
基于卷积神经网络的激光雷达点云目标分割*
2021-08-06 09:18黄影平
通信技术 2021年7期
张 青,黄影平
(上海理工大学,上海 200093)
0 引 言
自主驾驶系统依赖于对环境的准确、实时和强大感知。自主驾驶汽车需要准确分类和定位“道路对象”。本文将道路对象定义为与驾驶相关的对象,如汽车、行人、自行车和其他障碍物。不同的自主驾驶解决方案可能具有不同的传感器组合,但是激光雷达扫描仪是最流行的组件之一[1]。激光雷达扫描仪直接生成环境的距离测量值,供车辆控制器和设计人员使用。此外,激光雷达扫描仪在几乎所有照明条件下都具有强大的功能,无论白天还是黑夜,无论有无眩光和阴影。因此,基于激光雷达的环境感知任务已引起人们的关注。
本文使用基于Velodyne的64线3D激光雷达点云进行道路对象分割。考虑到激光雷达扫描仪的点云输出,该任务旨在隔离感兴趣的对象,并预测其类别,如图1所示。其中,汽车用c标注,行人用p标注,骑车人用b标注。
本文提出了一种基于卷积神经网络(Convolutional Neural Nets,CNN) 和 条 件 随 机 场(Conditional Random Field,CRF)的端到端流水线。具体地,先设计一个输入为转化后的雷达点云、输出为逐点标签矩阵集合的CNN,并通过CRF模型进一步完善CNN,再通过应用常规的聚类算法获得实例级标签。为将3D点云数据送到2D CNN中,本文采用球面投影将稀疏的不规则分布的3D点云转换为密集的2D图像。所提出的CNN模型从SqueezeNet[2]中汲取了灵感,经过精心设计后,可减小参数大小和计算复杂度,旨在降低内存需求,达到适合嵌入式应用的实时处理速度。CRF模型[3]被表述为递归神经网络(Recurrent Neural Net,RNN)模块,可以与CNN模型一起进行端到端训练。设计的模型在KITTI数据产生的雷达点云上训练,从KITTI中的3D边界框转换逐点分割标签。实验表明,设计的卷积神经网络达到了很高的准确性,且快速、稳定,可适用于自主驾驶应用。
1 相关工作
现阶段,点云分割的主流方法主要分为基于点云强度、曲率等特征分割的传统方法和基于神经网络的点云语义分割方法。
1.1 点云分割的传统方法
传统方法主要是移除地面,将其余点聚集成实例,从中提取特征,并根据提取的特征对每个群集进行分类[4]。这种方法尽管很流行,但存在缺点。首先,地面分割通常依赖于手工制作的特征或决策规则,一些方法依赖预设的阈值[5],而另一些方法需要更复杂的特征,如表面法线[6]或不变量描述符[7],这些都需要大量的数据预处理。其次,分类或聚类算法无法利用环境,最重要的是无法利用对象的周围环境[8]。最后,大多数地面去除的算法都依赖于迭代算法,如随机样本一致性(RANdom SAmple Consensus,RANSAC)[9]和高斯过程增量样本一致性(Gaussian Process INcremental Sample Consensus,GP-INSAC)[10]等。这些算法的准确性和运行时间取决于随机初始化的质量,存在不稳定性。对于自主驾驶系统这种嵌入式应用程序,这种不稳定性是不可接受的。
1.2 点云分割的神经网络算法
随着神经网络技术的快速发展,近年来越来越多的学者开始将这种高效方法应用在点云的语义分割上。基于神经网络的点云分割大致有两种。一种是以3D点云数据直接作为输入的点云分割算法。例如,文献[11]将基于三维的卷积神经网络对体素化后的点云数据作为输入,完成像素级别的语义分割。该方法虽然网络结构简单,且不需要数据预处理,但体素点云作为输入计算量大,难以解决空间信息丢失问题。另一种是将3D点云转化为2D图像作为输入的分割算法。例如,文献[12]主要是基于深度图像的孔洞填充顶帽算法,将点云映射到二维图像中,再通过检测到的相互连接的元件提取特征信息,训练卷积神经网络进行点云数据的分类。此方法虽然大幅减少了计算量,但在转换过程中丢失了点云图像的深度信息。
2 方法描述
2.1 点云转换
常规的CNN模型在二维图像上运行,可以用尺寸H×W×3的3维张量表示。前两个维度给空间位置编码,其中H和W分别表示图像的高度和宽度;最后一个维度给特征编码,最常见的是RGB值。但是,3D雷达点云通常以一组笛卡尔坐标(x,y,z)表示,还包括其他特征,如强度或RGB值。与图像像素的分布不同,LiDAR点云的分布通常稀疏且不规则。因此,直接将3D空间离散数据作为像素点会导致空像素过多。处理这样的稀疏数据效率不高,且计算量极大。
为了获得更紧凑的表示,本文将雷达点云投影到一个球体上,以实现密集的网格基表示,如图2所示。
相关公式可表示为:
2.2 网络结构
本文的卷积神经网络结构,如图3所示。基础模型源自SqueezeNet,一种轻型CNN,用50倍以下参数实现AlexNet级精度。SqueezeNet已成功用于图像的目标检测。
神经网络的输入是所述的64×512×5张量,从SqueezeNet移植层(Conv1a到Fire9)进行特征抽取。SqueezeNet使用max-pooling在宽度和高度上对中间特征图进行向下采样,但是由于本文中输入张量的高度远小于其宽度,因此仅对宽度进行向下采样。Fire9的输出是给点云的语义编码的下采样特征图。
为了获得每个点的标签预测,本文使用了反卷积模块(更准确地说是“转置卷积”),在宽度维度上对特征图进行上采样。使用跳跃连接,将上采样的特征图添加到相同大小的低级别特征图,如图3所示。具有softmax激活的卷积层(conv14)生成输出概率图,而概率图由循环CRF层进一步完善。

2.3 条件随机场
使用图像分割,CNN模型预测的标号映射倾向于具有模糊的边界。这是由于在max-pooling之类的下采样操作中失去了低级细节。准确的逐点标签预测不仅需要了解对象和场景的高级语义,还需要了解低级细节。后者对于标签分配的一致性至关重要。例如,如果点云中的两个点彼此相邻,且具有相似的强度测量值,则它们很可能属于同一对象,因此具有相同的标签。使用条件随机场(Conditional Random Fields,CRF)来优化CNN生成的标号映射。对于给定的点云和标签预测c,其中ci表示第i个点的预测标签。CRF模型采用能量函数:
式中:一元多项式ui(ci)=-logP(ci)由CNN分类器产生的预测概率P(ci)决定。
二元多项式定义了将不同标签分配给一对相似点的“惩罚”,定义为:
式中:μ(ci,cj)=1,ci≠cj且都不为0。二元多项式与km有关,km是取决于点i和j的特征的高斯核。wm是相应的系数。
本文使用了两个高斯核,即:
最小化CRF能量函数,可产生精确的标签分配。式(2)的精确最小化很难解,可以用一种平均场迭代算法来近似有效地求解它。将平均场迭代表述为递归神经网络(RNN),将平均场迭代算法的详细推导及其公式化阅读器定义为RNN。这里仅简要介绍作为RNN模块的平均场迭代的实现,如图6所示。CNN模型的输出作为初始概率图被馈入CRF模块,之后基于作为式(3)的输入特征来计算高斯核。
上述高斯核的值随着两点之间的距离(在3D笛卡尔空间和2D角空间中)飞速下降。因此,将每个点限制到3×5的小区域内核上作为输入张量。然后,使用上述高斯核对初始概率图进行过滤。以上述高斯核为参数,可将该步骤实现为一个局部连接层。之后对聚合概率重新加权,并使用“兼容性转换”来确定其改变各点分布的程度。此步骤可以实现为1×1卷积,训练期间学习其参数。将初始概率添加到1×1卷积的输出中,更新初始概率,并使用softmax对其进行归一化。模块的输出为完善的概率图,通过迭代应用此过程,可进一步完善该概率图。实验中,使用3次迭代来实现准确的标号映射。该递归CRF模块和CNN模型可以端到端一起训练,使用单级流水线,避开了多级工作流中存在的传播错误线程。
2.4 数据收集
本文的初始数据来自KITTI原始数据集。该数据集提供了按顺序组织的图像、LiDAR扫描和3D边界框。以3D边界为界进行逐点注释。对象的3D边界框中的所有点均被视为目标对象的一部分,然后对每个点分配相应的标签。这种转换的例子,如图2(a)和图2(b)所示。使用这种方法收集了10 848张带有逐点标签的图像。
3 实 验
3.1 评估指标
本文在类级和实例级的分割任务上评估模型的性能。对于类级分割,将预测分数与地面真值标签逐点比较,并评估精度、召回率和IoUc(交并比)分数。
这些分数定义为:
式中:pc和cς分别表示属于c类的预测点和地面真值点集;|·|表示集合的基数;IoUc分数用作我们实验中的主要准确性指标。
对于实例级分割,先将每个预测的实例i与地面真值实例进行匹配。此指数匹配过程可以表示为M(i)=j,式中i∈{1,…,N}表示预测实例指数,j∈{ϕ,1,…,M}表示地面真值指数。如果没有与实例i匹配的地面真值,则将M(i)设置为ϕ。匹配过程M(·)通过点数对地面真值实例进行排序,对于每个地面真值实例,找到具有最大IoU的预测实例。对于每个c类,实例级精度、召回率和IoU分数计算为:
式中:pi,c表示属于类c的第i个预测实例。不同的实例集互相排斥,因此∑i|pi,c|=|pc|。同样,对于ςM(i),c,如果地面真值实例与预测i不匹配,则ςM(i),c为空集。
3.2 实验设置
本文的主要数据集是上述转化的KITTI数据集。将原始数据集分为具有8 057帧的训练集和具有2 791帧的验证集,并在实验中确保训练集中的帧不会在验证序列中出现。同时,在Tensorflow中开发了模型,并在实验中使用了NVIDIA TITAN X GPU、Drive PX2 AutoCruise和AutoChauffeur系统。
3.3 实验结果
图7是二维数据语义分割结果可视化。表1总结了该卷积神经网络的分割精度。比较CNN网络的两种结构,一种具有递归CRF层,另一种不具有递归CRF层。较高的IoU对逐点正确性有要求,因此这有着极高的挑战性。但是,本文设计的卷积神经网络仍然取得了较高的IoU分数,尤其是在汽车类别中。汽车类别的类级和实例级召回率均高于90%,对自主驾驶而言是理想的。行人和骑车人类别的较低表现归因于以下两个原因:(1)数据集中行人和骑车人的实例更少;(2)行人和骑车人的身材要小得多,且细节更多,因此很难进行分割。
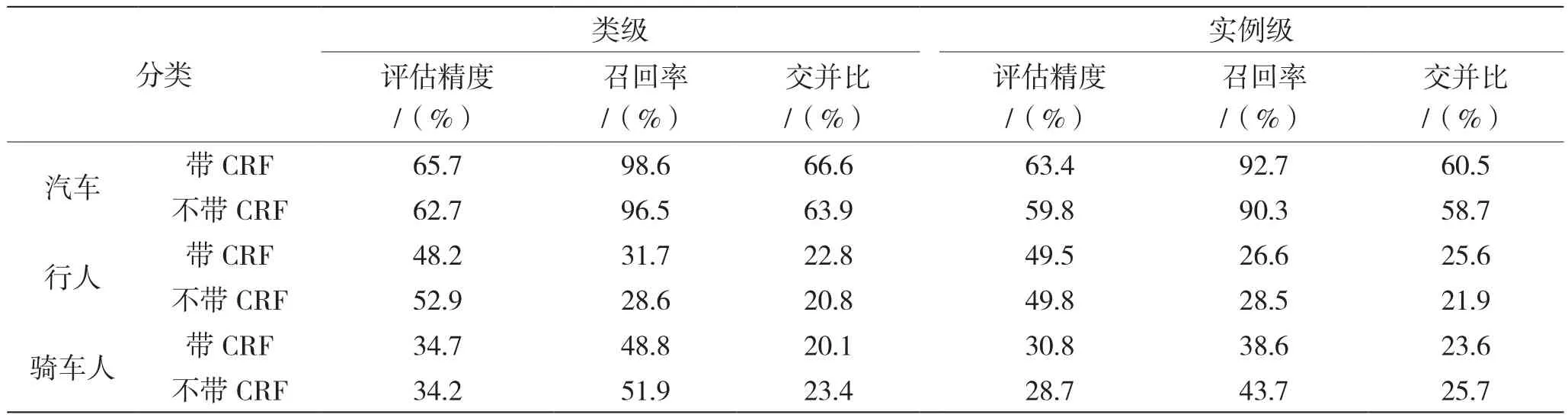
表1 本文卷积神经网络的分割性能
将CNN与CRF相结合,显著提高了汽车类别的准确性。提高主要来自精度的提高,因为CRF可以更好地过滤边界上错误分类的点。同时,CRF在行人和骑车人分割任务中的表现略差,可能是由于行人和骑车人缺少CRF参数调整所致。
在TITAN X GPU上,不带CRF的CNN处理一个LiDAR点云帧只需要8.9 ms,结合CRF层的CNN处理一个LiDAR点云帧也只需要13.8 ms,比当今大多数LiDAR扫描仪的采样速率快得多。Velodyne HDL-64E LiDAR的最大和平均转速分别为20 Hz和10 Hz。两个模型的运行时标准偏差都非常小,这对整个自主驾驶系统的稳定性至关重要。
4 结 语
对于雷达点云产生的道路对象分割,本文基于SqueezeNet设计的卷积神经网络,是一种较为准确、快速且稳定的端到端方法。提出的深度学习方法不依赖手工制作特征,而是利用通过训练获得的卷积滤波器;提出的深度学习方法使用深层神经网络,因此不依赖于RANSAC、GP-INSAC和聚集聚类等迭代算法;提出的深度学习方法将流水线减少到单一级,避免了传播错误的问题。结果表明:根据自主驾驶等应用的要求,该模型实现了非常好的精度、运行速度以及稳定性。
猜你喜欢
无线互联科技(2022年2期)2022-04-20
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
锦绣·下旬刊(2019年3期)2019-09-10
电子制作(2019年11期)2019-07-04
现代交际(2018年14期)2018-11-01
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
外语学刊(2009年3期)2009-06-04
