
Big Data-Based Transformer Substation Fault Prediction Method
2021-08-16 01:56:20XinWuJianLiQiHuang
Xin Wu | Jian Li | Qi Huang
Abstract—Transformer substations play a major role in power systems.The fault of a transformer substation will jeopardize the safety and effective operation of the power system.The fault signal of a transformer substation includes the fault status and fault occurrence time.In this paper,we propose a transformer substation fault prediction method based on big data analysis.Thus,a new transformer substation fault prediction method is developed by combining the advantages of decision tree algorithms and grey system theory to predict the fault status and occurrence time with high accuracy.As a case study,the transformer substation fault signals obtained from a region in the southwest of China are analyzed using the proposed method based on big data.The experimental results confirm that the proposed method achieves high-accuracy fault prediction.
1.Introduction
With the evolution of modern power systems,smart grid technology has developed rapidly during the previous few decades.As one of the most important infrastructures associated with smart grids,smart substations play an important role with respect to the flow of electric energy,conversion of voltages,control of power flows,and overall operation of a power system[1],[2].In January 2012,a plan of designing and building new smart substations was proposed by the State Grid Corporation of China (SGCC),and the operation of the first smart substation was initiated in November 2012.In recent years,more than 1000 smart substations were constructed every year in China[3],[4].
With an increase in operating time,the substation equipment will undergo aging,which may considerably damage the power system.To solve this problem,regular manual maintenance of the equipment is conducted at most substations.This relatively obsolete inspection system has obvious shortcomings,directly resulting in over-or under-maintenance[5].Especially in practical production,the smart grid monitoring data have increased exponentially by considering various systems and structures.Thus,using these big data to analyze and forecast faults is becoming a highly effective method that is superior to the traditional method.
Given the requirements of system reliability and safety,it has become vital to precisely predict the fault type and occurrence time at transformer substations[6],[7].Most previous studies have adopted two types of methods to predict the fault state:One method is to evaluate the current state of equipment based on the online or offline characteristics and the other method is to predict the aging trend of devices based on historical data.Thus,the main idea of fault prediction is to build models based on the existing monitoring data to predict faults.
Recently,several substation signal prediction methods have been proposed.In [8],using linear regression,a fault prediction method was proposed for the main components in a hierarchical system.The method of predicting the failure rate of substation equipment based on the grey-linear regression combined model was presented in [9].However,the nonlinear characteristics of power systems limit the application of these methods.A fan fault prediction method based on the support vector machine and particle swarm algorithm has also been proposed[10].In [11],the maintenance management method of electrical equipment based on the data mining method was proposed;however,the prediction of the fault occurrence time is not accurate.In [12],the fault prediction method was based on hybrid integrated time series,case-based reasoning and exhibited density functions,and high data requirements,which rendered the analysis less efficient.
Therefore,for fault prediction by transformer substations,we not only need the precise static prediction but also the prediction of the fault occurrence time.Then,the transformer substation faults can be comprehensively predicted.To overcome the limitations of the existing methods,this study proposes a novel prediction method based on substation warning signals.First,for predicting the fault status,the decision tree algorithm is more precise for the long-term prediction compared with the naive Bayesian algorithm.The grey system theory is used for predicting the fault occurrence time.The fault status and occurrence time can be predicted with high accuracy using Apark Spark (here in after referred to as Spark) data analysis tools.Spark is a fast and general engine for large-scale data processing and can also be used interactively with Python,Scala,and R shells[13].
The remainder of this paper is organized as follows.The next section discusses the fault status prediction using the naive Bayesian algorithm and the decision tree algorithm,and compares both these methods.Section 3 discusses the fault occurrence time prediction and explains the grey system theory.In Section 4,a novel prediction method is proposed.A case study is then outlined to demonstrate the manner in which the proposed method can be applied.Section 5 analyzes the data collected by the warning signal system of the transformer substation and predicts the fault status and occurrence time.Finally,Section 6 presents the concluding remarks and future work.
2.Fault Status Prediction
Transformer substations are one of the most important components of a power system.Avoiding damage to these units is vital to ensure the appropriate operation of the overall system.Many factors can cause substation faults,such as line and equipment issues[14].When these faults occur,the substation would give us the message of fault status,including informing,accident,deflection,overriding,and abnormality.The fault status can be predicted using different classification methods.
In this study,the supervised learning method is selected as the classification method.The supervised learning method is an important part of the machine learning field.It refers to a learning task for inferring the function from labeled training data[15].Based on the objects and class labels of a training set,the predefined class is identified and assigned to the selected object during the classification process.A complete classification method includes two phases:The first phase is defined as a learning phase,which is also known as the training phase;this phase entails building a classification model based on the known data (also termed the training data set).The second phase is the testing phase,which is also known as the working phase;in this phase,unknown data are classified based on the trained classifier.In the following section,the naive Bayesian algorithm and the decision tree algorithm were adopted as the classification method for predicting the substation fault status.
2.1.Naive Bayesian Algorithm
The Bayesian theory is a probability-based inference method.The formula of the Bayesian theory is shown in (1):

whereP(X∣Y) represents the probability that eventXwill occur if eventYhas occurred.
A naive Bayesian algorithm assumes conditional independence between attributes.It performs well in the medical domain and software fault-correcting field[16],[17].The process of the naive Bayesian classification algorithm provided by Spark is as follows.First,the prior probability of each category is calculated and its logarithm is estimated.

whereXis an item to be itemized;eachais a property ofX;Cindicates a set of categories.
The priori probabilities and their logarithmp(i) for each class are obtained as follows:

wheretiis the number oficategory,δis the smoothing factor,Iis the total number of times,andKis the number of categories.Then,the conditional probabilities of each characteristic attribute in each category are estimated and the logarithm is obtained:
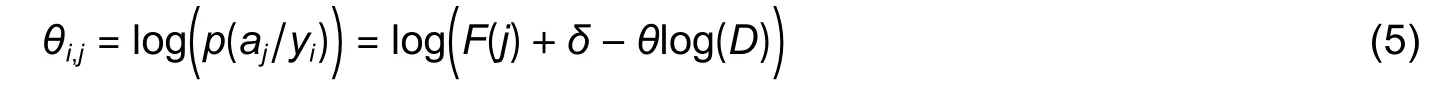
whereθi,jindicates the probability of characteristicjunder classiandF(j) is the number of occurrences of characteristicj.The conditional probability estimates for each characteristic attribute under each category are considered,and their logarithms are obtained via (5).Andθlog(D) is divided into the following two modes.
1) The polynomial mode is

For text categorization,ωirepresents the total number of words in classiandNfindicates the number of features.
2) The Bernoulli model is

For text categorization,nis the total number of articles under classi.
The probabilities ofp(yi/x) are calculated,and each attribute is conditionally independent in accordance with the Bayesian theorg,based on which the following can be derived:

Because the denominatorp(x) is constant for all categories,we maximize the numerator as (9):

By considering the logarithm of (9),the following equation can be obtained:

2.2.Decision Tree Algorithm
The decision tree algorithm is a type of nonparametric supervised learning method for classification and regression operations.In smart grids,it has been used for transformer design,condition monitoring,assessment,fault diagnosis,theft detection,and repair[18].The main objective of the decision tree algorithm is to create a model that can predict the value of the target variable by learning how to infer the characteristics of data based on simple decision rules.There are many implementation algorithms for decision trees,like ID3 and C4.5 algorithms.C4.5 is based on ID3,which attempts to identify small (or simple) decision trees.The C4.5 decision tree is one of the most widely used and effective methods for inductive inference[19].
The objective of a decision tree algorithm is to obtain a set of classification rules from a training data set.The optimization method entails selecting the local optimal features as the partitioning rule and is usually adopted to perform the prediction.The learning phase of the decision tree offered by Spark is generally divided into three steps:Feature selection,decision tree generation,and decision tree pruning.The specific process can be given as follows.
1) The criterion of feature selection is to determine the optimal local features and judge their classification effect on the current data set.It is considerably important to judge whether the data are classified according to the selective features.The information gain rate is used to measure the magnitude of this order of change.The determination of the classification rules at the current node is dependent on the ordinal purity of the classes in the node data set after segmentation.There are three methods to measure the purity of the node data sets,namely,entropy,Gini,and variance.In this paper,entropy is used to measure the purity and indicates the expected value of information.Information entropy can be defined as
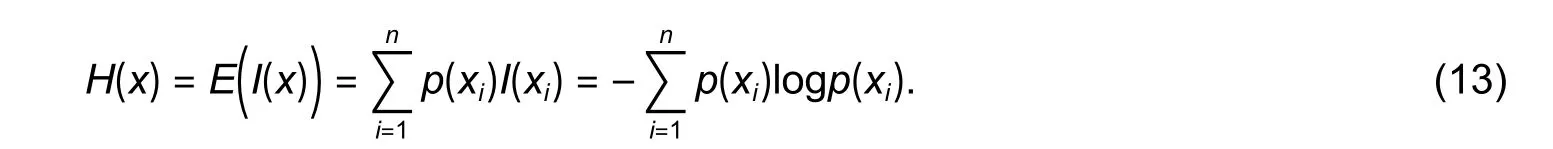
Further,conditional entropy can be defined as
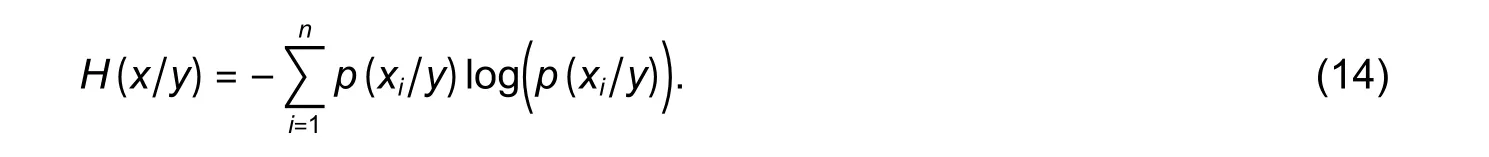
The information gain of characteristicAon the training data setD(g(D,A)) is defined as the difference between the information entropy of the setD(H(D)) and the conditional entropy with characteristicAunder the given conditionD(H(D/A)).Then,

whereH(D) is the information entropy from (13).
According toA,Dwill be divided intonparts,D1,D2,…,Dn.Then,H(D/A) is the average value ofH(Di),wherei=1,2,…,n.

The rate of information gain will be used to indicate the information gain,which is a relative value.The rate of information gaingR(D,A) of the characteristicAto the training setDis the ratio of the information gaing(D,A) and the entropy of the splitting information ofA,which can be given as follows:

whereH(A) is the split information ofAand

2) When the decision tree requires splitting,the gain rate of each attribute will be computed.Then,the maximum gain rate will be selected to split the decision tree algorithm.The generation process of the decision tree algorithm is shown as follows.
Input:Training data setD,characteristic valueA,and threshold valueϵ.
Output:Decision treeT.
1) If all the instances inDbelong to the same classCk,thenTis a single-node tree andCkwill be considered to be the class mark for that node.Then,returnT.
2) IfA=∅,thenTis a single-node tree and the largest class of instancesCkinDwill be considered to be the node mark.Then,returnT.
3) Otherwise,according to the Gini feature-selection algorithm,the information gain of each feature inAtoDis calculated,and the largest feature of information gainAgis selected.IfAgis less than the threshold valueϵ,thenTis a single-node tree and the largest class of instancesCkinDwill be considered to be the node mark.Then,returnT.Otherwise,according toAg=ai(aiis the arbitrary value inAg),Dwill be divided into some nonempty subsetsDi.Then,the largest class of instances inDiwill be the mark to build its child nodes.The decision treeTwill then be made up of the node and its child nodes;subsequently,returnT.
4) For the child nodei,the subtreeTiwill be obtained based on the training setDi,feature setA−{Ag},and the recursion process of (1) to (3).
2.3.Comparision of the Two Methods
The naive Bayesian algorithm,as a classical algorithm type,has a solid mathematical foundation and steady classification efficiency.However,different attributes must be independent,which will enable us to gain trustworthy prediction[20].In fact,connections always exist between different data.Furthermore,although naive Bayesian algorithms can produce good prediction results in a short time and occupy fewer resources,more accurate prediction results are required in the long term[21],[22].
The decision tree algorithm is simple and easy to understand.Trees can be visualized,and it is able to handle both numerical and categorical data.Other methods typically specialize in the analysis of data sets that feature only one type of variable.It can also solve the multi-output problems[21].It is common for decision tree algorithms to be subject to the overfitting problem with noise.To solve this problem,the generalization ability must be improved through pruning.Pruning is a method for finding a balance between the prediction error of a training tree and the complexity of the tree.The process of pruning the algorithm is as follows.First,back up from the leaf nodes.Then,compare the degree of ordinal change before and after the cutting of the node.If the ordinal change is small without the leaf node,the node must be cut off.Comparatively,the cost of the decision tree algorithm is higher,but its results are superior.Therefore,a decision tree algorithm will be selected for the big data-based prediction of transformer substation faults.
3.Fault Occurrence Time Prediction
In this section,the grey system theory is adopted into the classification method to predict the substation fault occurrence time.Fault status prediction provides us with a guide to solve the problems.Then,the level of faults can be estimated and more effective methods can be adopted.However,the prediction is only based on a single dimension,we should consider the fault occurrence time.In this section,the grey system theory is incorporated into the classification method to predict the fault occurrence time of a power substation.Timeseries analysis is a common sequence pattern search known as trend prediction exploration.Common trend prediction methods include the autoregressive integrated moving average model (ARIMA) and the grey system prediction model.
The grey system refers to an uncertainty system that can be reflected by part of the known information on the sample date.Incomplete information includes the system factor,factor relation,system structure,and system action principle.Uncertainty systems with incomplete information are considered by generating,excavating,and extracting useful information from available resources,based on which the operational behavior and laws of evolution of the systems can be accurately described and effectively monitored[23].Accordingly,there is a white system with complete information and a black system with incomplete information (only the latter is in contact with the outside world).The objective of the prediction method of the grey system is to determine the change rule by resolving the similarity or dissimilarity in the development trend of system factors.The model is established by generating the strong regularity of the data sequence to predict future development trends.The generation operation is divided into the accumulated generating operation (AGO) and inverse accumulated generating operation (IAGO).First-and second-order AGO sequences are often utilized.
AGO is a cumulative sequence over a time interval,the original sequence is shown as (19):


where

IAGO is an inverse cumulative sequence in a time period,X(1)is the original sequence:

The inverse cumulative sequence can be given as

where

The grey system prediction model is a time-series prediction model.The differential equation of grey system theory is the grey model (GM).GM(1,1),as the grey model’s first-order variable,is the most commonly used grey model.It is a time-series model,which is renewed as new data become available[24].The original model of G M(1,1) can be given as

whereais the development coefficient andbis the grey influencing coefficient that can be determined by

Using the least square error method,the parameters can be obtained as follows:

where
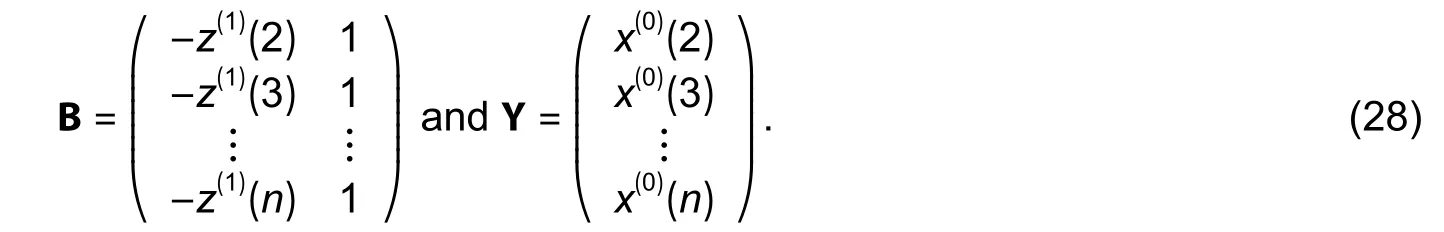
The solution of the differential equation is a time response sequence:

The time response sequence of G M(1,1) is as follows:

Commonly,x(1)(0)=x(0)(1) and
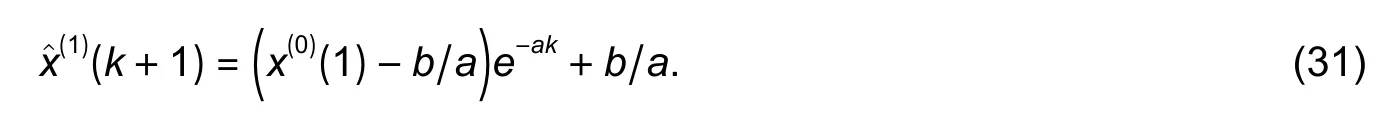
With IAGO,the results for G M(1,1) can be given as

4.Propesed Prediction Method
The main objective of the prediction method described in this study is to analyze the historical data of the collected alarm signals.The historical signal is used as an attribute of classification data,and the forecast content is placed in the classification category.All the analytical methodologies are based on the usage of the classification algorithm provided by the Spark big data platform.The prediction method is schematically depicted inFig.1and includes two parts.In the first part,the fault type of the substation is predicted using the decision tree algorithm.In this part,two methods are applied in practical cases.By comparing the results obtained using the decision tree algorithm with those of the naive Bayesian algorithm,the decision tree algorithm is concluded to be more suitable for performing fault type prediction.In the second part,the fault occurrence time is predicted using the grey system theory.These two parts can then be combined to construct a novel prediction method.The specific steps are as follows.
Step 1.Preprocess the collected alarm signal data.The collected data are classified according to the site and data attributes.Subsequently,the data are divided into a number of subsequences according to the length of a certain subsequence.The data of the alarm signal types must be replaced by the Hash table to convert the text data into double-type data,which are then available for the Spark platform.The time data require cumulative operation to generate time difference data and convert the white system into a grey system.
Step 2.Use the retention method to evaluate the performance of the algorithm.The preprocessed data are randomly divided into two parts at a 0.6:0.4 ratio,among which one part is termed as the training data set for training the classification model and the other part is called as the testing data set for testing the trained model.
Step 3.Enter the training data set into the algorithm to train the classification and grey models of the decision tree.
Step 4.Enter the testing data set into the trained algorithm model for testing.This process is called the working session.
After entering the test data into the resulting classification model,the predicted classification category is obtained.If this category is the same as the real category in the data,the result is accurate;otherwise,the result is inaccurate.Subsequently,the amount of test data is divided by the number of accurate categories to obtain the prediction accuracy.
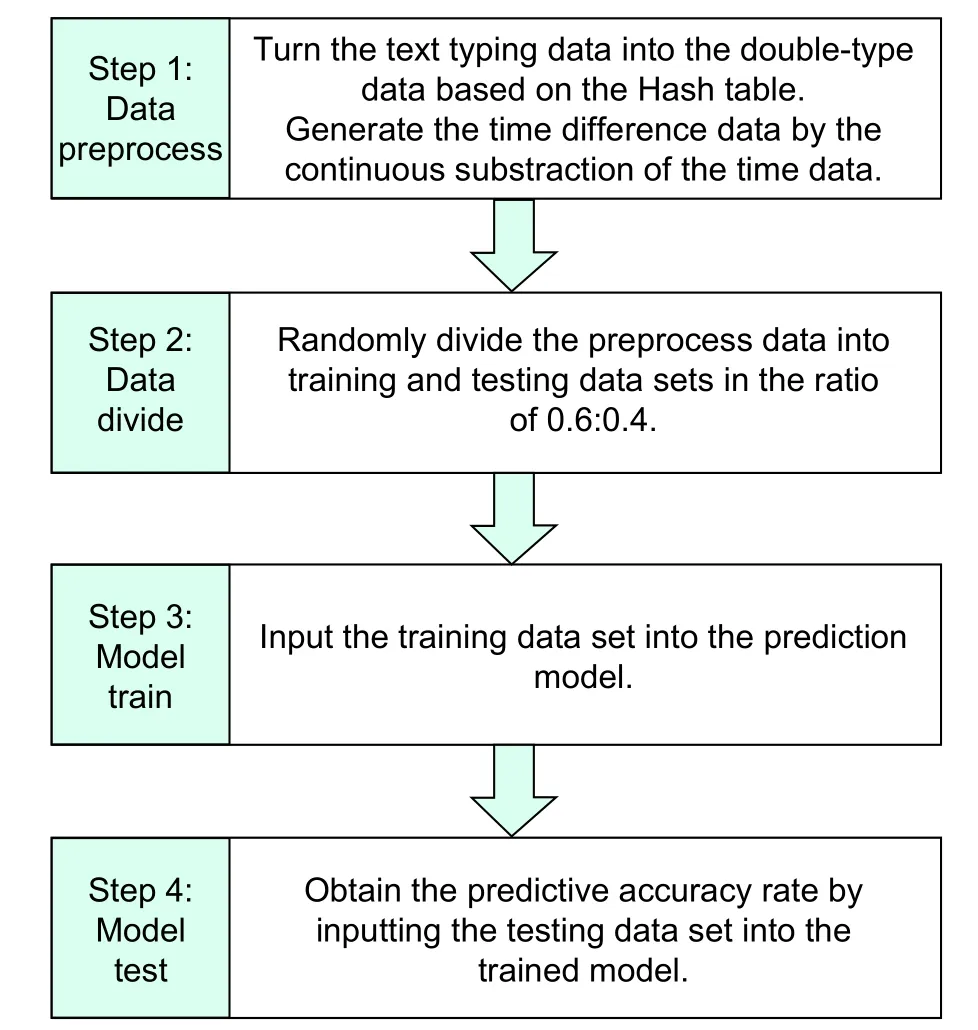
Fig.1.Diagram of the prediction method.
5.Case Study
5.1.Data Collection and Pretreatment
For this study,17675630 pieces of fault information were collected from a region in southwest China in 2016.Each piece of data contains 43 types of information,including the occurrence time,alarm information,device identification (ID),transformer name,and transformer voltage level.The occurrence time and alarm information are discussed in this study.The alarm information includes six different elements,namely,informing,overriding,abnormality,accident,deflection,and others.Informing indicates the normal operation of the equipment,whereas the remaining five categories represent transformer faults.Therefore,a transformer’s fault and the occurrence time can be predicted if the signal type and its occurrence time are accurately predicted.The occurrence time includes 24 hours per day,i.e.,from 00:00 am to 11:00 pm with a total of 24 data types,namely:00,01,02,03,04,05,06,07,08,09,10,11,12,13,14,15,16,17,18,19,20,21,22,and 23.
This paper analyzes and forecasts the substation fault types and fault occurrence times at four different sites.Station A presents 3625409 pieces of data,station B has 4494081 pieces of data,station C has 4902503 pieces of data,and station D has 4653637 pieces of data.Because the naive Bayesian and decision tree algorithms provided by Spark can only process and analyze double-type data,the previous output signal class data are mapped to the corresponding number via the Hash table.Table 1presents the corresponding Hash table.Furthermore,time data must be transferred via inverse cumulative calculations to obtain the time difference data.The previous data must be considered as the classification attributes,and the data to be predicted must be considered as the classification categories.During this study,the entire data sequence was divided into a number of subsequences containingNdata.It is necessary to predict theNth data.The first set of data is considered as attribute 1,the second as attribute 2,the third as attribute 3,and so on to establishN−1 data as attributeN−1.For the naive Bayesian algorithm,the data format should be the “Nth of data,the first data,the second data,···,the (N−1)th data.”

Table 1:Hash table
In this study,the accuracy of the two algorithms with respect to different subsequences is obtained by changing the length of the subsequences.The optimal subsequence length can be found by changing subsequence lengths.The lengths of the selected subsequences are 3,5,8,10,12,15,18,20,22,and 25.Finally,the processed data are divided into training and test data sets according to the ratio of 0.6:0.4 to complete final data preprocessing.
5.2.Fault Type Prediction
Six signal types are predicted in this study.The training data set of the signal type is input into the naive Bayesian and decision tree algorithms to obtain the corresponding training models.The accuracy of the naive Bayesian algorithm is a function of the testing data set entered into the model,as shown inFig.2.The accuracy of the decision tree algorithm is shown inFig.3.
Based on the obtained image,the decision tree algorithm can predict the signal type with high accuracy.The average accuracy of the length of each subsequence obtained via the algorithm can be calculated by averaging the accuracy of the four substations with the same subsequence length.The subsequence length with the highest average accuracy is the optimal subsequence length.
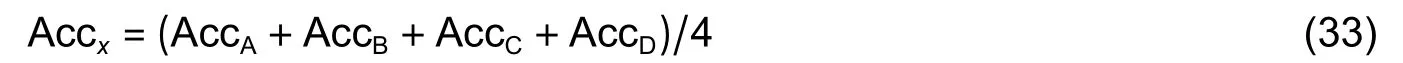
where Accxis the average accuracy of subsequence lengthxand AccA,AccB,AccC,and AccDare the accuracy of stations A,B,C,and D,respectively.And the average accuracy of the optimal subsequence length can be obtained as
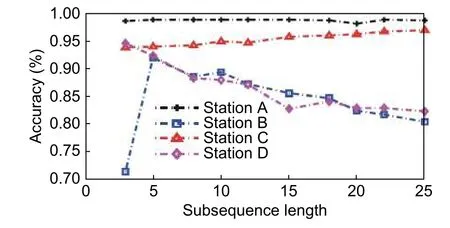
Fig.2.Accuracy of the predictive signal type using the naive Bayesian algorithm.
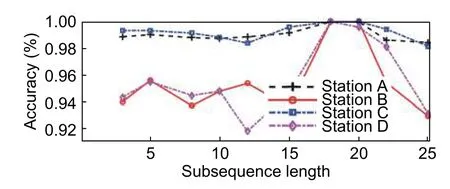
Fig.3.Accuracy of the predictive signal type using the decision tree algorithm.
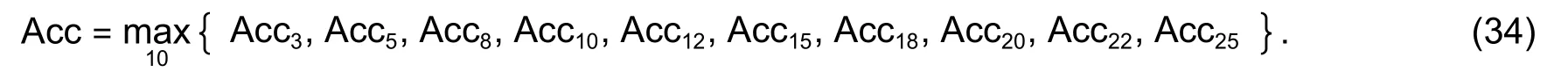
As shown inFig.2,the optimal subsequence length of the naive Bayesian algorithm is 5,and its accuracy is between 0.92 and 0.99 at different sites.When the subsequence lengths increase,the accuracy of stations A and B remain,steady,whereas those of stations C and D decrease rapidly.Therefore,the optimal subsequence length of the naive Bayesian algorithm is relatively short;thus,the algorithm works relatively quickly at low cost.However,the accuracy is not especially high,particularly over the long term.
As shown inFig.3,the prediction result of the decision tree algorithm is more accurate.The accuracy is greater than 0.95 for subsequences of different lengths.According to the above method,the average accuracy of the optimal subsequence length is 18,and the accuracy is approximately 1.This implies that the decision tree algorithm can accurately predict the fault types of transformer substations when considering the optimal subsequence.
The two aforementioned methods are used for predicting the fault types.The same data are utilized to build the classification model and perform the test.From the two figures,when the optimal subsequence length of the naive Bayesian algorithm is 5,its accuracy is identical to that of the decision tree algorithm.However,when the optimal subsequence length of the decision tree is 18,the accuracy of the naive Bayesian algorithm is not so good and is approximately 0.9.Thus,a more accurate result can be obtained for a longer subsequence length by using the naive Bayesian algorithm.For long-term prediction,the decision tree algorithm is selected as a better fault prediction method and must be applied to balance the subsequence length and cost.

Fig.4.Accuracy of the predictive occurrence time using the decision tree algorithm.
5.3.Fault Occurrence Time Prediction
First,the decision tree algorithm is used to predict the fault occurrence time.The training data the used are to build the model,and the testing data were used to verify the accuracy.Based onFig.4,the accuracy is not sufficient,especially for station D.Although the accuracy of station B is greater than 0.9,the accuracy of station C is approximately 0.7 and that of station D is less than 0.7.Thus,it is not viable to use the traditional decision tree algorithm for predicting the fault occurrence time.
Therefore,the grey system theory is selected to predict the fault occurrence time.In this method,the fault occurrence time prediction is converted into occurrence time difference prediction;then,a grey system is obtained.Thus,GM(1,1) can be used to predict the time difference of the next alarm signal based on the time difference of historical data.Finally,the predicted time difference is added to the current signal time,and the occurrence time of the next signal is obtained.
The training data set of the occurrence time difference data after preprocessing is input to GM(1,1),and the corresponding training model and time response formula are obtained.The accuracy of the testing data set input into the model is shown inFig.5.

Fig.5.Accuracy of the predictive fault occurrence time using the grey system theory model.
As can be seen fromFig.5,the grey system theory model has a high probability of predicting the occurrence time of faults.Different subsequences respond with different accuracy of occurrence time prediction.The accuracy of the four substations is more than 0.82.The accuracy of stations A and B is perfect,i.e.,approximately 1.The accuracy of station C is 0.88 to 0.92,whereas that of station D is 0.82 to 0.88.The prediction curves with respect to the accuracy at different substations exhibit small fluctuations.
In conclusion,the occurrence time prediction accuracy of the grey system theory is superior to that of the decision tree algorithm.Thus,the grey system theory is more suitable for fault occurrence time prediction.
5.4.Fault Prediction with Optimal Subsequence Length
By comprehensively considering the fault type and fault occurrence time prediction,the decision tree algorithm is combined with the grey system theory,and a novel method is obtained.The fault prediction result is shown inFig.6.The improved method can predict the substations’ faults effectively.Different subsequences result in different fault prediction accuracy.All the accuracy is greater than 0.75.For different substations,the accuracy rate exhibits some fluctuations.The accuracy of stations A and B is flat,approximately 1,whereas those of stations C and D are clearly changing.The accuracy of station C in case of different subsequences is greater than 0.85.However,the accuracy is less than 0.8 when the subsequence lengths of station D are 15 and 22.The accuracy of different substations is considerably different,and the optimal accuracy of each station is also very different.
The optimal subsequence length is obtained in the same way as in (33),with the optimal subsequence length of the novel method being 18.The experimental results obtained by combining the decision tree algorithm and grey system theory to predict the substation warning signals,as shown inFig.7,confirm that the proposed method achieves higher accuracy in fault prediction than that obtained by only using the decision tree algorithm to predict the fault type and occurrence time.

Fig.6.Accuracy of the predictive fault using the proposed method.

Fig.7.Experimental results for transformer substation fault prediction.
6.Conclusions
In this paper,we propose a method by using Spark as the data analysis platform and use the decision tree algorithm and grey system theory to forecast substation faults.Our method is confirmed to be very accurate with respect to the practical application of substation failure prediction analyzed and verified by using the substation fault signals in a given area of southwestern China.In future work,the faults in regional smart grids must also be considered.Moreover,the prediction of the influence of one transformer station’s faults on others in the same network could be discussed in detail.
Disclosures
The authors declare no conflicts of interest.
 Journal of Electronic Science and Technology2021年2期
Journal of Electronic Science and Technology2021年2期
- Journal of Electronic Science and Technology的其它文章
- Perovskite Single Crystals:Synthesis,Properties,and Applications
- Progress and Prospects of Hydrogen Production:Opportunities and Challenges
- Improved Active Islanding Detection Technique for Multi-Inverter Power System
- Comparison of Khasi Speech Representations with Different Spectral Features and Hidden Markov States
- Neural Network Based Adaptive Tracking of Nonlinear Multi-Agent System