
结合CNN和Catboost算法的恶意安卓应用检测模型
2021-08-06 08:23林华智黄剑锋林志毅
计算机工程与应用 2021年15期
苏 庆,林华智,黄剑锋,林志毅
广东工业大学 计算机学院,广州 510006
2018 年间,360 互联网安全中心记录了大约1.1 亿次恶意安卓应用程序感染[1],说明网络安全态势存在严重威胁,也使得恶意安卓应用检测成为网络安全的研究热点之一。恶意安卓软件检测技术可分为静态分析技术和动态分析技术两大类[2]。其中动态分析技术是利用沙盒、虚拟机来仿真应用的执行过程,通过实时监控应用执行过程中所产生的行为来判断其是否为恶意软件,此方法必须在程序运行时才能实施检测,耗费资源和时间多。静态分析法不执行程序文件,而是先对程序进行反编译,然后提取特征值进行分析和研究,是一类较为简便的安卓恶意应用判定方法。
近年来,越来越多学者将机器学习或者深度学习方法应用于恶意安卓应用检测。Zhu等人[3]提出通过提取权限、敏感的API 监控系统事件和许可率等关键特性,采用整体旋转森林(rotation forest)构建一个经济有效的安卓应用检测模型,其检测效果优于支持向量机模型,但所选取的特征较少,检测准确率不高。Wang 等人[4]通过提取权限、硬件功能和接收者动作等122 个特征,使用多种机器学习分类器进行训练和测试,并使用随机森林分类器(random forest)获得较高的分类准确率,但由于未提取系统调用函数特征,导致误报率比一般防病毒程序高。Suman 等人[5]提出通过提取权限和API 等特征,使用逻辑回归(logistic regression)构建分类模型,并且通过删除低方差特征来优化特征,获得较好的分类效果。Wang等人[6]提取了权限、intent、API和硬件特性等11类共3万多个特征,然后使用支持向量机(SVM)根据特征对检测的重要性对特征进行排序,并集成5种机器学习分类器进行分类,实验结果表明该集成方法优于单一机器学习模型,然而该方法需要提取的特征较多,特征维度较大,检测效率相对较低。Karbab等人[7]提取应用程序API 作为特征,使用卷积神经网络(CNN)来进行检测,实验表明该方法在多个数据集检测中具有较高的准确性。Wang 等人[8]提出基于深度置信网络(DBN)的恶意安卓应用检测方法,通过提取安卓应用的权限和API 函数作为特征,采用DBN 进行训练和测试,从而减少学习过程中的人工干预。Wang 等人[9]将卷积神经网络(CNN)与深度自编码网络(DAE)结合构建CNN-DAE 检测模型,提取了API、权限、硬件特性等多种特征来进行训练,该方法相比机器学习方法提高了检测精度,也相比CNN 减少了训练时间。总体而言,深度网络检测方法的检测效率较低,需要较大的样本量。
针对上述文献中存在的安卓恶意检测中存在的效率低、特征维度过大和样本量不足等问题,本文提出一个结合卷积神经网络(CNN)和Catboost 算法的混合检测模型,同时具备了CNN 的局部感知和降维后特征保持不变性的能力,以及Catboost算法对样本量和特征要求不高,不易过拟合的优点。卷积神经网络的特征提取功能可以增强信号和降低向量维度,可以较好地解决特征筛选和特征维度过大的问题,提高检测效率;运用鲁棒性高和对样本数量要求不高的Catboost 模型作为分类层进行分类,可以解决样本量不足而影响分类精度的问题。另外,使用遗传算法对Catboost进行快速的参数优化,进一步提高检测精确度和效率。
1 相关技术介绍
1.1 CNN神经网络模型
卷积神经卷网络(CNN)是一类包含卷积计算且具有深度结构的前馈神经网络[10],主要包括以下两层。
1.1.1 卷积层
卷积层的功能是使用卷积核对输入数据进行特征提取,有规律地扫过输入特征,在感受野内对输入特征做矩阵元素乘法求和并叠加偏差量:

1.1.2 池化层
池化层是对输入的对象进行抽象和降维,具有保持特征不变性和防过拟合作用。Lp池化是比较常用的一种池化方法,其一般表示形式为:

其中,p是预指定参数,当p=0 时,Lp池化在池化区域内取均值,被称为均值池化;当p→∞时,Lp池化在区域内取极大值,被称为极大池化[11]。
1.2 Catboost模型
Catboost 是一个基于梯度提升决策树的机器学习框架,它将所有样品的二进制特征存储于连续向量B又红又专中,叶子节点的值存储在大小为2d的浮点数向量中。对于样本x,建立一个二进制向量A:

其中,B(x,f)从向量B读取的样本x上的二进制特征f的值,而f(t,j)从深度i上的第t棵树中的二进制特征的数目。向量以数据并行的方式构建,可以实现高达3倍的加速[12]。
1.3 遗传算法
遗传算法(Genetic Algorithm,GA)是一种通过模拟自然进化过程搜索最优解的方法[13],具有内在的隐并行性和更好的全局寻优能力,其基本流程如图1所示。

图1 遗传算法基本流程Fig.1 Workflow of genetic algorithm
2 模型设计与实现
2.1 CNN-catboost模型的网络结构
本文提出的CNN-catboost混合分类模型,继承了卷积神经网络提取局部特征能力强和降维后保留有效信息效果较好的优势,以及catboost 模型无需广泛数据训练就可以产生较好分类效果的特点,并利用遗传算法的全局寻优调参能力缩减调参用时。其模型结构如图2所示。
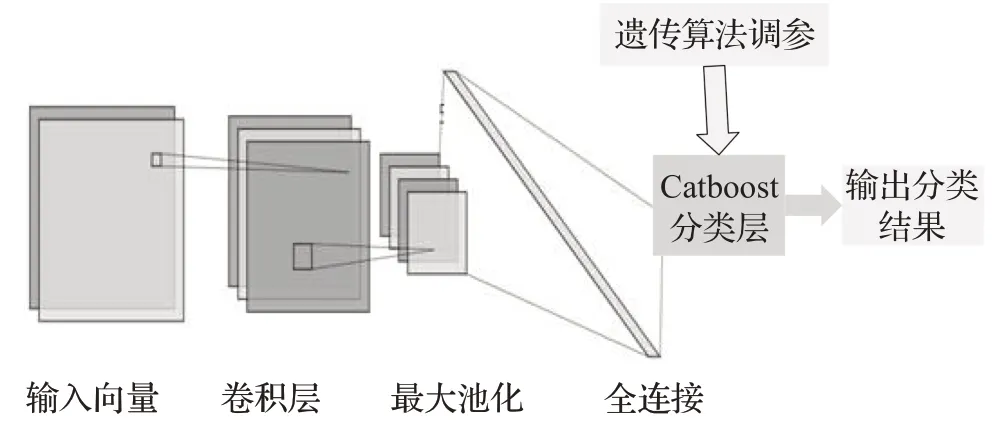
图2 CNN-catboost模型结构图Fig.2 Structure of CNN-catboost model
在CNN-catboost 模型中,首先输入层输入特征向量,卷积层对输入的特征向量进行提取和局部感知,利用卷积运算增强原始信号特征;然后再利用池化层对提取整合的特征进行下采样,在减少数据处理量的同时保留有用信息,减少冗余信息,特征维度降低,能促进最后一层分类模型的快速收敛,从而降低模型的训练时间,有效提高分类模型的泛化能力;另外,通过使用遗传算法对Catboost进行参数优化以进一步提高Catboost模型的分类准确率;最后在Catboost层对特征向量进行训练和测试。
安卓应用的特征种类和数量较多,特征的选择和处理是构建泛化性强的安卓恶意应用检测模型的难点。将Catboost应用于安卓恶意应用检测时,需要人工进行特征选择和过滤,其结果对Catboost的最终分类效果有重要影响。而CNN 模型具有自动学习特性,可以通过卷积层和池化层进行自动地特征优化,无需进行人工构造和过滤特征,可有效弥补Catboost在特征处理方面的不足。但是,将CNN应用于分类时,存在对数据量要求高、学习过程长,训练速度慢的缺陷,而Catboost的优势在于不易过拟合,训练速度快,无需大量数据进行训练即可获得高准确率的分类结果,正好可以改进CNN 模型的上述问题。
Catboost 的参数选取会影响其分类结果的准确性,而且最优化的参数有助于巩固其鲁棒性。而遗传算法以多点和并行搜索寻找全局最优解,在快速确定最优参数群的同时避免陷入局部最优解。因此应用遗传算法对Catboost 进行调参,借助其良好的全局搜索能力,以较少的资源消耗和时间确定最优化参数,加快Catboost的收敛速度。
综上所述,本文结合CNN、Catboost 和遗传算法的各自优势,利用CNN 中卷积层和池化层自动提取和选择特征,自动抽取安卓应用的本质特征,将其作为Catboost 模型的输入向量,并使用遗传算法快速确定Catboost模型的最优化参数,构造一个既避免人工选择过滤特征,又无需较多的数据样本就可以快速生成较好的检测效果的模型。
2.2 特征提取
CNN-catboost模型的第一步是输入特征向量,因此需要特征提取。本文首先使用androguard 工具提取到安卓应用的权限、API类包、四大组件、intent特征和硬件特性等各种静态特征;然后使用apktool 工具将APK 文件解码得到smali文件,进而提取OpCode特征[14]。
(1)权限特征:在一般情况下,安卓恶意应用申请的敏感权限比正常应用多,正常应用所申请的权限总量比恶意的多。本文选取了Android6.0 版本的25 个敏感权限和33个正常权限作为权限特征。
(2)API 特征:Android 应用的相关功能需要通过API调用来实现[15]。由于安卓API函数数量众多且每个API 函数敏感高低难以统计,本文选取了Android SDK所提供的150个安卓API类作为特征。
(3)组件数目:Android系统中的4种实用组件分别是Activity、Service、BroadcastReceiver 和ContentProvider。有些恶意家族应用为了保持恶意家族特性,会在同族软件中使用相同的服务名,所以本文提取这四种组件的数目作为特征。
(4)intent 特征:Intent-Filter 动作action 用于描述意图要执行的行为[16]。比如DIAL拨打电话不需要打电话的权限,恶意应用在用户不知情的情况下可以越权拨打电话,因此本文选取了恶意应用最常用的10个action来作为特征。
(5)硬件特征:uses_feature 描述了安卓应用所需要硬件特性,例如某恶意应用会申请GPS来窃取用户定位数据,所以本文提取用户最常使用的27 个硬件特性作为特征。
(6)OpCode特征:同族恶意应用变种往往具有高度相似的代码逻辑,并且可以由操作符序列进行表征。通过反编译APK得到smali文件中包含的Dalivk指令[17],从中抽取反映程序语义的七大类核心指令集合V、T、M、G、I、R、P,并去掉操作数,形成OpCode特征,如表1所示。

表1 OpCode特征核心指令集Table 1 Core instruction set of OpCode feature
2.3 特征预处理
对于安卓权限特征,将选取的25 个敏感权限和33个正常权限依次排列组成一个特征向量,排列方式如图3所示。若某一位取0则表示该权限在APK中未出现,取1则反之。

图3 安卓权限排列示意图Fig.3 Schematic diagram of Android permission arrangement
与敏感行为相关的安卓API 函数大部分集中于content、location和net等10 个类包中。首先将140个普通API 类包按照Android 官方API 文档的顺序排列在前,再将10 个敏感类包排在后,构成一个API 类包特征向量。一个API 类包在该APK 中出现的次数为该状态的取值,如图4所示。

图4 API类包排列示意图Fig.4 Schematic diagram of API packages arrangement
对于Activity、Service、BroadcastReceiver 和Content Provider 这4 种组件,取每种组件的数量为特征;intent特征中的动作所出现的次数即该向量值。
对于27个硬件特性特征,特性相关联的排列相邻,如Camera/camera.Flash/camera.front这几个排列在相邻,某特性若是被引用,则对应特征值为1,否则为0。
对于提取到的OpCode特征,建立一个2-Gram模型,模型中每个子集出现的次数则为特征向量的该状态值。
将以上6 类共298 个特征映射到向量空间,形成一个安卓应用的特征向量,如表2所示。

表2 特征向量表示Table 2 Representation of feature vectors
2.4 模型的训练过程
CNN-catboost 混合模型的训练过程主要分为特征处理、分类与调参两个过程,如图5所示。

图5 CNN-catboost模型训练过程Fig.5 Training procedure of CNN-catboost model
在特征处理过程中,由于特征向量中相似特性的特征相邻,值为0的元素较多,导致训练模型的时间较长,因此设置一个卷积层来聚合特征。因为特征向量为一维,所以卷积核的尺寸可以为1×2或者1×3,并且将卷积核的值都设为整数。特征向量经过卷积层处理后输入到池化层,池化层为最大池化,池化窗口大小为1×2,步长为2,特征向量经过下采样后,其维度会至少降低为输入向量的一半。
在分类与调参过程中,首先将经过处理的特征向量作为Catboost分类层的输入向量,使用默认参数进行训练;然后运用遗传算法对Catboost 分类层进行调参,首先随机初始化种群,使用二进制编码将待优化参数转换为染色体;然后计算模型的AUC值作为个体适应值,来评定各个体的优劣程度;然后采用轮盘赌法选择出适应性强的个体,并对染色体进行单点交叉和基本位变异,保留其优秀基因和产生有实质性差异的新品种;最后更新种群,再次计算适应度。重复上述步骤直至找到最优参数。调参结束后再使用最优参数值对特征向量进行训练,最后输出分类结果。
3 实验结果与分析
本实验方案设计思路如下:首先将应用遗传算法进行调参,得到最优参数;然后在相同样本量和特征维度的前提下,保持卷积层和池化层相同,在分类层分别选取Catboost 算法和其他5 种机器学习算法与CNN 进行适配,共构成6种CNN+机器学习算法混合模型,继而对比这6 种混合模型在分类准确度方面的效果;之后将CNN-catboost 模型与其他10 种较有代表性的和新出现的模型进行比较;然后将CNN-catboost与单一机器学习模型、其他混合模型以及单一深度学习模型的训练时间进行比较讨论;紧接着将CNN-catboost与单一机器学习模型、其他混合模型以及单一深度学习模型在检测耗时和资源利用率方面进行比较和讨论;最后在未知类型的安卓应用数据集上检测各模型的分类性能。
3.1 实验环境、数据集选取和评估指标
在实验中,物理主机为8 GB 内存,处理器为Intel Core i7-8750H,操作系统为64位Windows 10。
实验所采集的数据样本源自加拿大网络安全研究所(https://www.unb.ca/cic/datasets/android-adware.html)和VirusShare 网站(https://virusshare.com/),共有3 861个,其中良性样本包括杀毒软件、浏览器、通信软件、生活常用软件及管理类软件等多种良性应用,共1 690个;恶意样本包括2012年至2017年的广告软件、勒索软件、恐吓软件、短信恶意软件及僵尸网络软件等多个家族的恶意应用,共2 171个。
本文使用准确率(Accuracy)、精确率(Precision)、召回率(Recall),F1 值、AUC 值和检测耗时这几个标准进行作为实验结果判定指标,具体定义如下:

将恶意软件视为负例,良性软件视为正例,其中TP:预测为正,判断正确;FP:预测为正,判断错误;TN:预测为负,判断正确;FN:预测为负,判断错误。AUC被定义为ROC曲线(接收者操作特征)与横坐标所组成的面积,可以直观地评价分类器的性能,其值越大代表模型分类能力越好。
3.2 基于遗传算法的参数值优化实验
分类模型的参数值会直接影响到分类的准确性和效率。由于Catboost减少了对广泛超参数调优的需求,所以主要选取对模型影响比较大的4个参数进行讨论:最大树数iterations、学习率learning_rate、树深depth 和数值特征分割数border_count。其他参数设置为默认值。根据遗传算法的特点,结合常用的参数经验来初始化遗传算法参数[13],设置初始群体大小为50,交叉概率为0.6,变异概率为0.01,以此产生新的基因,同时避免陷入单纯的随机搜索。
在Catboost 算法的默认参数中,最大树为1 000,学习率为0.1,树深为6,数值分割数为256;而本文运用遗传算法的参数值进行优化尝试,得到以下最优参数:最大树为180,学习率为0.242,树深为8,数值分割数为250。分别将上述两种参数进行检验,结果如图6所示。可以发现,最优参数在各项分类评估指标中都优于默认参数。

图6 最优参数与默认参数对比Fig.6 Comparison between optimal parameters and default parameters
3.3 CNN-catboost与其他CNN+机器学习模型对比实验
在保持卷积层和池化层相同的前提下,将CNNcatboost 模型与其他5 种CNN+机器学习算法混合模型进行比。表3 列出了各混合模型中机器学习算法的重要参数。

表3 混合模型中机器学习算法的主要参数Table 3 Dominating parameters of machine learning algorithm in hybrid model
实验结果如表4所示,可以发现CNN-catboost模型比其他CNN+机器学习算法具有更优的分类准确度。

表4 CNN-catboost与其他CNN+机器学习模型实验对比Table 4 Comparison between CNN-catboost and other CNN+machine learning models
以AUC值为评估指标,将CNN-catboost与catboost、CNN-xgboost 与xgboost、CNN-decisiontree 与decision tree、CNN-randomforest 与random forest、CNN-logisticregression 与logistic regression、CNN-ensemble 与ensemble分别进行对比。其中catboost、xgboost,decision tree、random forest、logistic regression 等算法的参数分别与其相对应的CNN+机器学习算法混合模型中的机器学习算法的参数一致。在图7 中,CNN-catboost 与catboost 简化表述为CNN-/catboost,其余类似。由图7可发现,CNN+机器学习分类器混合模型的分类效果比单一机器学习分类器要好,而CNN-catboost 模型的AUC值最高,显示该模型具有较好的性能。

图7 CNN+机器学习与单一机器学习实验AUC值对比Fig.7 Comparison of experimental AUC values between CNN+machine learning and single one
3.4 CNN-catboost模型与其他多种模型对比实验
将CNN-catboost模型分别与catboost、xgboost模型、决策树decision tree、多层感知机MLP[18]、random forest模型[4]、logistic regression 模型[5]、ensemble 模型[6]、CNN模型[7]、DBN模型[8]和CNN-DAE模型[9]等分类模型进行比较,实验结果如表5 所示,可知CNN-catboost 的分类效果优于其他模型。至于CNN等神经网络模型的分类效果不够理想,原因在于样本数量不够,造成了过拟合。

表5 CNN-catboost模型与其他模型实验对比Table 5 Comparison between CNN-catboost and other models
3.5 训练时间对比实验
由于decision tree模型、random forest模型[4]、logistic regression 模型[5]、ensemble 模型[6]等机器学习模型复杂度低,所以训练耗时比较小,但他们的分类准确性也比较差,因此在本实验中不列入训练时间比较范围。本文将CNN-catboost模型分别与分类准确率较高的模型,包括混合模型(如CNN-xgboost、CNN-DAE[9]),以及单一机器学习模型(如catboost)和单一深度学习模型(如CNN[7]、MLP[18]和DBN[8])等进行训练时间方面的比较,结果如表6所示。
从表6 看出,CNN-catboost 的训练时间与CNNxgboost 相当,比其他混合模型以及单一机器学习和深度学习模型的训练时间少。经分析,原因如下:一方面,在本文的CNN-catboost模型中,经过卷积层和池化层处理的特征向量,在保留了特征的有效信息的同时,也明显降低了特征维度;另一方面,Catboost 算法对训练次数要求低,分类预测速度较快,而神经网络由于其非线性,梯度噪音等原因导致优化步骤多,导致训练时间较长,因此导致CNN-catboost的训练开销低于混合模型和单一深度学习模型和机器学习模型。

表6 各模型的训练时间Table 6 Training time of each model
3.6 模型检测耗时和资源利用率对比实验
将CNN-catboost模型应用于安卓应用检测,分析其在检测耗时、CPU使用率和内存使用率方面的表现。从3.1 节所述的数据集中选取511 个良性应用和649 个恶意应用(共1 159个)进行实验。继续选取其他分类准确率较高的模型与CNN-catboost进行对比,包括混合模型CNN-xgboost、CNN-DAE[9],单一机器学习模型catboost和单一深度学习模型CNN[7]、MLP[18]和DBN[8]等,结果如表7所示。

表7 检测耗时和资源利用率对比Table 7 Comparison of detection time and resource utilization
由表7 可知,CNN-catboost 的检测时间和内存使用率优于其他模型,CPU 使用率也优于大部分模型,说明将CNN-catboost 应用于安卓应用检测时具有检测耗时短、资源耗费少的优点。
3.7 未知类型应用检测实验
在本次实验中,利用CNN-catboost模型对随机搜集的未知类型的安卓应用进行检测,以检验其在实际应用中的效果。首先从各大安卓应用市场下载1 007个未知类型的安卓APK包,然后上传至VirusTotal(https://www.virustotal.com/)在线查毒网站进行分类检测,检测结果作为本次实验的检测基准。VirusTotal 网站对此1 007个样本进行检测的结果为:良性样本751 个,恶意样本256 个。继续使用3.6 节中提及的其他模型所得的检测结果进行对比,实验结果如表8 所示,其中Recall1 为良性样本召回率,Recall2为恶意样本召回率。

表8 基于未知类型安卓应用数据集的各模型对比Table 8 Comparison of models based on unknown Android app dataset
由表8 可知,在未知类型的应用检测中,相比于其他模型,CNN-catboost 可较好地区分良性和恶意应用,误判率比较低,切合对各种安卓应用进行安全检测的实际需求。
4 结语
本文提出一种有效地将卷积神经网络特征提取和降维能力以及catboost模型鲁棒性强的分类能力结合的混合模型CNN-catboost,该模型不仅兼具卷积神经网络可以增强特征信号,减少冗余信息的优点,同时还融合了catboost模型的低数据量要求即可获得较好分类结果的优势,通过运用遗传算法进行调参进一步提升catboost 模型的分类准确率。经过实验验证,该模型在提高了恶意安卓应用检测准确率的同时,也有效地缩短了训练时间,因而具有一定的实践应用价值。
鉴于深度学习方法对安卓恶意软件检测具有良好的发展前景,因此在下一步工作中将继续优化深度学习模型,进一步提高恶意安卓应用检测精度和效率。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
消费电子(2022年6期)2022-08-25
保定学院学报(2022年2期)2022-04-07
少年文艺·开心阅读作文(2019年8期)2019-09-12
许昌学院学报(2018年4期)2018-05-02
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
中华建设(2017年1期)2017-06-07
统计与决策(2017年2期)2017-03-20
信息安全研究(2016年4期)2016-12-01
