
基于特征优化和改进长短期记忆神经网络的NOx质量浓度预测
2021-08-03 08:31:12金秀章
热力发电 2021年7期
刘 岳,于 静,金秀章
(华北电力大学控制与计算机工程学院,河北 保定 071003)
随着大气污染问题日益严重,我国对燃煤机组NOx的排放要求也日益严格[1]。目前火电厂常用的烟气脱硝技术是选择性催化还原(SCR)脱硝技术,该技术设备结构简单,脱硝效率高。但电厂运行工况复杂多变,SCR设备入口烟气NOx含量波动频繁,使得脱硝过程喷氨量难以控制。当喷氨量过少时,NOx排放超标;喷氨量过多时不仅影响脱硝效率,还会腐蚀设备影响锅炉正常运行。因此,建立精准有效的入口NOx排放量预测模型,可为喷氨量的优化控制提供理论基础,对提高SCR烟气脱硝系统控制品质、减少电厂脱硝成本具有重要意义[2]。
燃煤机组NOx的产生受到多种因素如燃烧温度、一次风量、总煤量等影响,这些变量相互耦合,导致难以建立准确的 NOx排放量的预测模型。近年来,随着机器学习发展,许多建模方法被提出并应用于NOx排放量的预测。Zhou等人[3]采用支持向量机(SVM)建立了锅炉NOx排放量的预测模型。王博等[4]在SVM的基础上提出了一种基于支持向量回归(SVR)的预测模型,提升了模型的稳定性。Li等人[5]利用改进的粒子群(PSO)算法对SVM模型进行参数优化,提高了NOx排放量预测模型的精度。此外,神经网络也被广泛应用于NOx预测模型建立。谷丽景等[6]利用人工神经网络对NOx的排放进行了建模预测。李忠鹏等[7]利用寻优算法优化了BP神经网络参数,建立了更加精确的BP神经网络预测模型。周洪煜等[8]对传统的RBF神经网络进行了改进,通过引入混结构隐含层,改善了传统RBF神经网络变工况控制时的非线性和扰动适应能力。虽然人工神经网络拟合能力较强,但仍存在结构复杂、易陷入局部收敛等问题。长短期记忆(LSTM)神经网络是近年来新兴的一种循环神经网络,能够对数据进行长期记忆,在时序数据处理上具有独特优势。杨国田等[9]利用LSTM神经网络对NOx的排放建立了预测模型,钱虹等[10]将LSTM神经网络与深度学习相结合,提高了预测模型的泛化能力和收敛速度。
除建模方法外,输入变量的选取也直接影响预测模型的精度。吕游等[11]采用偏最小二乘方法对输入变量进行特征提取以降低维数和消除相关性,唐振浩等[12]采用LASSO选择算法分析变量的重要性,并利用经验模态分解(EMD)对信息进行特征提取,防止模型过拟合。Peng等人[13]将基于概率密度的互信息法引入非线性建模中,用于估计输入变量与输出变量的时延,提高了模型泛化能力。上述方法均从输入侧进行分析处理,并未考虑输出侧历史数据的影响。
综上所述,本文提出了一种基于特征优化和改进LSTM神经网络的SCR脱销入口NOx质量浓度预测模型。通过互信息算法确定变量之间的最佳延迟时间。通过mRMR算法对各个输入变量进行选择,以模型的精度作为评价函数,确定预测模型的最优输入变量。通过网格搜索算法和改进粒子群算法对LSTM神经网络进行参数寻优,建立SCR脱硝入口NOx质量浓度的预测模型,并加入出口NOx质量浓度历史数据。经实验证明,改进后的预测模型与经典预测模型相比预测精度更高,能够满足实际生产的需求。
1 样本特征优化
1.1 互信息和mRMR算法原理
在建模时,选取合适的数据可以体现输入和输出之间的关系,提高预测模型的精度。一般情况下都是选取与输出变量之间具有强相关性的变量,但是不同的输入变量之间可能也具有强相关性,此时输入集就产生了冗余变量,冗余变量会增加模型的复杂度,降低建模效率[14]。为此,提出了一种基于互信息的最大相关最小冗余特征选择算法。
互信息可以描述2个变量是否有关系,以及关系的强弱[15]。2个变量x、y互信息I(x;y)的公式为

式中,p(x)和p(y)分别是x和y的边缘概率分布函数,p(x,y)表示x和y的联合概率密度函数。
mRMR算法是一种filter特征选择算法,在保证特征子集最大相关性的同时又去除了冗余特征。其评价函数为
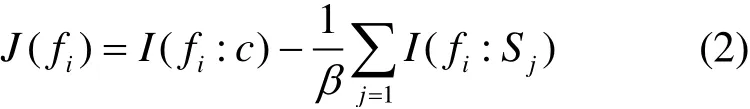
式中,fi为待选的输入变量,c为输出变量,Sj为已选变量,β为惩罚因子。
当惩罚因子较大时特征集的冗余性会降低,但会影响输入特征集对输出变量的相关性。文献[15]提出采用已选特征集的特征数量作为惩罚因子,充分考虑了已选变量集对候选变量的影响。此时mRMR的评价函数为

1.2 基于互信息和mRMR的特征优化
输入变量特征选择的算法流程如下:
1)初始化已选输入变量集合S(此时为空集),初始化待选输入变量集f(包含全部的变量)。
2)采用序列前向选择算法,首先从集合f中选出与输出变量相关性最大的变量作为初始变量加入S中,从剩下的变量中依次选取1个变量加入集合S中,通过式(2)计算评价函数J,选取J最大时对应特征变量为第2个加入集合S的特征变量。
3)通过上述方法依次确定各个特征加入集合的顺序,从而完成对初始变量的重要性排序。
4)在对各个变量进行重要性排序后,还需要确定输入变量的具体个数。由于RBF神经网络具有很强的非线性映射能力,能够反映不同的输入变量对输出的影响。因此,通过将不同特征子集输入RBF神经网络模型进行训练并预测,将预测结果作为评价函数,进而确定一组最佳的输入变量。
2 MPSO-LSTM网络预测模型
2.1 LSTM神经网络
长短期记忆神经网络(LSTM)是一种特殊的循环 神 经 网 络(RNN),它 由Hochreiter &Schmidhuber[16]1997年提出,并由Alex Graves[17]进行了改良和推广。RNN是一类能够处理序列数据的神经网络,它通过在神经网络结构中增加循环链接,因而具有短期记忆能力,可以用来处理序列数据。但RNN在处理长期依赖(即时间序列上距离较远的节点)时会遇到巨大的困难,会产生梯度消失或者梯度爆炸的问题,LSTM神经网络在RNN的基础上增加了输入门限、遗忘门限和输出门限,使得不同时刻的积分尺度可以动态改变,避免了梯度消失或者梯度爆炸问题。LSTM神经网络结构如图1所示。

图1 LSTM神经网络结构示意Fig.1 Schematic diagram of the LSTM structure
LSTM神经网络由多个图1这样的模块组成,图1中ht–1为上一个细胞层的细胞状态,yt–1为上一个细胞层的输出,xt为外部输入,3个σ表示sigmod函数,分别对应于LSTM神经网络的遗忘门、输入门和输出门,3个门共同合作,控制和保护细胞的状态,tanh层用来产生新的细胞状态值[18]。
LSTM神经网络的细胞单元更新过程如下:
1)细胞中第1个σ对应LSTM神经网络中的遗忘门,它决定了从细胞状态中丢弃的信息,遗忘门的计算公式为

2)第2个σ对应LSTM神经网络输入门,其对细胞状态中的信息进行更新,输出门计算为:

3)输出门输出细胞状态值,其计算公式为:
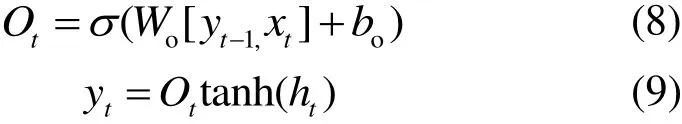
式中,W为各个门的权重系数,b为偏差。
2.2 改进PSO算法
为了提高预测模型的精度,需要对LSTM神经网络的参数进行优化,PSO算法是一种应用较广的群体智能算法,该算法源自对鸟类捕食问题的研究。它采用速度-位置搜索模型。每个粒子代表解空间的1个候选解,解的优劣程度由适应度函数决定,而适应度函数根据优化目标定义。PSO算法中粒子更新自身的速度和位置的计算公式为:

式中,V为速度,c1和c2为学习因子,r1、r2为随机数,w为惯性权重,X为粒子的位置[19]。
目前PSO算法主要存在以下问题:
1)在迭代早期可能出现最优解导致种群陷入局部最优,降低粒子的多样性。
2)由于惯性权重w固定不变,导致粒子种群的全局和局部的搜索能力不平衡,降低算法的搜索效率。
基于上述问题,本文提出了一种改进的PSO(MPSO)算法。根据文献[20-22]可知,惯性因子w较大时算法的全局搜索能力强,有利于增加种群的多样性;w较小时,算法的局部搜索能力强,能够加快算法的收敛。因此将w设置为随迭代次数递减,递减函数通过比较效果得出。最终得到惯性因子的计算公式为

式中:t为当前迭代次数,tmax为最大迭代次数,w的上下限分别设置为0.9和0.4。

MPSO算法流程如下:
1)对种群中每一个粒子进行位置和速度的初始化,计算每个粒子的适应度值,并初始化Pbest和
gbest。
2)在迭代过程中,通过计算适应度值,对粒子种群的个体最优Pbest和总体最优gbest进行更新。
3)当迭代少于一定次数时,判断每个粒子是否满足Pbest<pbest,若满足,则对粒子进行变异操作,重置粒子的速度和位置,对其他粒子则按式(10)和式(11)进行更新。
2.3 基于MPSO-LSTM网络的预测模型
将特征优化后的数据作为模型输入变量,改进LSTM网络作为预测模型,图2为总体算法流程。

图2 基于MPSO-LSTM网络的预测模型算法流程Fig.2 Flow chart of the algorithm for MPSO-LSTM pridiction
3 实验设计与结果分析
3.1 数据选取与处理
本文采用保定某600 MW电厂所提供的现场运行数据。该电厂采用选择性非催化还原(SNCR)和SCR联合脱硝的方式,通过向锅炉与SCR反应器之间的烟气管道喷洒尿素溶液,对烟气中NOx进行初步脱硝处理。
为验证模型的有效性,在负荷420~510 MW工况下,选取包括稳定工况和变工况数据共6 000组,其采样周期为5 s。其中前5 000组用来对预测模型做训练,后1 000组作为测试集检验模型的预测精度与泛化能力。通过分析NOx的生成机理确定包括机组负荷、总煤量、总风量、管道尿素流量、二次风量、给煤机电流等24个初始辅助变量。
由于锅炉燃烧具有大迟延的特性,采集到的数据与入口NOx质量浓度具有时间延迟,因此设计了一种基于最大互信息的时延分析方法。由于锅炉燃烧时间约10 min,所以设计时间延迟最大为10 min。通过计算辅助变量前10 min内各个时刻与输出变量NOx质量浓度的互信息,进而选取与入口NOx质量浓度相关性最大的时刻作为时间延迟补偿值,实现输入变量与输出变量的时序统一。表1为辅助变量与输出变量之间的最佳延迟及其互信息值。

表1 辅助变量的时间最佳延迟及其互信息值Tab.1 The time delay and maximum mutual information of auxiliary variables
在确定时间延迟后,还要对选取的辅助变量进行筛选。首先通过mRMR算法寻找不同输入变量的最优组合,再利用RBF神经网络预测模型分别对不同的最优特征组合进行训练和预测。通过比较预测误差,确定了11个辅助变量为模型的输入变量。
经过文献[23]证明,在输入变量中加入历史入口NOx质量浓度,可以显著提高LSTM神经网络预测模型的精度。为了确定最佳历史时间,分别选取前5、10、15、20 s的入口NOx质量浓度作为输入变量,与上述11个辅助变量共同加入预测模型中进行训练和预测,其预测结果见表2。

表2 不同输入变量下的模型预测误差Tab.2 The model prediction errors with different input variables
通过比较预测效果,最终确定将前5 s的入口NOx质量浓度作为最终的输入变量。
3.2 模型参数选取
利用LSTM神经网络搭建预测模型,网络的超参数通过寻优算法确定。由文献[23]可知,影响LSTM神经网络的重要参数主要为隐含层神经元数、最大迭代次数和初始学习率。对于隐含层神经元数和最大迭代次数,经实验证明,当迭代次数和隐含层神经元数过大时,预测模型的精度反而会降低,因此利用网格搜索算法进行参数寻优。对于初始学习率则通过2.2节的MPSO算法进行参数寻优,并以LSTM神经网络模型的预测误差作为适应度函数,最终确定LSTM神经网络的隐含层神经元数55,最大迭代次数250,初始学习率0.004 4。
3.3 模型评价指标
本文采用的模型评价指标为均方根误差δRMSE、平均相对误差δMAPE和皮尔逊性关系R,其计算公式为:

式中,yi为实际值,为预测值,n为测试集样本数量,σ表示方差,cov表示协方差。
3.4 实验结果分析
3.4.1 不同预测模型对实验结果的影响
为了比较LSTM神经网络模型的预测特点,分别利用RBF神经网络和LSSVM搭建了预测模型。RBF神经网络是一种拟合能力很强的前馈神经网络,LSSVM是一种基于SVM的改进算法,这2种方法在建模方面具有代表性,将LSTM神经网络模型与它们对比可以体现LSTM预测模型的特点。
本次实验通过MPSO算法确定了RBF神经网络和LSSVM预测模型的最优超参数,在输入变量和其他条件保持一致条件下,3种模型预测结果如图3所示,3种模型各评价指标结果见表3。由图3和表3可见:LSTM神经网络预测模型均方根误差比LSSVM模型降低了18%,比RBF神经网络模型降低了29%;LSTM神经网络平均相对误差比LSSVM模型降低了25%,比RBF神经网络模型降低了24%。在相关性方面,LSTM神经网络模型与真实值的相关系数最大,LSSVM模型次之,RBF神经网络模型最低。
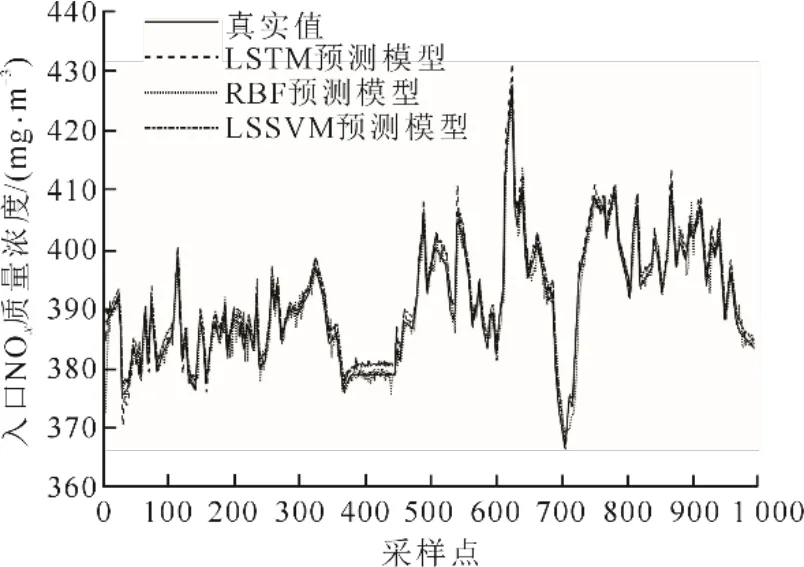
图3 3种模型预测效果对比Fig.3 The prediction results of each model

表3 3种模型评价指标Tab.3 The evaluation indexes of different models
为了更好地比较3种预测模型的特点,分别挑选不同时段进行放大,放大后测试集1和测试集2预测结果分别如图4和图5所示。
由图4和图5可见,在其他条件一致的情况下,RBF神经网络模型预测结果震荡严重,LSSVM模型预测效果稳定,但都没有LSTM神经网络模型接近实际值,充分证明了LSTM神经网络在建立NOx质量浓度预测模型上具有更高的精准度和更好的预测能力。

图4 测试集1预测结果Fig.4 Prediction results of test set 1
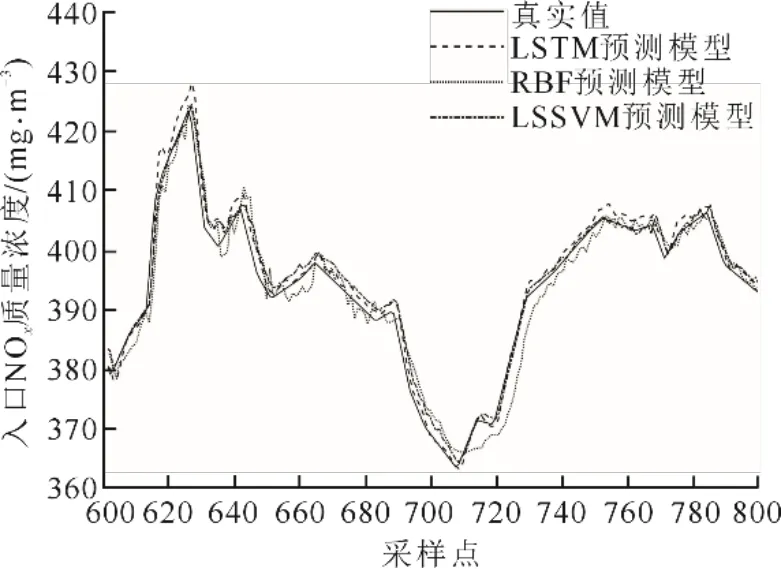
图5 测试集2预测结果Fig.5 Prediction results of test set 2
3.4.2 特征优化对实验结果的影响
本文通过对数据进行时延分析,确定了输入变量与输出变量之间的最佳延迟时间。通过特征选择算法选出最优特征子集。为了研究特征优化对LSTM神经网络模型的影响,分别利用不加时延和包含所有辅助变量的特征集数据对LSTM神经网络模型进行训练和预测,其他条件保持不变,得到对不同特征选择下的预测结果和不同特征训练集评价指标对比如图6和表4所示。

图6 不同特征选择下的预测结果Fig.6 Prediction results with different feature selections

表4 不同特征训练集评价指标比较Tab.4 The evaluation indexes of different feature training sets
由图表6和表4可见:经过时延分析的数据比未经过时延分析的数据均方根误差降低了26%,时延分析可以提升模型的精度。经过特征优化的数据比未经特征优化的变量均方根误差降低了50%,说明当输入变量较多时,由于冗余变量的存在,降低了模型的泛化能力,导致模型在测试集上的效果较差。时延分析和特征优化有效提升了预测模型的精度和泛化能力。
3.4.3 历史入口NOx质量浓度对实验结果的影响
为了研究历史入口NOx质量浓度对不同预测模型的影响,分别在输入变量中加入和去除前5 s的历史入口NOx质量浓度数据,利用LSTM神经网络、LSSVM和RBF神经网络预测模型进行实验,历史数据对3种预测模型结果对比及其评价指标如图7和表5所示。

图7 历史数据对3种预测模型影响结果对比Fig.7 Effect of historical data on prediction results of the above three models
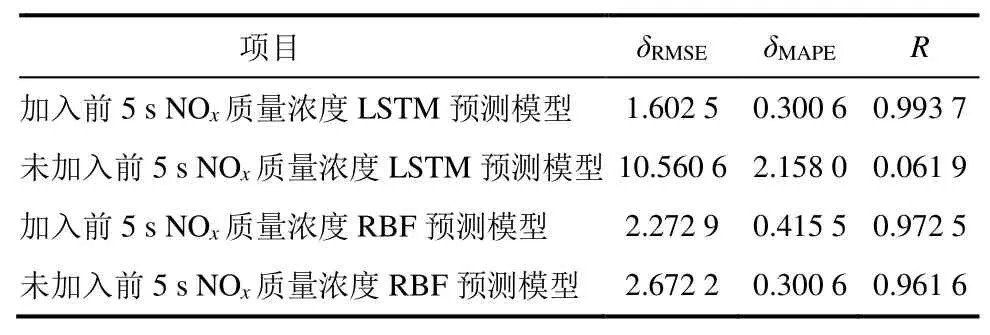
表5 历史数据对3种预测模型影响评价指标Tab.5 The prediction results of the above three models when considering the historical data
由图7和表5可见:LSTM神经网络模型加入1个前5 s的NOx质量浓度其均方根误差降低84%,而常用的RBF神经网络模型只能降低15%,说明LSTM神经网络能够对历史数据进行记忆。由于电厂NOx质量浓度数据在时间前后上具有一定的重复性,通过LSTM神经网络独特的记忆功能,可以从数据中挖掘出更多的信息,从而构造出精确的NOx质量浓度预测模型,相比于常见的预测模型,LSTM神经网络在预测时间序列数据时具有明显的优势。
4 结 语
本文针对SCR反应器入口处NOx质量浓度波动频繁、难以准确测量的问题,提出了一种基于特征优化和改进LSTM神经网络的预测模型。基于现场运行数据的实验结果表明,经特征优化后的输入变量,去除了冗余变量,提高了模型的泛化能力。基于互信息的时延分析,加强了输入变量与输出变量间的对应关系,有效提升了模型精度。采用LSTM神经网络建立预测模型,由于LSTM神经网络具有长期记忆的功能,在输入变量中加入历史入口NOx质量浓度,可以进一步提升模型的预测精度,最终在入口NOx质量浓度预测上取得较好效果,为以后建立预测模型提供了一种新的思路。此外,由于在输入变量中加入了前一时刻的NOx质量浓度,所以限制了预测模型在实际生产中的应用,下一阶段需考虑将模型预测输出作为下一次预测的输入变量,以满足实际生产的需求。
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
河北理科教学研究(2020年2期)2020-09-11 06:15:48
电子制作(2019年19期)2019-11-23 08:42:00
重型机械(2016年1期)2016-03-01 03:42:04
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
西北工业大学学报(2015年4期)2016-01-19 03:31:47
大连工业大学学报(2015年4期)2015-12-11 04:06:52
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
电测与仪表(2015年9期)2015-04-09 11:59:22
弹箭与制导学报(2015年1期)2015-03-11 15:32:31
