
谷物联合收割机油耗随机森林预测模型
2021-08-04 05:55杨丽丽田伟泽徐媛媛吴才聪
农业工程学报 2021年9期
杨丽丽,田伟泽,徐媛媛,吴才聪
(中国农业大学信息与电气工程学院,北京 100083)
0 引言
车辆燃油消耗的研究在车辆使用成本分析,环境治理等方面具有重要意义[1-2]。影响车辆的燃油消耗的因素大致可以分为四类:车辆行驶工况(加速、减速、发动机工况等)、道路状况、天气、车辆自身特性[3-6]。
研究表明车辆不同的行驶工况会导致±25%燃油消耗差异[7]。目前在城市交通领域,基于行驶工况进行油耗预测的研究较多。候亚美等[8]基于平均速度、交叉口密度、停驶比等数据构建了后向反馈(Back Propagation, BP)神经网络模型预测城市道路出租车油耗。赵晓华等[9]根据出租车在北京80个快速基础路段上的平均速度及加速度衍生出16个指标,经过主成分分析,建立了BP神经网络的城市快速路出租车油耗预测模型。Xu等[10]基于卡车在125个高速公路和主干道路段内的平均行驶速度及加速度,定义了能耗指标,描述了油耗与速度及加速度之间的动态关系。Wickramanayake等[11]根据上行下行时道路坡度相反的条件,分别构建了梯度增强树、随机森林、神经网络的3种长途公交车油耗预测模型。张登等[12]根据多种车身静态数据,包括车型、车长、质量、发动机最大功率等,建立了适用于多种车型的油耗预测模型。上述研究基本上是基于结构化道路对油耗与行驶工况的研究,然而无论是静态数据预测出的标准油耗还是考虑了实际行驶工况的预测油耗,因模型中车型或者路况相对确定,都难以直接迁移到农机中。
相比于城市交通领域,车辆燃油消耗在非道路车辆领域特别是农用车辆,国内外研究较少。随着中国农业机械化水平的不断提高,农业机械的保有量在不断的增加,根据国家统计局数据显示2019年中国农机总动力为10.27亿kW,总量近2亿台套[13]。农业机械对化石燃料的消耗也不断增长。预估农机工作时的燃油消耗对于环境治理,农机合作社成本投入,机手驾驶技术评价,燃油监管等有着十分重要的实际意义[14]。农机工作环境移动通信网络较差,GNSS数据回传不及时,农机转场时田间路况复杂多变,农机油耗存在和其所从事生产工作类型密不可分的问题。罗红旗等[15]根据旋耕深度、旋耕宽幅、车辆前进速度3个因素构建了回归方程用于玉米免耕播种机油耗预测,但收割作业相比于播种作业更加复杂,收割机作业时的发动机转速、发动机扭矩、加速度、收割机负载等因素对燃油消耗均有影响,因此此方法并不适用于收割机。相比于城市道路车辆,影响农业车辆燃油消耗因素相对复杂,单纯基于速度及加速度的行驶工况不能对车辆燃油消耗进行准确预测。
本文以2020年沃得4LB-150AA型号谷物联合收割机为研究对象,采集田内连续工作时的收割机行驶工况数据、发动机工况数据,提取出与油耗相关的特征,基于随机森林方法构建谷物联合收割机实时作业油耗预测模型。试验结果表明,模型输出具有较高准确率。
1 数据来源与处理
1.1 数据来源
农机实际工况下的数据采集是基于精准农业应用项目数据服务平台的2020年22辆谷物联合收割机全年工作数据,筛选农机型号为沃得半喂入式4LB-150AA型谷物联合收割机的记录。采样平均间隔1.3 s,共计130 788条记录。原始数据包括采集自CAN总线的发动机转速、发动机扭矩、发动机机油压力、瞬时油耗及同一时间采集自GNSS终端的瞬时速度、经度、纬度。
1.2 数据预处理
收割机短时间段内的行驶工况数据可以更好反映收割机作业状况,因此本文将采集的数据按照20~60 s的时间步长进行随机步长分组,共计320组。根据瞬时数据对农机工况进行统计如表1所示。

表1 农机工况统计量 Table 1 Statistics of agricultural machinery conditions
由表1可知,农机工作速度范围在0~6.0 km/h,数据中存在扭矩和油耗为0的值,与数据采集时农机正在作业不相符,因此作为异常值进行处理。同时,各项数据范围及单位不统一,建模之前需要对输入特征进行无量纲化处理。本文定义以下数据预处理规则:
规则一:通过插值清除扭矩和油耗的异常值,见式(1):
式中lt为t时刻的异常值;lt+1为t+1时刻的正常值;lt-1为t-1时刻的正常值。
规则二:采取标准化对数据进行无量纲化。将数据按均值中心化后,再按照标准差进行缩放,使各项数据均满足均值为0,标准差为1,服从正态分布。见式(2):
式中X′为无量纲化后的特征数据;X为原始特征数据;u为该特征均值;σ为该特征的标准差。
为区分采集原始数据集中的收割机工作省份,根据车辆工作时的经纬度坐标采用反向地理编码计算,得到22辆收割机数据分别来自辽宁、吉林、山东、江苏、湖北、浙江6个省份,对省份名称标签数字化。
1.3 指标定义
影响收割机燃油消耗的因素众多,参考国内外汽车工况的指标选取[16-19],本文基于采集的原始收割机瞬时工况,衍生出7个与油耗相关的指标。指标定义如下所示:
1)平均速度、发动机扭矩均值、发动机转速均值:
式中Xi分别代表第i秒农机速度(km/h);发动机扭矩(N·m)和发动机转速(r/min);T为单个组内的总时长,s;f(X)表示在Xi取值不同时分别对应的平均速度Vmean(km/h)、平均扭矩Nmean(N·m)和平均转速Smean(r/min)。
2)加速度均值,减速度均值:
式中ai+为单个组内第i秒车辆加速度,m/s2;Ta+为单个组内加速时长,s;a+mean为单个组内加速度均值,m/s2;ai+为单个组内第i秒车辆减速度,m/s2;Ta-为单个组内减速时长,s;a-mean为单个组内减速度均值,m/s2。
3)加速度方差,减速度方差:
式中Sa+为单个组内加速度方差,m/s2;Sa-为单个组内减速度方差,m/s2;其他变量定义同式(4)。
2 油耗预测模型构建
2.1 油耗影响因素分析
2.1.1 影响因素分析方法
为了找出1.3中所定义的指标与收割机油耗之间的相关性,并剔除与油耗不相关的指标,先进行单一指标对油耗影响的分析,然后通过斯皮尔曼相关系数分析各个指标与油耗之间的相关性。
斯皮尔曼相关作为一种常见的基于滤波器的特征选择方法,广泛的应用于度量两个变量之间的相关性[20],其计算方法如下所示:
式中rk为第k个指标与油耗的相关系数;n为样本容量;dkj为第k个指标与油耗之间的等级差;j为第k个指标中的样本下标。
2.1.2 油耗影响因素分析结果
1)单一指标对油耗的影响
收割机作业速度与该速度下对应的平均油耗关系如图1所示。图2统计了320组发动机工况及行驶工况与该工况下对应的油耗。
由图1可知,当收割机作业速度在0~2 km/h范围时,油耗随着作业速度的增加增幅相对较小,当收割机作业速度从2 km/h升至5 km/h时,显示油耗随着作业速度上升急剧上升,车辆行驶时车速与发动机功率大致呈现三次方关系[21],此阶段车速增加缓慢但是功率会迅速增大,进而导致油耗急速增加。图中当车速大于5 km/h时油耗会随着车速的增加略微下降,考虑到农作物的长势对收割机作业速度的影响较大[22],通常农作物长势稠密、植株高、产量高时收割机作业速度在3~5 km/h。收割机速度在5~6 km/h时,一般对应于2档作业,此时往往在收获比较干燥、稀疏的农作物,这时发动机负荷较低,燃油消耗较低。
由图2可知,随着发动机转速和发动机扭矩的增加,收割机油耗也会随之增加,其中扭矩数据虽然有一部分的离群点,但是总体上依旧具有较强的相关性,收割机在作业时较大的加速度与减速度也会增加燃油消耗,因此在收割作业时应尽量避免急加速、急减速或者尽量保持匀速作业会更加有利于节油降耗。
2) 区域收割机田间作业油耗差异分析
研究表明不同区域的农机作业方式及油耗存在较大差异[23-24],根据中国现有的农业区划[25],结合地形地貌,本文将辽宁、吉林、山东、江苏、湖北、浙江6个省份划分为东北地区(辽宁、吉林)、平原地区(山东、江苏,包括华北及长江中下游平原地区),丘陵地区(湖北、浙江)三个区域。数据量共计130 788条,其中各省份数据均不少于12 000条。参考国家统计局谷物单位面积产量数据[26],三个区域的平均油耗及谷物单位面积产量统计结果如图3所示。
从图3可以看出单位面积产量最高的东北地区收割机作业时平均油耗明显高于其他两个地区,随着单位面积产量的下降,收割机平均油耗也呈现出下降趋势。单位面积产量越高,收割机作业时发动机负荷越高,进而导致油耗偏高。单位面积产量和收割机平均油耗有一定的相关性。
3)各指标与油耗的相关性分析
各指标与油耗的相关系数如表2所示。

表2 指标与油耗之间的相关系数 Table 2 Correlation coefficient between index and fuel consumption
由表2数据可以看出本文中所选取的指标与油耗显著相关(P<0.01),其中发动机平均扭矩、平均转速、行驶平均速度与收割机油耗相关性较高,相关系数在0.6以上。其次是加速度均值、减速度均值、加速度方差、减速度方差这些与行驶工况相关的指标,相关系数在0.4以上。从相关系数的计算结果中也可以证明结合发动机工况数据对于预测收割机燃油消耗会更加准确。
2.2 随机森林模型的构建
本文基于Python3.7语言和Sklearn0.23.1机器学习库构建了随机森林模型,电脑运行内存为16G。将表2中的指标数据作为油耗预测模型的输入特征,并将输入特征及真实油耗y一同进行无量纲化处理,将320组数据按照8:2的比例分割为256个训练数据样本和64个测试数据样本。为保证预测模型的准确性和稳定性,对训练集做了10折交叉验证,采用网格搜索的方法找出模型最优参数。
随机森林是典型的集成学习算法,装袋法的代表模型[27-28]。其弱学习器为 CART(Classification and Regression Trees)决策树模型。
决策树的数量对油耗预测精度的影响最大,决策树数量太少,预测误差会变大,决策树数量太多,计算量会剧增,当决策树到达一定数量后,预测精度提升会很少。基于随机森林的油耗预测模型中决策树的数量与模型平均绝对误差及模型训练时长的关系曲线如图4所示。
从图4可以看出当决策树数量为150后,决策树数量继续增加,平均绝对误差曲线趋于平缓,但模型训练时长持续增加,因此决策树数量为150较为合适。
基于随机森林的油耗预测模型结构如图5所示,通过对256个训练集进行有放回的随机采样,构建出150个采样集,每个随机采样集大约包含167个训练样本,基于150个采样集构建150棵决策树作为油耗预测模型的弱学习器,决策树的每个结点包括n个样本,进行分裂时随机选择k个样本构成一个特征子集X′(对油耗有影响的特征向量),通过特征子集X′进行结点分裂,每个结点可以分裂为R1(q,s),R2(q,s)两个新的结点。其中q为X′中影响油耗的指标,s为结点分裂阈值,s的目标函数为
式中yl为第l条记录的真实油耗,L/h;xl为第l条记录中影响油耗的特征向量;c1为R1结点中真实油耗的平均值,L/h;c2为R2结点中真实油耗的平均值,L/h。回归决策树通常会导致偏差较小,方差偏大,使得油耗预测模型在训练集上产生过拟合现象,所以需要对建好的决策树稍加控制。本文采用较为常见的控制策略,对树的深度h、每个结点包含的最少样本数N、分裂一个结点需要的最小样本数m加以限制,通过网格搜索的方法找出h为21,N为2,m为2,相比于不加控制,油耗预测误差降低了0.01。随后对150棵决策树的油耗预测结果求解算术平均值作为最终预测结果。
2.3 模型性能评价
支撑向量机作为一种有监督的学习方法,在油耗预测研究中有较多应用,并且有较高的预测精度[29-31],因此为验证通过发动机工况数据及行驶工况数据构建基于随机森林的油耗预测模型的高效性,本文将基于支撑向量机的油耗预测模型[29-31]作为对比方案进行参考。
为了评价2种模型对油耗的预测准确性,本文比较了3种指标,分别为均方根误差RMSE、平均绝对误差MAE、决定系数R2,3种评价指标计算方式如下所示
式中yu′为测试样本中第u个预测油耗,L/h;yu为测试样本中第u个真实油耗,L/h;n为样本数量;为真实油耗的平均值,L/h。
3 结果与分析
两种模型的油耗预测输出与真实油耗关系如图6所示。其中A+B类型的点表示使用表2中全部指标进行油耗预测时模型的预测输出,A类型的点表示单独使用表2中A类指标对油耗进行预测时模型的预测输出,从图6可以看出加入发动机工况(B类)数据后,两种模型的油耗预测值与真实值的数值相似,并且要比单独使用A类数据进行油耗预测误差更小。模型的3种指标计算结果如表3所示。
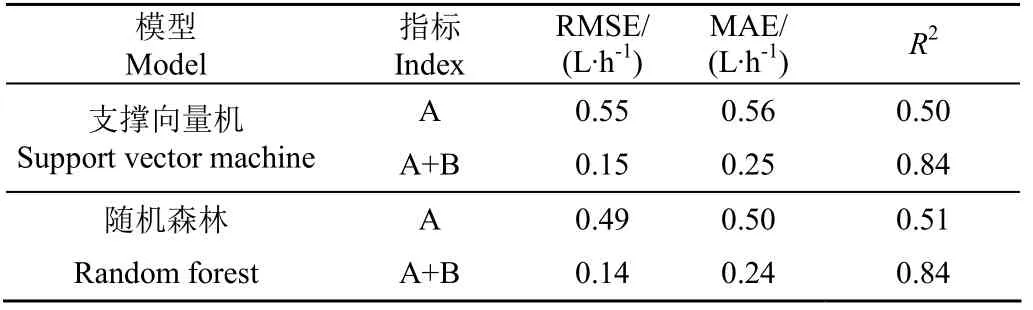
表3 基于不同模型和指标评估结果 Table 3 Results for model evaluation based on different models and indices
从表3中可以看出,支撑向量机和随机森林两种油耗预测模型在加入发动机工况数据训练后,3种评价指标的数值均明显变优,均方根误差分别为0.15和0.14 L/h,平均绝对误差分别为0.25和0.24 L/h,R2均大于0.5,R2最大值为0.84,说明两种模型均可以准确预测收割机燃油消耗,但基于随机森林的油耗预测模型无论是否使用发动机工况数据油耗预测误差均是最小的。
4 结 论
本文根据谷物联合收割机作业时的行驶工况数据及发动机工况数据,确定了与油耗相关的7个关键指标,基于斯皮尔曼相关系数分析了各个指标与油耗的相关性,其中平均转速、平均扭矩、平均速度与油耗的相关性较高,其次是加速度均值、减速度均值、加速度方差、减速度方差。通过大量数据的统计分析发现不同区域收割机作业的燃油消耗存在差异,并且和区域单位面积产量相关性较高。
本文选取7个指标并结合省份信息构建基于随机森林的油耗预测模型,并与支撑向量机模型进行对比。结果表明,两种模型均能够准确的预测燃油消耗,但基于随机森林的油耗模型预测误差更小,均方根误差为0.14 L/h。
本文以谷物联合收割机油耗为研究对象,在未来研究中,会考虑更多类型的农业机械,并将综合考虑多种地形、多种天气下的油耗,为农机的工况优化及精准油耗监管提供参考。
猜你喜欢
快乐作文(1.2年级)(2020年10期)2020-09-10
农民致富之友(2020年20期)2020-07-18
科学与信息化(2019年28期)2019-10-21
车迷(2018年12期)2018-07-26
农民致富之友(2018年7期)2018-05-04
车迷(2017年12期)2018-01-18
创新作文(3-4年级)(2016年5期)2017-05-16
科学与财富(2016年32期)2017-03-04
消费者报道(2014年13期)2015-03-19
决策与信息·下旬刊(2013年1期)2013-03-11
