
基于大数据技术精细化社会治理系统研究
2021-08-09 19:52赵志海
粘接 2021年6期
关键词:社会治理
赵志海
摘 要:为解决常用系统管理大数据时存储器容量较小,不能满足大数据存储需求,导致系统运行的并发性和可扩展性较差的问题,设计了基于大数据技术的精细化社会治理系统。硬件设计方面,采取分块模式设计系统总体结构,通过接口板和存储板组成大数据存储器,选取Virtex-4 FPGA芯片作为存储板内部芯片,优化存储板PCB布局,扩增存储器容量,满足大数据大容量存储需求;软件设计方面,通过网络爬虫采集社会治理相关大数据,预处理大数据并对其进行分类,得到精细化数据项,为社会治理工作提供数据支持。设置对比实验,结果表明,设计系统执行大数据写入/读取操作时,提高了并行加速度,扩展比更接近1,并发性和可扩展性优于常用系统。
关键词:社会治理;模块结构;存储板;大数据预处理;精细化数据项
中图分类号:TP311.13 文献标识码:A 文章编号:1001-5922(2021)06-0072-05
Abstract:In order to solve the problem that the memory capacity of common systems managing big data is small and can not meet the storage requirements of big data, resulting in poor concurrency and scalability of system operation, a refined social governance system based on big data technology is designed. In terms of hardware design, the overall structure of the system is designed in block mode. The big data memory is composed of interface board and memory board. Virtex-4 FPGA chip is selected as the internal chip of the memory board to optimize the PCB layout of the memory board and expand the memory capacity to meet the demand of big data storage; in terms of software design, through the web crawler to collect social governance related big data, preprocess big data and classify it, get fine data items, provide data support for social governance work. A comparative experiment was set up, and the results showed that when the design system performs big data write/read operations, the parallel acceleration is improved, the expansion ratio is closer to 1, and the concurrency and scalability are better than common systems.
Key words:system design; Module structure; memory board; Big data preprocessing; refined data items
0 引言
社會治理是国家体系的组成部分,完善社会治理体系,必须推进社会治理体系信息化。因此,研究基于大数据技术精细化社会治理系统,将大数据资源运用到生活各个领域,参与到社会治理模式中,使参与社会治理的主体,在工作中做到细致精确,为民众提供优化服务,具有重要意义。
文献[1]采用物联网和云计算等技术,构建城市发展框架,从空间分布角度出发,将城市划分为政府、人群、产业、社区4个子系统,推动城市治理,但该方法构建的系统框架元器件集中,导致系统运行时间较长,并发性较差。文献[2]以信息过滤为起点,融合相关大数据的辅助数据,利用标签数据和反馈信息,为管理对象提供数据支持,但该方法预处理后的异构数据,仍具有不同结构,导致系统可扩展性较差。针对以上问题,设计基于大数据技术精细化社会治理系统,优化存储器,存储大容量原始数据,高速稳定运行大数据操作程序。
1 基于大数据技术精细化社会治理系统设计
1.1 社会治理系统硬件设计
1.1.1 设计系统总体结构
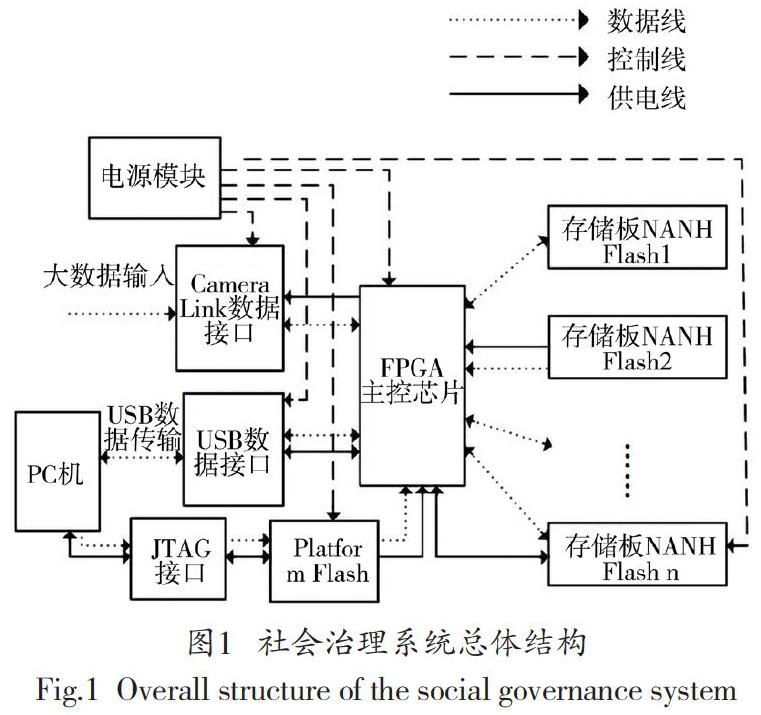
设计系统总体结构,实现社会治理相关大数据的输入输出和存储。系统采取分块模式,模块包括供电模块、主控芯片模块、主控芯片配置模块等模块。在Camera Link接口输入大数据,通过FPGA主控芯片内部的n块代码[3-4],编写双口RAM并检查执行的大数据,位宽转换64位数据信号,得到16位数据信息。下达大数据存储指令,缩短写指令的时间,由n块NAND Flash并行存储数据信息。通过NAND Flash获取的FPGA芯片和USB内部FIFO控制的主控芯片,获取与社会治理相关的数据,通过USB接口将数据传输到PC机。优化后的存储器结构如图1所示。
FPGA主控芯片选取CY7C68013型号,嵌入单片机8051核作为内部处理器,带有9.0KB片上RAM资源,与USB相互兼容,为大数据传输提供高速模式和全速模式,两种模式的速率分别可达490Mbps和15Mbps,拥有560个I/O引脚,方便大数据存储[5-6]。主控芯片配置模块选取合适的片外Platform Flash,型号为XCF08P-VOG48C,拥有10Mbit编程空间,与FPGA芯片进行匹配,提供5种配置模式。具体如表1所示。
当系统处于主控芯片配置模式时,将拨码开关接地,M0、M1和M2设置为0,从而选择主串模式下的FPGA芯片配置模式。Camera Link数据输入模块,使用4片DS90CR286和1片DS90LV019组成,采用MDR-26接头,该接头采用屏蔽技术,其接收信号包括6对控制信号和2对差分数据信号[7-8],大数据输入速度可达2.45Gbits/s,该模块使用24位Channel Link芯片,将接收的数据信号,转换为TTL电平信号,令社会治理相关大数据以700MB/s的速度,分配到数据线上,且线上数据速度保持在80Mb/s左右。至此完成系统总体结构的设计。
1.1.2 设计大数据存储器
设计系统存储器,高速、安全存储大数据,满足社会治理相关海量数据的大容量存储需求[9]。通过接口板和存储板,组成系统存储模块,扩大存储容量。接口板接收Camera Link数据信号,分配数据信号,传输至可用的存储板,利用双口RAM写入数据,在RAM另一端口导出数据,存入存储板,读取信号时,选择需要读取的存储板,查询社会治理相关数据。存储板内部采用型号为XC3S4000的Virtex-4 FPGA芯片,由芯片的写入模式记录并接收来自接口的控制信号和数据信号,在读取大数据时,串行数据信号从存储板芯片读取并通过主控芯片传输到接口面板。每块存储板采用6片FPGA结构,具备640个管脚数量,控制电路如图2所示。
该控制电路支持lvcmos I/O接口标准,符合LVDS信号,连接120Ω 在串行通信过程中,采用优化的PCB布局作为各存储单元的载体,用5层电路板将信号层、信号层和电源层隔开,实现了对接收端差分线的电阻化,减少了终端信号的反射,得到了完整的数据阵列,靠近报警层和地层,充分发挥电力层和地层的屏蔽作用。将接口板和存储板的芯片,放置在PCB层的中央位置,按照大数据流向排放,在芯片供电引脚处放置一个去耦电容,PCB布线采用 45°走线,使地线穿插在相邻的信号线之间,从而扩增存储板的存储容量,使其在短时间内存储社会治理相关大数据。至此完成大数据存储器的设计,实现社会治理系统硬件设计。
1.2 系统软件设计
采集社会治理相关大数据,输入存储至系统,预处理大数据,实现社会治理数据项的精细化分类。通过网络爬虫采集大数据[10-12],将社会治理作为关键词,在互联网中搜索网页,从种子UPL开始加入爬虫队列,解析下载网页,抓取UPL得到新的URL,获取社会治理领域数据,自定义添加社会治理相关内容,采集网页中的视频、音频、数据库、图片、文本数据等类型数据,去除新的URL,加入新的爬取队列,循环以上操作。通过随机选择数据采集中心的k个数据对象作为原始大数据采集中心,利用马式距离,比较初始聚类中心和剩余数据对象。马式距离计算公式为:
其中,N为原始大数据维度,xik为第k个数据维度中,大数据对象第i个数据、第j个数据的维度值,Hij为数据i和数据j间的马氏距离。若马氏距离Hij越接近1或-1,判定两个数据间的相关程度越高、距离越近,若Hij越接近0,判定相关程度越低、距离越远。将剩余数据对象移动到最近的起始类中心,然后再次选择聚类中心,重复迭代直至函数收敛,k个聚类中心不再变化。准则函数J定义公式为:
其中,Zr为第r类聚类中心的中心点值,Er为Zr平均值。清洗聚类后的原始大数据,删除社会治理不相关的记录,包括图片内容请求、文件请求、蜘蛛爬虫程序请求[13-15]。当分隔不符合逻辑的蜘蛛会话,蜘蛛通过HTTP头发起HTTP请求并识别网站用户,记录大量用户相关的社会治理信息。分片预处理后的大数据,对大数据进行精细化分类,得到不同局部的數据元组。分割后的精细化数据项如表2所示。
建设分布式SQL数据库,表示数据项属性结构,通过各项精细化数据集,为精细化社会治理提供数据支持。至此完成系统软件设计,实现基于大数据技术的精细化社会治理系统设计。
2 实验论证分析
将此次设计系统,与引言中提出的文献[1]和文献[2]两组常用社会治理系统,进行对比实验,分别记为常用系统1和常用系统2,比较写入/读取大数据时,3组系统的执行时间、并发性和可扩展性。
2.1 实验准备
搭建系统测试平台,集群节点包含4个存储计算节点、1个主控制节点,计算机处理器为Intel Xeon E5-2609,搭建集群网络拓扑结构,使主节点和存储节点在一个局域网内,在节点上完成系统部署和系统配置工作。实验数据为GroupLens提供的数据集包含视频音频、文档表格、图片影像、搜索引擎等,3组系统分别执行大数据输入输出、存储等操作,设计系统存储板优化后的PCB布局如图3所示。
2.2 实验结果
2.2.1 系统执行时间实验结果
当社会治理相关大数据写入/读取系统时,记录系统执行这一操作的运行时间,比较3组系统的大数据操作效率,实验对比结果如图4所示。
由图4可知,读取社会治理相关大数据时,数据量较少情况下,3组系统执行时间接近,当数据量增加时,两组常用系统执行时间迅速增加,设计系统执行时间上升缓慢,千次操作的平均执行时间为20.3s,常用系统1和常用系统2千次操作的平均执行时间,分别为26.1s和30.3s,相比两组常用系统,设计系统大数据读取的执行时间,分别缩短了5.8s和10.0s。大数据写入操作的执行时间,则明显小于读取时间,设计系统千次操作的平均执行时间为1.8s,常用系统1和常用系统2千次操作的平均执行时间,分别为2.6s和3.0s,相比两组常用系统,设计系统大数据写入的执行时间,分别缩短了0.8s和1.2s,提高了大数据写入/读取系统的执行效率。
2.2.2 系统并行加速比实验结果
令3组系统执行大数据写入/读取操作,通过加速比,衡量系统写入/读取程序的并行性,加速比越高,系统并行性越好。加速比m计算公式为:
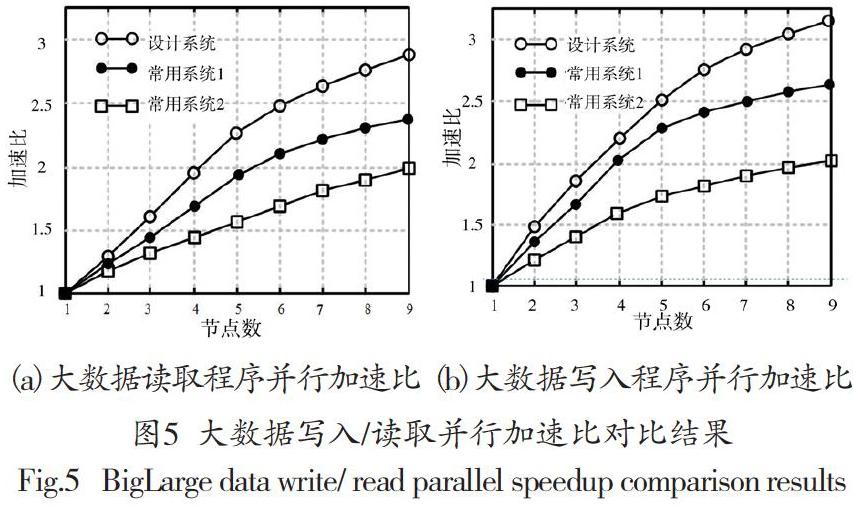
其中,t1为单处理器下,执行大数据写入/读取操作的系统运行时间,tn为n个处理器下系统并行操作的运行时间。在集群节点全开的环境下,执行大数据写入/读取程序,3组系统并行性实验对比结果如图5所示。
由图5可知,集群节点的节点数量较少时,系统在节点启动、大数据分片等无关步骤上,花费大量时间,执行写入/读取程序的时间占比不大,导致并行加速比较低,而节点数量增多时,并行操作的分布式优势显现出来,并行加速比随之增加。执行大数据读取程序时,设计系统平均加速比为2.3,常用系统1和常用系统2的并行加速比,分别为1.9和1.6,相比两组常用系统,设计系统并行加速比分别提高了0.4和0.7;执行大数据写入程序时,设计系统平均加速比为2.4,常用系统1和常用系统2的并行加速比,分别为2.2和1.7,设计系统并行加速比分别提高了0.2和0.7,设计系统并发性要优于两组常用系统。
2.2.3 系统可扩展比实验结果
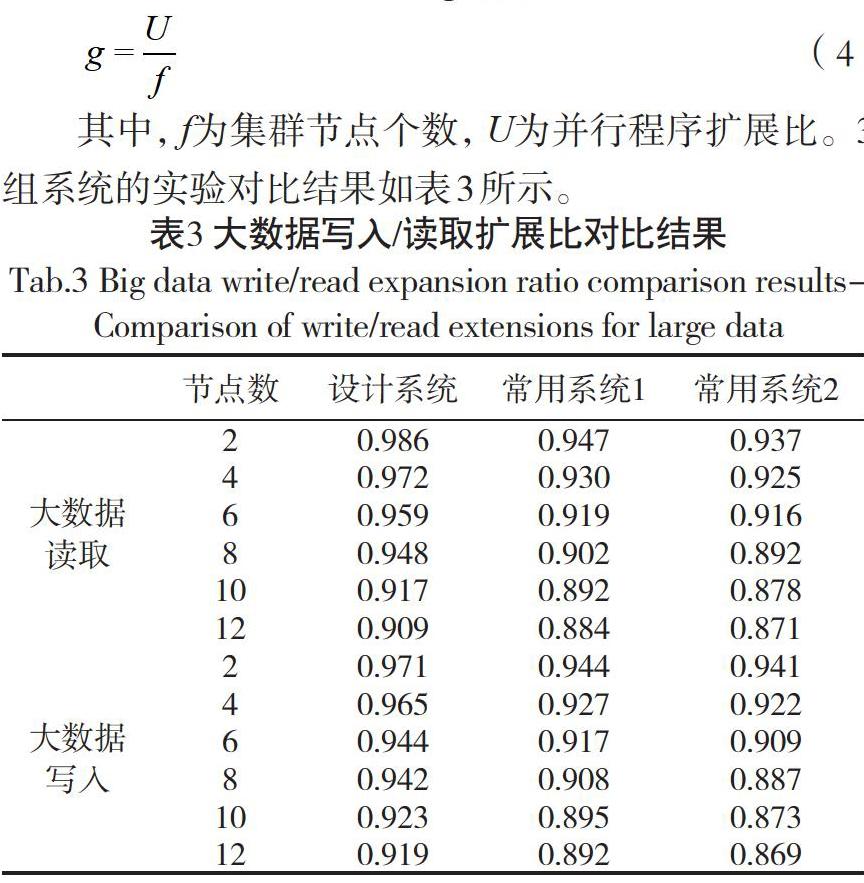
使用扩展比,衡量3组系统执行大数据写入/读取程序的可扩展性,扩展比越接近1,表示程序在该状态下的可扩展性越强。扩展比g计算公式为:
其中,f为集群节点个数,U为并行程序扩展比。3组系统的实验对比结果如表3所示。
由表3可知,当集群节点个数增加时,程序扩展比随之减小,设计系统执行大数据写入/读取程序的平均扩展比,分别为0.949和0.944,常用系统1执行写入/读取程序的平均扩展比,分别为0.912和0.914,常用系统2分别为0.903和0.900,相比两组常用系统,设计系统扩展比更接近1,执行大数据程序时,具有更好的可扩展性。
3 结语
此次设计系统充分发挥了大数据技术优势,提高了系统执行效率、并发性、可扩展性,为精细化社会治理提供数据支持。但此次设计系统仍存在一定不足,在今后的研究中,会为存储器配置更高速率的时钟,对社会治理相关大数据进行时序约束,进一步优化大数据存储速度。
参考文献
[1]刘子逸.大数据背景下的智慧城市管理系统的构建研究[J].智能城市,2021,7(02):51-52.
[2]沈志宏,趙子豪,王华进,等.PandaDB:一种异构数据智能融合管理系统[J].软件学报,2021,32(03):763-780.
[3]蒋宇.基于区块链的安全可信分布式大数据管理系统[J].中国新通信,2021,23(06):152-154.
[4]崔斌,高军,童咏昕,等.新型数据管理系统研究进展与趋势[J].软件学报,2019,30(01):164-193.
[5]许鑫,时雷,何龙,等.基于NoSQL数据库的农田物联网云存储系统设计与实现[J].农业工程学报,2019,35(01):172-179.
[6]郑美光,杨姣,常成龙,等.非结构化云数据管理系统不稳定数据分区识别算法[J].华南理工大学学报(自然科学版),2019,47(08):105-112.
[7]赵子豪,沈志宏.一种适合多元异构图数据管理系统的交互分析框架[J].数据分析与知识发现,2019,3(10):37-46.
[8]唐永军.分布式大数据管理系统的设计与实现研究[J].科技创新导报,2019,16(33):152+154.
[9]吴勇,陈慧,朱卫东.基于大数据分析技术的管理会计系统重构[J].财会月刊,2019(07):61-68.
[10]刘兴宇,孙永明,吴在军,等.基于物联网的广域网数据管理系统的研究[J].电子测量技术,2020,43(04):106-110.
[11]张学谋,王可豪,田大雕.基于Android平台的数据管理系统的实现[J].信息与电脑(理论版),2020,32(11):149-152.
[12]黄正鹏,王力,张明富.基于云计算的海量大数据智能清洗系统设计[J].现代电子技术,2020,43(03):116-120.
[13]万珊,苟文博.基于改进K-means聚类的数据自动采集系统设计[J].自动化与仪器仪表,2020(10):108-112.
[14]黄正鹏,王力,张明富.基于云计算的海量大数据智能清洗系统设计[J].现代电子技术,2020,43(03):116-120.
[15]金巨波.基于K-mean聚类算法的海量数据分析方法[J].九江学院学报(自然科学版),2020,35(04):53-55.
猜你喜欢
桂海论丛(2016年4期)2016-12-09
行政与法(2016年11期)2016-12-07
新教育时代·教师版(2016年27期)2016-12-06
法制与社会(2016年30期)2016-11-24
中国集体经济(2016年27期)2016-11-19
企业导报(2016年20期)2016-11-05
商(2016年27期)2016-10-17
企业导报(2016年14期)2016-07-18
