取像素级的低级特征且需要人为进行预处理操作,影响了图像的识别精度.人类视觉的处理过程将对图像内容的理解转化为对低层特征的语义理解,并将其逐层映射到高层领域,深度学习很好地模拟了该过程[3].因此,利用深度学习方法进行图像识别将大大地提高图像识别准确率.
图像识别是区分不同类别的图像,卷积神经网络(Convo-lutional Neural Network,CNN)是完成图像识别任务的最佳算法之一[4],设计卷积神经网络的目的就是模仿人类的学习模式,通过对输入样本的训练与测试,由简到深地提取特征来区分样本.神经网络可降低图像分类误差,得到高识别率.文章从算法运用方面指出卷积神经网络在各领域图像识别中的优点和缺点,为今后更深一步研究提供参考.
2 卷积神经网络概述
卷积神经网络[4]是一种前馈多层网络,信息的流动只有一个方向,即从输入到输出,每个层使用一组卷积核执行多个转换.CNN模型主要包含卷积层、池化层、全连接层.以CNN模型为基础,将多层卷积和多层池化结合产生新的网络模型,可提高网络结构的准确度.经典的卷积神经网络模型有GoogLeNet、AlexNet、VGGNet等[5].
利用CNN进行图像识别将图像直接输入到模型,不需要传统算法中的预处理和特征提取过程就可以保留图片本身的结构,从而降低模型处理复杂度.与其他神经网络的不同之处在于,CNN中存在一层或多层中的矩阵乘法运算被替换成卷积运算,其利用多层神经网络和图像局部性的优点减少了大量参数,提高模型训练速度.最初CNN被广泛应用于目标识别任务,目前在目标跟踪、姿态估计、文本检测与识别、视觉显著性检测、动作识别、场景标记等任务中也表现出了出色的性能.
CNN的基本结构为特征提取层和特征映射层.通过层间的感受野相连,提取局部特征.特征映射结构主要是使用Sigmoid函数对卷积神经网络进行操作,保证其位移不变性.卷积层是CNN中最基本的也是最重要的一层,基本上是对给定图像的像素矩阵进行卷积或乘法,以生成给定图像的激活映射(activation map),连接一个计算层,该计算层求得局部平均和二次提取特征,该操作减小了特征分辨率.卷积神经网络LeNet-5的模型结构如图1所示.
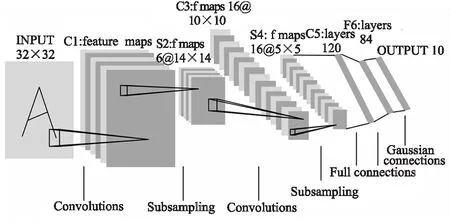
图1 卷积神经网络LeNet-5模型结构图[6]
3 在图像识别中的应用研究
基于卷积神经网络的图像识别技术由于提取特征能力强、识别精度高以及实施性强等优点,在人脸识别、人体动作识别、医疗图像、农作物病虫害等方面运用广泛,从2012年提出的AlexNet到2014年谷歌提出的GoogleNet图像分类错误率在数据集ImageNet上由16.4%降到6.7%.2015年,微软研究员提出PReLU-Nets[7]模型在ImageNet数据集上使得图像分类错误率降为4.94%,该模型成为第一次人脸识别错误率较低的模型.以下列举了卷积神经网络在人脸识别、人体动作识别、医疗图像处理、农业病虫害识别等领域的应用.
3.1 人脸识别
人脸识别(Face Recognition,FR)技术利用计算机学习通过人脸特征来提取个人信息,由于稳定性好从而逐渐运用到监控系统、智能支付、公安系统等应用中.
人脸检测自动检测人眼、鼻子等部位的轮廓点等人脸特征点,从而实现人脸关键点的高精度识别和定位,许佳等人提出了基于深度学习的人脸识别定位方法来使人脸关键点识别的应用性变强[8].
传统的人脸识别方法主要分为基于统计、知识两大类,如基于模版匹配等方法.人脸识别大多采用视频进行检测,由于人脸的表情、姿态、年龄、位置等引起的类内变化以及外界光照、背景等身份不同引起的类间变化从而影响视频检测人脸的精度,因此基于视频的人脸识别仍然是一个重大的挑战.为了提高人脸识别率,需要增强人脸特征对这些因素的鲁棒性[9].
采用聚合模型可以基于视频对人脸进行检测,Peng[10]等提出了基于几何特征的聚合方法,参考每个帧的重要性和帧与帧在特征空间中的几何关系.基于注意力的聚合网络在所有帧中沿着每个特征维度自适应地对特征进行加权,能够自适应地、细粒度地度量特征在所有帧中的重要性.
由于视频中存在图像模糊、表情姿态动态变化的情况,会导致识别精度较低.基于卷积神经网络改进的模型可以解决这一问题.Zhao[11]提出了一种端到端的可训练级联网络RDCFace,网络可以学习校正和对准参数,从而在不需要监控人脸标志点和畸变参数的情况下获得更好的人脸识别性能.
在实际情况下,人脸数据集是高度不平衡的,类的样本数量差异巨大,Liu等人[12]提出了Margin Softmax损失来自适应地调整不同类的Margin.Liu[13]等提出了Fair Loss,每个类通过深度Q学习(Deep Q-Learning)来学习一个自适应的Margin.Li[14]等人提出一种加权E-Margin损失用于获取具有高区分度的人脸识别特征.基于卷积神经网络的模型在人脸识别领域的运用,可以极大地提高检测精度.在人脸识别方向的发展中,解决上述存在的问题,会更有利于进一步研究.在复杂背景中,人脸由于物体、人脸间的遮挡,使得识别难度增强,为提高背景复杂下人脸的识别度,在训练过程中,局部遮挡人脸识别可以摆脱这一限制,何芳州等人提出了一种低秩稀疏与网络学习的人脸识别算法,使得遮挡噪声的敏感性降低,提高了复杂环境中人脸识别的可靠性和实时性[15].
人脸识别是一种流行而有效的生物识别认证形式,可用于访问基于用户的系统.但是人脸识别技术的一个缺点就是伪装者可以通过向传感器展示有效的用户照片来访问系统,使得人脸识别系统面临着各种类型的人脸欺骗攻击(face spoof attack),如打印攻击(print-attack)、重放攻击(replay-attack)、3D掩码攻击(3D mask attack)[16].
3.2 人体动作识别
视频中人体动作识别就是在视频内容和行为类型之间建立对应关系.传统的人体动作识别方法分为基于人体运动信息的特征提取方法[17]和基于时空兴趣点的特征提取方法[18,19]两大类.特征提取过程划分为特征提取与后续动作识别两个阶段.深度学习端到端的训练方法可以对特征提取与后续的分类识别进行统一训练与学习.
原始视频存在冗余信息,Yang[20]等提出了一种时空注意力卷积神经网络(STA-CNN),能够自动选择有区别的时间段、聚焦到信息空间区域,将时间注意力机制和空间注意力机制结合到卷积网络对视频动作识别.
CNN善于捕获局部特征,处理长时依赖问题效果不佳,而RNN尤其是LSTM在处理长时依赖问题时表现出巨大的优势,Zhao等[21]将改进的注意力CNN和RNN相结合来解决动作识别任务.
动作识别任务普遍出现在视频检测中,设计一种轻量级网络进行视频动作识别降低时空信息的建模能力,Li等[22]结合时间卷积与空间卷积提出一种时空协同卷积模型(STC-Conv)来降低模型复杂度、提高计算效率.实验结果表明该模型的性能优于3D-CNNs、计算成本甚至比2D-CNNs还低.
Roig[23]等针对缺少对行为相关的上下文信息的检测和理解能力,为此提出基于动作、场景、物体和声音特征的多模态系统和金字塔结构分层特征组合方法.实验表明多模态特征有效地提高人体动作识别能力.
近年来,人体动作识别取得了相当大的进展,但是由于遮挡、摄像机移动、光照变化、背景的复杂多样、受试者动作类似等原因,要准确地识别视频序列中的动作仍然具有挑战性.
3.3 医疗图像处理
医学图像种类繁多、分辨率低、人体结构复杂,在一定程度上限制了医生对患者做出有效诊断.当前临床影像诊断主要是人工阅片,但效率低下,且肉眼阅片方法存在较高的假阳性结果.卷积神经网络模型是医学影像中预测早起疾病症状的重要方式,通过有监督与无监督的算法对一些特定标准的数据集进行预测,其在医学领域发挥的作用日益突出.
采用医学图像分割识别感兴趣区域(ROI)内部或轮廓的像素或像素集,是对人体器官的医学图像进行精准有效地分割时实现疾病诊断的关键步骤.Tang[24]等人提出一种在自动上下文方案中使用多阶段UNet(MS-Unet)的框架来精确地端到端分割皮肤损伤.焦庆磊等[25]提出LSFNet模型来实现肺结节的检测,在分类时融合位置和尺寸信息过程中实现对输入图片进行肺部实例分割.
Zhou等[26]提出一种基于CNN的医学运动图像智能识别算法.极值学习机引用到CNN中,将融合后的特征训练为CNN的输入信息.该算法的人工特征与深度学习特征互补,从不同的角度描述了医学图像的人体运动信息.
Hu等[27]提出一种多核深度卷积(MD-Conv)模型用于胸部X线图像疾病自动诊断,能够利用多尺度核函数学习多尺度特征,运用于医学图像自动诊.
Mohamed等[28]构建CNN模型,在大型数据集上区分“散射密度”和“异质密度”两种类型的乳腺密度.为评估分类性能,在乳房X光图像数据集上,去除可能分类不正确的图像,实验表明该模型在两种乳腺密度类别方面具有非常优异分类性能.表1列举了一些深度学习在医疗上的应用.
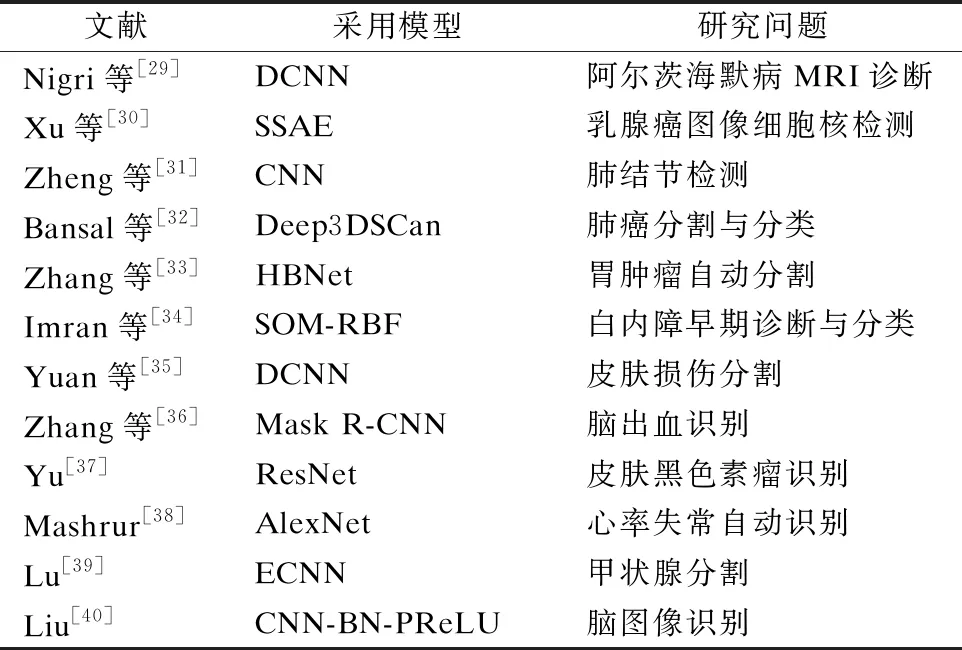
表1 深度学习在医疗图像中的部分研究应用
利用最前沿的技术对医疗图像进行分析研究有着重要的研究价值,可以帮助医生快速地做出诊断.
3.4 农业病虫害识别
病虫害是农业领域面临的最大的挑战,传统病虫害检测方法依靠农民的经验或者专家指导.由于农作物类型复杂、生长阶段不均等因素导致农作物图像特征提取困难,检测率低下.随着卷积神经网络的发展,目前科研工作者已经将其广泛运用于病虫害识别检测、植物和农作物的识别、杂草的检测与分类等多项研究.
针对水稻的主要害虫褐飞虱体积小、数量多,难以检测的问题,He等[41]提出一种两层均为Faster RCNN的检测算法,两层采用不同的特征提取网络,将该两层检测算法的检测结果与用YOLOv3的检测结果进行比较,发现前者的平均召回率要比后者高24.8%,对于不同的年龄段的褐飞虱,两层检测算法的平均召回率要比YOLO-v3高38%,实验结果表明该方法具有一定的有效性.因为AlexNet模型参数多、特征尺度单一,Zhang等[42]提出一种将扩张卷积(dilated convolution)与全局池化(global pooling)相结合的全局池化扩张卷积神经网络(GPDCNN)用于黄瓜病虫害识别,该模型相比CNN和AlexNet,在计算复杂度没有增加的情况下,通过用全局池化层代替全连接层增加了卷积感受野且不丢失判别式.Bollis等[43]设计了一个在显著性映射指导下的弱监督学习过程来自动选择图像中的ROI,这样大大地减少标注任务,并将其用于柑橘作物病虫害识别中,因缺少数据,创建了一个CPB数据集,在两大数据集IP102[44]和CPB上实验取得了不错的效果.Turkoglu等[45]将LSTM与预训练的CNN模型进行组合形成MLP-CNNs用于植物病虫害检测.在迁移学习过程中用AlexNet、GoogleNet、DenseNet201模型进行特征提取,后将这些特征输入到LSTM层,构建鲁棒的苹果病虫害检测杂交模型,实验结果相当于或优于预训练的模型.
卷积神经网络模型的快速发展使得农作物病虫害识别取得了一定成绩.由于实际农田中摄像机的稀疏性,所获取的图像往往模糊不清,且现有技术主要基于清晰、高分辨率的图像数据集上训练的,对于低分辨率图像的识别效果不佳.农作物病虫害种类多,每种病虫害对应的数据集比较少,因为需要为每种病虫害建立一定数量、一定规模的病虫害图像数据集.
4 总结与展望
卷积神经网络在计算机视觉方面的应用,包括图像的分类识别、视频识别等都有着明显的优势,在语音识别方面也取得了突破性的进展,但是图像识别在实际运用中仍然存在一些挑战,值得研究者进一步探讨研究与解决.
1)图像是识别的基础数据,图像识别中首要的挑战就是模糊图像、受环境影响的图像(如受光线、噪声影响)、遮挡的图像等情况.虽然前人提出了各种各样的技术来尽可能地减少这种挑战,但是这些问题依然存在于计算机视觉任务中.
2)卷积神经网络在检测中需要对数据进行标注,一个模型的训练过程中往往需要大量手工标注的数据,随着大规模数据量的涌现,无标签的未知数据占绝大多数,为这些数据做标签已经变得不够现实了,而且找专家来标注数据是非常昂贵的.这个时候我们就要学会从无标注的数据里面进行学习,现有的研究方法包括生成对抗网络、主动学习(Active Learning)[46]等.
3)非欧空间数据不存在平移不变性,采用图卷积神经网络可以处理图数据.在该领域中,目前存在的主要方法为谱方法和空间方法,研究表明,虽然图卷积神经网络取得了一定的成果,但仍然有很多问题需要解决[47].
4)目前在深度学习中训练网络模型需要大量的数据样本,如何在少量样本情况下即保证识别精度又能大大提高网络的训练速度是很多研究者的一个重要目标.数据扩充(Data Augmentation)是一项非常重要的技术,其可以从现有的数据中产生更多的有用数据.神经网络中Dropout的引入使得样本不足的条件下也能够比较高的识别率,文献[48]提出采用滑动窗口技术增加训练数据的方法.Chen等人[49]提出了一种GridMask的数据扩增策略,该策略删除均匀分布的区域,最后形成网络形状,使用此形状删除信息比设置完全随机位置更加有效.
总之,CNN目前还存在很多待解决的问题,这些问题不影响在各领域中图像识别的运用和发展.仍然是研究的一大热点.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
国际商业技术(2022年4期)2022-04-21
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
奥秘(2021年5期)2021-06-15
数码世界(2019年6期)2019-09-09
小雪花·初中高分作文(2017年9期)2018-05-21
中国信息技术教育(2016年21期)2016-12-05
