
面向海洋牧场智能化建设的海珍品实时检测方法
2021-08-04 05:55蔡克卫陈鹏宇林远山
农业工程学报 2021年9期
洪 亮,王 芳,蔡克卫,陈鹏宇,林远山
(1. 大连海洋大学信息工程学院,大连 116023;2. 辽宁省海洋信息技术重点实验室,大连 116023; 3. 设施渔业教育部重点实验室,大连海洋大学,大连 116023)
0 引言
海洋牧场是指利用自然的海洋生态环境,将人工放养的经济海洋生物聚集起来,像在陆地放牧牛羊一样,对海参、海胆、扇贝、鱼等海珍品资源进行有计划和有目的的海上放养,是拓展海洋渔业发展空间、促进海洋渔业可持续发展的有效措施。海洋牧场建设过程中需要进行海珍品捕捞量调查、养殖状态监测、海珍品采捕等任务,目前这些任务主要依靠人工完成,成本高,危险性大。基于水下机器人的海珍品捕捞量调查、状态监测、采捕是未来的发展方向,这些任务主要依靠水下海珍品检测技术来完成。因此,水下海珍品检测是其中的关键。
为此,国内外学者对水下海珍品检测进行广泛研究。郭常有等[1]将扇贝彩色图像通过阈值分割转变为二值图像,利用滤波技术减少图像噪声,并采用改进的OPTA算法和边界追踪算法提取扇贝图像边界,计算扇贝的位置坐标和大小。吴一全等[2]提出了一种淡水鱼种类识别方法。将形状与纹理特征组合成高维特征向量,通过人工蜂群算法的待定参数进行寻优。吴健辉等[3]提出一种基于图像处理技术的鱼种类识别方法。采用邻域边界算法对鱼体的轮廓进行提取,建立鱼体背部轮廓数学模型。采用鱼体背部弯曲潜能算法对不同种类鱼体样本的背部弯曲潜能值进行计算和聚类统计。崔尚等[4]提出基于Sobel改进算子的海参图像识别方法。将图像进行直方图均衡化处理,利用Sobel改进算子将增强后的图像进行分割处理,经过膨胀、腐蚀和小目标移除算法处理,得到含有海参目标的二值化图像。以上方法的基本思路是根据检测对象的特点利用图像处理技术设计特定算法进行识别,此类方法通常效率较高,但这些方法只针对单一品种进行检测,更重要的是需要根据领域知识进行手工特征提取,过程繁琐,工作量大,鲁棒性较差。
深度学习[5-8]具有自动特征提取的特点,大大提高了目标检测的效率和精度[9-12],推动了目标检测[13-17]在农业[18-20]、工业[21]等领域的广泛应用。为此,Li等[22]尝试使用基于改进的Faster-RCNN算法实现了12种鱼类的识别。通过使用区域建议网络,产生的高质量建议,与后续的鱼检测识别网络共享卷积特征,实现了良好的识别和检测性能。袁利毫等[23]提出基于YOLOv3的水下检测算法,利用水下机器人采集的数据对神经网络进行训练,采用小批量梯度下降法和冲量对神经网络权重进行更新,并调整算法的超参数,提高了水下小目标的识别率和检测速度。Kaveti等[24]提出了基于Inception v2的SSD检测算法实现了水下鱼类、海星和海绵的检测。利用机器人平台收集水下图像数据,建立数据标签,训练改进的算法模型,实现高精度检测。赵德安等[25]提出了基于机器视觉的水下河蟹识别方法,该方法通过在投饵船下方安装摄像头进行河蟹图像采集,修改基于YOLOv3网络的输入输出,并采用自建的数据集对其进行训练,实现了对水下河蟹的识别。郭祥云等[26]采用基于深度残差网络实现了水下海参识别算法。以海参图像为正样本,非海参图像为负样本构建数据集,以不同像素图像分别进行模型训练与识别。上述基于深度学习的海珍品检测方法的检测精度得到大幅提升,但是模型较大,难以部署到如水下机器人这种移动设备上。此外鲜有考虑水下图像模糊、对比度低、缺色等对检测所带来的检测性能影响。
为此,本文在原有YOLOv3网络结构基础上进行改进,提出了面向海洋牧场智能化建设的海珍品实时检测方法。该模型使用深度可分离卷积代替YOLOv3中的标准卷积,减少参数量,提升推理速度;针对水下图像模糊、对比度低、缺色等特点,采用基于UGAN的图像增强方法来对海珍品图像进行预处理;并且利用基于Mosaic的数据增广方法,提升图像数据的多样化,增加模型的鲁棒性。
1 海珍品检测网络框架
1.1 YOLOv3网络
YOLOv3网络结构整体框架分为两个部分:主干网络和检测器。
主干网络部分:YOLOv3采用Darknet-53作为特征提取的主干网络。由一个3×3卷积层和5个阶段的残差结构组成,每个阶段的残差结构数量分别为1、2、8、8、4。其中每个残差结构由一个3×3卷积层和残差块构成。残差块由一个1×1卷积层、一个3×3卷积层和求和运算构成。YOLOv3主干网络一方面采用全卷积结构,另一方面借鉴ResNet思想,引入了Residual结构,使网络深度增加,特征提取能力大幅增强。
检测器部分:YOLOv3网络生成三个分支,每个分支对应三种大小特征图,分别为13×13、26×26、52×52,每个分支结构由连续卷积块、3×3卷积和1×1卷积构成。其中连续卷积块由1×1、3×3、1×1、3×3和1×1连续卷积构成。经过网络计算,每个特征图会输出三个边界框,每个边界框会预测中心坐标x、y,宽w、高h、置信度和所属类别信息。
1.2 DSC-YOLO网络
为提高YOLOv3对水下海珍品检测的实时性,本文对其结构进行改进,提出一种轻量化模型DSC-YOLO,该模型采用深度可分离卷积[27]代替YOLOv3中的标准卷 积。深度可分离卷积是MobileNet采用的一种技术,其可分解为一个深度卷积和一个点卷积,如图1所示。该方法和标准卷积相比,其计算如式(1)所示。
式中M为输入特征图通道数,H、W为输入特征图的高和宽,N为卷积核个数,Dk为卷积核大小。具体地,将该技术应用到神经网络结构中,如图2所示。
在DSC-YOLO卷积结构中,图像数据先经过一个3×3深度卷积层;然后传入归一化层,加速数据收敛、防止过拟合和降低网络对权重敏感度;接着经过LeakyRelu激活函数层;输入到一个1×1点卷积层;最后经过归一化层和经过LeakyRelu激活函数层输出。
将YOLOv3中标准卷积替换为深度可分离卷积,其标准卷积的参数量是深度可分离卷积的8.88倍,如表1所示,大大降低了计算量,提高实时性。

表1 标准卷积和深度可分离卷积的参数量对比 Table 1 Comparison of parameters between standard convolution and depthwise separable convolution
1.3 基于UGAN(Underwater Generative Adversarial Network)的水下图像增强
受水体悬浮颗粒对光产生折射、散射、选择性吸收等特性的影响,摄像头采集到的水下图像存在色彩缺失、细节模糊、对比度低、噪声污染严重等问题,缺失大量有效信息的水下图像势必影响目标检测的性能。清晰的图像有助于提升检测的准确性,因此,有必要对水下图像进行增强。传统水下图像增强主要包括基于物理模型的增强方法和基于非物理模型的增强方法。前者针对模型缺陷,进行修补复原;后者针对图像的清晰度进行提高。这两种方法都需要手工特征提取。新的UGAN方法采用无监督方式,可以自动学习到训练数据样本的分布,产生新的数据。其主要思想是网络通过不断地对抗博弈,产生新的图像数据,实现从水下模糊图像到水下清晰图像的映射过程,如图3所示。本文使用UGAN对水下图像进行增强。为展示UGAN处理效果,本文从水下数据集随机选择四张具有代表水下环境特性的图像送入UGAN模型进行处理,效果如图4所示。图4中左侧图像代表了水下环境常见的图像问题,如模糊、对比度低、缺色或颜色背景等。右侧图像为UGAN增强后的对应图像。由图可见,UGAN能够对颜色进行校正,使图像更加明亮、清晰。
UGAN模型由生成网络和辨别网络构成,其整体为全卷积结构。生成网络采用Encoder-Decoder模式,在Encoder部分,由8个卷积层构成,卷积核大小为4×4,步长为2。每个卷积层后连接归一化层和斜率为0.2的LeakyReLU激活层。在Decoder部分,由8个反卷积层构成,反卷积核大小为4×4,步长为2。反卷积层后没有接入归一化层。前7个反卷积层连接ReLU激活层[28],最后一个反卷积层连接Tanh激活层。在上采样过程,每个反卷积层与对应的卷积层进行拼接输出到下一层,生成网络呈现出U形。辨别网络由5个卷积层构成,前三层卷积核大小为4×4,步长为2,第四层卷积核大小为4×4,步长为1,第五层卷积核大小为1×1,步长为1。每个卷积层后连接归一化层和LeakyReLU激活层。辨别网络采用PatchGAN设计,输出32×32×1的矩阵概率,与普通GAN的辨别网络输出的一个实数概率相比,可以获取更多的图像细节信息。
训练UGAN网络之前需要一组图像对,图像对通过CycleGAN[29]获取,把空气中图像输入到CycleGAN中,生成对应的水下环境风格图像。然后将空气中图像和水下环境风格图像作为图像对训练UGAN。生成网络接收一个水下环境风格图像和一个随机噪声,然后经生成网络生成水下生成图像,水下生成图像与对应空气中图像送入辨别网络进行辨别,若辨别为真,则返回真实标签,否则,返回生成标签。生成网络与辨别网络互相对抗博弈,直到辨别网络分辨不出水下图像是否为真实或生成图像为止。
1.4 基于Mosaic的数据增广
深度学习需要大量训练数据,而水下训练图像获取成本昂贵,有必要使用数据增广技术来生成大量训练样本[30]。目前数据增广主要有光度变换(亮度、对比度、色相、饱和度)、几何变换(随机缩放、裁剪、翻转和旋转)、图像遮挡、图像拼接等。考虑到Mosaic数据增广综合了光度变换、几何变换和图像拼接的优点,是一种集大成的方法,可以得到多样的数据格式,有望提升性能。为此,使用Mosaic方法进行数据增广。其思想是将四张传统增广的图像拼接在一起,形成一张完整图像,如图5所示。丰富了图片的背景,提升目标多样性,变相地提高了输入网络的图片数量。并且在进行批归一化[30]的时候同时计算四张图片的权值,以提升检测的性能。
具体做法是从水下数据集随机选取四张像素一致的图像,每张图像先进行传统数据增广方法,然后将增广后的图像进行随机大小裁剪,接着将第一张裁剪的图像固定在整体图像的左上角,第二张裁剪的图像固定在整体图像的左下角,第三张裁剪的图像固定在整体图像的右下角,第四张裁剪的图像固定在整体图像的右上角。最后得到一张Mosaic增广的图像,增广后的图像与原四张图像像素保持一致。
1.5 总体框架
基于上述改进方法,将三个方法结合在一起,改进的YOLOv3网络结构框架如图6所示。图中总共分为两部分:第一部分为数据预处理,第二部分DSC-YOLO网络。
数据预处理包括两部分内容:基于UGAN的图像增强、基于Mosaic的数据增广。图像增强用于提升图像清晰度与识别率,数据增广用于丰富海珍品的多样性,提升模型鲁棒性。DSC-YOLO网络减少大量标准卷积操作,减小模型大小,提升海珍品识别速度。相应地,将DSC-YOLO卷积结构应用到YOLOv3网络结构,得到改进的DSC-YOLO海珍品检测网络。在主干网络部分,将416×416图像送入网络的第一个3×3卷积替换为深度可分离卷积,同时将每个阶段的残差结构中的3×3卷积替换为深度可分离卷积。在检测器部分,将连续卷积块中3×3卷积替换为深度可分离卷积,同时将从连续卷积块输出的3×3卷积替换为深度可分离卷积。网络每个分支输出的特征图大小、Anchor数量和Anchor大小与原网络保持不变。
2 材料与方法
为了验证本文海珍品检测方法的有效性,进行了相应的试验。本节将从数据集来源、试验设置和试验环境、评估标准进行阐述。
2.1 数据集来源
本文采用“2017首届水下机器人目标抓取大赛(2017 Underwater Robot Picking Contest,URPC2017)”提供的真实水下图像数据集(http://2017.cnurpc.org/a/js/ 2017/0829/66.html)。该数据集共有三个类别:海参、海胆、扇贝,包含18 982张图像,图像分辨率为720×405,标注格式为VOC格式。
2.2 试验方法
将水下数据集随机划分成三份,其中15 182幅图像用于训练,1 900幅图像用于验证,1 900幅图像用于测试,比例约为8:1:1。在训练阶段,将DSC-YOLO、UGAN水下图像增强和Mosaic数据增广进行组合,训练得到4个模型: DSC-YOLO、DSC-YOLO+UGAN、DSC-YOLO+ Mosaic、DSC-YOLO+UGAN+Mosaic,然后将此4个模型与YOLOv3模型进行试验对比。使用预训练模型进行训练,节省时间,提高训练速度。在输入卷积神经网络前,数据集中所有图像的分辨率调整为416×416。训练时以4幅图像作为一个批次进行小批量训练,每训练一批图像,权值更新一次。权值衰减速率为0.000 5,动量为0.9,初始学习率为0.001。对网络进行110轮训练,每训练1轮保存一次模型,最终选取精度最高的模型。
本文试验采用的操作系统为Ubuntu16.04,深度学习框架为PyTorch,试验处理器为AMD Ryzen Threadripper 1920X 12核,内存为8 G,显卡为NVIDIA GeForce RTX2080,显存为8 G GDDR6。
2.3 评估标准
本文以准确率P、召回率R、多类平均准确率mAP0.5(mean Average Precision)和F1分数作为评价标准。准确率P为被正确预测的正样本数量占总预测的正样本数量的比值,如式(2)所示。召回率R为被正确预测的正样本数量占总正样本数量的比值,如式(3)所示。单类平均准确率AP(Average Precision)为准确率P与召回率R构成的P-R曲线的面积,如式(4)所示。多类平均准确率mAP0.5为当交并比(Intersection Over Union,IOU)为0.5时,准确率P与召回率R构成的P-R曲线的面积,如式(5)所示。IOU为预测框与真实框的交集与并集的比值,当预测框与真实框的IOU大于0.5,则为正样本,预测框与真实框的IOU小于0.5,则为负样本。F1分数为精确率和召回率的调和平均数,如式(6)所示。
其中,TP为模型正确预测的正样本数量,FP为模型错误预测的正样本数量,FN为模型错误预测的负样本数量,P(R)为P-R曲线函数,n为类别数量。
3 结果与分析
模型在1 900张图像测试集上,采用2.3部分所提的准确率(P)、召回率(R)、多类平均准确率(mAP0.5)、F1分数,以及推理时间(Inference time)和模型大小(Size)共6项指标,对各个模型进行评估,试验结果如表2所示。
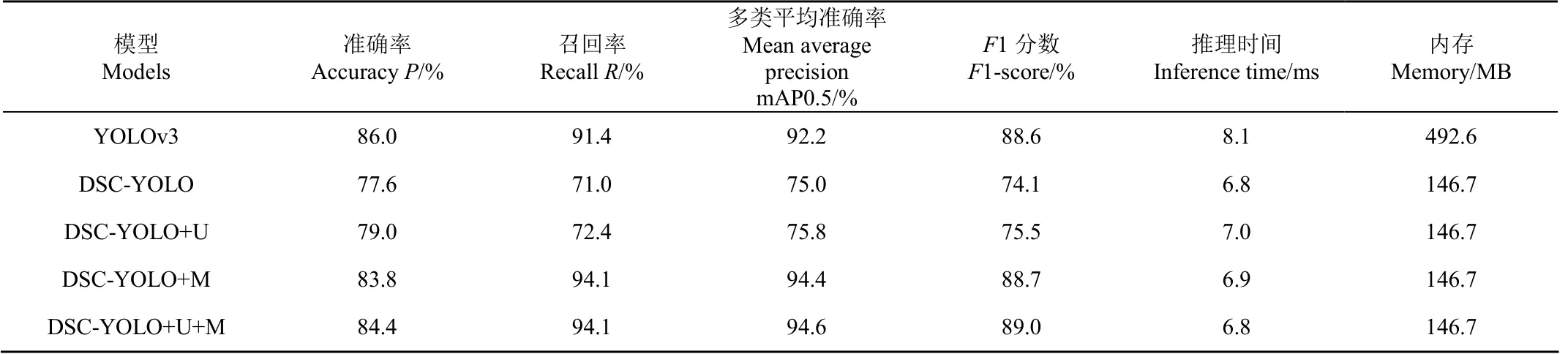
表2 模型检测性能对比 Table 2 Comparisons of model detection performance
由表2可知,在准确率P方面,YOLOv3模型为86%,DSC-YOLO+U+M模型为84.4%,仅相差1.6个百分点。在召回率R上,YOLOv3模型为91.4%,DSC-YOLO+U+M模型和DSC-YOLO+M模型同时取得了最大值94.1%,提高了2.7个百分点。
YOLOv3模型的mAP0.5为92.2%,模型大小为492.6 MB,推理时间为8.1 ms。与YOLOv3模型相比,DSC-YOLO+U+M模型大小为146.7 MB,减小约70%,推理时间缩减为6.8 ms,F1分数提升0.4个百分点,并且多类平均准确率提升2.4个百分点。
此外,除了YOLOv3模型外,采用UGAN的模型比未采用UGAN的模型,在多类平均准确率和F1分数指标上均有提升。并且采用Mosaic的模型比未采用Mosaic的模型,在多类平均准确率和F1分数指标上均有明显的提升。
综上,除了准确率P外,DSC-YOLO+U+M模型相较于YOLOv3和其他模型而言,在大幅降低模型参数量的情况下,其他各项指标都有所提升,展现出了优越的性能,模型检测效果如图7所示。
此外,试验中发现,本文模型对漏标的图像数据具有较强的鲁棒性,能够将图像中漏标的海珍品检测出来。本文随机从测试集中选择三张存在漏标现象的数据,如图8所示。图像8a中4个海参、5个海胆未标注,图8b中1个海参、3个扇贝未标注,图像8c中3个海参、1个海胆、6个扇贝未标注。其他模型均存在不同程度的漏检,而本文的最终模型DSC-YOLO+U+M将未标注数据正确检测出来。
根据上图模型检测数量统计模型的漏检率,如表3所示。其中漏检率计算是模型未检测到的目标个数除以实际标注和漏标数量总和。由表3可知,本文提出的方法漏检率数值最低,综合来说,本文提出的模型在数据集漏标的情况下,能够将漏标的海珍品正确地检测出来,鲁棒性良好。

表3 模型漏检率对比 Table 3 Comparisons of the model missing rate
4 结 论
本文提出了基于改进的YOLOv3网络的海珍品检测框架,该框架在训练阶段之前引入图像增强和数据增广方法用于提升图像清晰度和检测性能。然后采用深度可分离卷积,将标准卷积分解成深度卷积和点卷积,使参数量和计算量大大减少,推理速度缩短,模型大小缩减。在推理速度和准确率方面得到提高的同时,从定性和定量角度分析各个模型的性能。试验证明,改进的YOLOv3网络模型与图像增强和数据增广方法相结合,性能优于YOLOv3模型。
1)本文通过改进模型,使得模型参数量和计算量减少,模型占用内存大小为146.7 MB,YOLOv3网络模型占用内存大小为492.6 MB,模型占用内存减小70%。加入图像增强和数据增广方法,不增加模型参数量和计算量的同时,提高检测性能。
2)根据定性和定量结果比较,在网络训练之前采用基于生成对抗网络的图像增强方法,提升了图像的清晰度和检测的准确率,检测的目标更多,更全面,使得召回率提升2.7个百分点。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年11期)2019-07-04
福建基础教育研究(2019年6期)2019-05-28
