
基于特征级注意力的方面级情感分类模型研究
2021-08-02 08:55杨嘉佳熊仁都
电子技术应用 2021年7期
杨嘉佳 ,熊仁都 ,刘 金 ,唐 球 ,左 娇
(1.华北计算机系统工程研究所,北京 100083;2.中国长城科技集团股份有限公司,广东 深圳 518057)
0 引言
在信息化时代背景下,各行业产生了大量的多源异构数据。对这些数据的情感倾向进行分析,衍生出很多基于传统行业的新实践和新业务模式。情感分析是当下人工智能的一个热门应用,是自然语言处理领域的一个重要分支,根据文本研究对象细粒程度的区别,研究者主要在3 个层次级别上研究情感分析:文档级、语句级和方面级(aspect level)。情感分析的粒度越细,则精确度越高,也就能更好地发现情感极性。方面级情感分析技术[1]主要用于解决情感极性问题,与文档级、语句级情感分类相比,方面级情感分析因为基于aspect 实体,使得情感分析更加细粒化。
当前情感分类精度效果较好的研究,主要基于深度学习、注意力机制而开展[2-9]。但是基于深度学习的方面级情感分析模型主要依赖卷积神经网络、门控循环神经网络进行上下文的编码与特征变换等,这些网络在捕捉长距离依赖上有一定的局限性。此外,尽管基于自注意力机制的Transformer 提供了一种创新思路,但许多研究表明,在浅层网络和训练数据较少的情况下,自注意力网络的网络特征抽取能力不如LSTM 等经典网络,其中一个重要原因是注意力得分针对的是整个向量,灵活性差,复杂度低,当网络层数较少时无法捕捉到深层的语义信息。
针对模型分类高精度化、少参数化的情感分析应用需求,本文提出基于可复位特征级注意力的方面级情感分类模型和基于可复位特征级自注意力的方面级情感分类模型。实验结果表明,在取得与AOA 网络[2]相当分类精度的情况下,两个模型参数量分别为19 万、27 万,仅仅为AOA 参数量(109 万)的17%、25%。
1 相关工作
近年来基于深度学习的方面级情感分类技术得到了广泛研究。这些研究主要围绕循环神经网络、注意力网络而开展。
VO D T 和ZHANG Y[3]首次利用三段LSTM 对目标词和目标词前后上下文进行分别建模之后用于分类。TANG D 等人[4]提出了target-dependent的LSTM模型(TDLSTM)和target-connection LSTM(TC-LSTM)来扩展经典的LSTM 结构用于将方面特征纳入模型运算,其主要使用两个LSTM 分别对目标词左右的文本序列进行建模,之后将左右语句特征集合进行分类。KIM Y 等人[5]首次提出了一个结合方面词嵌入的基于注意力机制的LSTM模型,证明能够很好地捕捉与方面词汇相关的上下文信息,并在当时取得了SOTA(state-of-the-art)的表现。交互型注意力模型如IAN[6]、AOA[2]、MGAN[7]将方面词(target)对上下文(context)的注意力、上下文对关键词的注意力融入到模型,是目前具有最优表现的RNN 结构模型。VASWANI A 等人[8]提出了基于多头自注意力的Transformer模型对序列文本进行编码,摆脱了对RNN 等传统网络的依赖,自注意力机制不依赖序列顺序,能同时针对整个上下文进行特征提取,解决了循环神经网络无法捕捉长期依赖的问题。SONG Y 等人[9]通过使用基于自注意力的网络构建了Attentional Encoder Network 来进行语句上下文特征抽取,以及与目标词进行注意力交互。
尽管基于循环神经网络、注意力网络的方面级情感分析模型在分类准确率、模型参数量都得到了极大改善,但依然还有提升的空间。
2 可复位特征级注意力情感分类模型(RFWA)
实验发现,直接参照多头自注意力模型[8]将自注意力模块替换成特征级自注意力模块时,模型的性能表现并没有提升,反而使得网络变得非常难以训练,最终拟合效果也不如传统自注意力网络。然而,在进一步观察实验过程中的各个变量变化时,注意到在一部分样本上模型对缺省(文本批量化训练时候的补全向量,使得所有输入句子的长度一致)向量的注意力打分远高于真正的文本。据此,本文提出了可复位特征级注意力机制。
2.1 可复位
通常使用批训练技术加速神经网络训练速度,即每次传入一组训练样本,将得到的梯度更新量平均作用于网络参数上。文本任务相较于图像任务,每次训练的输入序列长短不一,而图像可以方便地缩放到统一大小,这就导致在序列并行化过程中需要通过补全的方式,通过在短文本末尾添加如全0 向量作为缺省向量,使得每一批样本中所有输入语句长度一样,从而使得输入的数据维度在训练过程中保持一致,方便并行处理。但是,添加的缺省向量会导致神经网络在训练初始阶段过多地关注到这些无关的没有实际意义的数据,减缓了网络收敛速度。注意力掩码技术则在很大程度上解决了这一问题。
为解决这个问题,研究人员提出了注意力掩码技术:输入样本时,真实词汇标记为1,缺省向量标记为0,该标记作为掩码传入神经网络。在计算注意力时候通常有两种校正策略。
(1)在计算注意力得分之后,softmax 归一化之前,对标记为1 的词汇注意力得分加1,标记为0 的则不作处理。而在特征及注意力模型中,由于得分是针对特征而言,注意力修正需要从向量转化为宽度等于词嵌入维度为e 的矩阵,设输入文本长度为4,网络可接收的最大文本长度为n,则注意力得分修正过程为:
获取注意力掩码:

转化成注意力掩码矩阵:
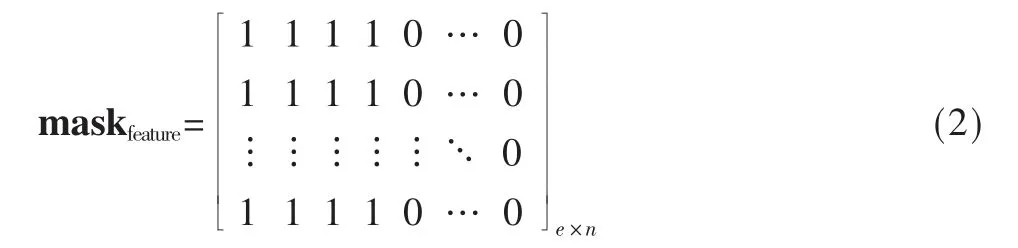
修正注意力得分scores,其中向量X 是上下文句子,向量q 是句子中的一个词:

(2)与上述过程相似,不同之处:对标记为1 的词汇不作处理,对标记为0 的词汇得分加上负无穷-inf,得:

以上两种策略都有助于注意力机制更好地关注到真实的输入数据,使真实词汇的打分偏高,对应的缺省向量的打分会变低。
通过使用注意力掩码技术可以让注意力网络关注到真正的输入上而非缺省向量上,但本文在实验中发现,网络针对相当一部分样本打分时,即使加上了注意力掩码偏置,网络依然对缺省向量打出比真实文本更高的分数,这说明在某些情况下特征级注意力网络需要输出的特征为0,而不是任何输入文本特征的和。
传统的特征级注意力机制通过打分函数得到相容性得分,然后使用softmax 对得分进行归一化,最后直接对全部输入词向量进行加权求和。可以发现在这个过程中,难以满足单层自注意力神经网络丢弃一个特定维度特征而使得输出为0 的要求。
因此本文在模型计算注意力得分之前,构造了一个全为0(可复位)的键向量,其对应的值向量也全为0。该项量与输入样本序列拼接并赋予相同的掩码值1,当注意力机制认为原始输入值上没有重要的特征时,只需提高0 向量的注意力得分即可,即将注意力转移到了一个空向量上。经过实验发现此方法可以显著提高模型的表现效果。
2.2 前置Position-Wise 前馈神经网络
传统自注意力网络,例如在Transformer模型中[8],Position-Wise 前馈神经网络发生在自注意力编码之后。受LSTM 的启发,本文将Position-Wise 前馈神经网络放置在注意力编码之前,将非线性变换的结果作为词向量的value,而原始的embedding 作为key 和query。从而得到如下式子,其中V 相当于对上下文X 中的每一个词向量进行了一次非线性变换后的结果,WV、bV分别表示权重矩阵和偏置矩阵。

用V 替换X,得到模型对输入得编码结果s:
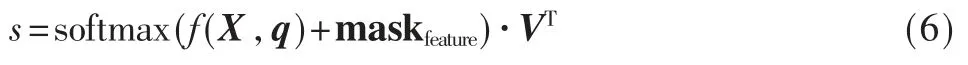
实验发现,经过改进,特征级注意力模型的表现得到了提升。
2.3 可复位特征级注意力情感分类模型
在2.1 节、2.2 节特征级注意力机制的基础上,可以得到可复位特征级注意力网络。RFWA 使用一层可复位特征级注意力网络完成方面词汇与上下文之间的交互,从而得到方面级词汇的基于上下文的表示。之后,使用均值池化方法处理超过一个词长度的方面词,通过一个全连接层和softmax 得到分类结果,模型架构如图1所示。本模型使用Glove[10]预训练模型的词嵌入作为原始输入。

图1 可复位特征级注意力情感分类模型
3 可复位特征级自注意力情感分类模型(RFWSA)
3.1 可复位特征级自注意力网络
(1)基于2.1 节的实验发现,在模型计算注意力得分之前,构造了一个全为0 的键向量;(2)基于2.2 节的实验发现,将Position-Wise 前馈神经网络调整放置在注意力编码前;(3)通过将特征级注意力机制的query 变量设置成输入向量,可得到特征级自注意力机制。结合以上3 方面,最终得到了一个改进后的可复位特征级自注意力网络。
其注意力得分计算原理如图2 所示,在原始文本向量结合补全向量的基础之上添加复位向量作为输入,应用特征级自注意力机制计算自注意力得分,利用可复位注意力掩码修正注意力得分之后,使用行序softmax 得到可复位特征级自注意力权重矩阵。

图2 可复位特征级注意力得分计算
3.2 可复位特征级自注意力情感分类模型
如图3 所示,RFWSA 使用位置编码、上下文特征级自注意力网络对上下文进行编码。同时,使用位置编码对方面词进行编码。然后再使用一层自注意力网络完成上下文与方面词的交互,之后通过池化层、全连接层和softmax 完成情感分类。其中,上下文特征级自注意力网络为3.1 节提出的可复位特征级自注意力网络模块。

图3 可复位特征级自注意力情感分类模型
4 实验及分析
4.1 实验设置
(1)数据集
使用SemEval 2014[11]方面级情感分析数据集进行训练和验证算法,该数据集分为两个子集,分别是Laptop在线评论数据、Restaurant 在线评论数据,每个数据集又被分为训练集和测试集,每条数据包括3 类人工标注好的标签。此外,还引入文献[12]中的Twitter 数据集作为测试。数据组成如表1 所示。

表1 实验数据统计表
(2)实验环境
使用Google Colaboratory 云计算GPU 进行训练,GPU型号为K80,12 GB 显存。
(3)超参数设置
为了防止网络的过拟合,添加了L2 正则化因子,通过L2 正则因子修正损失函数,将网络权重限制在一个较小的值,减小了梯度消失和梯度爆炸的可能。使用Adam算法进行梯度更新,学习率为0.01。Batch-size 为25。使用Glove 27B 300d 词嵌入初始化词向量,非词典词依正态分布置为随机值。添加了Dropout 层,keep-rate 设置为0.8,L2 正则参数为10-4,注意力计算层隐层大小设置为200 维,输入非线性变换层为150 维。所有代码基于Pytorch 实现。
4.2 实验结果与分析
实验结果如表2 所示。通过结果发现,RFWA、RFWSA 在方面级情感分类的表现上与现有主流模型相当。其中RFWSA 在Restaurant 数据集上准确度为0.819,在Laptop 数据集上准确率为0.746,分别超过表现第2好的AOA模型0.7 个百分点和0.1 个百分点,但在Twitter数据集上低于MGAN模型1.3 个百分点。

表2 实验结果对比
为了更好地比较模型在不同维度上的表现,本文统计了主要模型的参数量,如表3 所示。
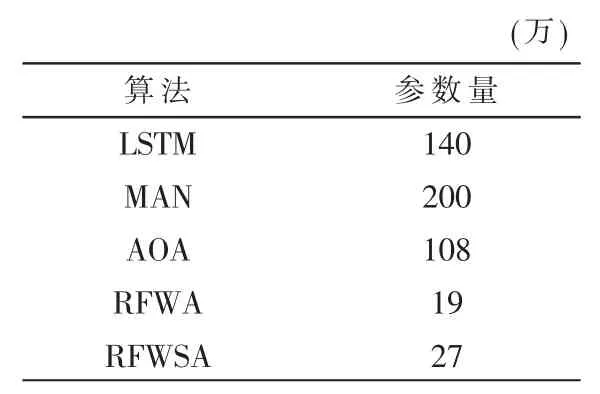
表3 相关模型参数量对比
从表3 中可以看出,RFWA模型仅使用19 万参数,而其在Restaurant 数据集上的分类准确率依然超过AOA模型0.2 个百分点。在参数使用量方面,RFWA 使用了19 万参数,RFWSA 使用了27 万参数,相比其他方面级情感分析模型优势明显。
5 结论
针对情感分析高精度、低参数化的要求,本文通过对基本特征级注意力模型进行改进,提出了基于可复位特征级注意力的方面级情感分类模型,得到RFWA和RFWSA 两个模型。在方面级情感分析公开数据集SemEval 2014、Twitter 上进行测试后,实验结果表明,两个模型在取得与现有主流模型相当分类效果的情况下,在参数利用率上具有明显的优势。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
通信学报(2019年5期)2019-06-11
通信技术(2018年3期)2018-03-21
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
浙江大学学报(工学版)(2015年4期)2015-03-01
