
Comparison of Khasi Speech Representations with Different Spectral Features and Hidden Markov States
2021-08-16 01:56:16BronsonSyiemSushantaKabirDuttaJuweshBinongLairenlakpamJoyprakashSingh
Bronson Syiem| Sushanta Kabir Dutta | Juwesh Binong |Lairenlakpam Joyprakash Singh
Abstract—In this paper,we present a comparison of Khasi speech representations with four different spectral features and novel extension towards the development of Khasi speech corpora.These four features include linear predictive coding (LPC),linear prediction cepstrum coefficient (LPCC),perceptual linear prediction (PLP),and Mel frequency cepstral coefficient (MFCC).The 10-hour speech data were used for training and 3-hour data for testing.For each spectral feature,different hidden Markov model (HMM) based recognizers with variations in HMM states and different Gaussian mixture models (GMMs) were built.The performance was evaluated by using the word error rate (WER).The experimental results show that MFCC provides a better representation for Khasi speech compared with the other three spectral features.
1.Introduction
Speech is the easiest mode of communications between individuals and in fact it is the most efficient form of exchanging information among humans.The perception of speech looks simple for humans but in reality it is quite complicated.The same word of a language can be pronounced differently by different people depending upon the region they have been living in.Also,every individual has unique pitch and formant.Hence,the representation of the speech signal is required in order to understand different features associated with and to preserve the information needed to determine the phonetic identity of speech.Generally,the representation of speech is specified by a model description including the parameters and coefficients of the signal[1].Based on these parameters,speech representations can be classified into two groups,namely the parametric representation (based on model parameters,e.g.,pulse code modulation) and the non-parametric representation (only consisting of signal coefficients,e.g.,sinusoids)[1].The representation of speech in a complete and compact form is of great importance in an automatic speech recognition (ASR) system[2].The usage of an appropriate representation of the speech signal yields a more efficient speech coding system,which could improve the quality of speech synthesis and the performance of recognizers[1].Speech recognition systems generally assume that the speech signal is a realization of some messages encoded as a sequence of one or more symbols.To realize the reverse operation of recognizing the underlying symbol sequence from the spoken utterance,the continuous speech waveform is first converted to a sequence of equally spaced discrete parameter vectors[3].This sequence of parameter vectors is assumed to form an exact representation of the speech waveform for the duration covered by a single vector (typically 10 ms or so).Much research has been carried out in this area to represent speech,however,majority of the work done uses only a few different signal representations.The cepstrum coefficient (CC) is a representation which is the most commonly used in speech recognition systems[4].
Using the canonical representation of speech,the separation of voiced and unvoiced sounds with the TIMIT database was performed in the past[1].The experiment focused on this separation with a high-efficient result was achieved.However,it did not perform the investigation of speech recognition.Other related studies using the spectral representation with combined pitch-synchronous acoustic features were also done,in which the result showed a relatively low word error rate (WER)[5].However,the experiment was only performed with few spectral features.The speech representation based on phase locked loop (PLL) features of voiced sounds with the TIMIT database showed a higher recognition rate when it was measured over a range of high noise[6],yet issues remain to cover the unvoiced segments.The phone recognition using three spectral features (linear prediction cepstral coefficient (LPCC),perceptual linear prediction (PLP),and Mel frequency cepstral coefficient (MFCC)) on the Manipuri language was performed with three different modes of conversation.The results showed a slight improvement[7].However,they did not perform the analysis with varying hidden Markov model (HMM) states and mixture models.In this work,the speech recognition would be performed with varying HMM states and mixture models,and meanwhile more spectral features will be used.
Despite major advancements have been achieved in the state-of-the-art speech recognition systems,there still exists a huge and challenging task,particularly for those with low resource languages.Till date,very limited research has been conducted with regard to to Khasi speech recognition and as far as our knowledge is concerned,no Khasi speech recognition with different HMM states has been performed.In this paper,we investigate the Khasi speech representation using different spectral features with three different HMM states,which is an extended version of our previous work[8].
2.Khasi Language
The Khasi language is one of the Austro-Asiatic languages under the Monkhmer branch and is spoken by the natives of the state Meghalaya[9].Depending on the geographical location and local residents,the dialects vary to some extent.Based on this,Bareh proposed a total of 11 Khasi dialects[10].According to the research of Nagarajaet al.,Khasi dialects are comprised of four major dialects including Khasi Proper (from Sohra),Pnar,Lyngngam,and War[11].Amongst these four dialects,Khasi Proper is the standard Khasi dialect and hence it is chosen to be studied in this work.
3.HMM State
HMM can be considered as a stochastic,finite state machine with an unobserved state used for modeling speech utterance[12].In HMM,the state is hidden,however,the output that depends on the state is assumed to be visible.Since the state is hidden,the only parameters for HMM are the transition probabilitiesaj,kand the emission probabilities (also called output probabilities)[13].Fig.1shows the general state diagram of HMM with thejth state and theith output probability distribution function.The states are fed forward,in other words,the states can stay in itself or move from the left-right direction but not in the reverse (right-left) direction.The starting state (q1) and the exit state (qj) are assumed to be non-emitting states,which means these states do not generate observations.The states (q2toqj–1)are considered to be emitting states with output probabilities ofb1tobi.These output probabilities generate the observation ot(the acoustic feature vector).Each observation probability is represented by a Gaussian mixture density[14].In this work,the 3,5,and 7 HMM states have been considered.
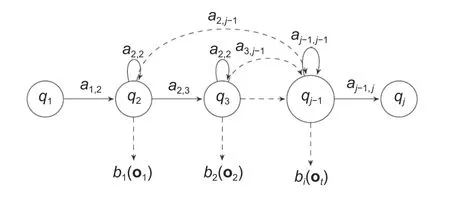
Fig.1.Left to the right HMM state diagram with the jth state and the ith output probability distribution function.
4.Spectral Features
In ASR systems,the feature plays a crucial factor.In this work,four different spectral features including linear prediction coding (LPC),LPCC,PLP,and MFCC have been used and they are briefly explained as below.
4.1.LPC
LPC is the method of estimating basic speech parameters (e.g.,pitch and formant) and used for representing speech with a low bit rate[15].It is based on the fact that a present speech sample can be approximated as a linear combination of past speech samples.
4.2.LPCC
LPCC is the derived feature of LPC,which is one of the most popular techniques used for the speaker recognition system[16].To compute the LPCC feature,the LPC spectral envelope is first computed.The technique is similar to the MFCC computation.In MFCC,pre-emphasis is applied to the speech waveform,whereas in LPCC it is applied to the spectrum of the input speech signal[17].
4.3.PLP
This technique is similar to LPC.However,in PLP the spectral characteristics are transformed to match the human auditory system characteristics,hence PLP is more adaptable to human hearing compared with LPC.The main difference between these two techniques is that PLP assumes the all-pole transfer function of the vocal tract with a specified number of resonances[15].
4.4.MFCC
This feature is defined as the representation of the short-term power spectrum of a speech sound.It is based on a linear cosine transform of a log power spectrum on a non-linear Mel scale of frequency.In MFCC,the frequency bands are equally spaced on the Mel scale.This characteristic feature enables MFCC to approximate the human auditory system’s response more closely compared with the linearly spaced frequency bands used in the normal cepstrum[18].
5.Database Description
The collection of speech data can be made from different modes (e.g.,read mode,lecture mode,or conversation mode).The speech data used for this experiment are read-based,uttered by 120 Khasi native speakers.The speech data were recorded in a laboratory by using the Zoom H4N Handy portable digital recorder with a sampling rate of 16 kHz,where each speaker was given 50 unique sentences to read.The detailed description of the speech database is shown inTable 1.

Table 1:Database description
6.Experimental Setup
The experiment was carried out in the Ubuntu 14.04 long term support (LTS) platform using the hidden Markov model toolkit (HTK).The features were extracted by applying a Hamming window of 25-ms size with a frame shift of 10 ms.The extracted spectral features were used for creating the acoustic model (AM),whereas the transcription labeled files were used for creating the language model (LM).The numbers of wave files used for training and testing were 6000 and 1800,respectively.Different AMs were built by using 3,5,and 7 HMM states to represent each phone.Then the global mean and variance per HMM state were calculated by using the predefined prototype along with the acoustic vectors and transcriptions of the training data set[19].The optimal values for the HMM parameters (transition probability,mean and variance vectors for each observation function) were re-estimated once an initial set of models was created.The pronunciation dictionary/lexicon was built by splitting the word sequence into the phone sequence.Table 2shows the illustration of the dictionary used in the experiment.Each phone acted as an acoustic unit that was further used for training the HMM model[20].LM was used for creatingn-gram corresponding to the text transcription.In this experiment,we used bi-gram LM.Finally,the decoder captured the distinct sounds of each word and produced the output.It was further matched with the trained HMM for each sound then the phone sequence was determined like in a pronunciation dictionary.Finally,the word was recognized.The detailed process is schematically shown inFig.2.

Table 2:Illustration of lexicon used in the experiment
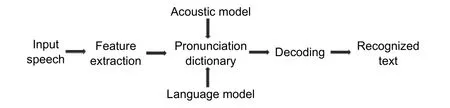
Fig.2.Schematic representation of speech recognition.
7.Results and Discussion
In this study,we have used four different spectral features with three different coefficient dimensions.HMM-based recognizers were built with different HMM states and different Gaussian mixture models(GMMs).From the experiment,we investigated the following three cases.
7.1.Case 1
In this case,the 13-dimensional spectral features were used to model HMMs with three different HMM states (3,5,and 7) and GMMs.The results are shown inFig.3.Using the LPC feature,we observed a relatively low reduction in WER irrespective of the variations in HMM states and GMMs.With the LPCC feature,more reductions of WER were noticed with respect to the changes in HMM states and GMMs.Furthermore,using the PLP and MFCC features,much more reductions of WER were presented as compared with the formal two features.For each feature,increasing the mixture components,more improvements in recognition were observed particularly for those with LPCC,PLP,and MFCC.However,a further increase in the HMM states to 7 shows a reduction in recognition performance.
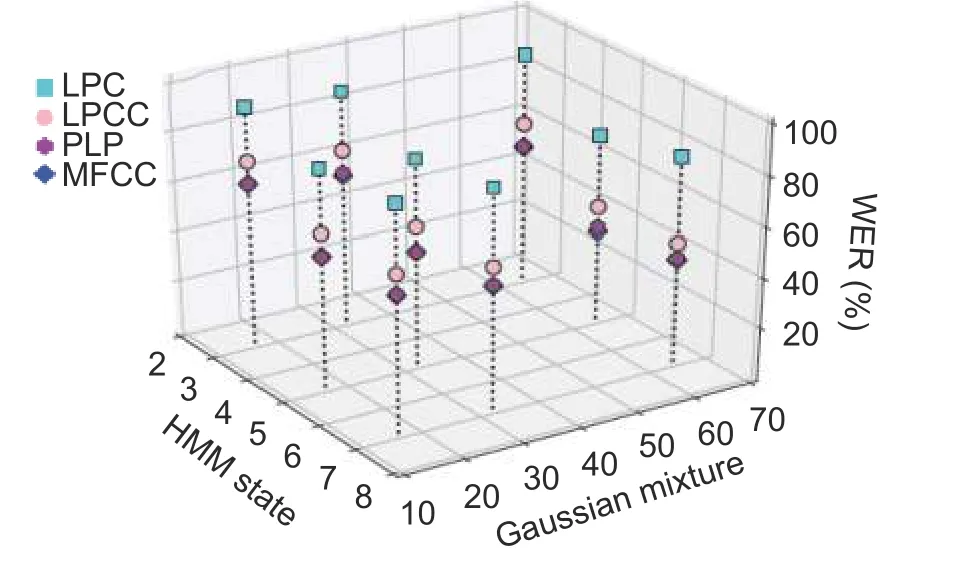
Fig.3.Scatter plot showing WER with respect to HMM states and GMMs for LPC,LPCC,PLP,and MFCC with 13-dimensional features.
7.2.Case 2
In this case,we used 26-dimensional features to build the models.By increasing the feature dimension,an improvement in recognition accuracy was observed.However,no improvement was obtained by using the LPC feature when increasing the feature dimension as well as HMM states and mixture components.Like in the first case (Case 1),there was a reduction in recognition performance when further increasing HMM states to 7,but with the increase of mixture components,it yielded good performance.The detailed change of WER can be observed inFig.4.
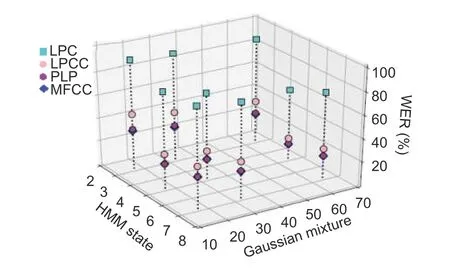
Fig.4.Scatter plot showing WER with respect to HMM states and GMMs for LPC,LPCC,PLP,and MFCC with 26-dimensional features.
7.3.Case 3
In the last case,we further increased the feature dimension to 39.The results can be observed fromFig.5.With further increasing the feature dimension,a more obvious improvement was raised in recognition than those in Case 1 and Case 2.However,by using the LPC feature,it showed poor performance.Besides 5 states,the variations of HMM states also did not show much enhancement in recognition.
In all the three cases,it was observed that the LPC and LPCC features resulted in poor performance.This may be due to the high noise sensitivity and the lack of using the human auditory feature during the feature extraction process as stated in [19].Further,it was observed that increasing the feature dimension could improve the performance.This possibly results from the insufficient coefficient to capture the phones under a low feature dimension.In order to make HMM more accurate,the mixture size must be increased[7]and,from the experiment,the optimal mixture size was found to be 64.Furthermore,though the increase of HMM states led to the increase of acoustic likelihood,it was found that when exceeding 5 states,no improvement was produced.This may be due to the short sequence of phones considered for creating the HMM model.The best performance was achieved by using 39-dimensional MFCC features with 5 HMM states,with the recognition accuracy of 90.36%.
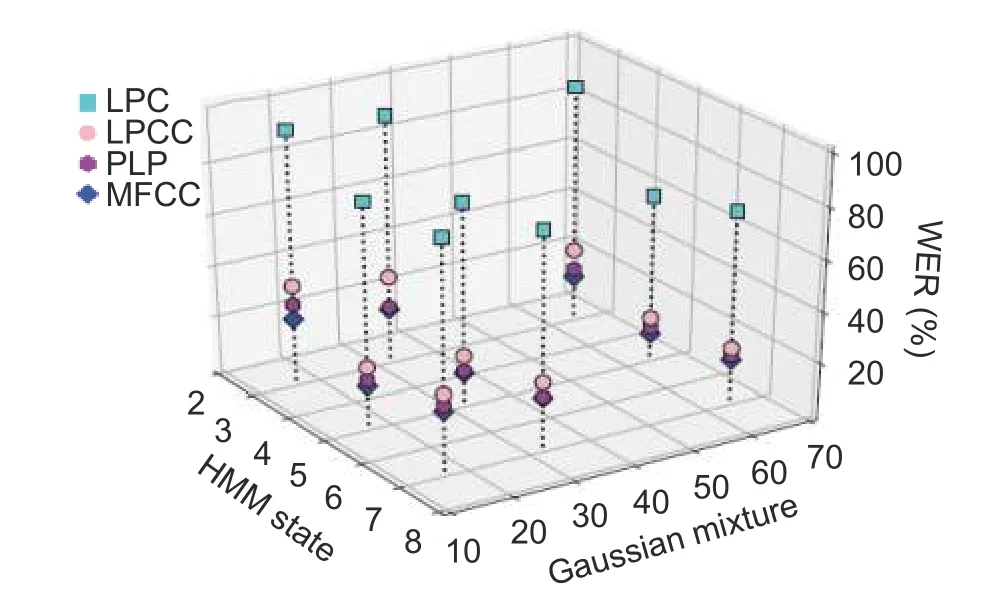
Fig.5.Scatter plot showing WER with respect to HMM states and GMMs for LPC,LPCC,PLP,and MFCC with 39-dimensional features.
8.Conclusion
In this experiment,we performed a comparison of Khasi speech representations with different spectral features and HMM states.The performance evaluation was done by building different HMM-based recognizers using the HTK ASR toolkit for different spectral features with different feature dimensions,HMM states,and GMMs.The experimental results showed the MFCC feature provided a better representation of Khasi speech.This study reveals that the ASR system does not only depend on model parameters but also the type of features used.One major outcome which can be derived from this work is that it has provided baseline information of the different features and HMM states.For future work,since ASR is a data driven system,more speech data can be incorporated and also the neural network classifier can be applied to improve the system performance.
Disclosures
The authors declare no conflicts of interest.
 Journal of Electronic Science and Technology2021年2期
Journal of Electronic Science and Technology2021年2期
- Journal of Electronic Science and Technology的其它文章
- Perovskite Single Crystals:Synthesis,Properties,and Applications
- Progress and Prospects of Hydrogen Production:Opportunities and Challenges
- Improved Active Islanding Detection Technique for Multi-Inverter Power System
- Big Data-Based Transformer Substation Fault Prediction Method
- Neural Network Based Adaptive Tracking of Nonlinear Multi-Agent System