
基于颜色和形状的鲜茶叶图像特征提取及在茶树品种识别中的应用
2021-08-02 15:54刘自强周铁军傅冬和彭华
江苏农业科学 2021年12期
刘自强 周铁军 傅冬和 彭华


摘要:对鲜茶叶颜色、形状特征进行提取,运用计算机视觉、图像处理技术识别茶叶品种。先用数码相机收集茶叶图像,然后对图像格式进行转换和预处理,再运用 HSI 模型提取茶叶颜色特征参数并采用二值化后图像提取茶叶形状特征参数,针对每一类特征,用6种分类器训练建模,并比较各模型的预测精度。结果表明,其中SVMKM和随机森林以2类特征建模,运用十折交叉验证,独立预测分类这2种方法的精确度达到89.5%。说明本研究运用的方法能成功识别出茶叶品种。
关键词:图像处理;图像特征提取;特征筛选;机器学习;品种识别;鲜茶叶
中图分类号:TP391.41 文献标志码: A
文章编号:1002-1302(2021)12-0168-05
收稿日期:2020-09-03
基金项目:湖南省教育厅科学研究项目(编号:17C0589)。
作者简介:刘自强(1988—),男,湖南衡阳人,硕士,讲师,主要从事生物信息处理研究。E-mail:362791767@qq.com。
随着茶叶加工工艺的提高,研究者更加注重茶叶加工和商品茶制作,逐渐忽视茶树栽培与茶树品种研究,不利茶树优良品种保护。而人工识别是以感官评价为主,这使得茶叶识别存有一定的误差,为了提高茶叶评定的准确性,利用计算机技术来识别茶叶成为一种新的选择[1]。
近年来,计算机科学技术快速发展,图像处理技术在诸多领域已有广泛应用。现阶段已有研究者利用数字图像处理技术对成品茶叶或植物叶片提取颜色、形状等特征,来识别茶叶品种。本研究通过提取多种鲜茶叶图像中的颜色、形状等有效特征参数,对鲜茶叶种类进行精准识别,并通过此方法来分辨茶树品种,这对茶树名优品种的发展保护及茶树品种的认知具有重大现实意义。
1 茶叶采样及图像处理
1.1 茶叶采样
分别摘取碧香早、福丰、福云6号、红芽佛手、尖波黄、金萱、茗丰、平云6号、香纪翠和政和大白等10种茶树品种的鲜茶叶片。另外,每个品种再摘取5张成熟叶,用于研究识别其他需要。
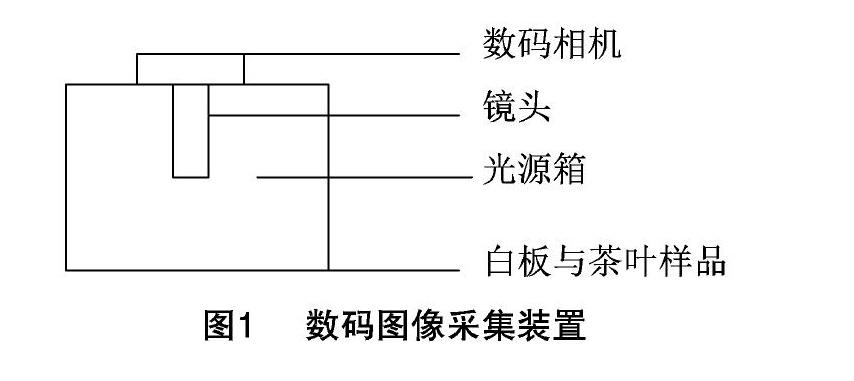
光源箱内开启白光源,相机型号为Nikon 1 J1,拍摄分辨率为1 900×1 700,光圈为F5.6,曝光时间为1/30 s,镜头距白板10 cm,具体操作如图1所示。
根据如上方法,在2 h内采集10种不同品种的100张鲜茶叶图像,每类鲜茶叶图像如图2所示(每种只列出1张)。
1.2 茶叶的图像处理
拍摄的图像光照和设备硬件等因素的影响,存在光照、阴影、边界等问题,会导致重影、边缘模糊、噪声等,须对其进行预处理,以提高特征提取精度。对所采集的图像去除无关信息,恢复有效信息,增强相关信息的可检测性。预处理的过程包括图像灰度化、图像分割、去除小孔洞及清除边界附近对象等。为提高图像的清晰度和图像分析准确度,对图像进行中值滤波去噪和直方图均衡等预处理。鲜茶叶图像经过预处理,一方面通过图像格式的转换,对得到的HSI图像提取出颜色特征参数,另一方面通过图像的二值化处理,得到茶叶的形状和轮廓图,提取其形状特征参数[2-5]。
鲜茶叶图像预处理步骤如下:第1步,对鲜茶叶图像经过B通道灰度化处理;第2步,对灰度化后的图像做二值化处理,用Otsu算法自动确定分割阈值,使目标与背景分离;第3步,对分割后的茶叶图像先闭运算处理后开运算处理,再去除目标图像外不相关目标;第4步,清除边界附近对象及区域外目标操作处理,得到最终预处理后图像。
对所有样本的鲜茶叶图像用相同方法进行预处理,以提取到准确的特征参数。具体流程及示例如图3所示。
2 茶叶颜色和形状特征的提取
2.1 颜色特征提取方法
提取10种不同品种共100幅原始鲜茶叶图像的R(红)G(绿)B(蓝)、H(色调)I(亮度)S(饱和度)、L*(亮度)a*(从红色到绿色的光谱变化值)b*(从黄色到蓝色的光谱变化值)分量值特征,对每个品种鲜茶叶的RGB、HIS 分量特征参数求平均值,结果见表1。由表1可知,各颜色分量特征的平均值有所差异,可利用不同品种的颜色差异做进一步分
析处理[6]。
2.2 形状特征提取方法
2.2.1 重心 预处理后的二值图像质量分布均匀,质心就是目标图像的重心。重心到茶叶目标图像边界最远距离称为最长半径,重心到边界最近距離称为最短半径,如图4所示。
2.2.2 面积、周长 面积是目标图像区域尺寸的度量,常用统计目标区域中像素点数的方法来计算。因像素点统计区域不尽相同,可分为投影面积、凸多边形面积、填充面积(图5)。周长是目标图像区域边缘长度。圆形度是周长2/面积的值,用来形容目标图像边缘复杂程度,而圆形性是4π×面积/周长2的值[7]。
2.2.3 最小外接矩形、长轴和短轴 包含目标图像且面积最小的矩形,称为最小外接矩形(MER,图6-a);最小面积矩形与周长的比值称为偏心率;以目标图像边界点间最长距离为外接矩形主轴,得到的矩形称之为主轴法外接矩形(MAR,图6-b)[8]。通常以主轴法得到的外接矩形的长称为长轴,宽称为短轴,长轴与短轴的比值称为伸长率,可将细长茶叶与方形或圆形的茶叶区分开来[9]。
2.2.4 最大内切圆半径 最大内切圆是目标图像内所能包含的最大面积的圆(图7)。
本试验主要测定的形状特征有投影面积、凸多边形面积、填充面积、周长、长轴、短轴、等价直径、最长半径、最短半径、内切圆半径、偏心率、实度、伸展度、最短长半径比、圆形度、短长轴比、面积周长比等19个。在Matlab软件中,可利用regionprops函数的Area、MajorAxisLength、MinorAxisLength、Eccentricity、EquivDiameter等命令实现参数测定[10]。
茶叶图像经预处理后,颜色、形状特征由软件处理(湖南农业大学农业信息研究所研发的农作物数字图像分析系统V2.0)获得。对形状特征参数求平均值,部分特征平均值如表2所示。
3 特征参数分析及筛选
3.1 茶树品种间特征参数差异性分析
利用单因素多水平方差分析(ANOVA)方法,对10个茶树品种鲜茶叶图像的31个特征参数分别进行显著性水平分析[11]。因为有10种茶树,所以自由度取值9。以周长特征为例, 用Matlab软件算出的P值为3.513 4×10-24,远小于上述临界值。对于周长特征,显然各品种间差异极显著[12]。
利用此方法,对10个样本品种的31个初始特征参数做单因素方差分析,结果见表3。
3.2 有效特征筛选
当样本数量相对较少,特征数量相对较大时,容易产生过拟合风险。用以上方法提取大量鲜茶叶图像特征参数后,由于茶叶样本数据间存在大量相关性,信息冗余,特征维数大,在机器识别过程中,会降低识别精度。因此,需对数据进行特征筛选,去除与目标值无关且带来噪声干扰的特征量,以利于在后续机器识别建模时,缩短训练时间,提高识别精度。
通过多轮末尾淘汰对特征因子进行筛选,对所有特征用libsvm经10次交叉验证建立模型可得初始分类精度,依次剔除每一特征,并以剩余特征利用libsvm经10次交叉验证建立分类模型。在第1轮的31个分类模型中找出最高的分类精度,如果该精度小于所有特征建模时所得的分类精度,说明所有特征均对建模有利,不能删除,应该保留;如果该精度大于原始精度,说明删除该特征后,有助于模型精度的提高,则该特征应删除并进入下一轮汰选;重复以上过程,直至某轮次删除某特征后,所有模型的最高分类精度小于上轮的最高分类精度;此时上轮次的最高精度即为该整个过程中模型的最高精度,其所对应的特征均应保留,汰选终止。
经过多轮汰洗后,保留27个特征参数:(1)颜色特征。图像颜色的R、G、B、L*、a*、b*分量特征。(2)形状特征。填充面积、周长、长轴、短轴、等效直径、最长半径、最短半径、偏心率、伸展度、最短长半径比、圆形度、短长轴比、面积周长比。
4 分析及讨论
4.1 结果
数据经归一化处理后,对100个鲜茶叶图像样本集数据采用K-折交叉验证方法(K取值为10),分别应用SVMKM、RF、NBC、Fisher、KNN和ELM算法进行建模分类识别[13],得出识别结果,比较分析各分类器的识别精度,并对颜色、形状特征分别建模识别,对结果进行比较分析,说明其特征的有效性。
通过检验,各分类器的识别精度都最高,数据集的泛化能力也最强[14]。针对所得到的鲜茶叶图像样本数据的样本小、种类多等特点,通过6种分类器从颜色、形状特征识别中得出结果,结果(表4)表明,通过图像处理方法,提取鲜茶叶片图像的颜色、形状特征[15],建立分类识别模型,能达到89.5%的识别精度。鲜茶叶叶片与茶树品种存在对应关系,利用图像处理方法分类识别不同品种鲜茶叶,同时也识别了鲜茶叶所属的茶树品种。
4.2 结论与讨论
本研究采用图像处理技术实现了茶叶颜色、形状特征参数提取等功能,建立了茶叶品种识别模型,对不同茶叶进行鉴别,预测准确率达到了89.5%,表明图像处理技术对识别茶叶品种是一种可行的方法。为了提高检测的准确性,可进一步提取茶叶的纹理、分形特征等信息并加以判别,从而更精准识别茶叶品种。
本研究利用圖像处理技术解决了茶叶品种识别问题,且识别率较高、精确。根据目前图像处理技术的发展及在诸多领域的应用进展,图像处理技术在农作物实时、无损、快速在线营养检测与病虫害防治方面有很长远的发展前景[16]。现今,食品安全问题也日益突出,非破坏性无损检测技术在农作物营养检测与病虫害防治中越来越受到重视。随着农作物图像处理技术发展,且分析处理能力逐渐提高,采用图像处理技术与相关专家的见解相结合方法,可及时掌握作物营养与病虫害信息,采取相应措施,对农作物生长能起到良好的促进作用[17],食物安全问题也能较好较快地解决。
参考文献:
[1]汪 建,杜世平. 基于颜色和形状的茶叶计算机识别研究[J]. 茶叶科学,2008,28(6):420-424.
[2]杨福增,杨亮亮,田艳娜,等. 基于颜色和形状特征的茶叶嫩芽识别方法[J]. 农业机械学报,2009,40(增刊1):119-123.
[3]陆江锋,单春芳,洪小龙,等. 基于数字图像的茶叶形状特征提取及不同茶叶鉴别研究[J]. 茶叶科学,2010,30(6):453-457.
[4]唐 敏,刘 英,费叶琦,等. 图像处理技术在现代林果采摘中的应用[J]. 林业机械与木工设备,2020,48(4):4-7.
[5]张俊峰. 基于统计形状特征的茶叶梗分离与识别[D]. 合肥:安徽大学,2012.
[6]陈怡群,常 春,肖宏儒,等. 人工神经网络技术在鲜茶叶分选中的应用[J]. 农业网络信息,2010(7):37-40,43.
[7]李清光,李晓钟,周惠明. 茶叶品种与产地识别技术研究进展[J]. 食品科学,2011,32(13):341-344.
[8]陈全胜,赵杰文,蔡健荣,等. 支持向量机在机器视觉识别茶叶中的应用研究[J]. 仪器仪表学报,2006,27(12):1704-1706.
[9]Pandolfi C,Mugnai S,Azzarello E,et al. Artificial neural networks as a tool for plant identification:a case study on Vietnamese tea accessions[J]. Euphytica,2009,166(3):411-421.
[10]Mugnai S,Pandolfi C,Azzarello E,et al. Camellia japonica L. genotypes identified by an artificial neural network based on phyllometric and fractal parameters[J]. Plant Systematics and Evolution,2008,270(1/2):95-108.
[11]Pandolfi C,Messina G,Mugnai G,et al. Discrimination and identification of morphotypes of Banksia integrifolia (Proteaceae) by an Artificial Neural Network (ANN),based on morphological and fractal parameters of leaves and flowers[J]. Taxon, 2009,58(3):925-933.
[12]李国正,王振晓,杨 杰,等. 基于SVM的特征筛选方法及其若干应用[J]. 计算机与应用化学,2002,19(6):703-705.
[13]郭金鑫,陈 玮. 基于HOG多特征融合与随机森林的人脸识别[J]. 计算机科学,2013,40(10):279-282,317.
[14]李锦卫. 基于计算机视觉的水稻、油菜叶色-氮营养诊断机理与建模[D]. 长沙:湖南农业大学,2010.
[15]Pham B T,Prakash I. Evaluation and comparison of LogitBoost Ensemble,Fishers Linear Discriminant Analysis,logistic regression and support vector machines methods for landslide susceptibility mapping[J]. Geocarto International,2019,34(3):316-333.
[16]刁智华,袁万宾,刁春迎,等. 病害特征在作物病害识别中的应用研究综述[J]. 江苏农业科学,2019,47(5):71-74.
[17]張 浩,李和平,叶 娟. 小麦籽粒外观形态特征测定技术研究[J]. 粮食与饲料工业,2013(3):7-9.
猜你喜欢
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年18期)2018-11-14
电子测试(2018年6期)2018-05-09
电子测试(2017年11期)2017-12-15
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
电气化铁道(2016年4期)2016-04-16
河南科技(2014年1期)2014-02-27
