
针对不平衡数据的用户画像方法研究
2021-08-19 08:23巩珂王霞
现代计算机 2021年21期
巩珂,王霞
(1.北方工业大学信息学院,北京100144;2.中共湖南省委党校湖南行政学院,长沙410006)
0 引言
随着电商技术的快速发展,用户画像技术逐渐兴起。从电子商务应用的特征出发,对互联网数据进行分析,基于分析结果对用户进行画像,并根据结果对用户进行有针对性的服务,来提高电商平台的效益,是现如今电子商务平台的发展趋势。2015年,“互联网+”写进政府工作报告,对知识产权等传统服务行业产生了巨大的影响,出现了一批潜力巨大的新型“互联网+知识产权”企业。如何利用互联网的优势,提高知识产权代理企业的订单量,提高用户的满意度,增强用户粘性,值得我们深入探讨和研究。
本文在对某知识产权平台用户进行画像研究时,发现数据存在不平衡的情况。不平衡数据指的是数据集中某一类或某些类的数量远小于其他类,通常比例低于1:2[1]。不平衡分类问题在医疗诊断[2]、信用卡欺诈行为检测[3]、软件缺陷检测[4]、垃圾邮件判断等领域尤其常见。传统的研究方法以总体分类的准确率为评价标准,分类结果会更多地偏向多数类样本,造成结果不够准确,难以获得有效的分类器。本文通过对不平衡数据的处理,结合随机森林算法,并对该算法进行改进,提出了一种基于特征组合和SMOTE的随机森林算法RFFCS(Random Forest based on Feature Combination and SMOTE),用改进后的方法在用户类型、VIP上进行实验。结果表明,本文所提方法在少数类的分类效果上有一定的提升。
1 对不平衡数据的处理——SMOTE算法
对不平衡数据的处理一直是数据挖掘领域最具挑战性的问题之一。由于样本分布不平衡,多数类样本(负样本)在总样本占据的比重较大,这种情况下训练出来的分类器不能得到很好的效果。目前比较常用的方法是从数据层面进行改进。对不平衡数据集进行重构,使多数类样本和少数类样本达到一个数量上的平衡,以实现提高少数类在传统分类器上的分类准确率的目的。
通常的做法是对样本进行重采样。包括对多数类样本进行的欠采样(Under-Sampling)、对少数类样本进行的过采样(Over-Sampling),以及结合了欠采样和过采样的混合采样(Hybrid-Sampling)。
欠采样的主要思想是通过某种方式选择部分的多数类样本组成负样本,使其和全部的少数类样本(正样本)组成正负均衡的样本子集。
随机欠采样(Random Under-Sampling,RUS)是最常用的方式[5],即随机地从多数类样本中选择样本。虽然RUS易于理解,操作简单,但是存在一定的问题:随机选择样本可能会遗漏多数类样本中潜在的高价值信息,导致分类性能降低,特别是当样本的不平衡率非常高时,会严重影响分类器的泛化性能。因此,研究人员会通过改进方法来弥补随机欠采样的缺陷。例如方昊则通过多次随机欠采样取代单次随机欠采样,提高了软件缺陷检测时的准确率,降低了误差[4]。
过采样则是通过某种方法生成少数类样本或对少数类样本进行重复采样,使其达到和多数类样本平衡的状态。随机过采样(Random Over-Sampling,ROS)是最简单的过采样方式[6]。ROS通过将少数类样本随机复制的方式,使正负类样本达到一个平衡。ROS的缺点也显而易见,在样本不平衡率非常高时,生成大量相同的少数类样本,容易造成过拟合现象。
为此,Chawla提出了合成少数类样本过采样技术[7](Synthetic Minority Oversampling Technique,SMOTE)。
SMOTE算法是在ROS基础之上改进的一种线性插值的过采样方法。采样过程如下:
第一步:随机选择一个少数类样本x;
第二步:基于KNN算法找出距离样本x最近的K个少数类样本;
第三步:从上一步中的K个样本中随机取出一个样本x~;
第四步:在x和x~连线上,根据如下公式,生成一个新样本;

第五步:重复前四个步骤,直到和多数类样本达到平衡。
SMOTE算法示意图如图1所示。
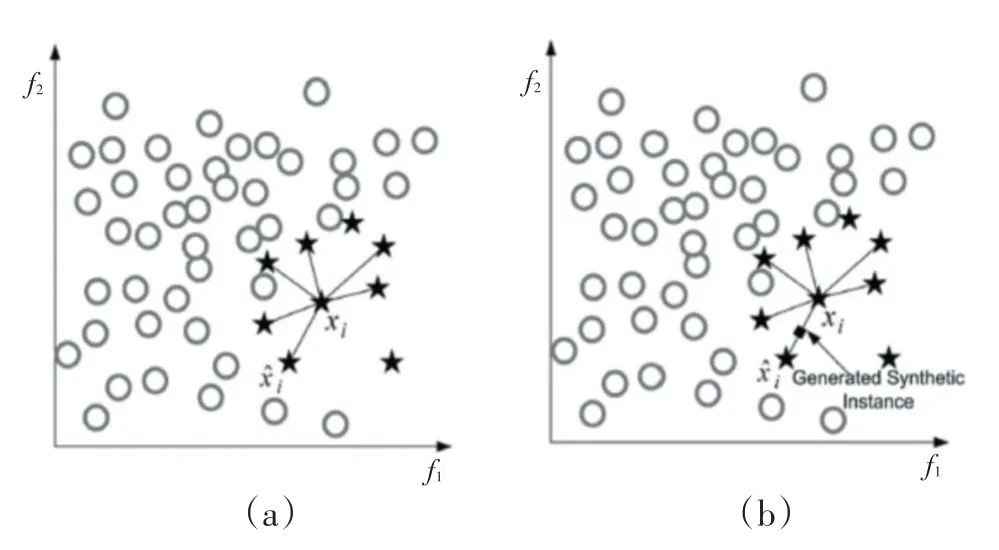
图1 SMOTE算法
SMOTE算法有效地改善了ROS随机复制新样本造成的过拟合问题,很大程度上提高了分类器的泛化能力。基于SMOTE算法,研究人员后续提出了一系列的衍生算法,例如赵锦阳提出了SCSMOTE算法[8],先在少数类样本中找到合适的候选样本及其中心,然后在候选样本与样本中心之间产生新的样本。除此之外,还 有MSMOTE、Borderline-SMOTE[9]、Safe-Level-SMOTE、TSMOTE等,其核心思想都是在特定的连线上进行插值。
无论是过采样还是欠采样,在面对较为复杂的情况时,使用单一的方法不可避免地存在一定的局限性。欠采样通过选择部分多数类样本的方式,容易遗漏潜在的有用信息。而过采样也容易造成过拟合问题,降低分类器性能。混合采样则将两者结合在一起,在保留两者优点的情况下,弥补两者的缺点,通常能得到比单一采样策略更优的效果。例如冯宏伟[10]对边界中的少数类样本的进行SMOTE过采样,对多数类样本进行随机欠采样。通过该方法得到了分类性能较好的分类器。
2 组合特征
通常情况下,构造单一的决策树分类器时需要进行剪枝操作,防止出现过拟合现象,而随机森林由于在特征选择的过程中是随机地选取其中的一部分特征,故不需要进行剪枝,也不会出现过拟合的现象,在处理高维数据时也具有较高的性能。利用该优点,再结合本文数据的特点,对特征空间进行扩展处理。
对于离散型特征,首先将它的n个属性值划分为n个特征。以性别为例,该特征包含男和女两个值,将其划分为{男,女}两个特征,属性值用1(是)和0(否)表示。例如样本A在性别特征上值为男,其在性别上的特征则可以表示为{1,0}。
对于连续型特征,可根据等宽划分法将值划分为长度相等的段。属性值上的断点可表示为:Fmin+n(Fmax-Fmin)/k。其中Fmin表示最小值,Fmax表示最大值,k表示将值域分成k个区间,可根据具体情况自定义k的值,n=0,1,2,3,…,k。以年龄为例,年龄是一个取值大于0的连续整数,取k为5,假设Fmax为100(大于100按100计算),则年龄特征可离散化为{[0,20),[20,40),[40,60),[60,80),[80,100]}五个特征。
将离散后不同类型的单一特征进行两两交叉,形成二元的组合特征。例如特征m有两个可能值{m1,m2},特征n也有两个可能值{n1,n2},特征m和特征n进行交叉后可表示为{{m1,n1},{m1,n2},{m2,n1},{m2,n2}}共4个特征。以性别和年龄为例,则可表示为{{男,[0,20)},{女,[0,20)},{男,[20,40)},{女,[20,40)},{男,[40,60)},{女,[40,60)},{男,[60,80)},{女,[60,80)},{男,[80,100]},{女,[80,100]}}共10个特征。
3 改进的随机森林算法
3.1 决策树
决策树(Decision Tree)是由Breiman提出,基于树形结构来对样本进行划分的一种分类算法。一颗完整的决策树通常包含以下三种元素:根节点、内部节点和叶节点。其中根节点是所有样本的集合,内部节点是根据一定规则选出的特征属性测试点,叶节点表示分类的结果。决策树的结构如图2所示。
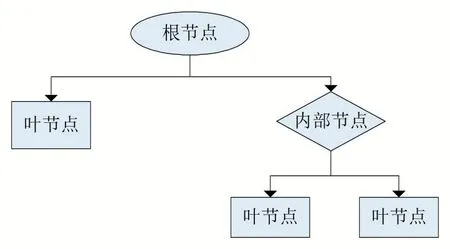
图2 决策树结构
早期的决策树算法分类回归树(Classification and Regression Tree,CART或CRT)使用基尼系数(Gini In⁃dex)来作为属性选择标准。基尼系数的定义如下:
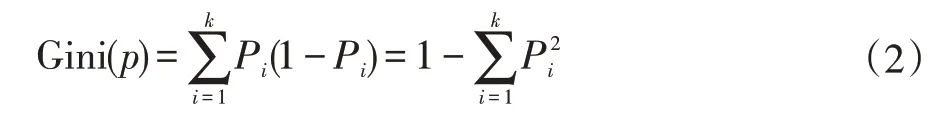
其中k为分类的数量,Pi表示样本属于第i类的概率。
除了CART算法,研究人员还提出了基于信息增益(information gain)的ID3算法[11]和基于信息增益率(information gain ratio)的C4.5算法[12]。
3.2 随机森林算法
随机森林算法(Random Forest,RF)[13]是一种以决策树为基分类器的集成学习(Ensemble Learning)算法。集成学习为了突破单一分类器在性能提升时遇到的瓶颈而被提出,除了RF,常用的集成学习方法还包括Boosting、Bagging[14](也称作“套袋法”)。
与Bagging类似,RF同样也是通过自助采样法进行样本的选择。两者最大的不同是:①随机森林只用决策树作为基分类器。②随机森林在样本扰动的基础上加入属性扰动,即在选择属性时也是随机的,增强了模型的泛化能力[15]。
随机森林还有一个很大的优点,不需要进行剪枝,也不需要进行特征选择,同样可以获得比单颗决策树更好的分类性能。
随机森林的算法过程如下:
(1)通过自助法重采样技术从训练集中有放回地随机采样选择n个样本;
(2)从特征集中随机选择d个特征,利用这d个特征和步骤(1)中所选择的n个样本建立决策树;
(3)重复步骤(1)和步骤(2),直至生成所需的N棵决策树,形成随机森林;
(4)对于测试数据,经过每棵树决策判断,最后投票确认分到哪一类。
3.3 改进的随机森林算法
随机森林作为一种集成学习方法在分类性能方面拥有比其他大多数模型更好的表现,但当面对不平衡数据时仍不能得到非常好的效果,根本原因就在于通过自助法取样并不能改变样本的不平衡分布。为此,本文对随机森林算法进行改进。算法分为训练阶段和测试阶段。在训练阶段,对随机森林中的任意一颗树来说,在通过自助采样法取得训练样本后,结合SMOTE算法生成少数类样本,使正负样本达到一个平衡状态,再利用得到的平衡数据对每一棵决策树进行训练。测试阶段中,通过上一阶段训练得到的决策树决策出的结果,采用投票的方式确定最终结果。
改进的随机森林算法流程图如图3所示。

图3 改进的随机森林算法流程图
本算法拥有如下优点:
(1)对每棵树单独进行训练集平衡处理,而非针对原始训练集,最大程度上保证了各子树间的差异性。
(2)每棵子树都选择部分样本和部分特征,避免了过拟合现象。
(3)由于生成决策树的过程中选择的是部分特征,使得在面对高维数据时也能有较高的算法效率,因此适合对特征空间进行扩展处理。
4 实验结果与分析
4.1 实验数据
某知识产权平台数据(已作脱敏处理),包含3200多条用户数据,选择用户类型为企业和代理所的数据,样本数量比为5:1,VIP属性包括非VIP和VIP,样本数量比为4:1。为了验证RFFCS算法的有效性,与决策树算法(DT)、随机森林算法(RF)进行对比。
4.2 评价标准
在一般的分类任务中,评价分类结果的好坏通常要用到如表1的混淆矩阵。

表1 混淆矩阵
根据混淆矩阵可得出三个基本评价指标:精确率(Precision)、召回率(Recall)、F-Score。公式如下:

其中,在式(5)中,α为调节精确率和召回率的权重系数,当α取1时,即为F1值。
在不平衡数据分类任务中,通常还会用到G-means。G-means可以用来衡量正负样本的的综合分类性能。其公式如下:

本文使用精确率、召回率、F1值、G-means作为算法的评价指标。
4.3 结果与分析
本文设计了两类各五组实验。首先是将未经特征组合处理的原始数据集用决策树(DT)和随机森林(RF)进行验证,然后对特征进行组合处理,再用上述两种算法进行实验(DT_FE和RF_FE),以验证特征组合的有效性,最后在RF_FE的基础上引入SMOTE(RFF⁃CS),并进行实验。实验结果如表2所示。

表2 DT、DT_FE、RF、RF_FE、RFFCS在用户类型上的分类效果比较
表2 给出的是五种算法模型在用户类型上的分类结果。由表中数据可以看出,RFFCS的分类性能要明显高于其他四种模型,F1值和G-means值达到了0.640和0.727,尤其是相较于DT,分别高出62.4%和41.3%,即使是性能最好的RF_FE,RFFCS在F1和G-means上也要高出27.0%和14.5%。值得一提的是,尽管对特征进行了组合,扩展了特征空间,DT_FE性能仍不及RF,但与DT相比,无论是精确率、召回率,还是F1值和G-means,DT_FE都有着不同程度的提高,平均提高了18.5%,而RF_FE和RF相比,除了精确率略有下降外,其余三个指标都有所提高,证明了特征组合的有效性。
表3 给出的是在VIP属性上的分类结果。结合表中数据,我们可以得出如下结论:与在用户类型上的结果相同,RFFCS算法得到了最好的分类效果,召回率和G-means甚至达到了0.9以上。DT效果最差,F1和G-means只有0.578和0.762,DT_FE次之,各项指标较DT均有所提高,但平均提高率仅有3.7%,不及表2中的18.5%。和RF相比,RF_FE仍然优势明显,各项指标的平均提高率达到了4.6%。与其他四种方法进行对比,RFFCS均有着可靠的性能。在G-means这个指标上,RFFCS分别提高了20.7%、17.6%、8.1%和5.4%。
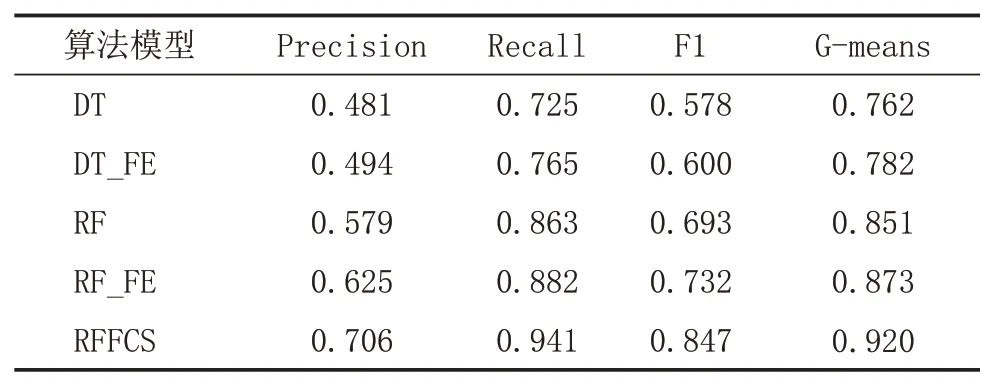
表3 DT、DT_FE、RF、RF_FE、RFFCS在VIP属性上的分类效果比较
综上所述,本文所提RFFCS算法对于不平衡的数据的分类是有效的。
5 结语
本文针对用户画像研究过程中存在的数据不平衡问题,提出将SMOTE过采样结合进随机森林的每棵子树中,在解决了数据不平衡问题的同时,保证了子树间的差异性,隐性地提高了随机森林的分类性能。同时利用随机森林在属性选择时的优越性,提出了对原始特征空间进行扩展。实验结果表明,本文所提的方法在对数据集分类时与其他对比方法相比有着较为显著的提升效果。此外,本文在设计算法时森林规模是固定的,下一步将设置不同的决策树数量来验证算法的稳定性。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
科学与信息化(2019年28期)2019-10-21
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
软件导刊(2017年4期)2017-06-20
数学学习与研究(2017年3期)2017-03-09
科学与财富(2016年32期)2017-03-04
决策与信息·下旬刊(2013年1期)2013-03-11
