
基于遗传算法的近红外光谱定性分析特征波长提取方法研究
2021-08-17 02:51:08李浩光于云华沈学锋
光谱学与光谱分析 2021年8期
李浩光,于云华 ,逄 燕,沈学锋
1. 山东石油化工学院机械与控制工程学院,山东 东营 257061 2. 中国石油大学(华东)新能源学院,山东 东营 257061
引 言
近红外光谱仪制造是我国仪器制造业的短板,目前国产近红外光谱仪多应用于实验室场合[1-2],体积大、 功耗高、 价格昂贵、 难以二次开发,极大地限制了近红外光谱分析技术的推广应用[3-4]。近红外光谱仪昂贵的价格及其较大体积制约了近红外光谱分析技术的大范围推广应用,究其原因还是近红外光谱仪本身价格昂贵且体积尚未做到便携化、 微型化。
MicroNIR-1700光谱仪是美国VIAVI公司生产的一种微型便携式光谱仪,该型光谱仪将近红外光源、 分光部件及近红外检测器集成于φ45×42 mm的体积之内,且内部不含移动部件,重量仅为60 g左右,是目前世界上体积最小的微型近红外光谱仪,该型光谱仪能实现微型化主要原因是使用了线性渐变滤光片技术及InGaAs探测器(128线元),目前国内仪器厂商及科研院所研发或生产的相关产品尚不能达到该型光谱仪的技术性能; 同时VIAVI公司出于技术保护的目的,不对外出售相关元件,因此国内尚无厂家有能力生产或仿制类似性能的微型光谱仪。据光谱仪的工作原理可知,其价格高低及微型化难度与光谱仪所能检测波段以及分辨率密切相关,以线性渐变滤光片与InGaAs探测器为例,分辨率越高,检测的波长点越多,其价格越高,制造难度越大。若能够借鉴MicroNIR-1700光谱仪的微型化设计思路,并在其基础上设计只需要采集少量波长点吸光度的光谱仪,则分光部件与InGaAs探测器元件成本与制造难度可大幅降低,并进一步降低光谱仪整体造价。
针对某一特定的定性分析任务,若能够从大量波长点中挑选出少量的特征波长点,并利用挑选得到的少量特征波长点完成对被测样本的定性分析任务,则可以降低仪器制造成本,并降低光谱仪微型化的难度,从而有利于近红外光谱分析技术的大面积推广与应用。
以玉米单倍体和多倍体籽粒作为研究对象,针对二类籽粒分类任务,多天以漫透射方式采集被研究对象的近红外光谱,按时间顺序将所采数据分为5个数据集,对第1个数据集使用遗传算法提取出10个特征波长点,再将提取得到10个特征波长点,用于剩余4个数据集的单倍体二倍体鉴别,以检验方法的有效性。实验结果表明使用10个特征波长点能够获得与全光谱基本一致的鉴别效果,说明使用少量特征波长点上的吸光度值也能够有效鉴别单倍体,针对玉米单倍体鉴别这一特定任务,可以降低仪器制造的成本与微型化的难度,为加快近红外光谱定性分析技术在单倍体育种行业的应用提供技术基础。虽然研究对象为玉米籽粒,但是方法思路亦可推广至其他被测对象,可为其他领域某个特定任务开发低成本便携式微型近红外光谱仪提供借鉴。
1 基于遗传算法的特征波长点选择方法
1.1 算法原理
在近红外光谱定性分析[5-7]问题中,将遗传算法(genetic algorithms, GA)与某一分类算法结合搜寻最有利于分类任务的原始光谱特征波长点子集,即可构成基于遗传算法的近红外光谱特征波长点选择方法。
遗传算法模仿自然界中生物进化过程,在算法中包含了繁殖、 交叉、 变异等生物进化过程中的重要步骤。
在实际自然界生物进化过程中,生物染色体具有一定变异概率,上一代染色体在繁殖时,染色体会相互交叉并遗传给下一代,生物进化时总是选择并保留最能适应其生活环境的遗传基因,而遗传算法则是选择最有利于分类的特征子集,且在每一代分类时都选择一组当前最优的特征子集,进行循环的变异、 繁殖、 交叉、 分类等步骤,直至满足算法设定条件。
遗传算法首先将需要特征筛选的向量编码成一条染色体,对于特征选择,其目标是从D个特征中挑选d个特征,首先需将全部特征表示成一个由D个二进制代码构成的字符串,二进制字符串中的0表示该维对应特征未被选择,1则表示该维对应特征被选择,该字符串就代表遗传算法中的染色体,可将其用m来表示。若在D维特征中选择d维全是1的有效特征,则存在种组合。
对于分类任务,遗传算法最优目标就是选择最适合分类的特征子集,因此分类器的鉴别准确率就可作为遗传算法的适应度函数值,对于算法中每个迭代步骤中的若干条染色体,每一条染色体即对应一个适应度值,即分类器鉴别准确率。
若待挑选的特征波长点为n个,基于遗传算法的特征选择方法可由以下几个步骤实现:
(1)对所有特征是否被选择使用二进制编码: 采用0和1对本节中数据中的全光谱所有波长点进行编码,每一个波长点对应染色体中的一个基因。若编码为l则表示该波长点被选中。若编码为0则表示该波长点未被选中,一种0和1编码组合即可当作一条染色体。
(2)初始化染色体种群: 染色体种群规模设定为N,采用随机初始化的方式,产生N个编码长度为n的染色体,设定迭代次数为100。
(3)解码并以SVM分类器的分类准确率作为适应度函数: 将染色体解码,并采用SVM方法进行鉴别。使用交叉验证的方法,计算每一个染色体对应的平均正确识别率与平均正确拒识率。
(4)计算适应度函数的值: 正确识别率与正确拒识率的均值越高,则适应度越高。考虑到收敛速度,将适应度函数设为正确识别率与正确拒识率的均值。
(5)使用选择、 交叉、 变异操作繁殖下一代染色体: 采用“轮盘赌”选择法,按设定交叉概率对染色体进行交叉,采用精英主义策略,只留下最优值,并按设定变异概率进行变异。
(6)将步骤(5)中的新一代染色体代入步骤(3),重复步骤(3)—(5),直到满足收敛条件。
1.2 算法设计
图1是采用基于遗传算法的选择波长点方法示意图。首先采用遗传算法与分类算法结合从原始光谱中提取最有利于分类的少量特征波长点,再利用少量特征波长点吸光度对待鉴别光谱类别进行鉴定。为对提出的基于遗传算法的特征波长点方法进行优化设计,选择如下近红外光谱数据集作为实验数据集:
以中国农业大学国家玉米改良中心提供的某品种玉米单倍体和二倍体籽粒作为研究对象,分5日连续采集其近红外光谱,使用自制近红外光谱采集装置,并以漫透射采集方式交替采集单倍体、 二倍体单籽粒近红外光谱各100条,共5组数据,5个实验数据集按时间顺序依次编号为T1—T5。
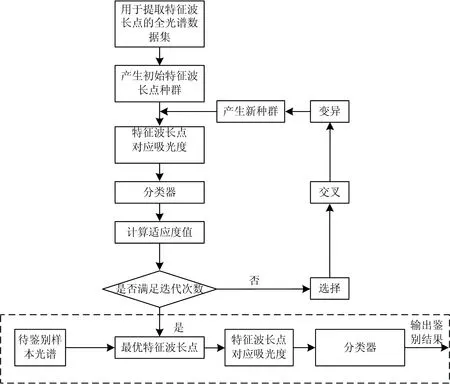
图1 基于遗传算法的选择波长点方法Fig.1 Selection of wavelength pointsbased on genetic algorithms
遗传算法中的适应度函数值使用SVM分类器所得的被测光谱正确识别率与正确拒识率[9-12]的均值来衡量。
SVM使用LIBSVM工具箱,设置SVM分类器[8]类型为二分类类型,以最优识别率为标准,在高斯核参数σ及正则化参数C指数增长的过程中以网格的方式搜索最优高斯核参数σ及正则化参数C,高斯核参数σ=3.2,正则化参数C=0.56。
基于遗传算法的特征选择方法中种群规模、 交叉率、 变异率三个参数对识别性能、 收敛速度具有明显影响。为确定适合本任务的种群规模、 交叉率、 变异率,以单倍体二倍体籽粒鉴别任务为例对三个参数进行如下分析研究。

图2 识别率随种群规模变化曲线图Fig.2 Recognition rate as population size increasing
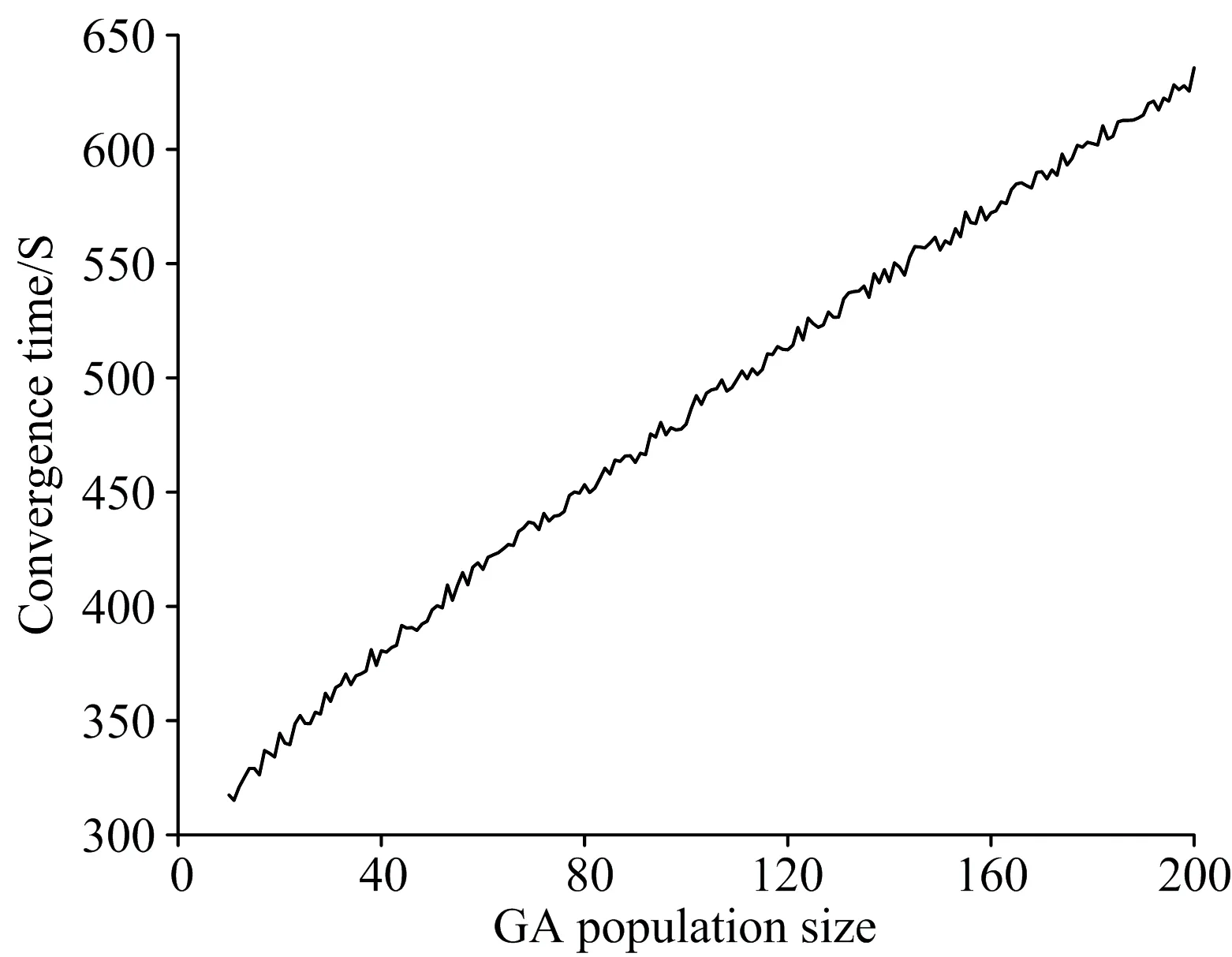
图3 收敛时间随种群规模变化曲线图Fig.3 Curve of convergence time as population size increasing
由图2与图3可知,随着遗传算法中群体规模增大,迭代次数及迭代时间显著变化,分类准确率随种群规模增大首先出现上升趋势,当种群规模达到80时分类准确率趋于平缓,而程序运行时间始终是直线上升趋势。
由此可见,识别率满足条件时,增大种群规模需花费较大计算代价,因此遗传算法种群规模设置不宜过大。综合考虑特征波长点的分类识别性能与算法收敛时间,利用遗传算法挑选特征波长点时,设置遗传算法种群规模为80。
由图4—图7分析可知,随交叉率与变异率增大,识别率到达一定值以后,其变化趋势趋于稳定,增长趋势并不明显,与此同时,收敛时间却呈现线性增长趋势,分析认为随着遗传算法中交叉率越大,遗传种群中产生新模式的概率相应增大,在开始阶段有时能够扩展至整个编码空间,但原有模式被破坏的可能性也随之增大,而交叉率过小导致每一步搜索空间过小,导致算法难以收敛。

图4 识别率随交叉率变化曲线图Fig.4 Curve of recognition rate as crossing rate changing
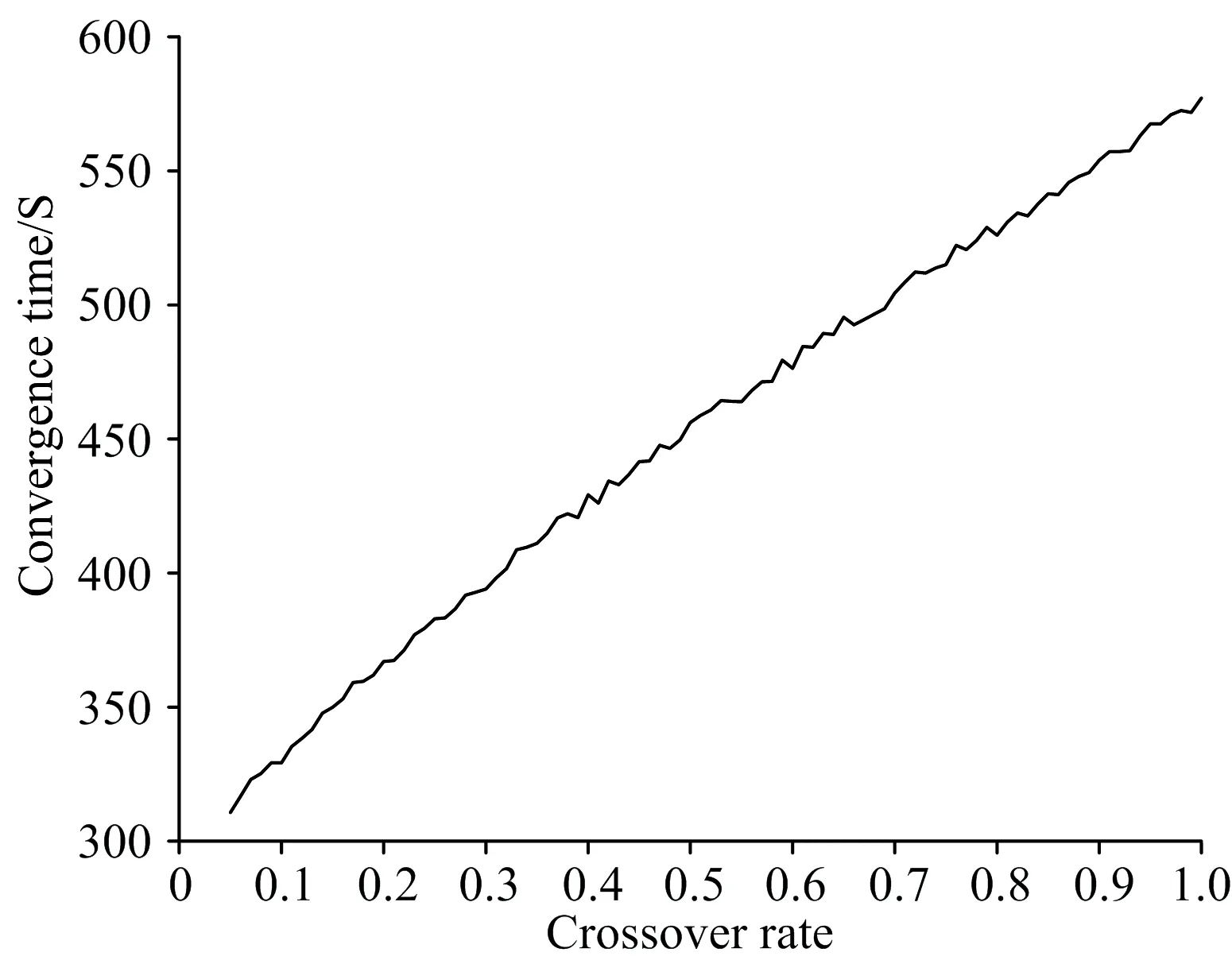
图5 收敛时间随交叉率变化曲线图Fig.5 Curve of convergence time as crossover rate changing
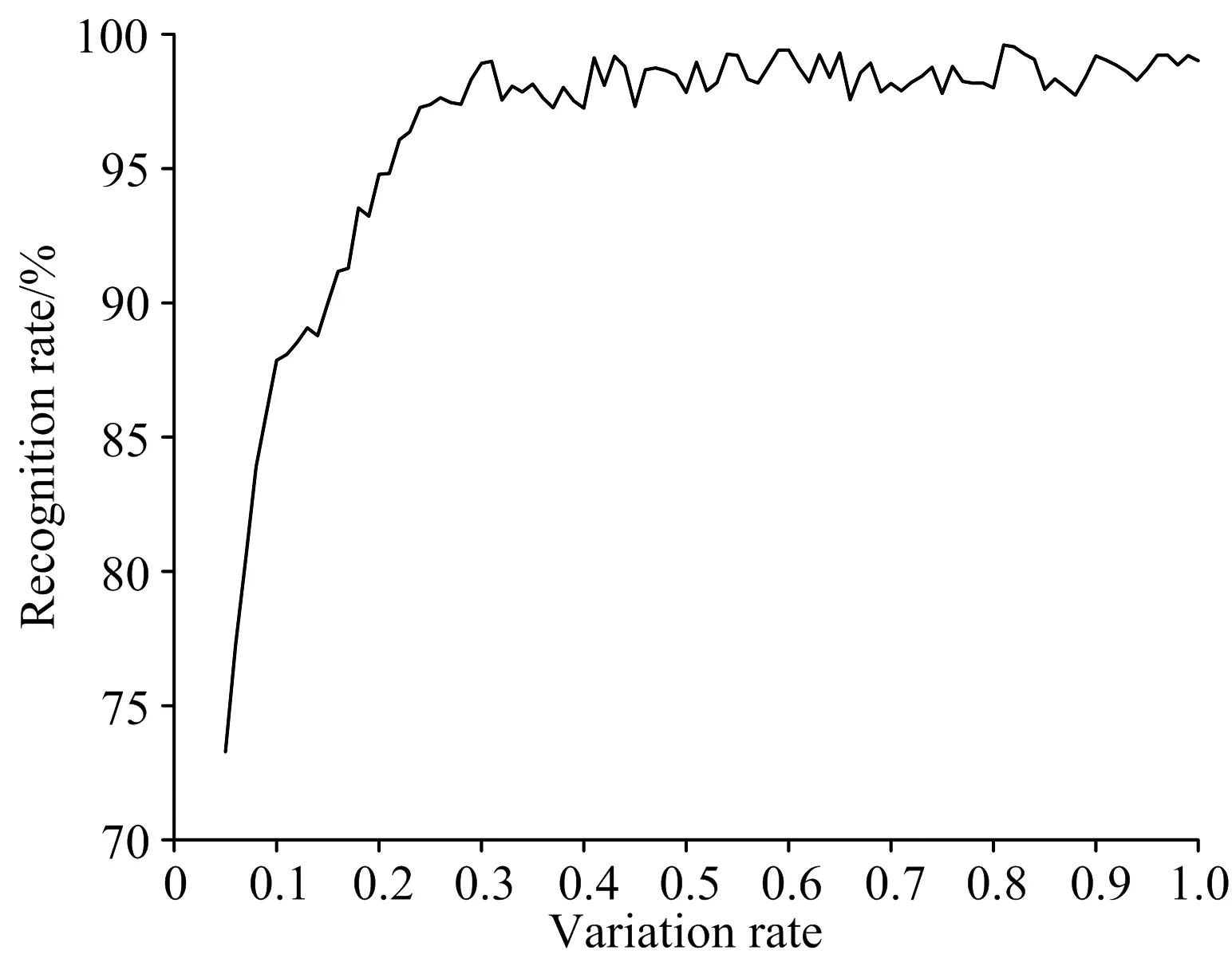
图6 识别率随变异率变化曲线图Fig.6 Curve of recognition rate as variation rate changing
相比于交叉率,变异能够提高算法所得解的多样性,但变异率较大时,易导致遗传算法变为随机搜索,变异率设置过小,种群易出现早熟或易陷入局部最优解。综合考虑所选特征建立模型的识别效果与收敛时间,使用遗传算法方法进行特征波长点选择时,为使所获特征波长点具有最优分类性能,交叉率设置为0.5,变异率设置为0.3。
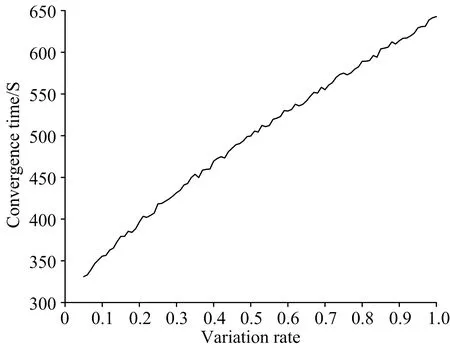
图7 收敛时间随变异率变化曲线Fig.7 Curve of convergence time as variationrate changing
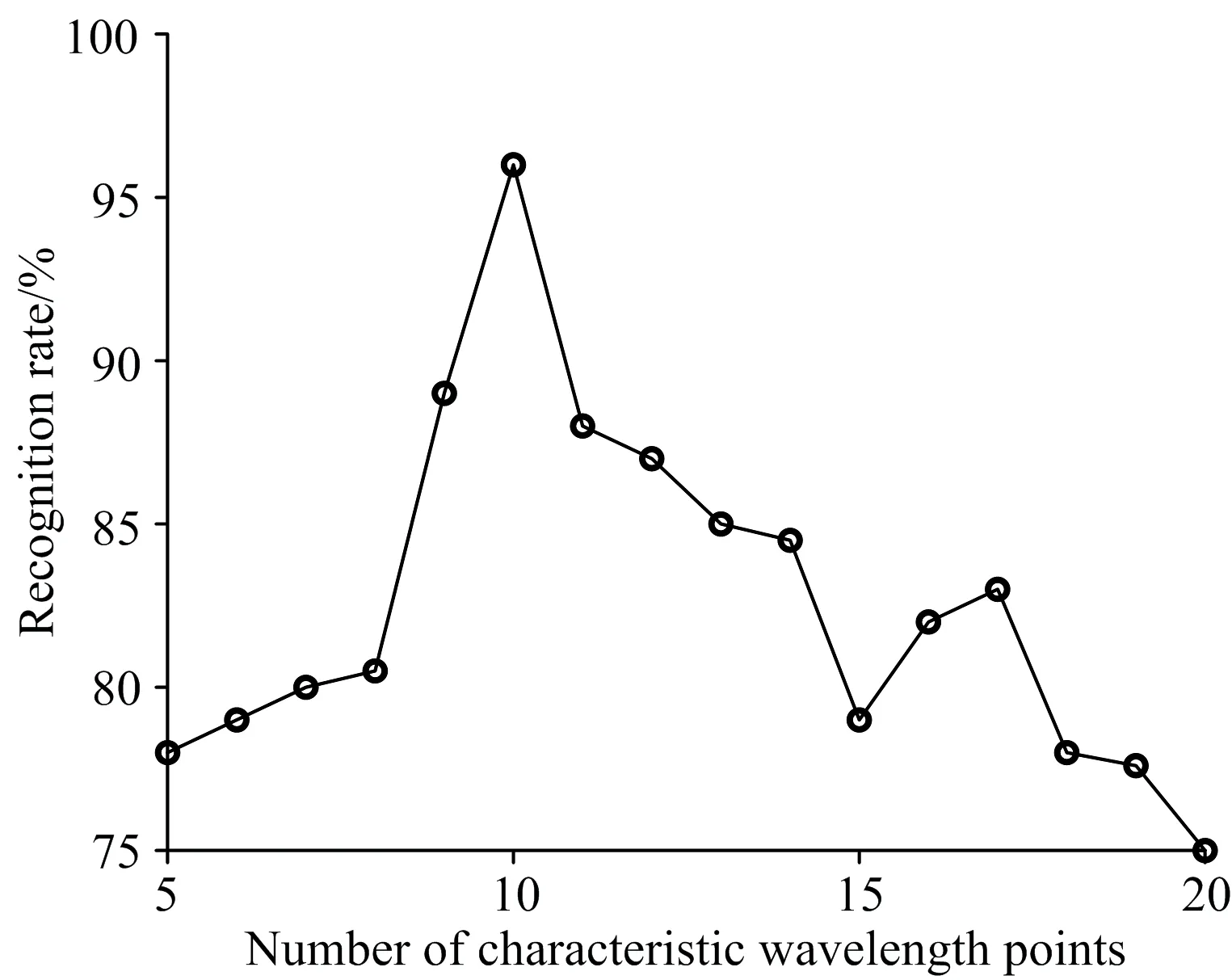
图8 识别率随特征波长点个数变化曲线Fig.8 Curve of recognition rate when characteristicwavelength points increasing
图8是单倍体二倍体籽粒的识别率随特征波长点个数变化曲线,由该曲线可以看出,在特征波长点数目增长过程中,识别率表现出先升后降的趋势,特征波长点增加到10时,识别率达到最高,其后随着特征波长点数增加,识别率又出现下降趋势,说明选择10个特征波长点能够获得最优分类效果。特征波长点过少,模型出现欠拟合的情况,而特征波长点过多时,一方面会增加模型训练时间,另一方面易导致模型过拟合,因此以下实验选择挑选10个特征波长点进行实验。
以T1—T5作为实验数据集,利用SVM分类器的准确率作为GA算法适应度函数,得到10个特征波长点如表1所示。

表1 特征波长点列表(nm)Table 1 Characteristic wavelength point list (nm)
表1中为使用遗传算法对T1数据集进行特征选择得到的10个特征波长点。由此可知,针对数据集T1中的单倍体二倍体光谱数据,表1中的10个特征波长点最能够反映被测品种玉米籽粒单倍体与二倍体之间的差异信息。
2 结果与讨论
为验证所挑选的10个特征波长点用于近红外光谱定性分析的可行性,进行如下实验:
2.1 实验1
利用挑选得到10个特征波长点,分别从T1—T5等5个实验集单倍体、 二倍体数据中各随机抽取50条光谱建模,将剩余光谱作为测试集进行测试,共实验20次,识别率取平均,如表2和表3所示。
全光谱方式采用平滑(平滑窗口9)、 一阶导(9)、 归一化、 PLS(11)及LDA(4)降维后,再使用SVM进行分类。
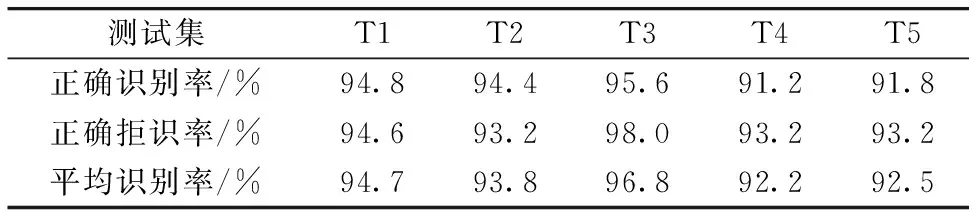
表2 各数据集识别结果表Table 2 Recognition results (Characteristic wavelength point)
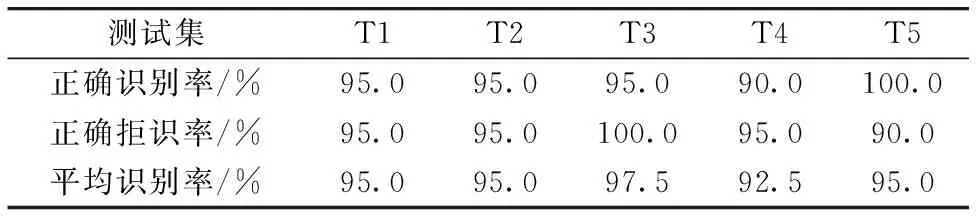
表3 全光谱各数据集识别结果表Table 3 Recognition results (whole spectra)
对比表2和表3发现,在各个独立的测试数据集中,特征波长点与全光谱两种方式下单倍体及二倍体的平均识别率基本接近,具体分析如下:
(1)10个特征波长点方式: 在T1—T5数据集上,特征波长点方法所得平均识别率在92.2%~96.8%之间。
(2)全光谱方式: 在T1—T5数据集上,平均识别率在92.5%~97.5%之间。
由此可见,利用10个特征波长点的方式时,单倍体识别率相对于全光谱方式只略下降。说明采用特征波长点方式时,利用当天光谱数据进行训练,当天数据作为测试集进行测试,实验结果与全谱区识别性能相差不大,证明了使用特征波长点方法能够在当日数据集上取得较高的识别效果。
2.2 实验2
利用挑选出的10个特征波长点,以T1作为训练集,利用T2—T5等4个实验数据集进行测试,检验特征波长点方式在多个测试集中的泛化能力。
由表4和表5可知,利用T1实验集的数据进行训练,T2—T4数据集作为测试集测试时,10个特征波长点方式所得的识别率与全谱区方式所得的识别率也非常接近,具体分析如下:
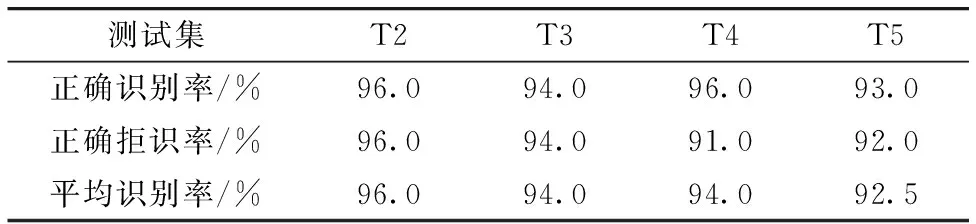
表4 各数据集识别结果表(特征波长点)Table 4 Recognition results (Characteristic wavelength point)

表5 各数据集识别结果表(全光谱)Table 5 Recognition results (whole spectra)
(1)以10个特征波长点方式在T2—T5四个数据集上进行测试,所得的平均识别率在92.5%~96.0%之间。
(2)以全光谱方式在T2—T5数据集上测试,所得的平均识别率在93.5%~96.5%之间。
由此可见,特征波长点方式所建立的定性分析模型与全谱区方式所建立的定性分析模型性能基本接近,在不同数据集上都具有较强泛化能力。
以玉米单倍体和二倍体籽粒作为研究对象,针对两类籽粒分类任务,分多天以漫透射方式采集研究对象的近红外光谱,按时间顺序将所采数据分为5个数据集,对第1个数据集使用遗传算法提取出少量特征波长点,再将提取得到少量特征波长点,用于剩余4个数据集的单倍体二倍体鉴别,以检验方法的有效性。实验结果表明使用少量特征波长点能够获得与全光谱基本一致的鉴别效果,说明使用少量特征波长点上的吸光度值也能够有效鉴别玉米单倍体。
3 结 论
针对某一特定的定性分析任务,若能够从大量波长点中挑选出少量的特征波长点,并利用挑选得到的少量特征波长点完成对被测样本的定性分析任务,则可以降低仪器制造成本,并降低光谱仪微型化的难度,从而有利于近红外光谱分析技术的大面积推广与应用。本文研究了基于遗传算法的特征波长点选择方法,采用遗传算法与分类算法结合的特征波长点选择方法,以玉米籽粒为研究对象,从原始光谱中提取最有利于单倍体二倍体分类的十个特征波长点,再利用十个特征波长点的吸光度对多个测试集中的单倍体与二倍体籽粒进行分类,并将特征波长点方法与全光谱进行了对比实验,本研究可以为针对某一特定应用场景的近红外光谱仪小型化和简单化提供理论依据, 虽然所研究对象为玉米籽粒,但是方法思路亦可推广至其他被检测对象,可以为其他领域某个特定任务开发低成本便携式微型近红外光谱仪提供借鉴。
猜你喜欢
特产研究(2022年6期)2023-01-17 05:06:16
山西农业科学(2020年8期)2020-08-13 07:44:06
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
河南农业科学(2018年5期)2018-01-19 08:25:55
实用口腔医学杂志(2017年6期)2017-09-19 02:51:28
中国交通信息化(2016年2期)2016-06-06 07:28:02
中国照明(2016年4期)2016-05-17 06:16:15
中国学术期刊文摘(2015年8期)2015-10-29 09:51:18
