
基于改进的CBOW与BI-LSTM-ATT的文本分类研究∗
2021-08-08 11:08潘俊辉王浩畅
计算机与数字工程 2021年7期
王 辉 潘俊辉 王浩畅 张 强 张 岩
(东北石油大学计算机与信息技术学院 大庆163318)
1 引言
文本分类是使用特定程序对给定的文本,按一定的分类标准进行自动分类的过程,其目的是将未知类别的文本归类到一个或多个类别[1]。
近年来,鉴于深度学习技术在语音识别、计算机视觉、自然语言处理及生物信息学等众多领域的迅猛发展和优秀表现,相比于传统的机器学习方法,基于深度学习的分类技术逐渐占据了文本分类技术的主导地位[2]。2006年,Hinton等提出深度信念网(Deep Belief Networks,DBNs)的快速学习算法[3];同年,Bengio等提出了神经网络模型,探讨和对比了RBMs和auto-encoders[4]。2014年,Bahdan⁃au等提出把重点放在比较重要的特征信息上的注意力机制,成为了深度学习领域的研究热点[5]。然而,现有的方法通常忽略了特征词的上下文信息,以及特征词所处位置不同对分类能力的影响。鉴于此,本文提出一种改进的加权CBOW与BI-LASM-ATT模型应用于文本分类研究。首先,对特征词频次与反频次进行改进,加强评估特征词的重要程度;其次,为反映当前词对全文信息的重要程度,以及词位置对分类能力的影响,提出一种加权CBOW模型;最后,将生成的向量表示作为基于注意机制的双向LASM模型的输入,得到Softmax分类器分类结果。
2 相关工作
2.1 深度学习文本分类
基于深度学习的文本分类,借助深度网络的特征抽取能力,实现了端到端一步到位的特征提取,免去了人工特征提取过程,主要由以下几个步骤组成。
1)文本预处理。除了传统机器学习文本预处理的基本方法外,深度学习文本预处理重点在文本的向量表示。最常用的方法是独热编码(One-hot Embedding)表示法,其原理是把每个词占n维向量中的一维,标记为1,其他全部标记为0。鉴于独热编码的稀疏编码方式,产生了大量冗余数据,Miko⁃lov等学者于2013年提出了word2vec来解决这个问题[6]。
2)文本分类模型构建。2014年,Kim提出的Text-CNN(Text Convolotional Neural Network)在文本分类中取得了不错效果[7];2015年,Lipton提出的RNN(Recurrent Neural Network)能够更好表达上下文信息[8];近年来,长短期记忆网络(Long Short Term Memory networks,LSTM)利用能够学习长距离文本依赖的特点,成为深度学习的研究热点[9]。
2.2 注意机制
注意力机制模仿了生物观察行为的内部过程,即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制[10]。谢瑜等提出的空间注意机制下的自适应目标跟踪,解决了多种复杂环境的跟踪失败问题[11];马书磊等提出的全局注意机制图像描述方法,解决了图像描述方法全局信息缺失问题,能够生成更准确的文本内容[12]。
3 基于改进的CBOW与BI-LSTMATT文本分类模型
本文构建了基于改进的加权CBOW与BI-LSTM-ATT文本分类模型,结构如图1所示。

图1 基于改进的加权CBOW与BI-LSTM-ATT文本分类网络结构图
3.1 改进的加权CBOW模型
训练前,将语料库中的所有n个单词进行独热编码为w(i)∈Rn。CBOW模型根据上下文预测目标单词,最后使用模型的部分参数作为词向量。CBOW模型分为三层:第一层为输入层(INPUT),窗口为c,假设c取2,选取目标单词w(i)上下文中的2c个词向量(w(i-2),w(i-1),w(i+1),w(i+2))作为输入context(w)1,context(w)2,…,context(w)2c。第二层为投影层(PROJECTION),将输入层的向量累加求和第三层为输出层(OUT⁃PUT),对应一颗二叉树,以语料中出现过的词为叶子节点,以每个词在语料中出现次数为权值构造出来的哈弗曼树[13]。
为了得到预测w(i),在CBOW模型第一层提前设定窗口大小为c,因此词预测结果w(i)主要受指定窗口的2c个上下文相关词向量影响,失去了与全部文本信息的关联影响。为反映当前词对全文信息的重要程度,以及词位置对分类能力的影响,提出一种加权CBOW模型,即TFIDF-CBOW模型,如式(1)所示。

TFIDF(Term Frequency-Inverse Document Fre⁃quency),一种用于信息检索、数据挖掘的常用加权技术。以词出现的频率为特征选择依据,综合考虑了频次和反文本频次,主要用来评估特征项的重要程度。传统的TFIDF公式如下所示:表示特征词在文本中出现频次;表示特征词重要程度的度量。其中,ni,j是特征词ti在文本中出现过的次数,∑knk,j是文本中出现过的特征总数,N表示文档的总数,N(ti)表示包含词ti的文档总数。

在TF公式的实际应用中,忽略了出现在标题和文本中的特征词分类能力是有明显区别的,两者权重明显不同,出现在标题中的特征词能够更清晰的说明文本类别,因此其具备更好的分类能力。将特征词ti出现在标题位置的频次记为ftitle(ni,j),权重记为α;文本中出现的频次记为fbody(ni,j),权重记为β。为体现标题特征词重要性,α应大于β权重数值,通过调整α和β数值,可得到不同位置权重对分类效果的影响,改进的TF公式如下:
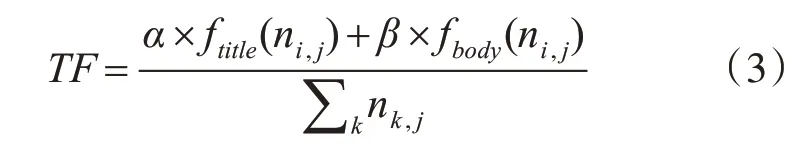
在IDF公式的实际应用中,忽略了特征词对文本全局信息的影响。若某个特征词在某类别文本中出现频数比较大,在另一类文本中出现频数比较小,这样的特征词是具备更好分类能力的。我们将特征词ti出现在类别cm中文本的频次记为numm,其余类别中的频次记为num,影响因子定义为,改进的IDF公式如式(4)所示。若numm数值较大,num较小,则影响因子γ数值偏大,说明特征词ti具备比较好的分类能力。

因此,改进的TFIDF公式如下:

加权TFIDF-CBOW模型得到的词向量表示为

3.2 基于注意机制的BI-LSTM分类模型
LSTM由Hochreiter与Schmidhuber于1997年提出[14]。它是RNN的一种优化,解决了长序列学习的梯度消失问题[15]。本文介绍的是文献[16]BI-LSTM-ATT分类模型,如图2。
模型在传统LSTM基础上增加了注意机制。单词向量xij表示第j个单词向量在第i个文本中,使用双向LSTM模型对文本注释得到模型中的注意机制计算出每个元素的概率权重αit,抽取对文本重要的词向量构成最终特征向量,相关公式如式(7)。


其中,W是权重矩阵,将输入的hit进行线性转换,uw是词水平的上下文矢量,C是第i个文本的文本向量。图2中的Y表示经word2vec映射后的向量,H表示经标准LSTM训练学习得到的向量。C和H两种向量在分类中的权重参考文献[16]分别设定为0.4和0.6,则文本属于某一类的概率计算公式如式(8)。
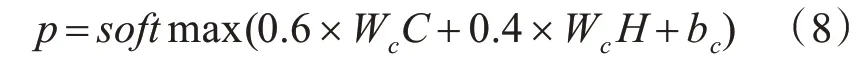

图2 基于注意机制的BI-LSTM分类模型
4 实验
4.1 数据集
实验数据采用的是复旦大学提供的文本分类语料集,在20个类别中选取了十个类别进行实验,分别为计算机、军事、医学、艺术、历史、体育、农业、经济、政治、教育。从中随机选取训练集5000条数据,测试集3000条数据。
4.2 评价指标
本文采用文本分类问题常用的几个性能评价指标,主要有精确率召 回 率x代表分类正确的文本数,y代表实际分类的文本数,z代表应有的文本数。F_meature作为标准测度,综合考虑了Precision和Recall的影响。
4.3 实验结果对比与分析
实验将本文提出的方法与传统机器学习方法以及深度学习方法进行对比,包括SVM、Text-CNN、RNN、LSTM、Bi-LSTM。表1显示了不同算法分类准确率。从表1可知,本文算法在很大程度上提高了文本分类准确度,在对不同类型数据集的分类效果上均优于现有算法,比传统机器学习分类算法准确率提高了一倍,比深度学习分类算法准确率提高了约10个百分点。传统机器学习分类算法SVM忽略了特征词之间的联系,对所有类别的分类均没有达到40%以上,分类效果最差。Text-CNN、RNN和LSTM分类效果明显优于SVM,但次于本文提出的算法,主要原因在于这三种算法均忽略了特征词文本的上下文关系。Bi-LSTM考虑了文本的上下文,分类效果明显提升,但由于梯度下降等原因,仍不能完美发挥分类作用。实验表明,本文提出的基于改进的CBOW与Bi-LSTMATT文本分类模型,可以有效提高文本分类效果。

表1 不同算法的分类准确率对比
5 结语
本文提出了一种基于改进的加权CBOW与BI-LSTM-ATT文本分类模型,应用于复旦大学提供的语料集分类。实验表明,本文提出的方法在精确率、召回率、F_meature效果对比中,比传统机器学习和深度学习算法均有明显提高,整体准确率也是最佳的。在未来的工作中,将进一步研究特征词选取方法和耗时的改进,考虑如何利用注意机制更有效地关注到关键信息,以及尝试更多领域语料集的实验结果对比。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
现代计算机(2021年33期)2022-01-21
少儿画王(3-6岁)(2020年4期)2020-09-13
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
东方教育(2018年20期)2018-08-22
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
微型计算机(2009年4期)2009-12-23
教学与管理(理论版)(2009年9期)2009-11-04
