
面向容器环境的Flink的任务调度优化研究
2021-08-06 03:22房六一徐浩桐段晓东
计算机工程与科学 2021年7期
黄 山,房六一,徐浩桐,段晓东
(1.大连民族大学计算机科学与工程学院,辽宁 大连 116600;2.大数据应用技术国家民委重点实验室,辽宁 大连 116600;3.大连市民族文化数字技术重点实验室,辽宁 大连 116600)
1 引言
随着互联网技术的飞速发展,万物互联成为未来发展的必然趋势,人类正从计算机时代走向数据技术时代。据国际数据公司IDC(International Data Corporation)预测,2025年全球产生的数据量将达到163 ZB[1]。与此同时,具有高可伸缩性、部署方便、初期成本低、按使用付费、运行维护成本低特点的云计算技术也得到了迅猛发展。大数据管理系统正在向支持可伸缩性和支持批计算、流计算、机器学习等多计算模式相融合方向发展[2]。
Flink[3]作为最新一代的大数据计算引擎,具有低延迟、高吞吐等优势,使其备受学术界和工业界青睐。与此同时,随着虚拟化技术的发展,各种应用都在使用容器化部署。然而,Flink在容器中部署时,由于其不能感知到结点负载情况,会导致任务分配不均匀,造成性能下降。
本文提出一种面向容器环境的Flink任务调度算法FSACE(Flink Shedule Algorithm for Container Environment),该算法在容器环境下部署Flink任务时,结合集群容器负载信息调度任务,从而使任务分配更加均衡,提升了Flink在容器环境下的处理效率。
本文的主要贡献有:
(1)提出一种结合容器部署负载信息的Flink任务调度算法。该算法获取每个结点性能信息与容器在结点上的分布信息,优先选择空闲资源较多的结点的容器,同时可以避免容器被频繁选中造成负载不均。
(2)利用不同规模的数据集进行对比实验,实验表明,本文提出的FSACE算法相比默认的Flink任务调度算法在计算时间、吞吐量、时延和资源利用方面都有优化。
2 相关工作
容器环境下大数据计算平台的任务调度优化算法主要分为以下2类:
(1)优化大数据处理引擎的任务调度算法。文献[4]提出了处理空间数据的批流融合处理架构,可以支持多源空间连接查询。文献[5]研究了批流融合系统中多算子放置问题,使算子能更均衡地分布到集群各结点上,提升效率。文献[6]提出了适用于Nephel[7]数据流平台的响应式资源调度策略,通过建立数学模型计算每个算子的并行度,并通过任务迁移实现集群资源的动态伸缩,但是在其任务迁移过程中,网络传输开销较大。文献[8]通过监控集群性能指标,建立了针对Strom[9]平台无状态数据流的弹性资源调度策略。文献[10]提出分布式弹性资源管理协议,实现了集群规模对输入负载的快速响应。文献[11]通过实现上下游结点算子的灵活迁移和动态链接,应对内存不足造成的背压[12]问题。文献[13]提出了自定义代价模型,在邻近代价阈值[14]时启动分区映射算法[15],实现结点间计算负载的最优分配。文献[16]将流式计算拓扑定义为流网络模型[17]并从中寻找优化路径,从而提高集群吞吐量。此外,文献[18-21]也分别提出了不同的负载均衡策略,以提升集群性能。这些算法由于没有考虑容器部署情况对于Flink资源调度的影响,造成任务分配不均匀,进而拖慢任务执行速度。
(2)基于结点性能信息的容器优化调度算法。文献[22]提出了基于负载预测的扩容策略和综合考虑状态因素、资源因素的优化策略,可以减少应用请求响应时间,减少结点资源碎片化,提升集群服务质量。文献[23]提出一种动态缩容算法,在缩容过程中根据某一服务在不同结点上分布的Pod(Kubernetes创建或部署的最小基本单位)[24]实际资源使用情况,计算出该结点删除Pod后的CPU内存资源均衡度,最后选择删除资源均衡度最小的结点,可以使集群具有更好的资源均衡度。这些研究工作考虑了容器情况的影响,但调度的基本单位为容器,调度粒度较粗,无法根据Flink任务具体情况进行资源调度。
综上,现有研究工作一部分没有考虑容器情况对于Flink任务调度的影响,一部分无法适应Flink资源调度。针对这一问题,本文提出了面向容器的Flink任务调度算法FSACE,算法通过获取容器的性能信息,优化Flink的任务调度,有效地改善了容器环境下Flink负载不均的问题,提高了计算效率。
3 研究技术背景介绍
本节主要介绍FSACE算法相关的技术背景,主要包括3个方面,分别是Flink大数据计算平台、容器技术[25]和Flink容器环境下部署方式。
3.1 Flink大数据计算平台
Apache Flink是一个批流融合分布式处理框架,其功能十分强大,不仅可以运行在包括YARN[26]、Mesos[27]和Kubernetes[28]在内的多种资源管理框架上,还支持在裸机集群上独立部署。Flink可以扩展到数千核心的集群中,其数据可以达到TB级别且仍能保持高吞吐、低延迟特性。
3.1.1 Flink编程模型
Flink的组件分为4层,各个模块之间的层次关系如图1所示。
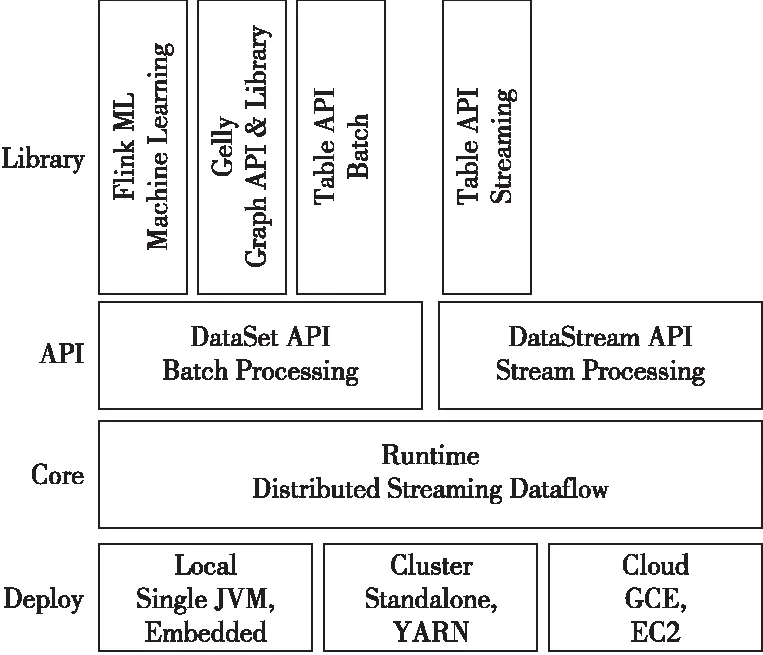
Figure 1 Flink programming model图1 Flink编程模型
图1中底层是Deploy层,Flink支持多种部署方式,例如本地(Local)单机版、Standalone集群部署、YARN集群部署和Kubernetes等云(Cloud)部署方式。
第2层是Core层,这一层是Flink分布式数据处理的核心实现层,包括计算图的所有底层实现。
第3层是API层,该层包括了流处理(DataStream)API和批处理(DataSet)API,Flink的批处理是建立在流处理架构之上的,因此Flink更适合流处理场景。
最上层是Library层,本层是Flink应用架构层,构建在DataStream API和DataSet API之上。
3.1.2 Flink算子转换
Flink中的执行图可以分成4层:StreamGraph、JobGraph、ExecutionGraph和PhysicalGraph。这4层执行图表示了从程序最初的拓扑结构到可执行Task的变化过程。
(1)StreamGraph:是根据用户通过Stream API编写的代码生成的最初的图,用来表示程序的拓扑结构。
(2)JobGraph:StreamGraph经过优化后生成了 JobGraph,为提交给JobManager的数据结构。其中主要的优化为,将多个符合条件的结点链在一起作为一个结点,这样可以减少数据在结点之间流动所需要的序列化、反序列化和传输消耗。
(3)ExecutionGraph:JobManager根据JobGraph生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最为核心的数据结构。
(4)PhysicalGraph:JobManager根据Execu- tionGraph对Job进行调度后,在各个TaskMan- ager上部署Task后形成的“图”,是各个Task分布在不同的结点上所形成的物理上的关系表示,并不是一个具体的数据结构。
以并行度为2(其中Source并行度为1)的 SocketTextStreamWordCount为例,4层执行图的演变过程如图2所示。
3.1.3 Flink任务调度
Flink集群启动后,首先会启动一个JobMa- nager 和多个TaskManager。用户的代码会由JobClient提交给JobManager,JobManager再把来自不同用户的任务发给不同的TaskManager执行,每个TaskManager管理着多个Task,Task是执行计算的最小单元,TaskManager将心跳和统计信息汇报给 JobManager。TaskManager之间以流的形式进行数据传输。
上述除了Task外的三者均为独立的JVM(Java Virtual Machine)进程。其中,TaskManager和Job并非一一对应的关系,每个TaskManager最少持有1个slot,slot是Flink执行Job时的最小资源分配单位,在slot中运行着具体的Task任务。
Flink提供了2种基本的任务调度逻辑,即Eager调度和Lazy From Source。Eager调度会在作业启动时申请资源将所有的Task调度运行,更加适用于流作业;而Lazy From Source则是按拓扑顺序来进行调度,更加适用于批作业。2种任务调度均是从各TaskManager中的slot池中依次获取可用的slot进行资源分配。
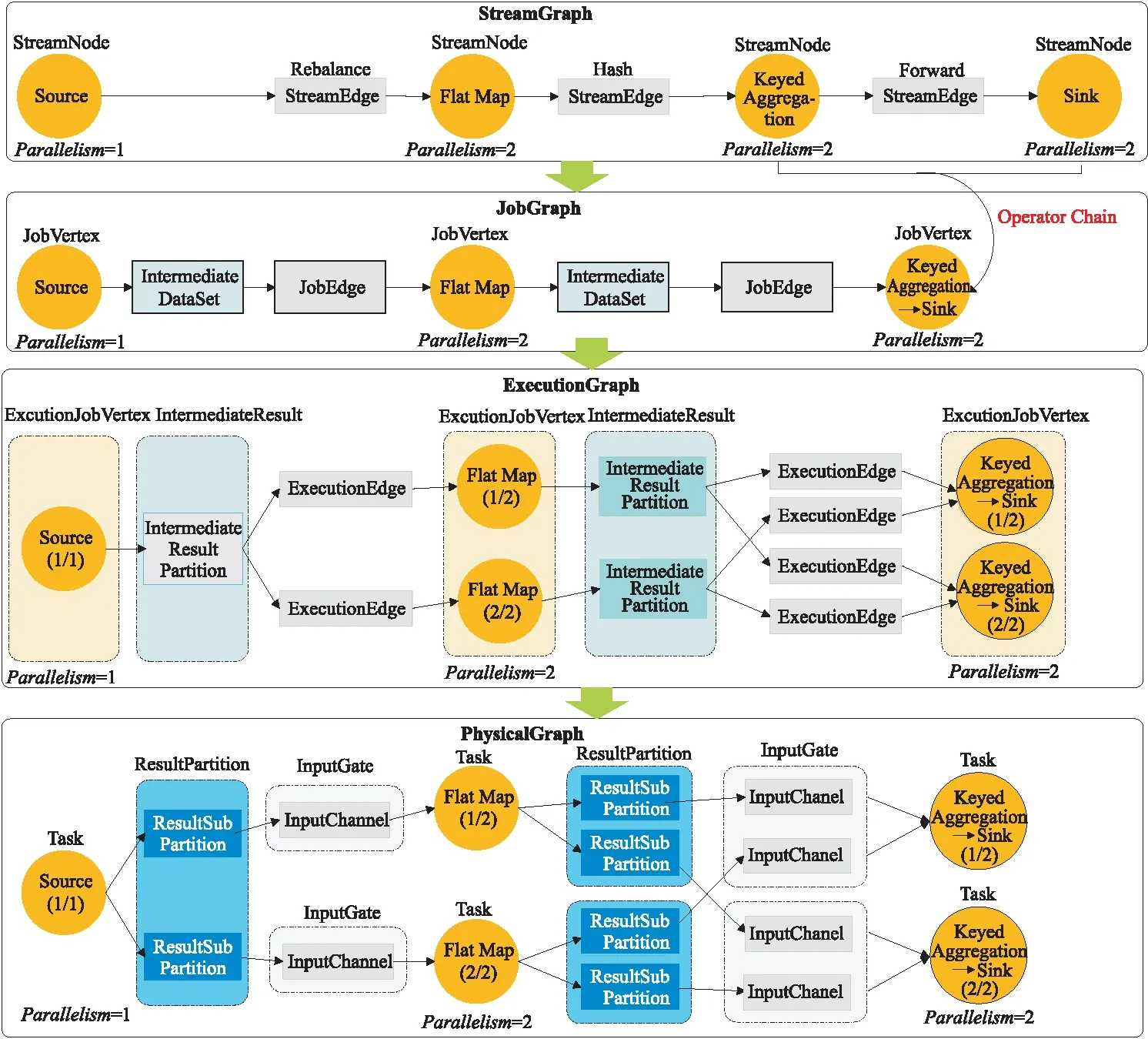
Figure 2 Flink operator conversion 图2 Flink算子转换
3.2 容器技术
容器技术是一种可以有效地将单个操作系统的资源划分到独立的组中,以便更好地在独立的组之间平衡有冲突的资源使用需求的技术。
Docker[29]是基于Go语言的开源容器项目,是C/S架构,主要由客户端和服务器2大核心组件组成,通过镜像仓库来存储镜像。客户端和服务器可以运行在同一台机器中,也可以通过Socket或RESTful API来进行通信。
Kubernetes用于容器编排,具有自动化程度高的优势。Kubernetes可以将各种服务器资源整合到一起,应用的整个生命周期都可以实现自动化管理,用户不用关心具体容器如何部署,并且可以获取容器的相关信息。
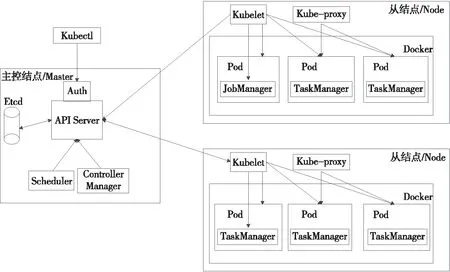
Figure 3 Deployment of Flink in a container environment图3 Flink容器环境下部署
3.3 Flink容器环境下部署方式
将Flink在容器环境下部署的架构如图3所示。
Flink的容器组件主要包括JobManager与TaskManager,其中JobManager容器主要负责任务调度,而TaskManager容器主要负责执行计算任务。
为了监控容器资源性能部署了开源的Metric-Server。在Kubernetes上部署Metric-Server之后,它在每个结点上都会有一个副本,负责收集容器性能信息,并实现Flink应用整个生命周期的自动化管理。
在Kubernetes主结点上的组件主要包括Controller Manager、Scheduler和Etcd。其中 Controller Manager可以用来控制Flink容器副本的数量,Scheduler负责应用的调度,Etcd键值数据库负责持久化存储集群配置。从结点上的组件主要Kubelet和Kube-proxy,负责与API进行通信。
4 任务调度优化算法
本节首先分析Flink容器环境下部署时默认的任务调度算法存在的问题,之后介绍本文提出的Flink任务调度优化算法(FSACE)。
4.1 问题分析
在容器环境下部署Flink大数据处理平台时,由于每个结点上的容器数量不完全相同,容器也并不是都用于Flink部署,因此使用Flink默认的任务调度算法,会将每个容器作为一个分配单元分配,这将导致各个结点上任务负载不均。
Flink默认任务调度算法、Kubernetes容器调度算法和本文所提算法的任务调度实例如图4所示。
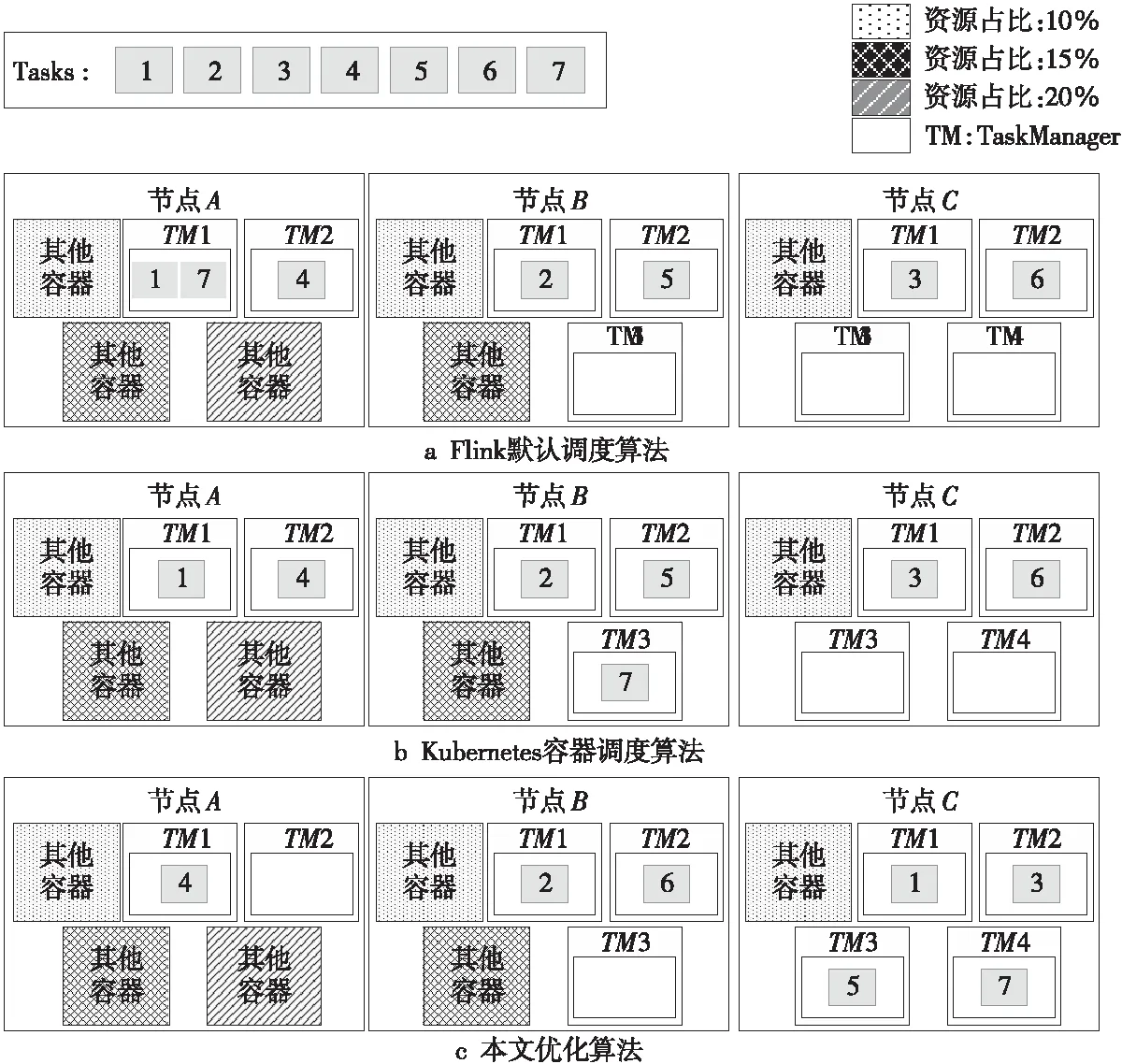
Figure 4 Flink containerized cluster processing task set图4 Flink容器化集群处理任务集合
Flink集群中有3个结点分别编号为A、B、C,这3个结点在性能上存在差别,结点C的性能最好,结点B次之,结点A最差。每个结点上运行着不同的容器,占用着大小不同的资源,结点A容器资源占用最多,结点B次之,结点C容器资源占用最少。
集群中结点C的性能明显优于结点A和结点B的性能。假设此时集群中需要处理含有7个任务的任务集合。
按照Flink默认的任务调度算法,结点A处理任务1,4,7,结点B需要处理任务2,5,结点C处理任务3,6。性能最差的结点A被分配了最多的任务,结点B和结点C分配了相等的任务。这样的任务分配结果就会造成负载不均衡。由此导致结点A处理时间拖慢了全部任务完成的时间,集群吞吐量下降,延时增加。
在Kubernetes容器集群情况下,按照其默认的容器调度算法,此时集群中,结点A处理任务1,4,结点B需要处理任务2,5,7,结点C处理任务3,6。性能最差的结点A和性能最好的结点C分配了相同数量的任务,结点B分配了最多的任务,也造成了结点负载不均,从而增加了整个Job的运行时间。
按照本文提出的FSACE算法,结点A性能最差,处理任务7,结点B性能好于结点A的性能,处理任务5,6,结点C性能最好,处理任务1,2,3,4。此时,性能好的结点处理更多的任务,性能相对差的结点处理更少的任务,集群中任务分配相对均衡,从而减少了任务的运行时间。
在容器化的Flink集群中,容器部署不均会造成结点间存在很大的性能差别,如果采用Flink默认的轮询策略,会造成任务在结点上分布不均衡,进而影响集群计算效率。
4.2 FSACE算法思想
FSACE算法基本思想是,Flink在容器环境部署时,为使任务分配更为均衡,需要获取结点性能与容器在结点上的分布情况,然后根据结点性能与容器在结点上的分布情况调度任务,每次选择评分最高的容器分配任务,并调整各结点的评分。在调度任务时考虑以下3个问题:
(1)结点上容器资源分配不均问题。拥有较多空闲资源的结点不应被频繁分配任务,需要根据容器的分布计算结点的性能,给结点评分,并优先将计算任务分配给评分高的结点所在的Flink容器。
(2)结点性能上限问题。为了避免评分较大的结点被连续选中,导致评分较大的结点很快达到它的性能上限,最终该结点过负载。FSACE算法会在选中结点时,适当降低结点评分,这样使性能较高的结点不会连续被选中,而是相对错开被选中,从而使任务分配更均衡。
(3)分布在同一结点的各容器资源会相互抢占资源问题。在一个容器中分配任务时,该结点占用的资源增加,为使任务调度更加均衡,应适当减少在该结点上的其他容器中分配任务,因此该结点其他容器分配任务的优先级应当下降。
例如,容器环境下Flink集群中3个结点A,B,C,它们的权值比值为3∶1∶2,因此当有6个任务需要被调度时,前3个任务分配给结点A,接下2个任务分配给结点C,最后一个任务分配给结点B。这样的任务调度策略就能充分发挥结点A的性能优势,同时规避了结点C的性能劣势。因此FSACE算法能够充分利用集群各个结点的计算能力。
4.3 技术架构
FSACE的技术架构如图5所示,其中架构的最底层为容器(Container),以Docker作为容器运行引擎,HDFS(Hadoop Distributed File System)作为分布式存储系统。
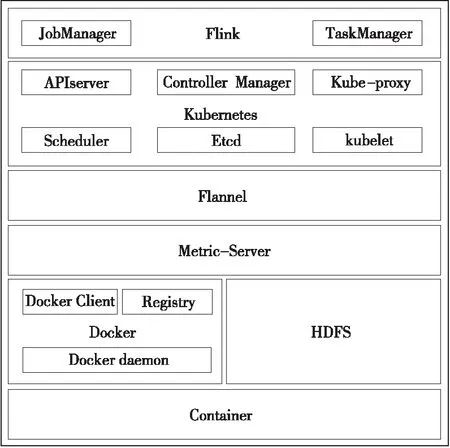
Figure 5 Technical architecture图5 技术架构
使用Metric-Server监控结点上的容器性能信息,Flannel作为容器网络插件,为每一个容器分配独立的IP。
使用Kubernetes作为容器集群管理工具。最上层为Flink大数据处理平台,主要包括JobManager和TaskManager 2种容器。
FSACE的调度流程如图6所示。FSACE算法首先会通过Metric-Server获取各个结点上的容器信息,以及每个结点的性能信息,之后将这些需要的信息发送给Flink。
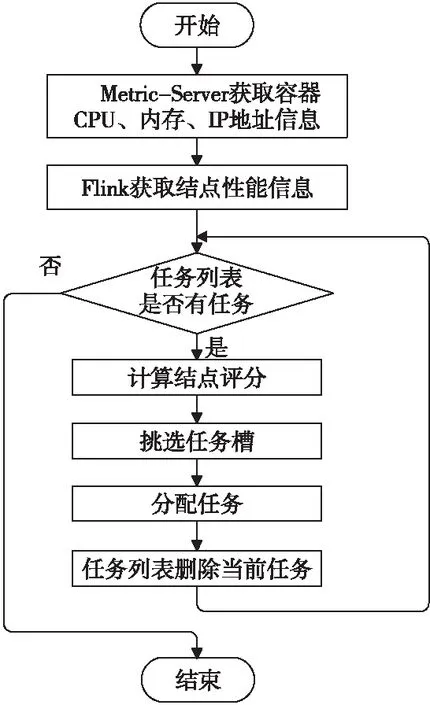
Figure 6 FSACE scheduling process图6 FSACE调度流程
接下来判断任务调度列表中是否存在未调度的任务,如果没有还未调度的任务,则流程结束;如果有任务,那么根据结点性能进行结点评分,然后挑选任务槽,分配任务,将任务优先分配给评分高的结点所在的任务槽,并且避免评分过高的结点被频繁选中导致负载过高的问题,之后在任务调度列表中将已经分配的任务删除。
4.4 FSACE算法
在容器化Flink集群中解决负载不均衡问题,就需要采用优化的结点性能评分任务调度算法,而这种算法需要得到集群中每个结点的性能评分。通常用计算资源来代表结点的评分,而影响Flink集群运行效率最主要的就是计算资源。计算资源中最具代表性的是CPU可用资源和内存可用资源,因此本文使用CPU可用资源和内存可用资源来给结点评分。
初始调度时根据CPU可用资源和内存可用资源指标得到一个结点初始评分P。使用初始评分P来衡量该结点的性能高低,初始评分的计算如式(1)所示:
P=δC+(1-δ)M
(1)
其中,C是CPU可用资源,M是内存可用资源,δ代表CPU可用资源在整个初始评分中所占的比例,1-δ代表内存可用资源在整个初始评分中所占的比例。通过实验发现,CPU与内存的比例不同,会影响任务运行时间,经过多次实验发现,Flink容器集群对CPU的资源敏感性大于对内存的资源敏感性,δ为0.9时效果最好。
使用当前评分Y来衡量运行过程中每个结点的评分。当前评分等于上一次的评分加初始评分,第1次当前评分等于初始评分。每经过一次调度有效评分都会发生变化,使用当前评分来衡量结点的性能,每次挑选当前评分最高的结点作为目标结点。削减当前评分的计算如式(2)所示:
(2)
其中,Y是当前评分,n是当前任务数,P是结点i的初始评分,当Y是被选中的最高评分时,T是每个结点的初始评分的和,若Y不是最高评分则T为0。
算法1是结点性能评分算法,其中输入的HttpDatas结点性能信息是通过Metric-Server容器组件获取到的每个容器信息,经过叠加计算获得的。然后,遍历这个结点性能集合,根据结点的CPU、内存信息计算每个结点的初始评分P,Y为结点的当前评分,初始时当前评分等于初始评分。然后,将计算好的每个结点性能评分加入到结点性能评分的集合DataSets中。
算法1结点性能评分算法
输入:Flink的结点数据集合HttpDatas。
输出:带评分的结点性能集合DataSets。
①fordatainHttpDatas
②P=(data.cpudata+(1-δ)data.memorydata;
③Y=P;
④d=newDataSet(ip,cpudata,memorydata,Y,P);
⑤DataSets.add(d);
⑥endfor
⑦returnDataSets
算法2是结点的控制评分算法,首先进行数据的初始化,把目标结点的instance变量初始化为空,把评分初始化为0(第1行)。然后将每个结点的DataSet都与instance比较,如果DataSet.Y比instance.Y大,则用instance记录DataSet,同时用T不断累加初始评分P,每个DataSet的当前评分加上自身的初始评分P(第2~8行)。结束循环后,把instance记录的当前评分最大的DataSet的有效评分减去总的评分T,之后getAvailableSlot()函数会顺序遍历这个结点上的TaskManager容器,并返回一个TaskManager容器中可用的Slot(第9行和10行)。
算法2控制评分算法。
输入:结点的性能评分数据集合DataSets。
输出:当前评分最大结点的任务槽Slot。
① Initializeinstance=null;T=0;
②forDataSetinDataSetsdo
③ifDataSet.Y>intance.Ythen
④instance=DataSet;
⑤endif
⑥T=T+DataSet.P;
⑦DataSet.Y=DataSet.Y+DataSet.P;
⑧endfor
⑨instance.Y=instance.Y-T
⑩slot=instance.getAvailableSlot()
本文提出的FSACE算法考虑到每个结点的性能差异,根据结点实时性能赋予每个结点合适的评分,根据评分大小进行轮询调度,这样就能够使任务调度负载均衡。
为了防止轮询调度时评分较大的结点被连续多次选中造成评分较大的结点迅速达到负载上限,结点的计算效率降低,因此采用一种更加合理的处理方式,即让结点被错开选中。
4.5 算法示例
为了能更好地解释优化的Flink任务调度算法,本节给出一个任务调度算法的示例。
容器化Flink集群中有3个Slave结点,分别为Slave1、Slave2、Slave3。假设初始的评分比例是Slave1∶Slave2∶Slave3=3∶1∶2,因为初始的时候结点的有效评分等于它自身的评分,因此有效评分比Slave1∶Slave2∶Slave3=3∶1∶2。
分别采用Flink默认任务调度算法和FSACE算法进行阐述。假设有一个任务集合共有6个子任务。
(1)Flink默认任务调度算法。该算法不需要考虑评分,因此其任务调度过程如表1所示。其中Slave1被选中2次,Slave2被选中2次,Slave3被选中2次,这3个结点被选中的次数一样多,即3个结点轮流被选中。显然这种任务调度策略没有考虑到每个结点的性能,Slave2的性能最差,却被分配到和Slave1、Slave3同等工作量的任务,因此Slave2成为提升集群效率的瓶颈。
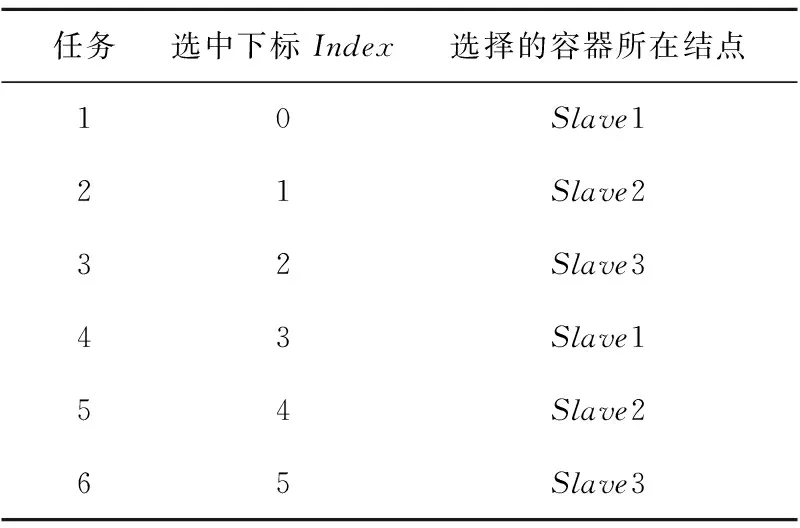
Table 1 Task scheduling process by Flink’s default algorithm
(2)FSACE算法。FSACE算法就是在任务调度的过程中,考虑每个结点CPU和内存的大小,对每个结点进行评分,优先挑选评分高的结点分配任务,并且避免某个评分高的结点连续被选中导致该结点达到负载上限,影响整个集群计算效率的问题。FSACE算法调度过程如图7和表2所示。结点被选中的顺序分别是Slave1、Slave3、Slave1、Slave2、Slave1和Slave3。最终的顺序考虑了每个结点的性能,又避免了性能较好评分高的结点连续被选中导致负载不均的问题。
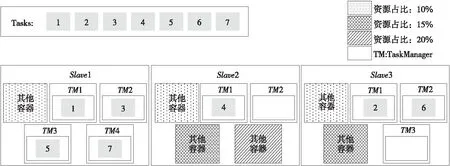
Figure 7 Task scheduling process of optimized algorithm 图7 优化的算法任务调度过程

Table 2 Task scheduling process of FSACE
综上所述,通过对2种任务调度算法过程的详细描述可以看出,FSACE算法在考虑了结点性能的基础之上,进一步避免了性能较好的结点连续被选中,使得整个Flink容器集群变得负载均衡,提高了整个集群的计算效率。
4.6 复杂性分析
在时间上,FSACE算法的时间复杂度为T(n)=O(m*n),其中m是容器数,n是任务数。
在空间上,FSACE算法中的性能评分算法需要存储容器部署信息,包含容器所在结点位置、容器IP地址、结点CPU使用率和结点内存使用率等信息,在算法中还需要用到中间变量及评分信息。每一条信息约几十字节,故算法空间复杂度为O(m),其中m为集群中的容器数。
5 实验
本节主要描述Flink默认任务调度算法与本文提出的FSACE算法的对比实验。通过Docker容器平台将Flink各个组件容器化,之后通过配置文件将Flink容器配置到Kubernetes集群中。在Kubernetes容器集群中,配置了Metric-Server容器监控组件来获取容器的性能信息。
5.1 实验环境说明
FSACE算法使用Java作为编程语言实现,操作系统使用CentOS,容器运行平台使用Docker,容器管理系统使用Kubernetes,容器性能监控组件使用Metric-Server。各软件版本如表3所示。
实验硬件环境配置:本文共使用4台阿里云服务器组成集群,其中性能最好的结点作为Master结点。各结点硬件配置如下:
结点1:通用型ecs.g6,CPU:4核,内存:8 GB,系统盘(SSD 云盘):200 GB;
结点2:通用型ecs.g6,CPU:2核,内存:4 GB,系统盘(SSD 云盘):200 GB;
结点3、4:通用型ecs.g6,CPU:2核,内存:2 GB,系统盘(SSD 云盘):200 GB。
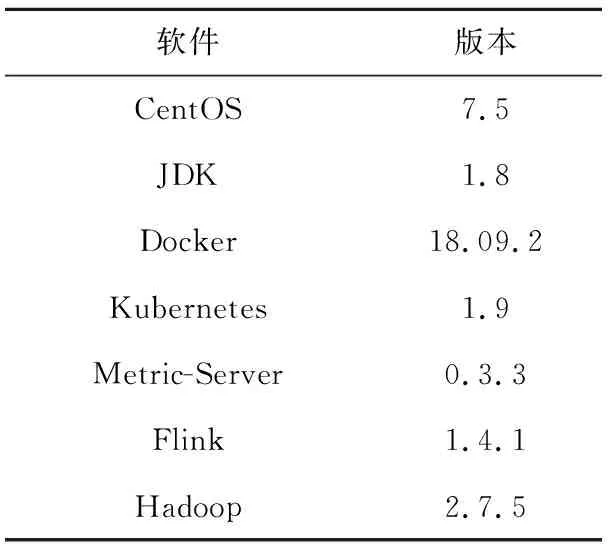
Table 3 Software version
生产情况下任务负载,每个结点上由于运行的容器的数量和规模不同,使得每个结点的性能变得不同,实验中为了尽可能模拟生产情况下任务负载,除了Flink的容器之外,在结点上部署了一些用于其他服务的Pod。每个结点的Pod以及资源配额数量如表4所示(集群单一结点CPU容量为1 000m,CPU分配单位为m,代表千分之一CPU)。
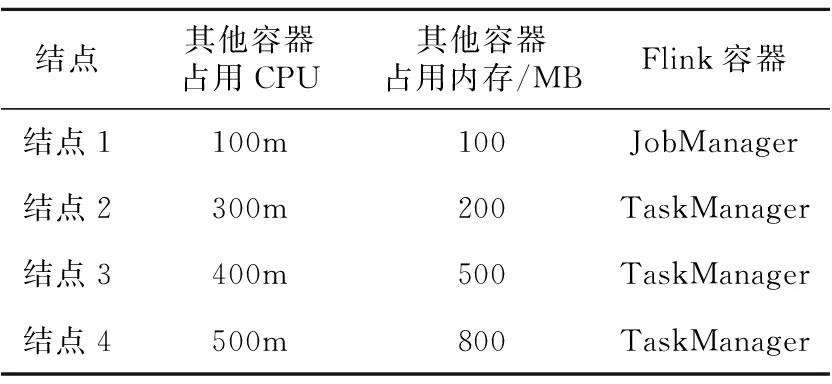
Table 4 Node resource quota
本节主要进行了CPU评分影响运行时间的实验、Flink默认任务调度算法、Kubernetes容器调度算法与本文提出的FSACE算法的对比实验,实验数据集为3种不同规模数据集。为了减小误差,每次实验进行3次取平均值。
5.2 实验参数说明
本文使用了WordCount计算任务进行测试,使用的实验数据集共有3种规模,测试程序分别在这3种数据集、不同的容器数量、并行度情况下进行了多组实验,之后选取实验效果较好的参数设置进行了TeraSort计算任务的实验。
实验中使用Flink默认任务调度算法、Kubernetes容器调度算法、FSACE算法从时延、吞吐量和运行时间方面做了对比和分析。
实验中使用一个计算任务例子WordCount,该程序主要是统计每个单词出现的次数,执行过程是Source-FlatMap-GroupBy-Sum-Sink,其中Source是读取数据源,FlatMap是将每一行语句按照空格拆开变成多个单词,GroupBy则是将单词分组,相同的单词被数据重组(shuffle)到同一个结点,后续可以统计单词个数。Sum统计每个单词出现的次数,Sink把统计结果写入到HDFS中。
实验中另一个计算任务是TeraSort,它是分布式计算平台中用于对数据进行排序Benchmark,在不同平台上对数据排序的效率是衡量分布式系统处理能力的公认标准。整个实验中所用到的实验参数如表5所示。

Table 5 Experimental parameters
5.3 实验结果与分析
图8展示了δ对于运行时间的影响。由实验结果可以看出,δ会影响任务的运行时间,容器环境下Flink任务的执行时间对CPU的资源敏感性大于对内存的资源敏感性,并且δ为0.9时,运行时间最短,后面的实验均采用δ=0.9。
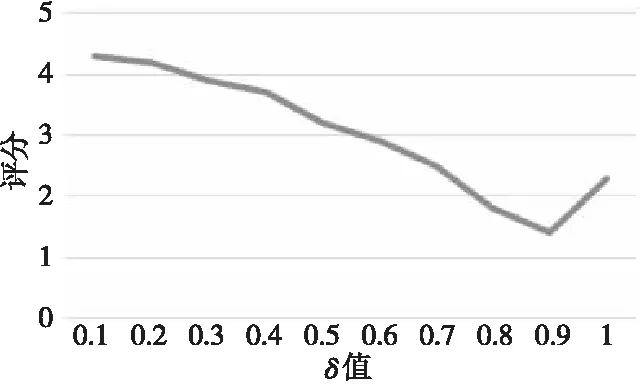
Figure 8 Running time v.s. δ图8 运行时间随δ值变化
在不同规模数据集上,算法任务运行时间评测结果如图9所示。FSACE算法相对其他2种算法,Flink任务的运行时间明显减少,并且随着数据集规模的增加,优化效果更加明显。实验结果显示,本文提出的算法由于结合了容器部署信息调度任务,使任务分布得更加均衡,从而提高了集群效率,减少了任务运行时间。本文算法也能够将新分配的计算任务尽可能多地分配到计算资源丰富的结点所在的TaskManager容器中,并且能够避免连续选择某一结点,这样使得计算资源丰富的结点能够负担更多的任务,而计算资源少的结点负担相应少的任务,因此使Flink容器集群负载均衡,从而缩短任务的运行时间。
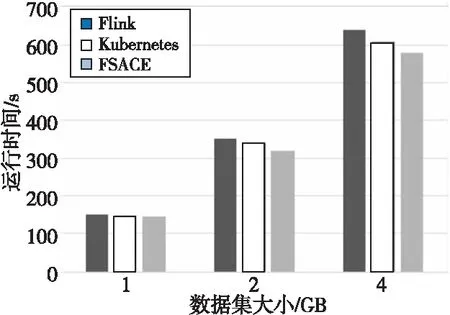
Figure 9 Comparison of task running time under different data set size图9 不同规模数据集上任务运行时间对比
在不同并行度下,算法任务运行时间评测结果如图10所示。并行度更高时,本文提出的FSACE算法相对其他2种算法的Flink任务的运行时间提升更加明显。实验结果显示本文提出的算法有较好的可扩展性。
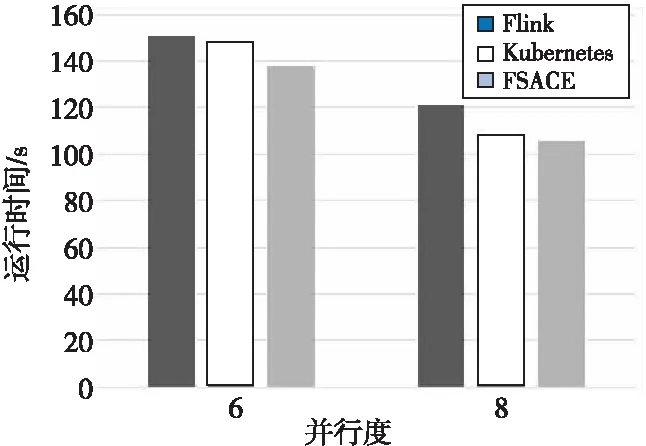
Figure 10 Comparison of task running time under different parallelism图10 不同并行度下任务运行时间对比
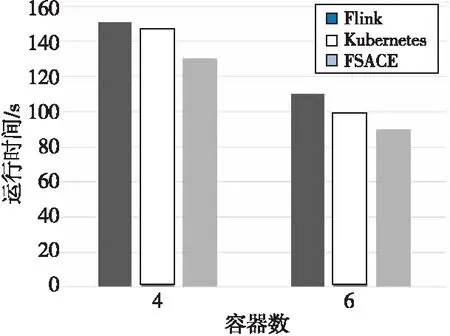
Figure 11 Comparison of task running time under different container numbers图11 不同容器数量下任务运行时间对比
在不同容器数量下,算法任务运行时间评测结果如图11所示。实验结果显示,FSACE算法相对其他2种算法Flink的运行时间提升相对明显。实验结果表明,本文算法更适于多容器环境下部署。FSACE算法的运行时间比Flink默认的任务调度算法的运行时间少,平均运行时间少8%,显示了本文算法在容器环境下部署Flink任务调度能有效提升任务运行效率。
在不同计算方面,算法任务运行时间评测结果如图12所示。实验结果显示,TeraSort任务执行时间比WordCount的任务执行时间明显要少,这是由于WordCount计算过程相对更加复杂,因此需要的任务执行时间更多。实验结果还显示,FSACE算法在WordCount计算任务上的优化效果比TeraSort计算任务更加明显,其原因是TeraSort计算任务结点间的负载较均衡。
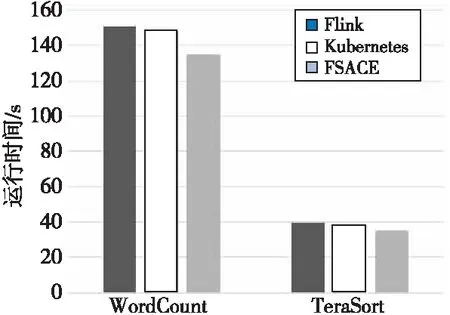
Figure 12 Running time of different computing tasks图12 不同计算的任务运行时间
算法调度后任务均衡性评测结果如图13所示。实验结果表明,使用FSACE算法,容器集群中不同结点的CPU和内存资源使用更加均衡。这是由于FSACE算法在任务调度时结合了容器部署信息,从而使任务更均衡地分布在结点上。
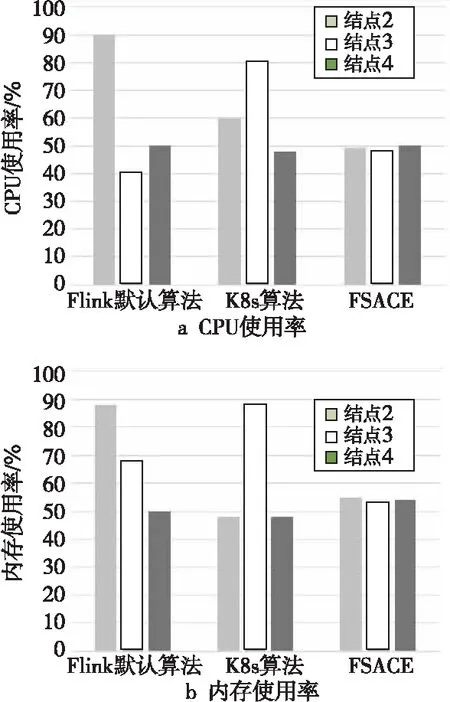
Figure 13 Load comparison of cluster nodes图13 集群结点负载对比
另外,本文对FSACE算法的任务调度时间与任务运行时间进行了评测,评测结果如图14所示。实验结果显示,在任务调度算法方面,由于FSACE算法需要获取容器部署信息,任务调度也比Flink默认算法复杂,因此任务调度稍慢于Flink。但是由于任务执行时间占更主要部分,而FSACE算法能在容器环境下使任务分布得更加均衡,因此运行时间快于Flink。
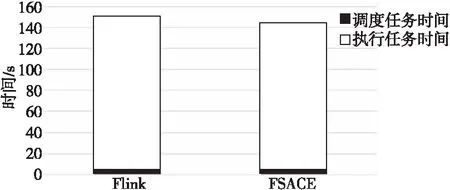
Figure 14 Task running time comparison图14 任务运行时间对比
综上所述,在Flink容器集群中,在某些情况下,由于集群中运行着较多的提供不同服务的容器,导致每个结点的性能不一样,FSACE使计算资源多的结点上的TaskManager容器被分配相对多的任务,而计算资源相对较少的结点上的TaskManager容器被分配相对较少的任务。这种任务分配策略能够实现负载均衡,缩短任务的运行时间,避免了默认的Flink任务调度算法中由于计算资源少的结点中的TaskManager容器完成和其他结点同等的任务而影响整体作业的完成进度,因此能够节省计算的时间,提高集群的计算效率。
6 结束语
本文首先介绍了容器环境下大数据处理引擎任务调度优化的研究背景与意义,以及大数据处理引擎任务调度优化方面的国内外研究现状。之后介绍了本文使用的相关技术,并仔细研究了Flink默认调度算法,分析了其在容器环境下任务调度容易发生负载不均衡的问题,提出了适用于容器环境下的Flink任务调度算法。实验结果表明,本文提出的FSACE算法,在容器集群中容器分布不均衡的情况下,能够减少作业运行时间,使得负载均衡,提高整个集群的计算效率。
在未来计划继续进行以下几方面的工作:
(1)使用更大规模的数据集验证实验效果;
(2)在进行任务调度优化的过程中考虑不同算子的特点进一步进行优化;
(3)根据不同的任务类型,调整CPU占用率和内存在评分中的权重,进一步优化评分算法。
猜你喜欢
中学生数理化·八年级物理人教版(2022年4期)2022-04-26
电子制作(2021年14期)2021-08-21
读者·校园版(2019年24期)2019-12-10
制造技术与机床(2019年4期)2019-04-04
测控技术(2018年7期)2018-12-09
数学物理学报(2018年1期)2018-03-26
信息通信技术(2015年6期)2015-12-26
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
小朋友·聪明学堂(2015年8期)2015-11-30
电子设计工程(2014年12期)2014-02-27
