
一种双端口发射队列及其性能优化
2021-08-06 03:22隋兵才孙彩霞王永文
计算机工程与科学 2021年7期
隋兵才,孙彩霞,王永文,郭 辉
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
微体系结构技术的不断革新,使得微处理器的时钟频率不断提高,芯片的集成度也越来越高。这2个方面也同时导致了整个处理器更高的功耗密度,也就必须使用更高的成本以降低整个处理器的工作温度。降低处理器的关键功能部件的功耗,可以有效地提高整个处理器的能效,并能够降低冷却成本,或者说,在给定能效的情况下,处理器可以获得更高的性能。
发射队列是超标量处理器中的关键功耗部件,并对整个处理器的性能起着决定性的作用。为了保证超标量处理器的整体性能和功耗,必须要对发射队列进行低延迟、 低功耗的专门设计。
传统的发射队列都是利用全相联的唤醒机制来实现。这种实现方式需要在每个时钟周期对发射队列中所有的指令进行操作数的检查监控,直到指令所需要的所有源操作数就绪,并且执行资源可用时,才可以将该指令唤醒并等待到执行部件执行。选择控制逻辑在源操作数就绪的所有指令中选择一条或者多条指令送入执行单元。尽管这种实现方式可以有效地提高处理器的IPC(Instructions Per Cycle),但是发射队列的延迟会与处理器的时钟频率不相匹配。 并且,随着发射宽度或者发射队列的大小的增大,发射队列的复杂度会急剧增大。
本文提出了一种能够以较低功耗有效提高乱序超标量处理器性能的发射队列结构。该结构包含多个指令队列,能够根据指令之间的相关性,估算指令的发射时机,将指令分配到不同的队列中。
2 相关工作
指令通过取指和译码流水站之后,通过分派逻辑被存储到发射队列中,在所有操作数准备好之后被发射到执行单元。发射队列的设计需要着重考虑影响性能和复杂性的相关问题,包括:指令的保存方式、指令的发射逻辑、指令的监控逻辑以及如何选择指令的执行单元。
传统的发射队列基于CAM(Content-Address- able Memory)结构[1],能够有效提升处理器的IPC,但是同时也使得处理器的功耗按比例增大。后续也有相关的实现针对CAM结构的功耗问题进行优化[2,3],大多通过动态调整发射队列的大小,或者通过关闭空闲的唤醒逻辑,或者利用发射队列与ROB(Re -Order Buffer)的控制逻辑关系来降低CAM的功耗。
Buyuktosunoglu等[4]提出了一种CAM和RAM(Random Access Memeory)相结合的发射队列实现结构,以有效降低发射队列的功耗。同时,论文中也提出了类似的动态调整发射队列大小的设计思路。Brown等[5]提出了一种流水实现的发射队列,能够保证连续发射指令。Ernst等[6]提出了一种可以包含3种类型存储项的发射队列,能够降低功耗,提高发射队列的性能。
Cotofana等[7]提出了一种利用计数器减少资源冲突的发射队列选择逻辑,相对于传统的发射机制,能够更快地唤醒和选择指令并发射到功能单元。Kucuk等[8]针对发射队列提出了低功耗比较器、0字节编码和位处理方式,以有效降低相关功耗。 Lebeck等[9]提出了一种等待指令的存储缓冲,以保存与访问Cache失效指令相关的指令。当Cache失效处理完成之后,相关指令从缓冲中移动到发射队列中。Brekelbaum等[10]提出了基于结构化调度的发射队列结构,关键性的指令被存放在高速CAM/RAM发射队列中,而非关键性指令存放在低功耗高延迟的CAM结构中。Canal等[11,12]提出了不同于传统方式的发射队列结构。分派时,该结构首先估算每条指令的发射时机,然后根据计算结果进行顺序发射。由于在分派时刻很难估算出指令的精确发射时机,该结构中实现了一个很小的CAM/RAM阵列,以保存在预计时刻不能发射出去的指令,直到按照传统的方式将其发射到功能单元中。Michaud等[13]提出了一种2级发射队列结构,其中第1级与传统的CAM/RAM结构相同,第2级保存暂时不能被唤醒的指令。该实现机制能够很好地解决指令之间的相关性,但是在一定程度上增加了实现的复杂度。Raasch等[14]提出了一种可调整的发射逻辑,该逻辑实现了多个存储体,可以根据指令的延迟将指令从一个存储体调度到另一个存储体,可以实现很高的频率,但是功耗依然是一个比较大的问题。
上述很多实现机制需要在分派时计算被分派的多条指令的发射时机,这必然导致复杂的硬件实现逻辑。
由于CAM结构的发射队列的功耗更高,因此研究人员提出了很多非CAM结构的发射队列结构。通过分析指令特性,发现大部分指令的后续相关指令并不多,因此Canal等[11]提出了一种根据每条指令唤醒N条相关指令的结构。Palacharla等[1]提出了一种FIFO结构的发射队列,只有FIFO头部的指令才会被发射出去。
Moreshet等[15]提出一种双端口的发射队列结构,能够以更小的发射队列资源获得更高的指令并行度,并能够有效减少发射信用处理通路的关键路径。
其他关于发射队列结构的综述可以参考文献[16]。
3 发射队列设计
发射队列是超标量处理器中的乱序控制部件。发射队列接收指令控制部件分派的指令相关信息,并负责监控执行部件的数据总线使用及空闲状态,更新发射队列中等待发射的指令的操作数相关信息,一旦指令的所有操作数准备就绪,并且不存在后续的流水线和总线相关,该指令即进入准备状态。发射队列从已经准备就绪的所有指令中选择一条指令发射到对应的流水线中执行。由于VFU(Vector and Float Unit)部件的执行流水线是不等长流水线,并且多个流水线共享3条结果总线,因此VFU部件的发射队列还需要根据各条指令的延迟情况,以及结果总线的空闲情况,判断准备发射的指令是否存在结构相关。此外,为了提高浮点处理性能,根据处理器融合乘加实现的方式,发射队列也维护了FMUL/FADD/FCVT(Floating-point CoVerT)部件指令结果数据旁路到浮点融合乘加的累加操作数中的相关控制,以保证浮点融合乘加指令不必等到所有的操作数都全部准备好之后再进行发射,可以在2个乘法操作数准备好,并且确定累加操作数可以通过旁路获得的时候,就将融合乘加的指令提前发射到乘法流水线中。
发射队列的结构图如图1所示,其中UOP代表Micro-OPeration。浮点部件的发射队列为2入2出24项的结构。每个时钟周期最多可以接受指令译码部件分派来的2条指令,并且每个时钟周期可以最多向流水线中发射2条指令执行。整个发射队列采用节拍(age)计数的方式进行发射控制,每个时钟周期从24个发射项中选择操作数已经就绪的并且节拍数最多的2条指令进行发射,2个发射端口可以分别向VFU的所有2条流水线中各自发射指令。
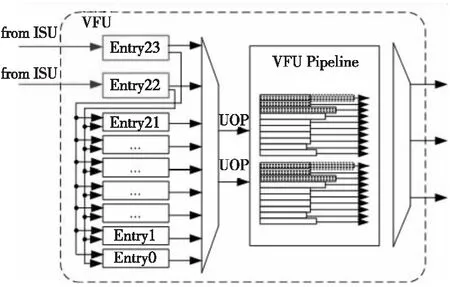
Figure 1 Structure of dual-port issue queue图1 双端口发射队列的结构图
(1)时序控制:发射队列的每一项有一个age标识,发射队列有多少项age标识就有多少位,每一位对应一项。每一项根据age标识来判断当前项与其他各个项的时序关系,如果age标识中的某个对应位为1,表示当前项要比对应项后进入流水线。
(2)发射队列首项:发射队列的结构均为2入2出。指令控制部件分派来的指令只进入发射队列的首2项,然后再由首2项输出指令信息并将其保存到其他项,其他发射队列项与ISU(Instruction Schedule Unit)无接口。首项接收的指令的age标识为全1。
由于VFU部件的各个流水线长度不一致,所有的流水线共享3条结果总线,因此需要对发射出来的指令进行结果总线的相关判断。VFU部件根据指令的延迟的不同,对各个延迟的指令对应的结果总线维护了一个记分牌,用于记录当前流水线中的指令需要占用的结果总线的情况。发射队列在发射指令的同时,需要根据所发射的指令的延迟,检查对应的延迟的记分牌,如果有空闲总线,则该指令可以正常发射;否则,该指令不能发射。
4 分析与优化
4.1 硬件开销分析
24项的单端口发射队列的结构图如图 2所示。

Figure 2 Structure of single-port issue queue图2 单端口发射队列的结构图
对比图 1和图 2的结构可以看出,本文提出的双端口发射队列与分布式单端口发射队列的项数均为24项。双端口发射队列的头2项为入口项,采用向下移动的方式维护,所以其它项的指令信息来源于2个入口项。发射指令时,双端口需要从24项中选出2项,传统实现需要2个24选1的选择逻辑,但是为了降低硬件实现的复杂度,也可以使用12-1的选择逻辑实现。单端口发射队列的第11项作为入口项,也采用向下移动的方式实现,其它项的指令信息来源于入口项。发射指令时,分别使用2个12-1的选择开关实现。因此,从硬件实现开销角度来说,双端口的发射队列并没有增加很多额外的硬件开销。相比于分布式的单端口发射队列实现,如果流水线端口slotj和slotk属于不对称结构实现,slotj和slotk的可用发射队列项都是24项,但是单端口发射队列的可用发射队列项为12项,能够有效提高非对称流水线设计中发射队列的利用率。
4.2 发射策略优化
发射队列向执行部件发射指令的策略对整个流水线的效率有很大影响。由于本文的发射队列是一个2入2出的队列结构,所输出的2条指令需要根据类型不同分配到不同的执行槽上。本文设计对比了2种不同的发射策略对执行性能的影响。2种不同的发射策略如图3所示。图3a的发射队列在接受分派的指令时,不对指令进行分类检查,而在发射到执行流水线之前,分别从发射队列的高低2部分选取最老的指令,然后对2条选取出的指令进行类别判定。如果2条指令存在执行流水线冲突,则取消1条指令。否则,将指令发射到对应的执行流水线中执行。图3b的发射队列在接收分派的指令进入发射队列之前,对所处理的指令进行执行流水线的标记,指令进入发射队列之后就已经确定在流水线j(slotj)或者流水线k(slotk)执行。发射时,从所有的队列项中分别选取流水线j(slotj)或者流水线k(slotk)中的最老的指令进行发射即可。
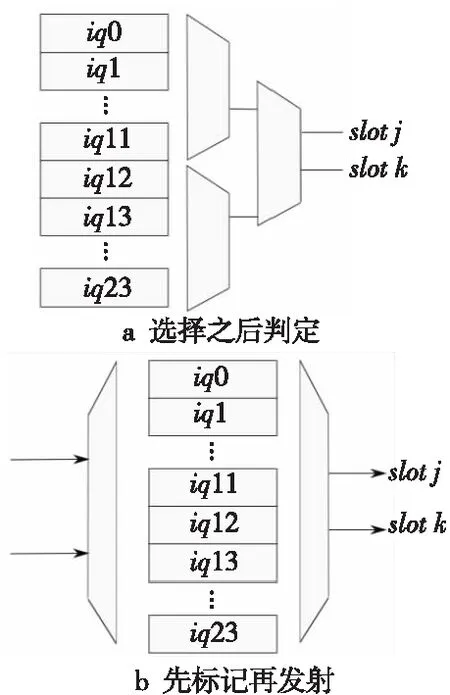
Figure 3 Two different issue strategies图3 2种不同的发射策略
对2种发射策略进行SPEC2006性能评测的结果如图3所示。发射队列输入端对指令进行执行流水线的标记相比于基准版的发射策略能够有效降低执行流水线的冲突,提升执行的有效IPC,最大可提升10.68%。2种发射队列的主要不同点在于是在发射队列输入端还是输出端进行执行流水线的判定。图3a从发射队列的高低2部分分别选择2条指令,在输出端进行执行流水线的判定,需要的选择逻辑较少,但是存在2条指令执行流水线冲突的情况。图3b在发射队列的输入端就进行执行流水线的标记和确定,在发射时只要选择对应执行流水线的指令发射到对应的执行流水线中,能够有效减少执行流水线冲突的情况,但是选择控制逻辑较多。
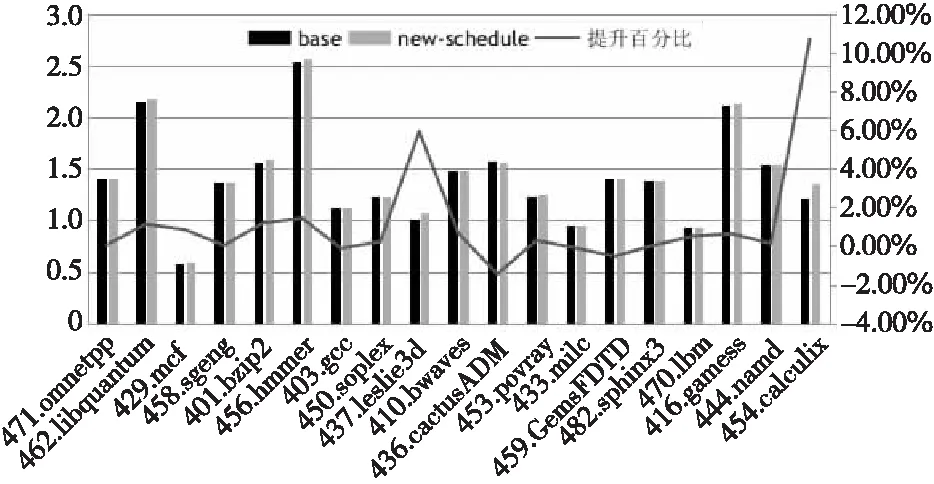
Figure 4 Performance comparison of two issue strategies图4 2种发射策略性能对比
4.3 发射队列项数
由于发射队列是乱序超标量处理器中最关键的乱序资源,其项数对性能和整个处理器的PPA(Performance Power and Area)指标影响很大,因此,本文也对比了24项发射队列与32项发射队列对处理器SPEC2006实际IPC性能的影响,发射队列均采用输入端标记式的发射策略。SPEC2006的IPC性能测试结果如图5所示。
由于仅增加了浮点部件的发射队列,所以SPEC的整数程序的性能提升不大,但也有稍许提升。对于浮点测试程序平均IPC性能提升2%,最大提升8.59%。但是,454.calcculix程序IPC性能降低12%,可能是该程序的访存较多,增大发射队列会引起更多的流水线刷新,从而引起性能的降低。因此,增大乱序发射资源的同时,必须相应地优化其他乱序资源,以达到资源的最大利用率,有效提升IPC性能。
5 结束语
发射队列是超标量处理器中的关键部件,并对整个处理器的性能起着决定性的作用。本文设计并实现了一种2入2出的发射队列结构,并对不同的发射策略进行了性能评测与优化。比对了32项与24项发射队列对处理器有效IPC性能的影响。发射队列的项数对处理器的IPC性能有重要影响,在增大发射队列资源的同时,也必须相应地优化其他乱序资源,以获得资源的最大利用率。
猜你喜欢
北京航空航天大学学报(2022年7期)2022-08-06
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
小学科学(学生版)(2020年2期)2020-03-03
军营文化天地(2018年2期)2018-12-15
产品可靠性报告(2017年7期)2017-09-05
个人电脑(2016年12期)2017-02-13
电子制作(2016年19期)2016-08-24
中国资源综合利用(2016年9期)2016-01-22
电源技术(2015年11期)2015-08-22
