
基于多模态对抗学习的无监督时间序列异常检测
2021-08-17 00:51黄训华张凤斌樊好义
计算机研究与发展 2021年8期
黄训华 张凤斌 樊好义 席 亮
(哈尔滨理工大学计算机科学与技术学院 哈尔滨 150000)
时间序列(time series)是按照时间排序的一组随机变量,它通常是在相等间隔的时间段内依照给定的采样率对某种潜在过程进行观测的结果.视频、音频、轨迹图、心电图和动作捕捉都是常见的时间序列,对这些数据进行分析和检测的关键是识别其中的模式、趋势和相关性[1].时序数据的分析广泛地应用在科学、工程和商业领域中[2-3],例如社交媒体[4]、城市数据[5]、电子交易[6]和排名统计[7]中.在这些领域中时序数据的分析需求主要包括特征提取、相关性分析和异常检测等.
异常检测的目的是找到某些观测值,它与其他的观测值有很大的偏差,这样的偏差可能是由于不同的原因或机制所产生的[8-9].在时序领域,现有的异常检测方法可分为有监督、半监督和无监督3类.其中,无监督方法在训练时不需要加注标签,通过密度估计的方式来检测异常.这种检测方式提供了良好的泛化能力,使模型不受限于数据的标签类型,是一种更适用于时间序列的检测方式[8].而在众多的无监督异常检测方法中,基于生成对抗网络(generative adversarial network, GAN)[10]的无监督异常检测算法因为优异的分布学习和特征重构能力得到了越来越多的关注.GAN是一个强大的高维数据建模框架,常用来建模复杂高维的数据分布,它起初作为自然图像[11-12]的生成模型已经获得了巨大成功,并且越来越多地用于时序信号[13]和医学成像[14]的异常检测领域.例如, Zhou等人[15]提出了一种基于GAN的心电数据异常检测模型,模型通过建模正常心电数据的分布来检测异常,并通过划分固定长度的心跳节拍将数据进行分段检测.这种划分时序周期的方法难以检测无明显周期的数据和长度可变的数据,更难以充分利用时序信息前后依赖的分布关联.为了利用时序依赖关系,Li等人[16]提出了一种基于GAN的多变量时间序列异常检测模型,此模型可以利用长短时记忆网络(long short-term memory, LSTM)[17]来捕捉时间依赖关系,再使用GAN建模分布来实现异常检测.在此基础上,Geiger等人[18]也提出了一种GAN与LSTM结合的时序异常检测方法,不同的是,该方法针对时序特征设计了多种重构误差计算和异常评分方法,进一步增强了模型的时序异常检测能力.上述方法都通过使用GAN学习特征分布的方式进行了异常检测,但是这些方法只在时序信息的时域特征上进行了分布学习,忽略了时序信息在多模态特征空间的分布关联,造成了对现有信息利用不足的问题.
如图1所示,在时序异常检测领域传统异常检测方法多采用原始时间序列直接进行单模态的检测,存在不能充分利用时序信息潜在分布关联的不足.作为对比,为解决传统方法单模态学习的不足,通过利用多模态特征空间的分布关联,本文提出了一个通用的无监督多模态对抗学习时间序列异常检测框架(multimodal GAN, MMGAN),旨在联合学习时间序列在时域空间和频域空间上的特征分布,增强模型分布建模能力.作为一个多模态对抗学习检测模型,MMGAN能以生成对抗的方式捕捉时间序列在每个模态空间上的特征分布,并建立模态间的分布关联,再通过重构检测异常.具体地,MMGAN主要有模态转换、多模态生成器和多模态判别器3部分组成.首先,模态转换模块负责时序特征从时域到频域的映射.其次,多模态生成器作为一个分布学习模块,由多模态自适应编码器和解码器组成,以2个模态信息为输入,通过模态间权重共享和低维特征融合对时间序列进行多模态的分布关联学习和特征生成.然后,多模态判别器作为一个分布对齐模块,由多模态判别网络组成,以原始多模态信息和多模态生成器的生成特征为输入,通过多模态判别网络的判别进行分布对齐.最后,通过多模态生成器和多模态判别器的博弈对抗,多模态生成器学习到正常样本的特征分布,正常样本可以通过模型进行高质量的重构,而异常样本通过重构则会产生误差,发现异常.
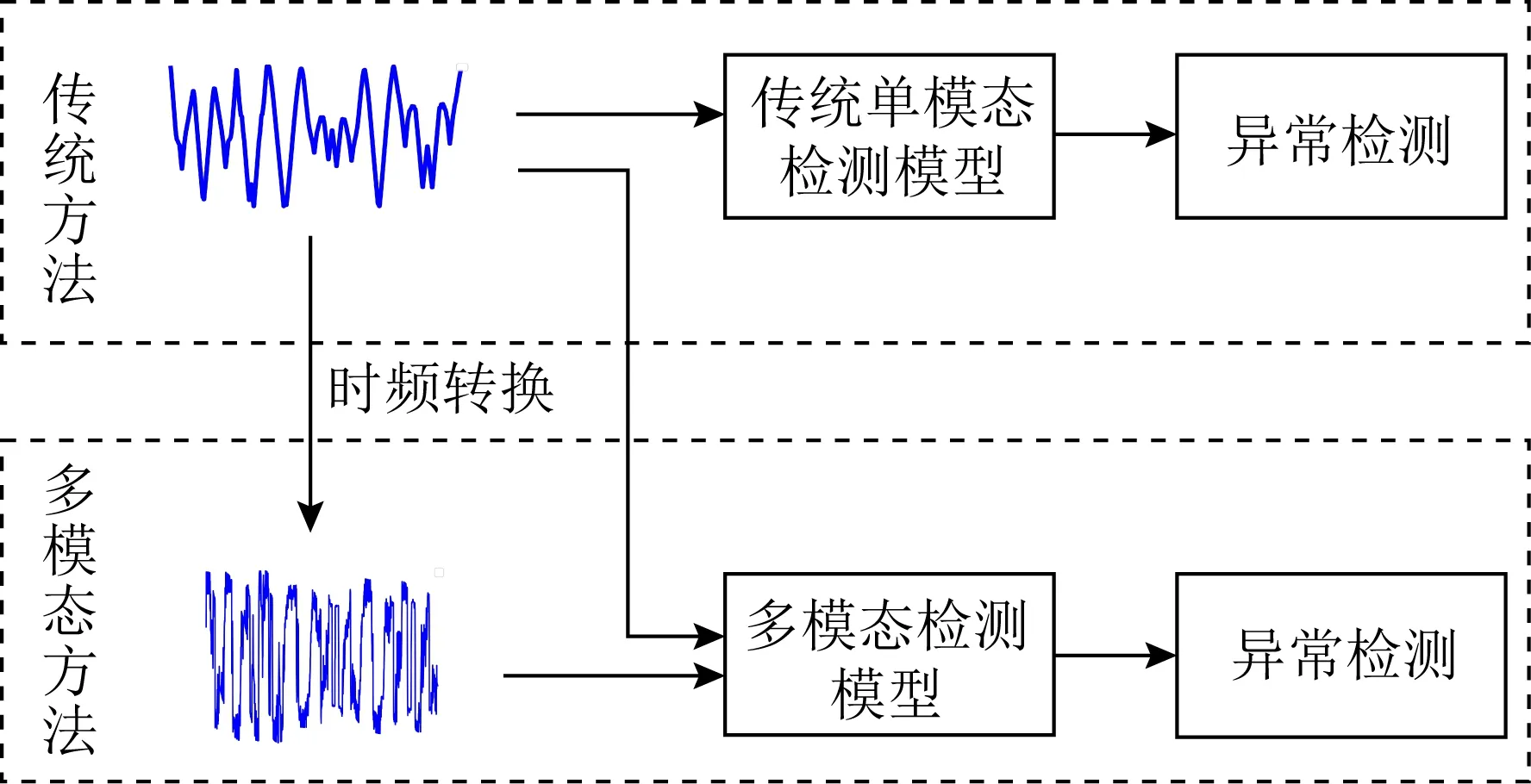
Fig. 1 Comparison of single modal and multimodal detection models图1 单模态与多模态检测模型对比
本文贡献如下:
1) 提出了一种通用的多模态时间序列的无监督异常检测框架.通过挖掘正常时序信息在不同模态上的特征分布,实现异常时序信息的有效检测.
2) 提出了一种基于对抗学习的多模态时间序列异常检测方法.该方法提出一个多模态生成对抗网络模型,实现正常时序信息关于时域特征分布和频域特征分布的联合学习,通过将异常检测问题转化为时序信息在时域和频域空间的重构度量问题,从时域空间和频域空间2个方面度量时间序列的异常值,实现更有效的异常检测.
在多个真实时序信息数据集上做了充分的实验,结果表明:相比最新的基准方法,本文提出的方法在AUC和AP这2个性能指标上实现了最高分别12.50%和21.59%的提升.
1 相关工作
1.1 基于GAN的无监督异常检测方法
异常检测在众多领域已经得到了非常广泛的研究[19-21].无监督的异常检测方法由于训练不需要标签而更贴近实际应用场景,是一种更理想的检测方法[8].具体的无监督检测算法包括基于聚类和基于重构的算法等.
基于聚类的方法通过学习正常数据周围的分类边界来划分异常,如单类支持向量机(one-class SVM, OCSVM)[22]等.基于重构的方法一般先学习数据的潜在低维表示,再通过重构误差[19]的方式来确定样本是否异常,例如:主成分分析方法(principal com-ponent analysis, PCA)及其一些变体[23],但这些方法只能进行线性重构.而且,这些算法都是基于离群值不像正态数据集中分布的假设,无法正确检测密度较高的组异常.为表征非线性变换,解决传统重构方法的缺陷,基于深度学习的自动编码器(auto encoder, AE)[24]、递归自编码器(recurrent neural network auto-encoder, RNNAE)[25]、长短时自编码器(long short-term memory auto-encoder, LSTMAE)[26]和变分自编码器(variational auto-encoder, VAE)[27]相继出现.但是,如果没有适当的正则化,这些重构方式容易出现过拟合,进而导致检测精度降低.
另一种基于重构的无监督异常检测方法是基于GAN的,GAN可以通过生成器(generator,G)和判别器(discriminator,D)的博弈对抗来学习特征分布,生成高质量的重构特征.例如,Schlegl等人[14]提出了一种通过GAN建模正常图像分布进行异常检测的方法.这是GAN在异常检测方向的开山之作,然而,该方法在测试时需要为每个样例解决一个优化问题,以找到一个潜在的表示,然后使用这个潜在表示来计算异常,这极大增加了该方法的时间复杂度,降低了检测效率.在此基础上,Zenati等人[28]提出了一种基于双向GAN的异常检测模型.此模型采用多个判别器来稳定GAN的训练,提高了检测性能的同时减少了时间复杂度.但是此模型较为复杂的结构擅长处理高维特征,在低维小数据集上处理太过冗余,导致效率低下.Akcay等人[29]提出一种使用多个编解码网络的GAN进行异常检测的方法,该模型针对图像做了多种约束,在视觉领域得到了广泛认可.但是这种针对性的模型设计也限制了该方法在其他领域的应用.而在时序领域, Zhou等人[15]提出一种基于GAN的心电异常检测模型,此模型通过重构心电数据进行异常检测,但是该方法仅限于周期性的数据,分段检测方法也难以充分利用时序信息的潜在关联.为了利用时序依赖的同时进行异常检测,Li等人[16]提出了一种基于GAN的多变量时间序列异常检测模型,通过在GAN中嵌入LSTM的方式,此模型可以利用特征的时序依赖进行分布学习和特征重构.但是,由于LSTM网络无法并行、训练慢和难以处理长序列的特点导致了此模型应用有限.通过以上现状可以看出,基于GAN的无监督异常检测算法在不同应用领域都取得了成效,但是在时序领域,面对复杂多变的时序信息,已有的检测方法仅是在时域空间上进行特征学习,不能充分利用时间序列在多个空间上的特征.受此启发,可以设计一种多模态的检测方法,利用多个空间特征分布的联合学习提高模型对时序数据分布的建模能力,执行更高效的异常检测.
1.2 时间序列的时频模态
时间序列可以利用时频联合域分析将自身的时域特征映射到频域空间形成多模态特征.多模态特征可以为异常检测提供时域与频域的联合分布信息,解决了以往单一的时域或者频域分析的缺陷,为时序检测提供了更多的角度.而现有的检测方法却忽略了这种多模态特征的学习方式.
能进行时序模态转换的时频分析工具有很多,比如,傅里叶变换(Fourier transform, FT)、短时傅里叶变换(short-term Fourier transform, STFT)和小波变换(wavelet transform, WT)等.在异常检测领域, Gothwal等人[30]提出了一种利用FT对心电信号进行异常检测的方法,该方法首先通过FT对心电峰值进行分析,然后利用神经网络对心脏疾病进行检测,但是因为傅里叶变换无法应对非平稳信号的缺陷,该方法对某些非平稳异常类型识别较差.Cocconcelli等人[31]提出了一种电机损伤检测方法,该方法利用STFT对电机运行进行周期性的特征提取,再进行时频平均以增强故障特征.但是由于短时傅里叶变换的“窗口”尺寸需要手动设定,所以该方法难以高效利用时序特征,也难以应对突发载荷.
WT继承和发展了STFT局部化的思想,通过提供一个随频率改变的“时间-频率窗口”弥补了“窗口”大小不随频率变化的不足,是进行信号时频分析和处理的理想工具.WT通过变换能够突出问题某些方面的特征,能进行时间(空间)频率的局部化分析,并能通过伸缩平移对信号逐步进行多尺度细化,最终达到高频处时间细分、低频处频率细分、自动适应时频信号分析的要求,从而可聚焦到信号的任意细节,解决了FT的缺陷.WT在应用领域,特别是在图像处理[32]和信号检测[33]以及众多非线性科学领域得到了广泛的应用.多模态方法可以利用WT的这种多分辨率特性挖掘频域空间上的分布信息,充分利用时序信息的时频关联.
基于以上2部分的相关研究现状,在时序异常检测领域,现有的检测方法只能在时间序列的单个特征空间上进行特征学习,忽略了时间序列在多个特征空间上的分布关联.而时频分析方法可以将时域特征映射到频域,为检测提供多个模态空间上的特征.因此,本文提出了一种多模态对抗学习时序异常检测框架,通过小波变换将时间序列映射到频域形成多模态特征,并利用GAN出色的分布学习能力来捕捉这种多模态特征分布关联,以此实现多模态的时序异常检测.
2 多模态对抗学习异常检测方法

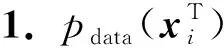
定义2.pZ(zT)和pZ(zF)是原始模态分布在低维空间Z上的映射,pZ(z+)是空间Z上2个低维分布的融合.
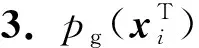
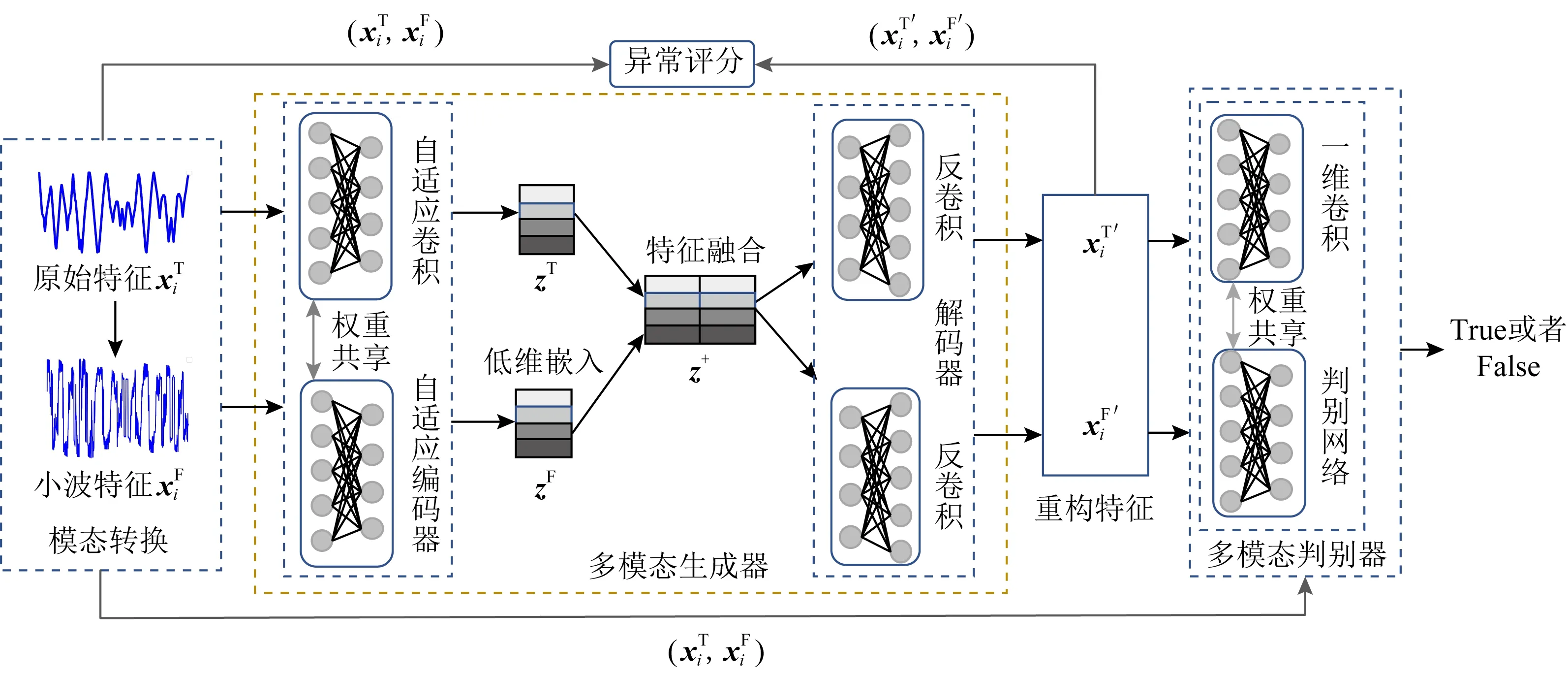
Fig. 2 Multimodal generation adversarial model图2 多模态生成对抗模型
根据分布定义,多模态生成对抗网络的目标函数为

(1)
根据式(1),对于给定的多模态生成器G,最佳的多模态判别器为
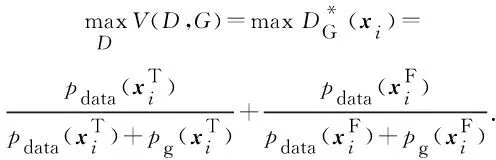
(2)

2.1 模态时频转换

(3)
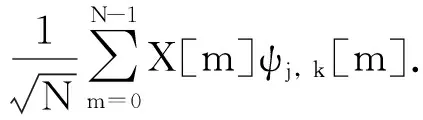
(4)
在式(3)和式(4)中wφ[j0,k]被称为近似系数,wψ[j,k]被称为细节系数.不同层次上的细节系数反映了信号在不同尺度上的方差,而近似系数则反映了信号在该尺度上的平滑平均.离散小波变换的一个重要性质是每一层的细节系数是正交的,对于任何一对不在同一层的细节系数,如式(5),其内积为0:
wψ[j, *]·wψ[j′,*]=0.
(5)
因此,可以将细节系数解释为信号的加性分解,即多分辨率分析.小波变换利用这种多分辨率特性能在非平稳时间序列上进行时频分析,使异常检测模型对非平稳时间序列信息也具有高效的检测能力.
2.2 生成器和判别器
MMGAN的生成对抗部分主要由多模态生成器和多模态判别器2部分组成.
2.2.1 多模态生成器
为了充分利用多模态时序信息的同时解决模态特征维度变换带来的参数敏感性问题,MMGAN的多模态生成器采用了一种覆盖所有尺度的自适应卷积架构(omni-scale CNN, OSCNN)[34].这个架构在学习过程中会自适应选择最优卷积核大小,避免过大或过小卷积核带来的时序特征表示损失和噪声问题[34],辅助多模态方法进行更好的特征学习.如图3所示,MMGAN使用的自适应卷积架构由输入数据、自动设置卷积核、拼接、激活函数和输出5个基本部分构成.卷积核的大小为1到N的质数,卷积核的数量为1到N的质数个数,N的大小与每个模态特征的维度正相关.在最后一层卷积中,只有大小为1和2的卷积核,通过这种卷积架构,卷积的接受域可以覆盖所有尺度的时序样本,保证时序特征得到高效学习.
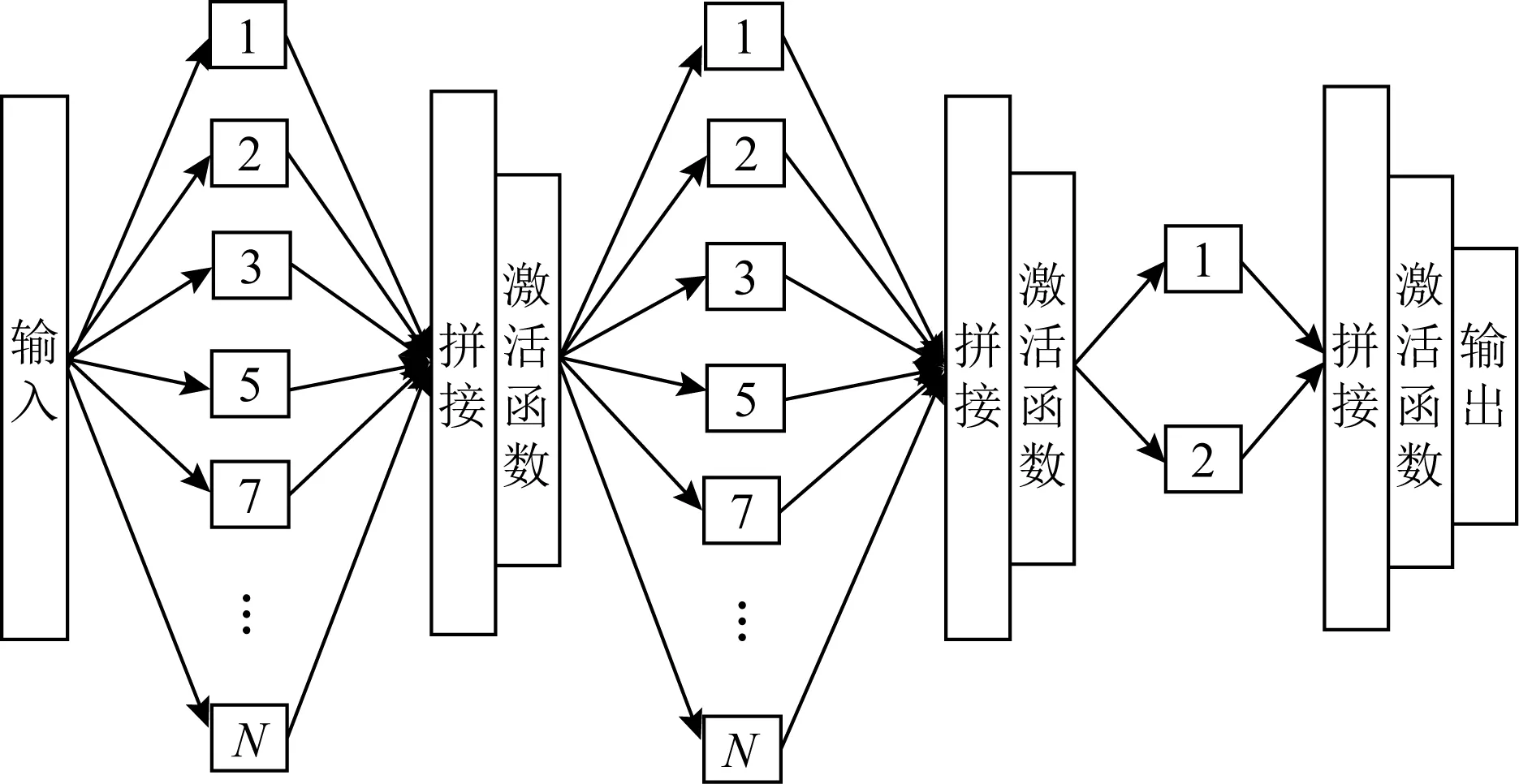
Fig. 3 Adaptive convolution图3 自适应卷积
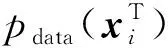
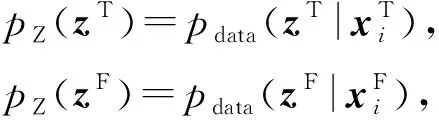
(6)
低维嵌入函数为

(7)
生成器G再将zT和zF融合为z+,融合公式为
z+=fusion(zT,zF)=zT⊕zF,
(8)
其中,⊕符号代表特征按照指定维数concat的操作.
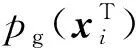
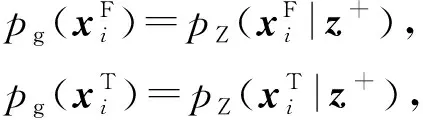
(9)
特征重构函数为

(10)
多模态生成器通过编解码方式建立了时序特征分布的映射关系,并通过网络权重共享和低维特征融合建立时序特征的时频分布关联,充分利用时序信息多模态分布关联的同时解决参数敏感性问题,使多模态时序特征得到高效学习,增强模型特征重构能力.
2.2.2 多模态判别器
2.3 损失函数

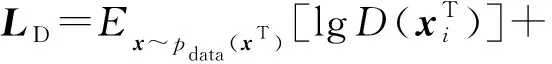
(11)
在多模态生成器G中,损失函数采用重构误差损失和成对特征匹配损失的组合,以此来最小化原始时序数据和经过判别网络隐藏层学习到的时序特征的误差,提高判别网络的性能.fD为判别网络某一隐藏层上的激活函数,多模态重构误差损失和多模态成对特征匹配损失函数分别为
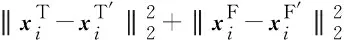
(12)
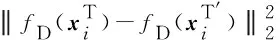
(13)
所以,多模态生成器损失函数为
(14)
2.4 异常检测
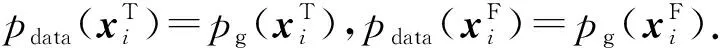
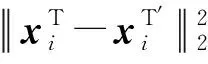
(15)
其中λT和λF为每个模态评分的权重,计算为

(16)
其中size()为模态特征维度.
2.5 算法实现
综合以上,MMGAN的时序异常检测具体过程如算法1:
算法1.多模态异常检测算法.
输入:输入时序样本矩阵T=(x1,x2,…,xN),N为样本数量;
输出:异常评分.
② FORiIN {1,2,…,N} DO:


⑥zT和zF通过式(8)进行融合;
⑦pZ(z+)通过式(9)进行分布高维映射;
⑧z+通过式(10)进行重构;
⑨D通过式(11)进行损失计算,梯度下降更新模型;
⑩G通过式(14)进行损失计算,梯度下降更新模型;
结合算法1,时间序列的多模态异常检测过程为:
1) 原始时域时序特征通过步骤③生成频域特征.
2) 在多模态生成器中,2个模态数据依此通过步骤④~⑧学习关联分布并重构出2个特征.生成器通过步骤⑩进行更新.
3) 在多模态判别器中,通过步骤⑨对生成特征和原始特征进行判别,以对齐原始分布和生成分布,并更新自身.
综上所述,MMGAN是一个基于重构的异常检测方法,异常的评估取决于生成样本与原始样本的距离,即生成器从潜在空间学习特征分布的能力.而MMGAN的多模态思想可以在时域和频域2个空间上对特征分布进行联合学习,增强模型的分布建模和特征重构能力,从而提高检测性能.
3 实验结果分析
本节从对比实验、消融实验和可视化实验3个角度分析论证多模态异常检测框架的检测性能.
3.1 环境和数据集
实验基于Ubuntu环境,使用Pytorch框架进行模型搭建.平台主要硬件参数为CPU Inter Core i7-9700,内存64 GB,GPU NVIDIA 2070,8 GB显存.
实验使用的数据集为:
1) MIT-BIH心电图数据集.MIT-BIH心律失常数据集包含了来自Beth Israel医院的48个试验对象的心电图记录.标签由2个或更多独立的心脏病专家在每一次心跳的波峰上注释,指出每一次心跳的位置和类型.根据AAMI推荐,正常节拍包括标注为N,L和R4的节拍,而命名为102,104,107和218的记录由于信号质量不够而被删除.数据集总共包含97 568次心跳节拍和2 860万个时间点.实验时,本文采用和文献[15]相同的数据处理方式,即把ECG数据按周期切割成相同的心跳节拍进行检测.
2) UCR时间序列数据集[35].该数据集于2002年推出,经过数十年发展已经成为时间序列领域的重要资源,至少有1 000篇发表的论文使用了该数据集,UCR已经成为时间信号处理领域的基准数据.该数据集一直在经历周期性的扩展.在本文使用时,UCR已经拓展为128个数据集.实验时,从中取部分标签种类或者特征长度不同的5个数据集,相关数据集统计如表1所示:

Table 1 Data Set Statistics表1 数据集统计信息
3.2 评价指标
由于数据的处理方式和训练方式存在样本不平衡的特性,本文使用AP(average precision)和AUC(area under curve)指标来衡量模型性能,相较于其他直接基于混淆矩阵的评价方式,AP和AUC的计算方法同时考虑了模型对于正例和负例的分类能力.更重要的是,在数据样本正负类不平衡而且随着时间变化的情况下,它们依然能够对分类器做出合理的评价.AP和AUC的计算结果分别来源于PR(precision-recall)曲线和ROC(receiver operating characteristic curve)曲线,其最根本的统计来源为异常检测的分类混淆矩阵,如表2所示:

Table 2 Classification Confusion Matrix for Anomaly Detection
计算AP的PR曲线如图4所示,其中横轴为召回率(Recall,或TPR),反映了分类器对正例的覆盖能力.而纵轴为精确度(Precision),反映了分类器预测正例的准确程度.PR曲线反映了分类器对正例的识别准确程度和对正例的覆盖能力之间的权衡.样本中每个类别可以绘制出一条PR曲线, 曲线中为依次改变置信度为10%~100%得到一组由精确度和召回率组成的坐标, 连接这些值就是PR曲线.
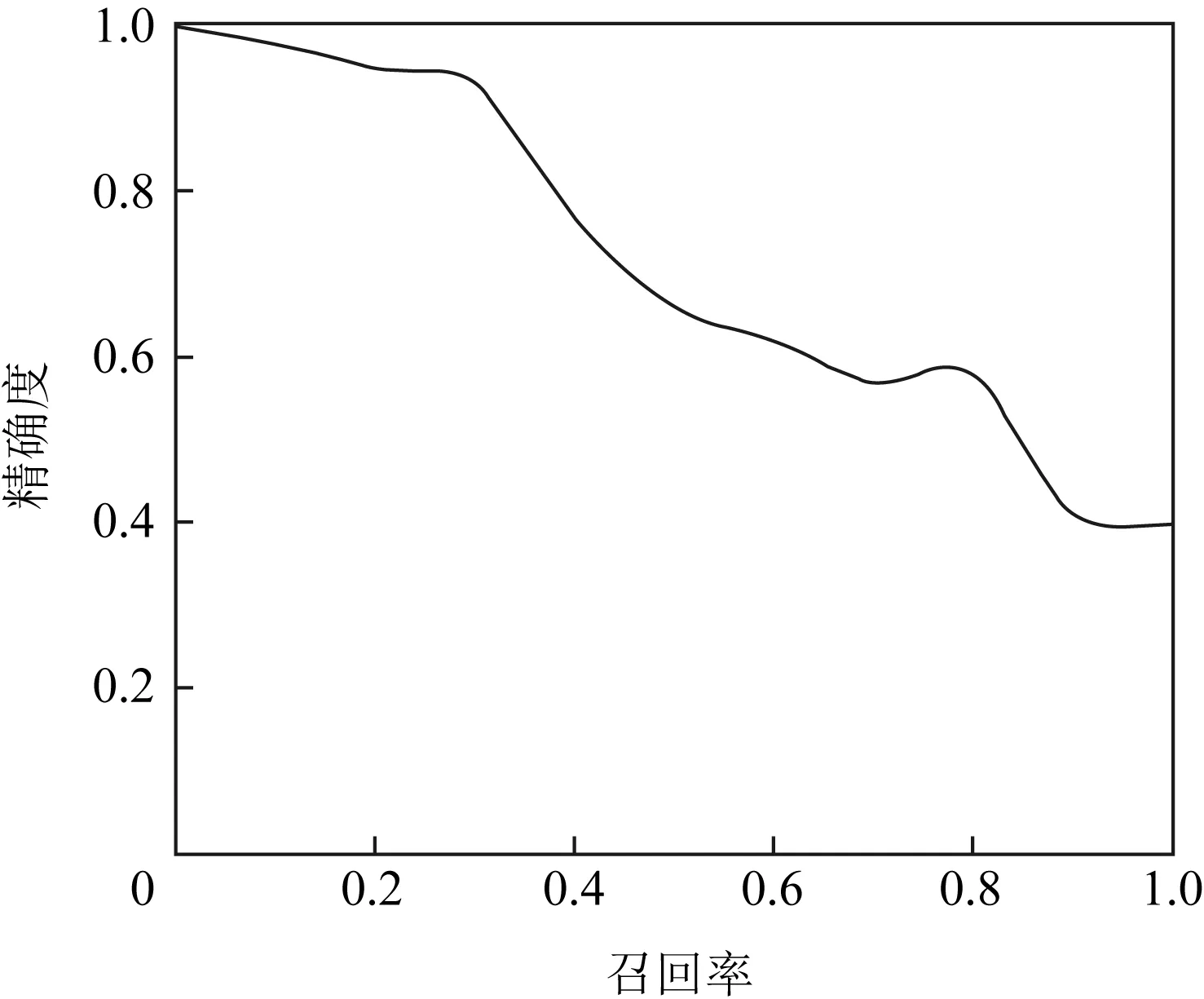
Fig. 4 PR curve graph图4 PR曲线图
精确度体现了预测为正且实际为正的实例占所有预测为正的样本比例,计算方法为
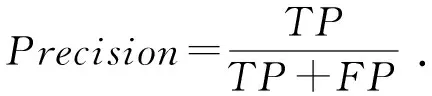
(17)
召回率体现了预测为正且实际为正的实例占所有正类样本的比例,计算方法为

(18)
计算AUC的ROC曲线是以假阳率(false positive rate, FPR)为横轴、召回率为纵轴,衡量二分类系统性能的曲线,反映了分类器对正例的覆盖能力和对负例的覆盖能力之间的权衡.同样依次取置信度10%~100%,会得到一组不同的假阳率、召回率组成的坐标,连接两者就能得到ROC曲线,ROC曲线与X轴围成的图形面积可以作为一个综合衡量指标,即AUC.
FPR表示预测为正但实际为负的实例占所有负样本的比例,计算方法为

(19)
3.3 实验设置和实验参数
为了验证本文方法的有效性,本文的实验过程将进行5个模型在6个数据集上的对比实验、消融实验和数据可视化实验.实验时采用“one VS all”的训练方式,依次将一类时序特征处理为正常,将其余种类的特征处理为异常.对每个标签重复训练10次,以保证结果的可信性和稳定性.对于每个数据集,实验中用80%的官方数据集进行训练,保持剩余的20%作为测试组,进一步从训练集挑选25%作为验证集,然后从训练集中丢弃异常样本.
实验基本参数:训练迭代次数为200,批大小batchsize=64,学习率lr=0.001.为了体现本文的自适应方法可以克服参数敏感性,面对不同的数据集和不同模态的特征维度,模型的网络参数均相同.使用Leaky Relu激活函数并设置斜率为0.2,编码潜在向量的维度由自适应编码网络自己学得.网络的具体参数表3所示,其中Conv(k,s,p)为一维卷积,ConvT(k,s,p)为一维反卷积,卷积网络中,k代表kernel_size,s代表stride,p代表padding.

Table 3 Network Parameters表3 网络参数
3.4 对比方法
MMGAN将与4种传统单模态异常检测方法进行对比.
1) AnoGAN[14].是一个基于WGAN的生成对抗模型,在训练阶段,仅使用正常样本无监督地学习一个潜在空间中的流形分布.测试时,对于测试样本,定义一个损失函数进行多次反向传播以求得一个样本的潜在空间表示.生成器利用这个潜在表示生成一个新的数据,使用这个生成和原始样本进行异常检测.AnoGAN是生成对抗思想在异常检测的开山之作.然而,在测试时,该方法需要为每个例子解决一个优化问题,以找到一个潜在的表示z,然后使用这个z来计算示例的异常值,这使得该方法在大型高维数据集或实时应用中不切实际.
2) ALAD[28].是一个基于双向GAN的异常检测模型.模型训练时,从一个数据x的原始特征空间中经过编码得到一个潜在向量z,同时从某个分布中采样得到z′,解码z′得到x′,最后将(x,z)和(x′,z′)送入判别器进行判别,以此稳定对抗训练.最后模型使用重构误差来确定数据样本是否异常.ALAD擅长处理高维特征,但是在低维小数据集上处理太过复杂,导致效率低下.
3) Ganomaly[29].是一个针对图像的生成对抗异常检测方法.不同于一般基于自编码器的方法,Ganomaly使用了一个编码器(encoder 1)-解码器(decoder)-编码器(encoder 2)的网络结构,同时学习原图、重建图和原图的编码、重建图的编码2个映射关系.该方法不仅对生成的图片外观做了约束,对图片内容也做了约束,在视觉领域得到了广泛认可.但是这种针对图像的设计使得该模型在时序领域表现欠佳.
4) BeatGAN[15].是一个应用在时序上的生成对抗模型,该方法以划分固定心跳节拍的方式对ECG数据进行了异常检测,模型也采用编码器的方式得到样本的潜在表示.不同的是,BeatGAN在判别网络中采用对抗正则的方式对编码中间特征进行了约束,一定程度上解决了梯度消失和爆炸问题.但是该方法由于采用划分周期的方法,所以难以高效处理无明显周期或者特征长度可变的时序特征,更难以充分利用时间序列的关联关系,应用有限.
综合以上分析可以看出:传统单模态异常检测算法因为各自的局限性,并不能在时序领域建立一个通用的检测模型对时间序列进行高效的利用.本文提出的多模态检测方法可以充分利用时序信息在多模态空间上的特征分布关系,解决传统方法带来的问题.
3.5 实验结果分析
3.5.1 对比实验
5个模型在6个数据集的对比实验结果如表4所示.从表中可以看出,在UCR的5个数据集上,MMGAN在网络参数固定的情况下在AUC和AP这2个指标上实现了对传统最优单模态方法最高12.50%和21.59%的超越,证明MMGAN的自适应网络帮助模型在多模态空间上学习到了更好的特征分布.在CBF这个小数据量的数据集上,MMGAN相较于传统单模态检测方法在2个指标上实现了12.50%和21.59%的最高提升,证明在小数据量的数据集上多模态思想充分利用已有信息的优势愈发明显.在MIT-BIH的Arrhythmia数据集上,面对具有明显周期的ECG数据,MMGAN在2个指标上分别实现了对传统最优单模态方法的1.20%和1.02%提升,证明多模态方法针对大数据量的周期性数据也能进行高质量的分布学习.综上,本文提出的MMGAN能有效学习时间序列在不同模态上的分布关联实现更高效的异常检测,弥补了传统单模态方法只能利用单一空间数据进行学习的缺陷.

Table 4 Abnormal Detection Results表4 异常检测结果
3.5.2 消融实验
为了验证模型中各部分的有效性,本节将在UCR的ElectricDevices数据集上进行MMGAN的消融实验.4种模型结构分别为:
1) GAN模型.单模态生成对抗模型,生成器和判别器使用最基本的卷积和反卷积作为网络编码解码结构.
2) MMGAN w/o(without) M模型.在生成对抗模型中使用单模态自适应编码器作为编码模块,未添加多模态结构.
3) MMGAN w/o(without) OS模型.使用多模态结构,但是多模态生成器使用基本卷积网络和反卷积网络作为编码和解码器,未添加自适应卷积结构.
4) MMGAN模型.本文最终模型,使用多模态框架并添加自适应编码器作为框架的编码部分.
以上4种模型在ElectricDevices数据集上的AUC和AP指标如表5所示:
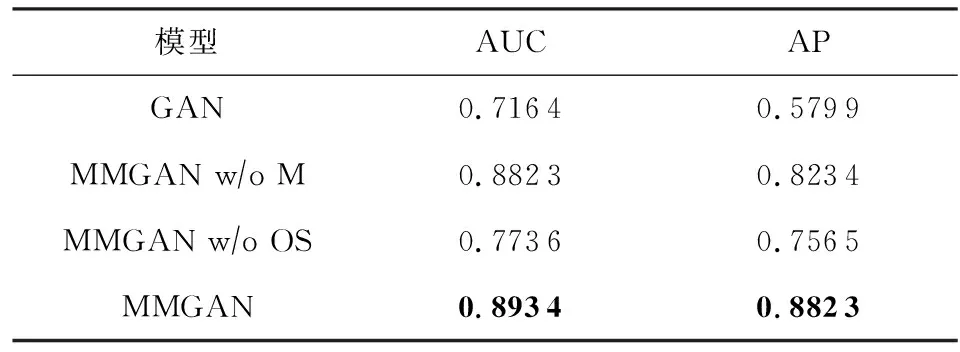
Table 5 Ablation Experiments on ElectricDevices Dataset表5 ElectricDevices数据集消融实验
从表5中可见,加入自适应结构的生成对抗模型(MMGAN w/o M)较只使用普通卷积结构的GAN,在AUC和AP这2个性能指标上分别提高了23.16%和41.99%,证明自适应卷积较传统卷积方法能在时序特征上学到更好的特征.而加入多模态结构的生成对抗模型(MMGAN w/o OS)较GAN在2个指标上分别提高了7.98%和30.45%,证明多模态思想帮助模型学到了多空间的联合分布,比单模态方法执行了更高效的异常检测.而最终的模型比只使用自适应结构的模型(MMGAN w/o M)在2个指标上分别提高了1.26%和7.15%;比只使用多模态思想的模型(MMGAN w/o OS)在2个性能指标上分别提高了15.49%和16.63%;比只使用普通卷积的模型(GAN)在2个性能指标上分别提高了24.71%和52.15%;证明自适应结构与多模态方法的结合使得MMGAN在多模态特征空间上学到了更好的特征分布,在AUC和AP上实现了检测性能的超越.
3.5.3 数据嵌入可视化
为了探索学习过程中数据嵌入的质量,本节实验对不同方法的样本嵌入进行可视化比较.具体而言,从ElectricDevices的测试集中选择1 674个数据样本.在此数据集上本文方法与Ganomaly和AnoGAN进行比较,将这3个方法的样本嵌入作为t-SNE工具的输入,然后生成二维空间的样本嵌入可视化.结果如图5所示,其中蓝色对应于正常类别,红色对应于异常类别.模型从左至右分别是AnoGAN,Ganomaly和MMGAN.
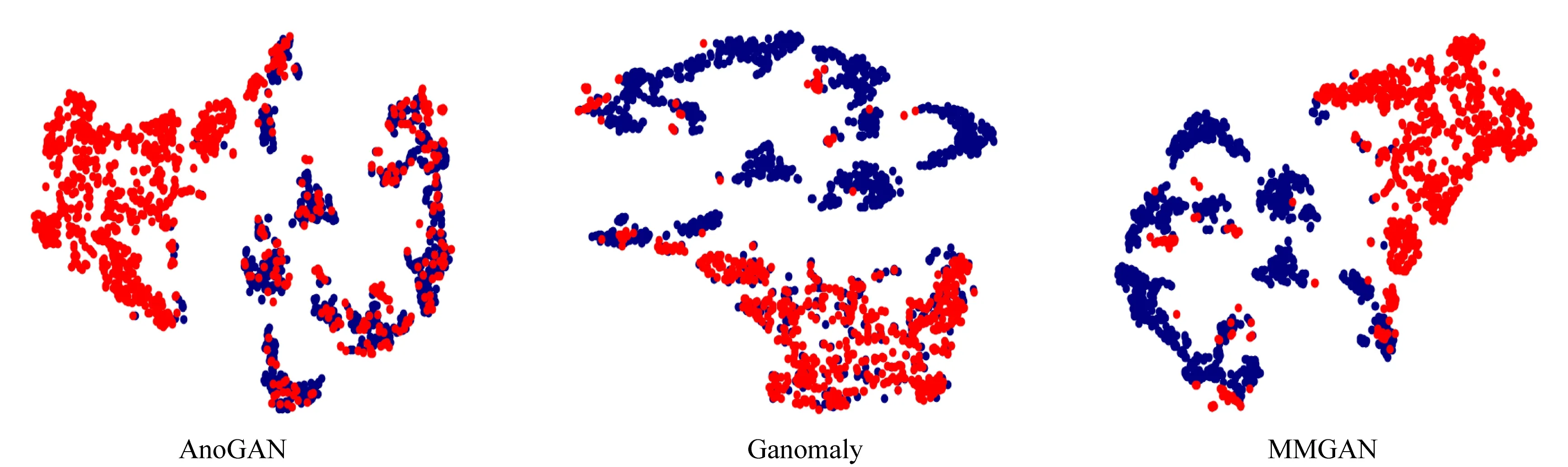
Fig. 5 Feature embedding图5 特征嵌入
在MMGAN的可视化结果中,正常数据和异常数据分布在不同的空间范围内,正常和异常数据都进行了有效聚集,而且边缘分界明显.证明多模态框架帮助模型学习到了更好的时序特征分布,充分利用了时序特征在多个模态上的分布关联,将样本进行了更好的分离.对比Ganomaly和AnoGAN,这2种方法的嵌入较本文方法在可视化上有明显差距,Ganomaly分界尚为明显但是重叠样本较多,AnoGAN分界不明显的同时重合样本点也很多,嵌入效果差.
3.5.4 异常分布可视化
为了探索模型对异常数据的检测能力,本节实验对不同方法的异常评分分布进行了可视化实验.具体而言,本文方法与Ganomaly和AnoGAN在ElectricDevices的测试集上分别进行异常评分计算,然后将评分生成柱状图.结果如图6所示.
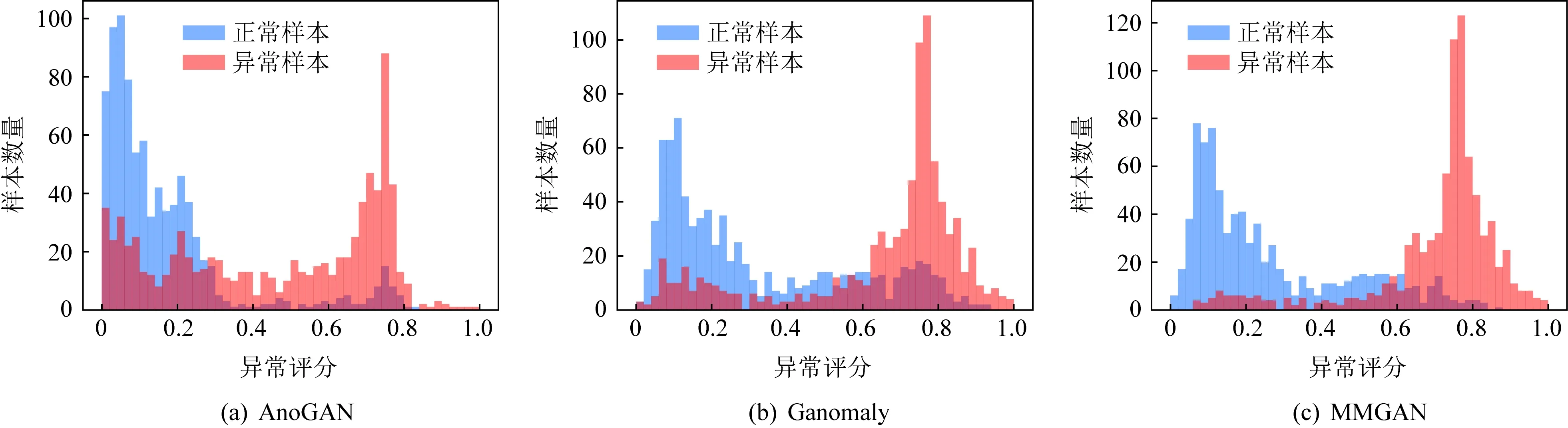
Fig. 6 Anomaly score distribution图6 异常评分分布
在MMGAN的异常评分分布结果中,评分中的正常和异常分布边界(异常阈值)清晰明显,重合分布很少,正负样本的评分都进行了有效聚集.证明多模态检测框架学习到了高质量的特征分布,从而给出了更准确的异常评分.对比Ganomaly和AnoGAN,这2种方法的异常评分分布较本文方法在可视化上有明显差距,Ganomaly正负评分的样本重合分布较多,AnoGAN则更甚,大量正常样本被预测为异常.
综合以上所有实验结果,异常检测对比实验证明本文模型在AUC和AP这2个指标上实现了检测性能的提升;消融实验证明了本文各个思想对于时序异常检测的有效性;数据嵌入可视化体现了多模态检测思想帮助模型在时间序列上提取到了更好的嵌入特征;异常评分分布可视化证明了本方法更好地完成了正负样本评分的分离.可以得出结论:本文方法相较于传统单模态模型在时间序列的异常检测上表现出了更优异的检测性能.
4 总结与展望
当前,在时间序列异常检测领域,传统的单模态检测方法只能在单个数据空间上进行特征分布学习,从而造成了对现有信息利用不足、检测效率低等问题.然而多模态方法可以利用多模态空间上的特征分布关联解决传统单模态方法的缺陷.据此,本文提出了多模态生成对抗检测模型,通过“生成+对抗”的方式发掘时间序列在多个模态空间上的特征分布关联,充分利用时序信息进行分布建模,以此提高检测能力.另外,采用自适应卷积的编码器可以针对时序特征建立最优的特征提取方式.整个模型在充分利用时序信息分布的同时解决了参数敏感性问题,提高异常检测效率.
本文在6个数据集上进行了大量的实验,结果验证了本文思想的有效性,多模态方法可以通过学习时序特征在多个特征空间上的分布关联来充分利用已有信息提高异常检测效率.下一阶段我们将考虑将更多的模态加入到这种方法以期望达到对时序信息更高效的利用.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年10期)2022-06-09
计算技术与自动化(2022年1期)2022-04-15
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
汽车工程师(2021年12期)2022-01-17
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
意林·作文素材(2021年23期)2021-01-22
