
基于人工智能和随机森林的心理健康分析方法研究
2021-08-15 11:36童欢欢
电子设计工程 2021年15期
童欢欢
(西安航空职业技术学院,陕西西安 710089)
随着社会竞争、生活压力的增大,不少人出现了焦虑、抑郁等心理疾病。近年来,心理疾病逐渐呈现年轻化趋势,越来越多的年轻人出现心理健康问题,尤其是大学生[1-3]。然而人们对于心理健康的关注度较低,即使其已经出现了一定程度的症状,仍然没有意识到疾病的发生。心理疾病的出现,严重影响着人们的工作和生活,开展对心理健康状态分析方法的研究具有重要意义[4-7]。
传统心理健康监控方式相对被动、缺乏准确性,人们需要主动找心理医生咨询,并且进行检测才能确定是否患有疾病[8]。而医生主要采用的诊疗手段为沟通和问卷的形式,病情诊断结果在一定程度上受医生主观判断的影响而有所差异。值得注意的是,传统心理健康监控方式在心理健康疾病预防方面的效果极大取决于人们对心理健康的关注程度,且对于心理疾病发展的程度、药物的效果等缺乏合适的生物标记来量化[9-11]。
随着科技的发展,除了通过患者叙述自己的观念和感受来确定病情外,越来越多的学者开始尝试通过脑电波、心率以及皮电信号来研究心理健康是否出现了问题[12-13]。为了探寻更加高效、准确的心理健康判断方法,人工智能技术在抑郁症等心理疾病诊断方面的应用越来越多,并取得了初步成果[14-16]。
文中着眼于大学生心理健康情况,分别从学生的生理和心理两个角度进行心理健康分析。心率和体温等生理信息的变化可以反映该学生的心理变化;同时,其社交平台的言论也能反映出其心理状态是否正常。文中使用人工智能来进行多源、异构数据的特征提取;并使用随机森林作为分类器来识别心理健康程度。
1 智能化心理健康分析模型
为了提高人们对心理健康的重视程度以及对自身心理健康情况的了解,文中进行了智能化心理健康分析方法研究。大学生心理健康划分为焦虑、抑郁、恐惧、偏执、敌对5 个维度。智能化心理健康分析方法主要是构建智能化心理健康分析模型,模型具体框架如图1 所示。该模型侧重于心理健康的监控、心理疾病的预判,依靠智能设备作为运行平台和数据来源,通过对用户的心跳速率、运动数据深度分析用户行为信息;同时对用户社交账号的状态、评论等进行关键词提取,分析其情感状态。通过多模态数据的信息挖掘可以全方面地检测用户心理状态的变化,以便可以更好地预防心理疾病的出现。
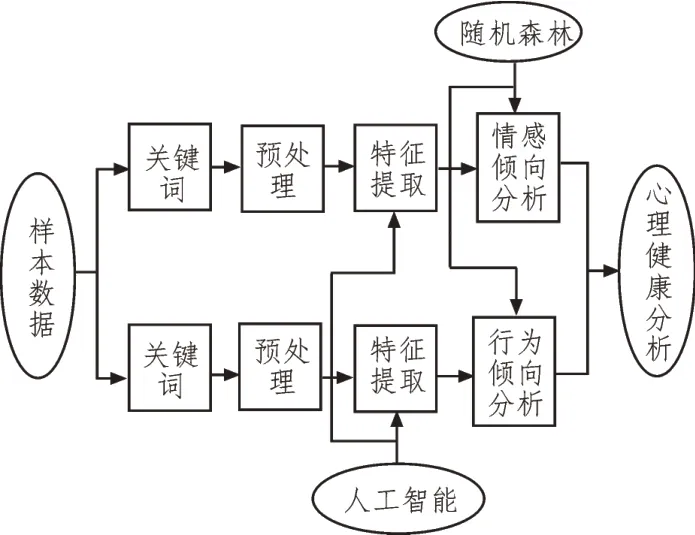
图1 智能化心理健康分析模型结构框架
为了建立全方位、智能化的大学生心理健康评估模型,文中通过采集心率、社交文本等信息来构建原始数据集并分别提取特征。然后,采用多特征融合的方式来进一步将特征向量降维。最后,利用融合后的特征向量作为训练样本数据进行模型参数的优化。文中使用人工智能的方法来确定生理信息和文本信息的特征向量。对于心理健康的分类判断则采用了随机森林算法。当模型的识别精度满足阈值时即代表模型参数已训练完成,可用于测试样本数据的验证。随机森林算法以多次随机采样的方式来保障模型的多样性,避免出现过饱和现象;同时将采样信息输入至多个弱分类器,来提高模型的复杂度。通过对每一个弱分类器的分类结果进行投票来确保整个模型具有较好的分类准确率以及泛化能力。
2 基于人工智能和随机森林的分析方法
2.1 生理信息与心理健康
近年来,越来越多的学者开始关注心率与心理健康之间的联系,试图利用心率的变化来量化心理健康,从而建立基于心率变化的心理疾病预测模型。心率的变化,通常使用心率变异性来描述。心率变异性被定义为连续心跳之间的时间间隔长度的变化情况,通常正常人的心跳并不是保持相同的时间间隔,且当人处于平静、运动、焦虑时,心跳的速度也有所不同。因此,通过监测正常人与心理疾病患者不同场景下的心率,可实现心理疾病的量化检测。
心率数据通过智能可穿戴设备的传感器采集,通常是一串时变、非稳态的时序波形数据,因此需要先进行时频域特征值的计算,再进行数据统计特征计算。由于人在不同的状态、不同的环境中心率跳动情况有所不同,因此在基于心率信息的心理健康分析模型中融入环境信息、体征状态信息和行为信息会提高心理疾病的识别精度。环境信息主要包括测试者所在地的海拔、气温等;体征信息包括体温、体表湿度;行为信息包括了步行数、步行数变化率等。
以上信息均为时序波形数据,特征提取和分析过程如图2 所示。首先分别将心率、环境、行为以及体感信息通过智能设备的传感器采集,并进行不同频率的离散化处理以便降低数据量、提高运算效率。然后再经过去基和滑动窗口操作将数据中的白噪声以及无意义数据剔除。最后分别就时域和频域进行特征提取,并进行各个特征的数理统计计算。
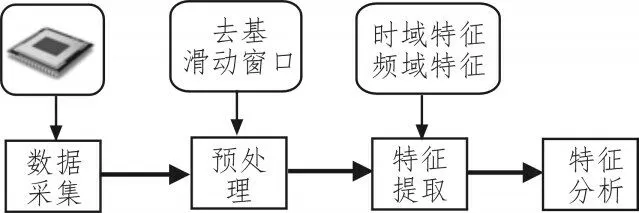
图2 生理信息的特征提取、分析示意图
考虑到智能可穿戴设备中加速度计和陀螺仪所带来的噪声信号等干扰,需要将传感器采集到的原始数据利用滑动窗口和去基的操作方法进行预处理。原则上,滑动窗口的大小应设定为传感器采样频率的2 倍,但为了保证快速傅里叶函数的计算,实际窗口的大小被定义为:

考虑到测试者并不是全时处于运动状态,采集到的数据中,静态数据占据了较大的比例,为了降低静态数据特征提取的计算量,文中采用去基操作进行静态数据预处理。具体操作为:首先使测试者处于完全静止的环境中,保持放松的状态进行各项数据采集,并提取各项特征作为基准值。当在其他环境和用户状态下,即可使用数据样本减去基准值,从而有效降低环境、状态所带来的影响,提高计算效率。
时域特征主要有平均值、标准差、最指、中位数等;频域特征有直流分量、信号幅度面积和幅度统计特征。其中信号的幅度面积可用下式描述:
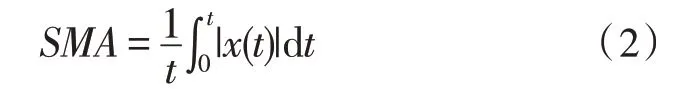
该指标被定义为离散数据与时间轴所围成面积的和,用于区分静态数据和动态数据。
在进行运动状态的数据采集时,提取特征既要保证精准度,同时也要避免计算量过大。因此,文中采用式(3)和式(4)进行时域和频域特征值的计算,式中,i表示第i条加速度计和陀螺仪的数值,ai表示的是合成后的加速度,wi表示的是合成后的角速度。
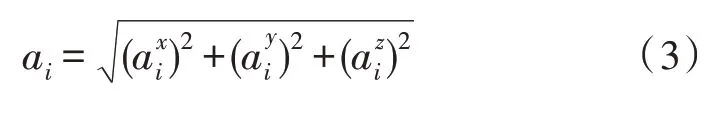
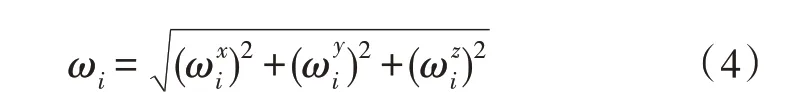
2.2 文本信息与心理健康
心率等生理指标是人身体状态的表现,而人所说的话、写下的文字则是其内心状态的反应。当人出现心理疾病时,其思想与正常人相比具有一定的消极性,利用其在社交平台上的文本信息进行心理健康评估的框图如图3 所示。
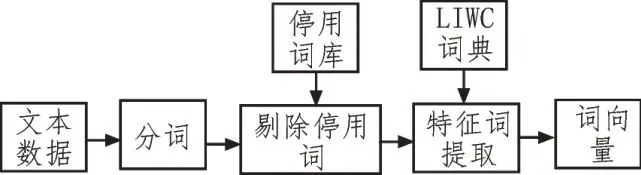
图3 融合了LIWC词典的文本信息的特征向量的提取
首先进行文本特征的提取。文中采用词袋模型来分解文本、提取特征向量。词袋模型的关键在于词典的构建以及各个特征词的权重计算。文中使用LIWC 词典作为基本词典,LIWC 词典包含了大量的心理过程词、社会过程词以及语言过程词。通过将用户在社交论坛上的文本信息进行分词,剔除停用词后再与LIWC 词典比对,由此得出文本信息中各个词对该用户心理健康的区分能力。
由于不同类别的词汇作用不同,文中主要集中关注人称代词、否定词、认知过程词汇等,并对这几类词汇进行权重计算,具体过程如下:
1)首先统计LIWC 词典中各个词类在相关主题中出现的次数。
2)对上述词频,计算标准差al,i并对最大值进行归一化处理。标准差的数值越大,表明该类词汇越有利于区分文本信息所体现的情感倾向与心理健康程度。
3)确定每个词的权重。通过判别该词汇属于LIWC 词典的哪一个分类来调整该词在甄别文本情感倾向时的权重。具体公式如式(5)所示。
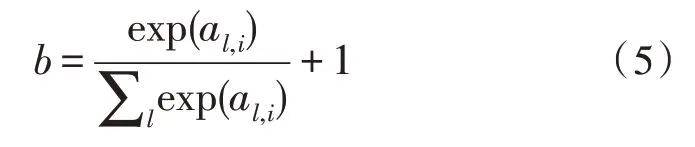
文本词向量的提取及文本信息情感倾向识别,则采用了基于随机森林和卷积神经网络的文本信息情感倾向识别模型,具体结构如图4 所示。首先将上文生成的特征向量以词向量矩阵的形式输入至输入层。在Attention 层中,可计算出不同词类的标准差,标准差越大,表明该词类在识别心理健康方面具有更显著的作用。在卷积层中,利用不同大小的滑动窗口来选择文本中的局部词向量,进而拼接得到新的矩阵。池化层通过选择合适的池化函数来选择区分文本情感最有效的特征值。将全连接层中已经完成上述处理的特征矩阵传输至随机森林中进行分类。值得注意的是随机森林中一颗决策树的平均泛化误差PE 与回归函数有关,具体公式如式(6)所示。
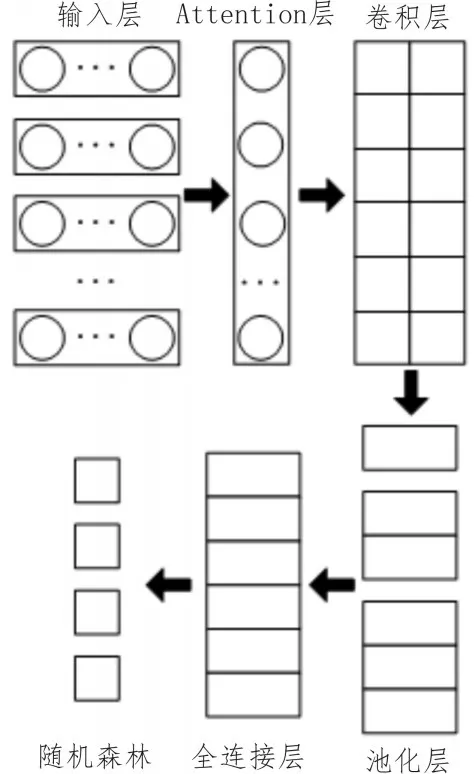
图4 基于随机森林和卷积神经网络的文本信息情感倾向识别模型结构示意图
在利用训练样本进行模型训练时,通过反向传播的方式来最小化交叉熵损失函数,同时对各个神经元的权重系数L2 进行正则化处理,以避免过度拟合。
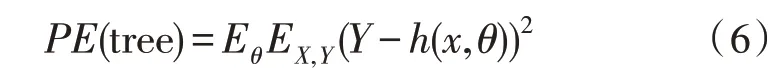
3 实验测试与数据分析
为了验证文中所提方法的正确性,使用某大学本科生、研究生以及博士生的真实数据集作为研究对象,其年级和性别如表1 所示。为了保证模型训练充分、且结果有效,随机抽取85%的样本数据作为模型训练数据;其余数据作为检测数据。通过设置对照组来测试文中所述方案的性能。对照组分别采用前馈神经网络和支持向量机两种分类器。由于随机森林算法决策树的数量影响着分类准确率,首先进行决策树数量的选择。测试结果如图5 所示。从图中可以看出,随着决策树数量的增多,分类准确率逐渐增加并趋于固定值。

表1 研究对象年级、性别统计情况
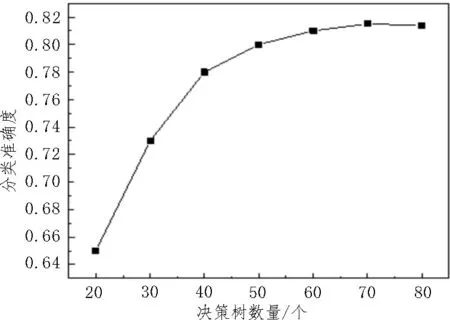
图5 不同决策树个数对分类准确率的影响
图6 以某个研究对象的数据为例,分别使用专家评判、随机森林、支持向量机、前馈神经网络四种方式进行心理健康程度的测试。图中横轴“1,2,3,4,5”分别代表焦虑、抑郁、恐惧、偏执、敌对这五类心理健康维度。在各个维度中越靠近专家评判,表明该算法识别准确率越高。从图中可以清晰看出,随机森林算法作为分类器识别结果更接近专家评判。综合所有样本数据,统计结果如表2 所示。文中所述方案在训练样本时识别结果准确率为81.8%;测试样本识别准确率为80.4%。两者数值均高于支持向量机和前馈神经网络算法。
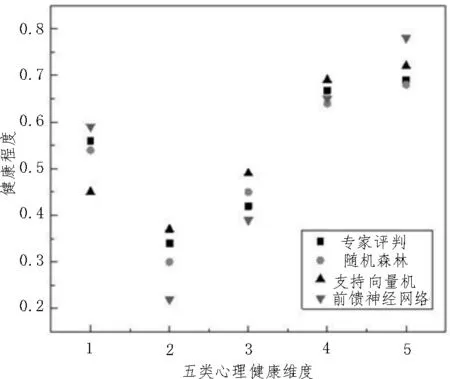
图6 某个研究对象五类心理健康维度实验组和对照组识别结果对比
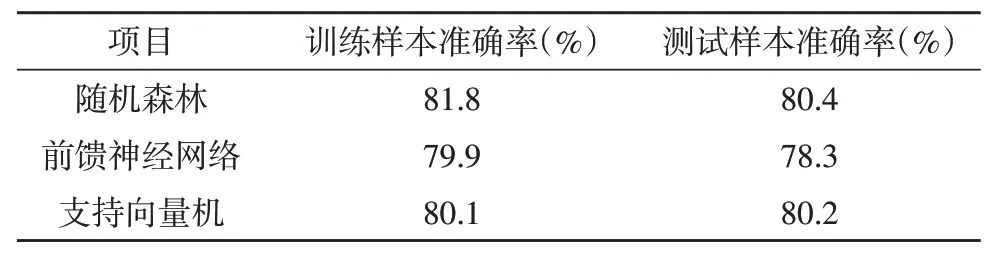
表2 实验组与对照组心理健康识别结果对比
4 结束语
文中使用人工智能中的卷积神经网络和随机森林算法进行了大学生心理健康分析技术的研究。使用心率等生理信息和社交文本信息可增加判断心理健康的数据维度,提供多层次的心理健康判断模型。卷积神经网络的应用使得样本数据的特征提取更快速和准确;同时采用随机森林算法作为分类器。经过测试和数据分析,文中所述方案在大学生心理健康的分析、识别方面具有80.4%的准确率,与支持向量机和前馈神经网络算法相比,其具有更高的识别准确率。
猜你喜欢
保健医苑(2022年4期)2022-05-05
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
家庭医药·快乐养生(2021年1期)2021-02-04
工业设计(2020年3期)2020-05-14
求学·理科版(2020年4期)2020-05-13
新世纪智能(数学备考)(2020年12期)2020-03-29
科学导报(2019年16期)2019-09-23
中国交通信息化(2018年5期)2018-08-21
