
基于K阶互信息估计的位置感知网络表征学习
2021-08-17 00:51储晓恺范鑫鑫毕经平
计算机研究与发展 2021年8期
储晓恺 范鑫鑫 毕经平
1(中国科学院大学 北京 100049) 2(中国科学院计算技术研究所 北京 100190)
图(网络)是节点与边的集合,其中节点代表了一类特定的事物,而边则代表了节点与节点之间的关联.现实世界中的大量数据均可抽象为图结构数据,比如社交网络、生物网络、学术网络等.为了更好地支持这些基于图结构数据的应用和分析,如何合理有效地表征网络节点成为了关键所在.传统的独热码方式(one-hot),由于其空间复杂度会随着节点规模的扩增而快速增大,严重限制了大规模网络数据处理和分析的能力,并且独热码无法表达节点间的相关性,间接影响了下游任务的效果.近年来,随着深度神经网络和表征学习在图像、自然语言处理等领域取得重大的成功,不少研究者开始关注如何对图中的节点进行低维表征,使得该表征可以保留网络节点间的相关性,即网络表征学习[1-3].现如今,网络表征学习已经在多种网络处理和分析任务上证明其有效性,包括网络节点分类[4-5]、链接预测[6-7]、社区发现[8-9]等.
迄今为止,学术界已经提出许多网络表征学习方法[1,10-11].大部分方法通常关注如何建模节点的近邻信息.然而,少有方法重视节点的位置信息在表征中的作用.对于每个节点,它相对于网络中其他节点的最短距离标定了该节点在网络中的位置.相较于近邻信息,节点的位置信息包含更宽的感受野和更全面的结构上下文信息,而这类信息在一些与结构分析相关的数据挖掘任务中是至关重要的.如图1所示,如果只重视近邻信息,那么用户(节点)A和B因其直接相连将会获得相似的节点表征.然而,当我们考虑两者的位置信息,会发现他们在不同的距离上有着完全不同的邻居节点,这意味两者的表征应具有较大的差异性.因此,如果表征模型可以感知到2个节点在各阶邻居上的差异,那么学到的表征将能够支撑更多与网络结构或与节点距离相关的下游任务.然而,现有的方法通常只关注节点的近邻信息,虽然部分方法(如GraRep[12])通过计算节点间转移概率的方式捕捉中心节点与高阶节点间的相关性,但这种方式却模糊了各阶邻居间的界限,使得模型仍然无法捕捉节点的位置信息.
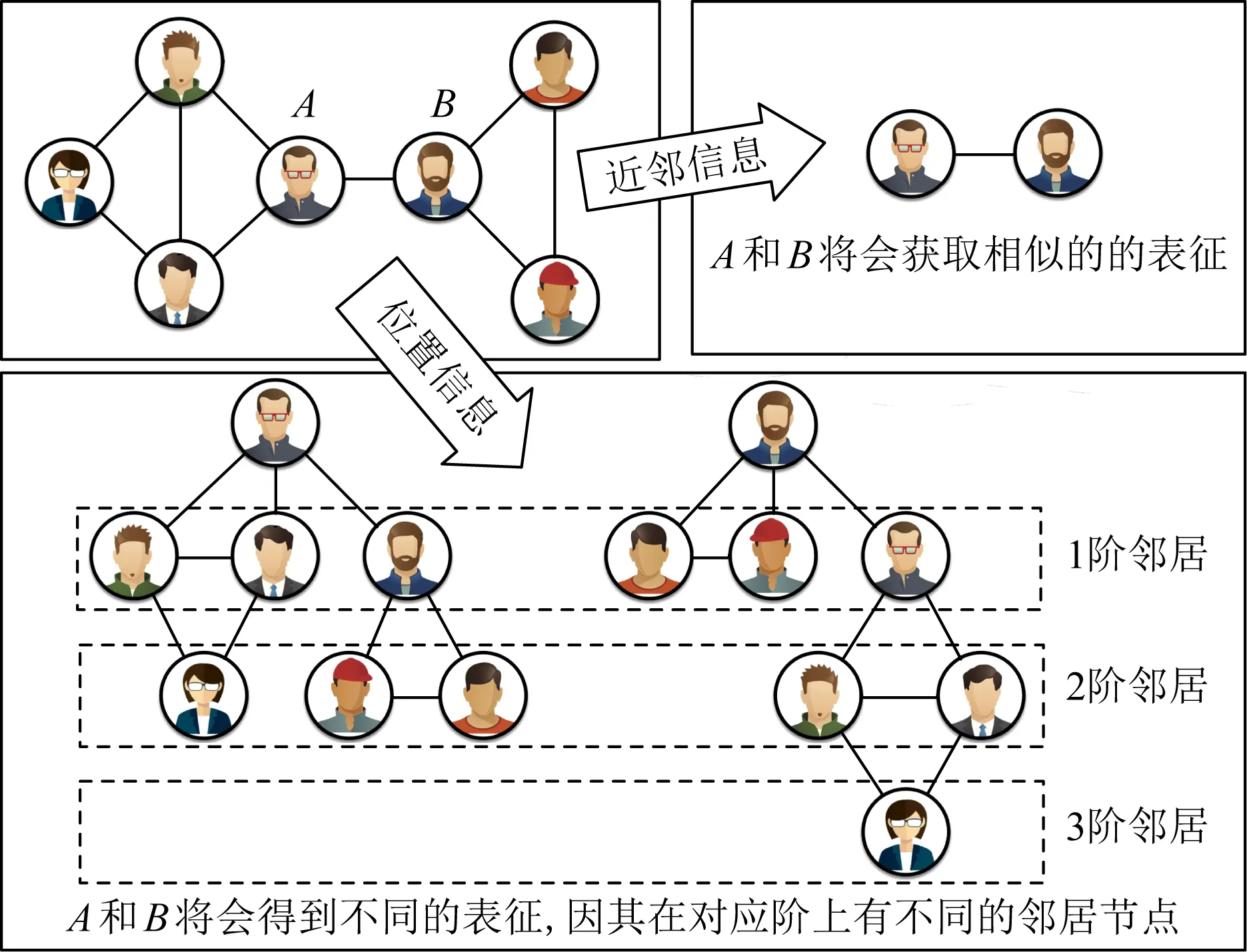
Fig. 1 The importance of positional information in network embedding图1 位置信息在节点表征中的作用
为了将节点的位置信息嵌入到节点表征中,本文提出了一种基于k阶互信息估计[13-14]的位置感知网络表征学习模型(position-aware network rep-resentation learning viak-step mutual information estimation, PMI),该模型通过最大化节点与其各阶邻居之间的互信息,从而捕捉到节点的全局位置信息.其直观解释在于:处于不同网络位置的节点,在不同阶结构上通常拥有不同的邻居,因此在模型训练的过程中,激励每个节点去分别记住并区别自身在各阶的邻居节点.通过这种方式,模型可以从节点的各阶邻居获取不同的上下文信息,从而学得更具区分性的节点表征.本文的主要贡献涵盖3个方面:
1) 提出了一种基于K阶互信息最大化的表征学习模型PMI,该模型不仅可以保留节点的局部结构信息,还可以捕捉节点的全局位置信息;
2) 为了捕捉节点的位置信息,PMI最大化每个节点与其K阶邻居间的互信息,从而让每个节点能够识别并记住其各阶邻居;
3) 在4种不同类型的真实网络数据集上进行多种代表性网络分析实验,包括链接预测、多标签分类、网络重构等.实验结果表明PMI可以有效地获取高质量的节点表征.此外,在另一项邻居匹配任务上的实验结果表明:相较于现有的工作,本文提出的PMI模型可以有效地捕捉节点的位置信息.
1 相关工作
1.1 网络表征学习
随着网络数据的大规模增加,近年来大量研究者对网络节点表征开展了研究[1,6,10].本文主要针对同质网络下的网络表征学习问题,即节点与边的类型有且仅有一种.大部分研究类比自然语言和网络节点在统计特征上的相似性[1],提出基于语言模型的网络表征学习.文献[1]提出了DeepWalk模型,首先通过随机游走(random walks)获取节点序列,再利用语言模型SkipGram[15]获取节点的表征.在DeepWalk的基础上,文献[10]修改了节点的采样策略,提出了一种带偏好的随机游走策略(biased random walks),该策略权衡了广度优先搜索(breadth first search, BFS)和深度优先搜索(depth first search, DFS).除此之外,一些文献也通过直接建模邻居间的相关性来学习节点表征.基于近邻相似的假设,文献[13]着重捕捉一阶或二阶邻居间的关系,并采用负采样策略对大型网络进行训练.文献[12]通过计算节点的K阶转移矩阵来建模高阶节点间的相关性,并通过矩阵分解获取节点表征.一些工作[11]也利用自动编码机来学习节点表征,通过最小化自动编码机的输入和输出来学习节点的表征.文献[11]证明这种方式等同于学习节点间的二阶关系.不同以上基于近邻假设的方法,文献[16]认为空间结构相似的节点在表征空间中也应当相近,基于结构相似性假设,作者建立一个多层次的带权重网络来衡量节点间的结构相似性.然而,上述工作均无法捕捉节点的位置信息.针对该问题,本文提出一种基于K阶互信息估计的网络表征学习方法,最大化节点与其各阶邻居间的互信息,让每个节点能够记住并识别来自不同阶的邻居,从而将位置信息融入节点表征中.
除了上述针对同质网络的表征学习方法,一些研究者提出在其他不同类型网络场景下的表征学习方法,包括异构信息网络[17-18]、多层网络[19-20]、符号网络[21-23]、属性网络[24-25]等.此外,一些文献着手于为不同的应用设计对应的表征学习方法,如社区发现[26-27]、结构识别[28-29]等.近几年,图神经网络(graph neural networks, GNNs)[30-32]成为了属性网络表征学习的热门,其在半监督学习下的图分类、节点分类等问题上超越了传统方法,取得了优异的效果.
1.2 互信息估计
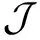
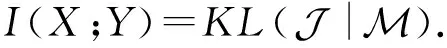
(1)
尽管式(1)在形式上十分简洁,但它的精确计算仅适用于离散变量或是已明确先验分布的连续变量,因此,它的适用场景较为有限.为解决该问题,文献[33]提出一种基于神经网络的互信息估计模型MINE,利用DV(Donsker-Varadhan)表征推导式(1)的下界:

(2)
其中,DM(·,·)是参数为M的双线性函数,该方法在学习更好的生成模型方面表现出了很强的一致性.
受到MINE的启发,文献[14]首次将互信息的神经估计应用到无监督图像表征学习中,并提出DIM模型.作者认为在很多场景下,并不需要关心具体的互信息值,而更关心变量间互信息的相对大小.因此,DIM模型用J-S散度(Jensen-Shannon divergence)替代K-L散度,并采用一种对抗训练的方式最大化正样本间的互信息:

(3)
其中,sp(x)=log(1+ex)为softplus激活函数,变量z为采样出的负样本.通过式(3),DIM最终最大化每张图片的全局特征与其每个像素表征间的互信息,并取得了优异的效果.
受到MINE的启发,文献[34]提出模型DGI并首次将互信息估计应用到属性网络节点表征学习中,最大化网络全局表征与节点局部表征间的互信息.而文献[35]提出了模型GMI,该模型最大化中心节点表征与其一阶邻居属性间的互信息.本文所提出的PMI模型与上述DGI和GMI模型存在较大的不同,如图2所示:1)本文针对的是网络结构表征,并不包含属性信息;2)本文方法通过最大化中心节点与其各阶邻居间的互信息,从而获取每个节点的位置信息.
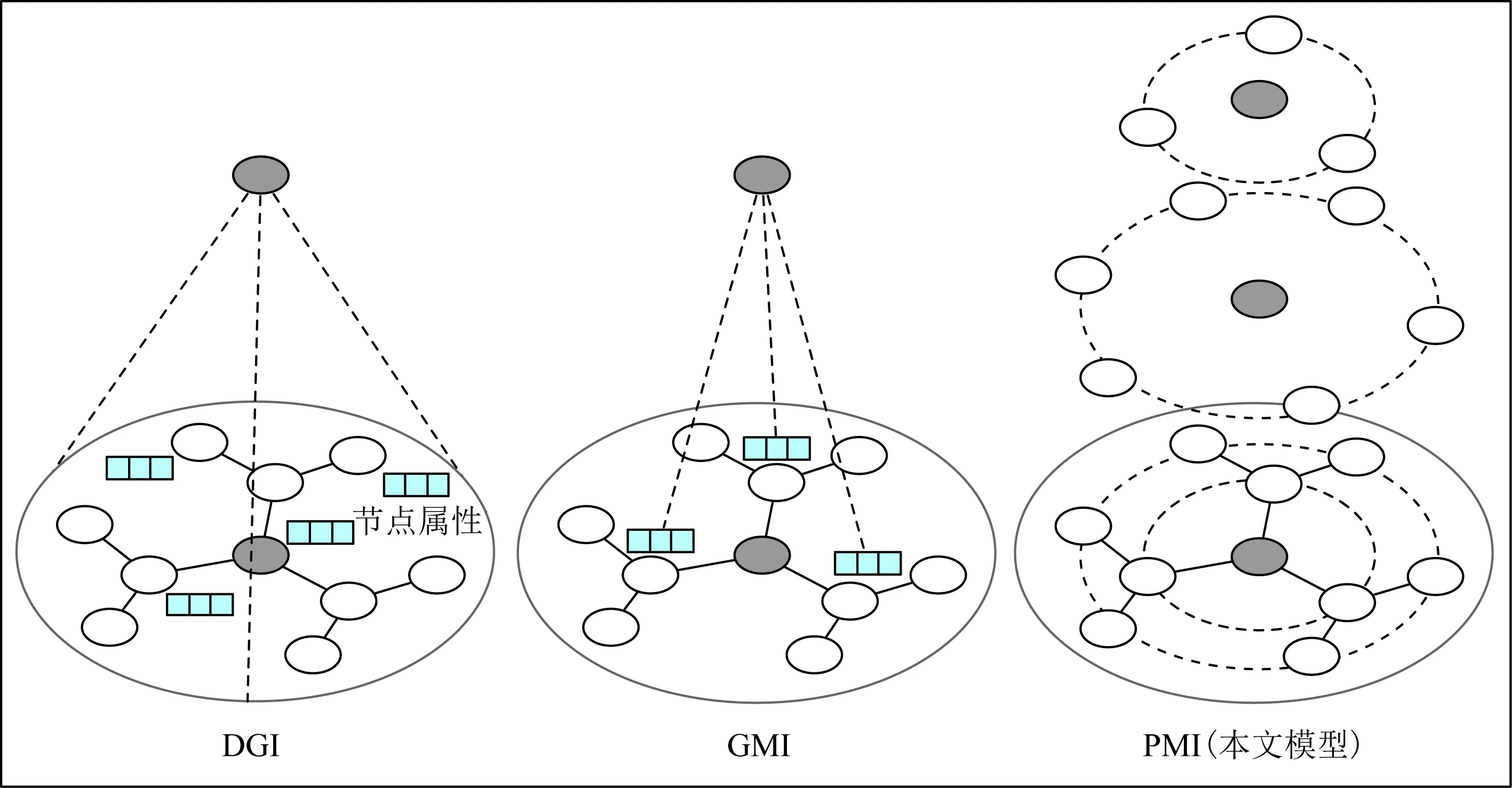
Fig. 2 Difference from current mutual information-based embedding models图2 本文工作与现有基于互信息的图表征模型的不同
2 问题定义
首先给出本文方法涉及到的相关定义,表1列出了本文的主要符号以及对应的含义.
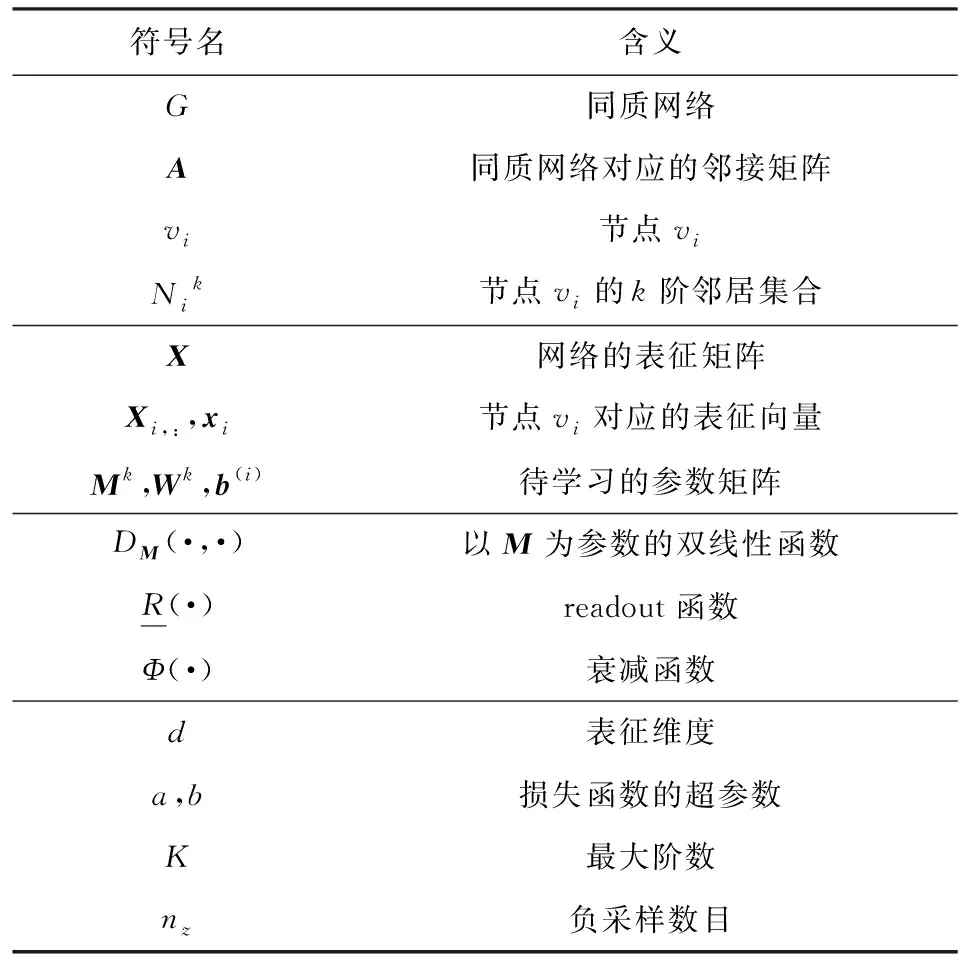
Table 1 Primary Notations and Explanations表1 主要符号和对应含义
定义1.同质网络.给定一个无向图G=(V,E;A),其中V={v1,v2,…,vn}代表节点集,E代表边集合,矩阵A是图G的邻接矩阵,其中Ai,j=1当且仅当节点v1和v2间存在一条边,否则Ai,j=0.
本文方法通过最大化每个节点与其各阶邻居间的互信息学习节点的表征,其中第k阶邻居和网络表征学习的定义分别如下:
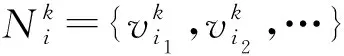
定义3.网络表征学习.给定图G,网络表征学习旨在学习图G中节点的表征矩阵X∈n×d,其中d是表征维度,其中矩阵的每一行向量Xi,:表示节点vi的表征.在后续的论述中为了简明起见,也用xi代表vi的表征.
现有的网络表征学习模型无法学习到节点的位置信息.为了解决该问题,我们认为关键在于训练的过程中,适当地激励节点记住并区别其在各阶上的邻居节点.为此,我们尝试将互信息神经估计融入网络表征学习中,为各种下游分析任务生成位置感知的节点表征.
3 基于互信息估计的位置感知表征学习方法
3.1 总体框架
如图3所示,本文提出的PMI模型主要分为2个模块:1)K阶互信息估计模块用于捕捉每个节点的位置信息;2)网络重构模块用于学习网络的基本结构信息.因此,最终优化函数也分为2部分:
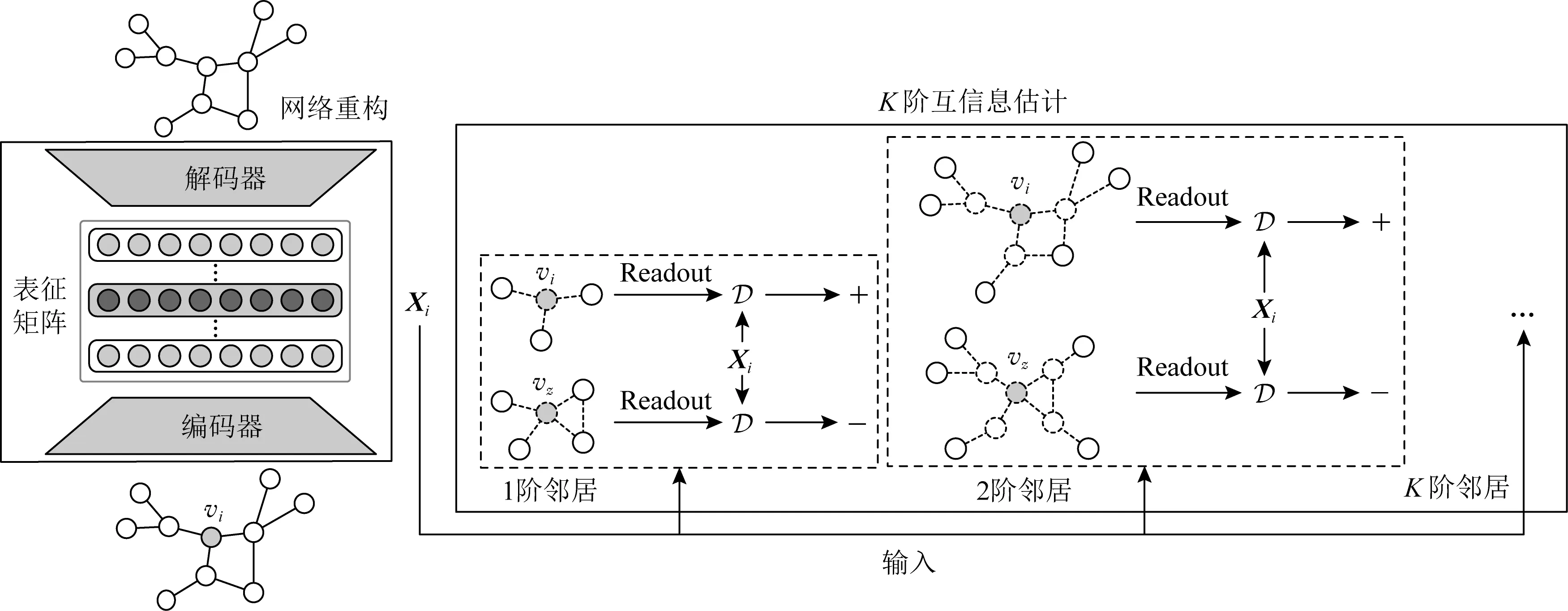
Fig. 3 An illustration of the proposed model PMI图3 本文提出的PMI模型
(4)
其中JMI代表K阶互信息估计模块的优化函数,而JAE则对应了网络重构模块的优化目标,超参数α和β用来权衡两者.接下来,我们逐一介绍面向K阶邻居的互信息最大化和基于自动编码机的结构学习模块,最后对本文方法的复杂度进行分析并给出优化方案.
3.2 面向K阶邻居的互信息估计
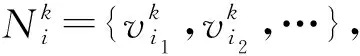
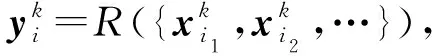
(5)

接下来,介绍最大化中心节点vi与第k阶邻居节点集合的互信息.在式(3)的基础上,我们定义互信息估算公式为
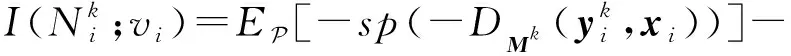
(6)
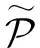

因此,面向第k阶邻居的互信息最大化的优化目标定义为
(7)
其中X是待学习的表征矩阵.最终,总优化目标定义为与阶数k相关的加权和:
(8)
考虑到位于更高阶的邻居节点对于中心节点的影响力往往越弱,在式(8)中,我们添加了一个与阶数相关的衰减函数Φ(k)来控制不同阶的邻居对于中心节点影响力的强弱,该衰减函数满足Φ(k+1)≤Φ(k),并且当k>0时有Φ(k)>0.
3.3 基于自动编码机的结构学习
面向K阶邻居的互信息最大化模块尽管可以让节点表征获取节点对应的位置信息,但无法学习到网络中最基本的结构信息,即边信息,而边信息在多种下游任务中是极其重要和基础的,丢失该信息将会极大地影响下游任务的效果.因此,PMI模型需要另一个模块来学习网络中的基本结构信息.尽管当前对于结构信息的表征学习模型[2,11-12]层出不穷,但我们发现自动编码机模型是最契合本文方法的一类模型,因为它可以直接建模近邻间的关系而不对互信息估计产生影响.同时,这也有助于我们设计一种端到端的学习模式.
尽管已有大量工作基于不同假设设计不同的自编码机模型[11,36-37],但PMI模型仅需要一个能够捕捉基本结构信息的模块,因此我们采用一种简单的自编码机模型,通过直接重建网络中的边来学习网络结构.
自编码机的编码器部分采用2层的DNN(deep neural network),其中第i层的DNN定义为
X(i)=σ(W(i)X(i-1)+b(i)),
(9)
其中,X(i)是第i层DNN的输入特征,且有X(0)=A为网络的邻接矩阵,W(i)和b(i)为待学习的参数,σ(·)为激活函数,这里我们使用修正线性单元ReLu(·)作为激活函数.第2层DNN的输出就是节点的表征X=X(2).
对于解码器模块,我们采用一个简单的点乘形式重构整个网络:
Z=σ(XTX),
(10)
其中σ(·)=1/(1+e-x)为sigmoid函数.这种简单的点乘形式不仅有效减少本模型的参数量,而且可以避免繁重的编码机预训练过程[11,38].
最后,自编码机的优化目标为重构出的网络与真实网络的距离:
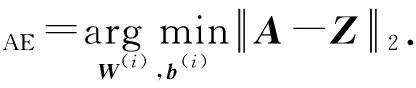
(11)
3.4 复杂度分析
模型的复杂度主要分为2个部分:K阶互信息估计模块和自动编码机模块.对于前者,每一阶的互信息估算的复杂度为O(d2|V|),对于自动编码机模块,DNN层的计算复杂度为O(d(i-1)d(i)|V|),其中d(i-1)和d(i)代表第i层DNN的输入和输出维度.因此,整个模型的复杂度为
4 实验评估
为了评估本文提出的PMI模型的有效性,我们将模型训练得到的节点表征作为下游网络分析任务的输入,测试其在多标签分类、链接预测和网络重构任务上的效果.此外,为了验证学到的表征是否能够捕捉其全局位置信息,我们在4.5节进行对于表征中位置信息的进一步分析,测试模型在邻居对齐任务上的效果.最后,我们对PMI模型中的参数敏感度进行实验分析.
4.1 实验设置
我们使用的真实网络数据来自多个不同领域,统计数据如表2所示,各个数据集的具体描述如下:
1) PPI[10].该网络是蛋白质相互作用网络(protein-protein interactions)的子图,数据来源于文献[3].
2) IMDB[39].该网络数据抽取自MovieLens(1)https://grouplens.org/datasets/movielens/,其中每个节点代表一部电影,节点间的连边表示2部电影出自同一位导演.
3) WordNet(2)http://www.mattmahoney.net/dc/textdata/.该网络为维基百科中的单词共现网络,每个节点表示一个单词,而单词间的连接表示2个单词在同一个文档中共同出现.
4) VoteNet[1].该数据来自于斯坦福的公开数据集who-votes-on-whom,是一个投票网络.
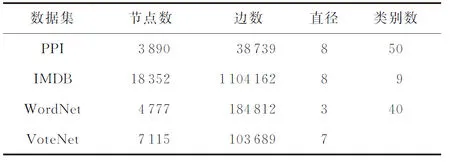
Table 2 Network Statistics表2 各数据集的网络统计数据
为了验证PMI模型的效果,我们与当前7种具有代表性的网络表征学习方法进行比较,包括基于随机游走的方法(DeepWalk[1]和Node2Vec[10])、基于近邻估计的方法(LINE[2]和GraRep[12])、基于自动编码机的方法(SDNE[11])和基于互信息的方法(DGI[34]和GMI[35]).为了公平比较,包括本文方法在内的所有方法的节点表征维度d均设置为128.对于模型Node2Vec,我们采用grid search方法在参数空间p,q∈{0.25,0.5,1,2,4}中搜索其最佳参数;对于LINE,我们分别优化1阶近邻和2阶近邻,并将两者学到的表征进行拼接获取最终表征;对于模型GraRep,我们同样采用grid search在参数空间K∈{1,2,3,4,5}中搜索其最佳超参.由于本文PMI模型仅考虑网络结构信息,我们将归一化后的邻接矩阵作为模型SDNE,DGI,GMI和PMI的输入.此外,遵循文献[11]中的策略,我们使用深度置信网络(deep belief network, DBN)[38]对SDNE模型进行参数初始化.本文方法的其他超参设置为:最大阶数K=3,负采样数目nz=5,自动编码机的各层输出维度分别为256和128,超参数α=β=1,并使用Φ(k)=k-1作为衰减函数.
4.2 多标签分类
我们首先测试各模型在多标签分类任务上的效果.采用multi-class SVM[40]作为模型分类器,并将节点表征作为SVM的输入特征来训练分类器.选择20%的标签节点作为训练样本,剩下的80%用作测试和效果评估.对于每个模型,重复上述实验5次并计算每个模型的Micro-F1,实验结果如表3所示.结果表明,本文方法在所有数据集上均取得最好的效果,在各数据集上分别有1.63%,1.36%和1.59%的提升.进一步分析可以发现:基于随机游走的方法(DeepWalk和Node2Vec)在各数据集上的效果优于其他对比方法;而LINE和SDNE的表现也较为稳定,但由于这2种方法过于强调近邻相似,导致整体效果不佳;相比之下,GraRep的表现在各个数据集上非常不稳定,比如其在PPI上的分类效果较差,这主要因为GraRep引入的高阶信息中包含了大量的噪音,这些信息影响了节点分类的效果,也影响了节点表征的区分性;另外2种基于互信息的方法DGI和PMI在多标签分类任务上的表现也欠佳,这2种方法的表征依赖于高质量的节点属性信息,当输入的网络结构信息并不包含具有鲜明特性的局部结构信号时,它们无法学到具有区分性的节点表征.相比之下,由于本文方法采用了一种K阶互信息最大化策略,其目的是让每个节点记住它的各阶邻居,PMI模型可以有效地从上下文信息中学到结构相似性,从而最终在多标签分类任务上取得较好的效果.

Table 3 Results of Multi-label Classification表3 多标签分类结果 %
4.3 网络重构
网络重构任务测试学到的节点表征是否可以保留原网络的结构信息.在本文中,实验设置与文献[11]类似:每个模型依据学到的表征相似性推理出k条可能在网络中存在的边,计算精确率precision@k,该指标表示在k次预测的边中有多少在原网络中是真实存在的.我们以IMDB和VoteNet数据集为例,比较每个模型的推理精确率.
如图4所示,PMI模型在2个数据集上都展现出更加稳定的提升.尽管SDNE和LINE在k较小时表现较优,但当更多的边需要被推测时(即更大的k),2种方法的精确率都出现大幅度下降.另一个比较有趣的发现是,2种基于互信息的方法(DGI和GMI)也取得了较为不错的效果,这说明通过加强节点与局部邻居的互信息或增强节点与全局结构的互信息都有助于表征获取丰富的网络结构信息.另一方面,PMI模型由于采用一种K阶互信息最大化的策略,使得每个节点的表征都携带其全局位置信息,可以在网络重构任务上取得最好的效果.
Fig. 4 Performance on network reconstruction图4 网络重构结果
4.4 链接预测
链接预测是网络分析中的重要任务,其目的在于预测网络中缺失的或潜在的连接关系,我们通过探究表征是否可以捕捉一些潜在的关联信息来进一步比较表征质量.对每个网络数据集,我们首先随机删除20%的边作为测试集,剩下的部分则作为每个模型的输入用作表征学习.对测试集中的每条边,我们采样一条网络中不存在的边作为负样本,将链接预测任务转为二分类任务进行评估,并使用AUC(area under curve)作为评价指标.实验结果如表4所示.
从实验结果中可以发现,本文提出的PMI模型在3个数据集上均取得最好的效果,说明采用的K阶互信息最大方法可以有效地捕捉网络结构信息.此外,其他2种基于互信息的方法(DGI和GMI)均可取得非常不错的效果,结合4.3节在网络重构任务上的效果,我们可以得到这样一个结论:最大化节点与其近邻或全局结构的互信息有助于模型捕捉网络更深层的结构信息.其他几种方法,如DeepWalk,Node2Vec,GraRep也在其中几个数据上取得不错的效果,但整体效果并不稳定.我们认为出现该问题的原因在于表征无法获得节点的全局位置信息.直观上,在图上距离越近的节点越容易产生关联,因此节点的位置信息对于链接预测任务而言是非常重要的.而相反,本文提出的PMI方法通过最大化中心节点与各阶邻居的互信息,让中心节点能够记住其任意阶的邻居,从而使得学到的表征可以保留全局位置信息,捕捉更多网络结构中的隐藏信息,最终在链接预测任务上取得令人满意的效果.
4.5 案例研究
为了研究本文提出的PMI模型是否可以使得表征学习到节点的全局位置信息,本节进行一个新颖的实验:邻居对齐.该实验的目标是让每个节点识别来自同一阶的节点并区分来自不同阶的节点.通过该实验,我们可以从侧面知晓学到的表征是否包含了位置信息.
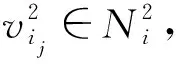
1) 本文方法在2个数据集上均取得最优的效果.这说明通过本文方法学到的节点表征可以有效记住各阶的邻居信息,从而区分不同阶的节点.
2) 大部分方法都可以有效地识别1阶邻居,这主要是由于近邻假设导致1阶邻居节点通常与中心节点在向量空间中更近,因此较为容易区分.但对于其他阶的邻居节点,我们发现大部分方法(尤其是基于随机游走和自编码机方法)的效果存在明显下降,比如SDNE在PPI上区分3阶邻居时仅有52%左右的准确率,而DeepWalk在2个数据集上识别3阶邻居时均只有55%左右的准确率.这些实验结果均说明当前方法通常会混淆来自不同阶的邻居节点.
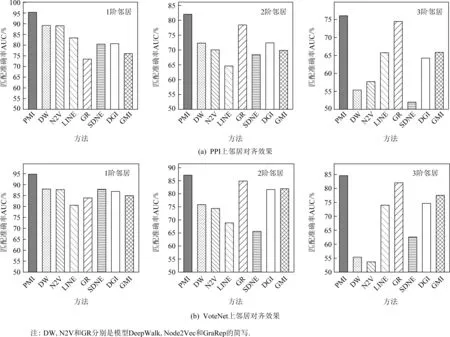
Fig. 5 Results of neighbor alignment图5 邻居对齐结果
3) GraRep在区分3阶邻居的效果上与本文方法相当,这是因为GraRep建模节点对间的转移概率,而较高阶的转移概率会远小于低阶的转移概率,因此GraRep可以比较有效地识别3阶邻居节点.尽管如此,在2个数据集上GraRep均无法有效地区分近邻节点(如1阶邻居),这说明GraRep易混淆1阶邻居和其他阶的邻居节点,无法有效地捕捉到节点位置信息.在4.2和4.4节的实验中,相关任务均要求模型能够有效地捕捉近邻信息,本节的实验结果也解释了为什么GraRep在之前的实验中效果并不理想.
小结:本文提出的PMI模型可以激励节点表征记录其各阶邻居的信息,从而有效地识别来自于不同阶的邻居节点.结合PMI模型在4.2~4.4节实验中杰出的表现,我们可以发现节点的位置信息对于下游网络分析任务而言是极其重要的.
4.6 参数学习
本节探究不同的超参设置对PMI模型的影响.我们选择PPI和VoteNet两个数据集,并在2个常见分析任务(多标签分类和链接预测)上进行参数学习.
我们首先研究衰减函数Φ(x)和最大阶数K对于模型的影响,比较5种具有不同衰减速度的衰减函数在最大阶数K∈{1,2,3,4,5}上的效果,相关实验结果如图6(a)所示.从结果中我们发现不同网络分析任务对于2类超参的偏好是不同的.在多标签分类任务中,当不考虑衰减函数时(即Φ(x)=1),整体效果会随着阶数K的增大而快速降低;相反,Φ(x)=1在链接预测任务上可以取得不错的效果,其准确率随K的增大而升高.总体而言,衰减函数Φ(x)=x-1,21-x,e1-x较为契合本文PMI模型.同时,对多标签分类任务来说,阶数K=2较为合适,这也暗示近邻信息往往决定节点的类别.而相反,随着K的增大,链接预测的效果普遍上升,说明高阶信息对于链接预测任务是比较重要的,因为高阶信息可以让表征在更加宽的感受野中学习节点的位置信息.
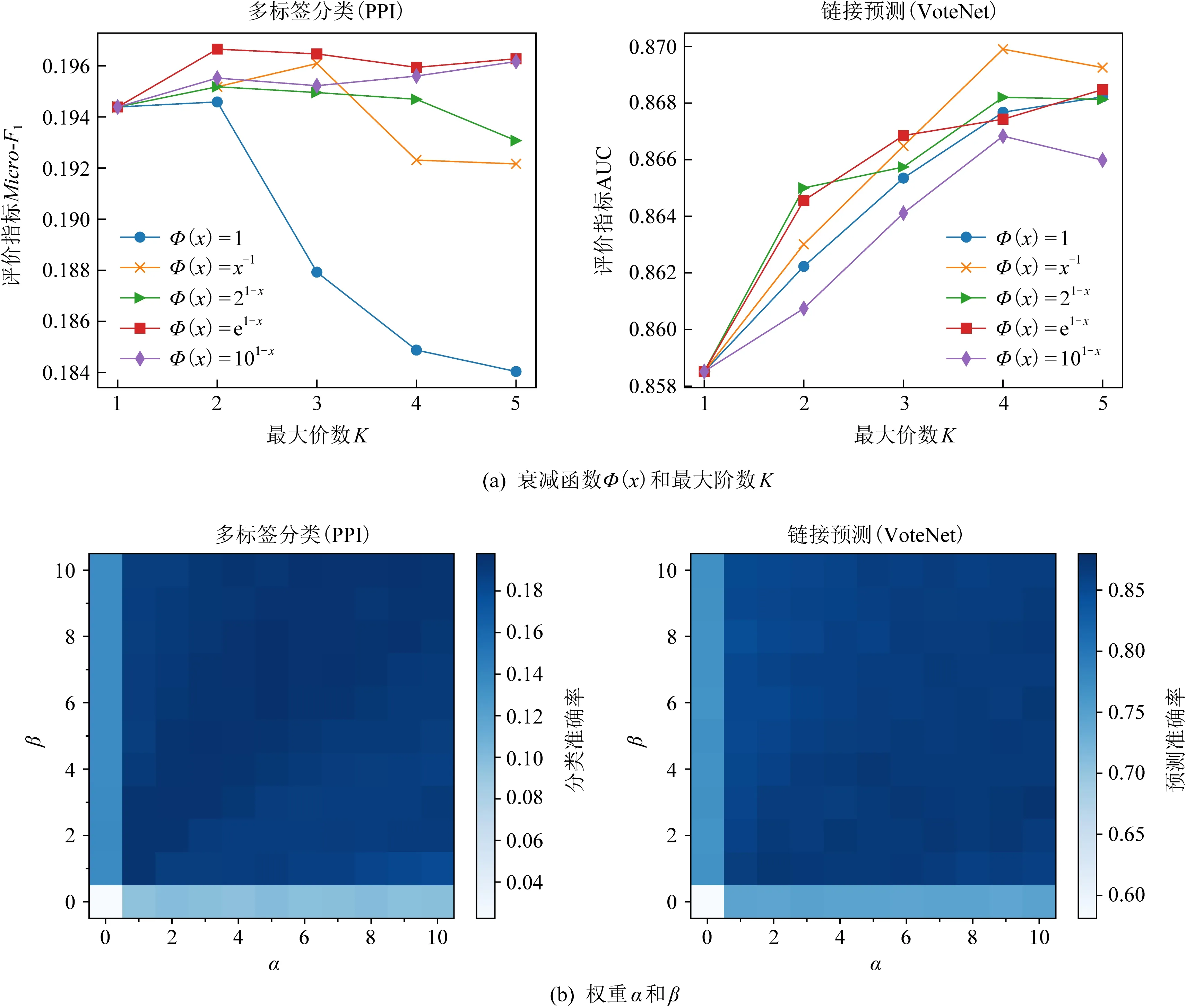
Fig. 6 Parameter study on two different tasks图6 在2种不同任务上的参数学习结果
接下来,我们研究损失函数中超参α和β对于效果的影响,两者用于平衡互信息估计和网络重构损失的权重.我们以0.1为步长,将α和β分别从0.0增加到1.0,并用热力图展示不同参数组合对多标签分类和链接预测效果的影响,结果如图6(b)所示.总体上,PMI模型对于两者的取值并不是很敏感,但当α和β分别取0时,方法有明显的下降,这也从侧面反映位置信息和结构信息对于节点表征都很重要.另一方面,我们也发现2类任务对于超参的偏好也是不一样的.对于多标签分类任务而言,颜色较深的区域往往靠近对角线附近,这说明对于分类任务,位置信息和结构信息同等重要;而对于链接预测任务,右下角的区域颜色较深,这意味着一个较大的α值会取得更好的效果,也说明节点的位置信息对于链接预测而言更加重要.
5 总 结
本文主要针对现有网络表征学习方法中位置信息缺失的问题,提出一种位置感知的网络表征学习PMI模型.在本文方法中,我们最大化每个中心节点与其各阶邻居之间的互信息,从而在训练的过程中激励每个节点记住其K阶邻居的信息,我们在4个不同领域的真实数据集上进行了多标签分类、链接预测、网络重构实验,实验结果表明本文所提PMI模型较现有表征学习模型不仅在各类下游网络分析任务上有所提升,并且通过在邻居对齐任务上的进一步分析,验证了PMI模型学到的表征可以有效地获取节点的位置信息.
猜你喜欢
导航定位学报(2022年4期)2022-08-15
现代电子技术(2022年4期)2022-02-21
好日子(2021年8期)2021-11-04
智能计算机与应用(2021年4期)2021-06-05
当代陕西(2021年1期)2021-02-01
考试与评价·高二版(2020年3期)2020-09-10
华人时刊(2019年15期)2019-11-26
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
中华诗词(2018年11期)2018-03-26
Coco薇(2016年8期)2016-10-09
