
基于Python 与MATLAB 混合编程的文本分类应用案例设计
2021-08-02 07:40刘卫国
软件导刊 2021年7期
刘卫国,陈 斌
(1.中南大学 计算机学院;2.中南大学 自动化学院,湖南 长沙 410083)
0 引言
Python 和MATLAB 是当今较为流行的两种编程工具,并各具特点。Python 语言简洁优雅、具有独特的功能特征[1],且作为开源语言,拥有许多功能强大的第三方函数库,开发效率高;MATLAB 以矩阵运算为基础,具有科学计算、图形绘制、数据分析等功能[2],且拥有大量学科性工具箱以及Simulink 仿真工具。很多学者也对其进行了研究,如文献[3]设计了基于Python 的机器学习教学案例;文献[4]利用Python 实现网络爬虫案例并将其应用于教学中;文献[5]利用MATLAB 设计了概率论课程教学案例。MAT⁃LAB 语言有别于传统意义上的通用程序设计语言,通常应用于学科层面,具备与学科结合的天然优势[6]。在Python或其他语言中,通过调用MATLAB 引擎执行MATLAB 程序可以扩展语言功能。
在Python 与MATLAB 教学中,结合两种语言混合编程,可以灵活设计适合各学科应用的教学案例,使学生在案例实现过程中深刻体会两种语言各自特点。本文以文本分类为例,介绍利用混合编程设计教学案例的方法。
1 Python 与MATLAB混合编程
实现Python 与MATLAB 混合编程,需要在Python 中启动MATLAB 引擎,从而在Python环境中调用MATLAB 函数。
1.1 MATLAB 引擎启动
启动MATLAB 引擎之前,必须给Python 安装MATLAB引擎。通过针对Python 的MATLAB 引擎API,可在Python中将MATLAB 作为计算引擎来调用。需要注意的是,不同版本的MATLAB 引擎分别支持不同版本的Python 环境,本文使用MATLAB R2016a 和Python 3.4 实现混合编程。
MATLAB 提供了Python 脚本文件setup.py 用于编译与安装MATLAB 引擎。以Window 操作系统为例,首先在命令提示符下将当前目录切换至MATLAB 软件所在磁盘,再使用cd 命令进入MATLAB 安装文件夹的setup.py 所在文件夹,例如cd D:matlab2016extern enginespython,最后使用python setup.py install命令安装MATLAB 引 擎。
安装好MATLAB 引擎后,需要在Python 中启动MAT⁃LAB 引擎,具体代码如下:

1.2 MATLAB 函数调用
利用MATLAB 引擎对象名在Python 环境中调用MAT⁃LAB 函数,调用格式为:
引擎对象名.函数名(函数参数)
在Python 中使用MATLAB 引擎调用MATLAB 的gcd 函数,求两个数的最大公约数,具体命令如下:
e1.gcd(30,56)#调用MATLAB 函数gcd 求30 与56 的最大公约数,返回值为2
2 朴素贝叶斯文本分类算法
朴素贝叶斯算法(Naive Bayes,NB)是基于贝叶斯定理与特征条件独立性假设的分类方法[7]。使用NB 进行文本分类,首先提取各文本中能体现内容的单词组成词汇集合,并将每个单词出现次数作为一个特征,然后把每个文本表示成一个单词的数字向量,其值为文本中该单词出现次数,接着使用数值计算条件概率,计算公式如下[8]:
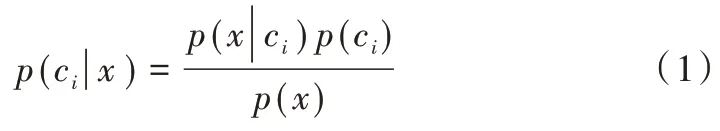
其中,x表示单词的数字向量,ci表示第i种类别的文本。使用该公式计算文本属于各类别的概率,并选择概率最大的一种类别作为文本分类结果。概率p(ci)等于第i类文本数除以所有文本数;条件概率p(x|ci)表示在已知文本类别的条件下,向量x中的单词出现概率[9]。由于假设向量x中各特征量相互独立,所以可使用p(x0|ci)p(x1|ci)p(x2|ci)…p(xn|ci)计算得到条件概率p(x|ci)[10]。
3 利用混合编程实现文本分类算法
本文以SMSSpamCollection数据集[11]中50篇不同短信文本作为分类对象,其中有25篇文本属于垃圾短信,剩下的25 篇属于合法短信。以文本中的英文单词作为特征,1 表示垃圾短信,0 表示合法短信。
主要算法流程用Python 结合NLTK 第三方库加以实现,其中的分类器训练及文本分类函数用MATLAB 语言编写。首先提取所有文本中的英文单词词干,生成一个涵盖所有文本的单词集合;然后依据该单词集合,以单词出现频率为特征生成描述各文本的单词向量集;将向量集随机分为训练集和测试集,使用训练集训练文本分类器,再使用交叉验证方法随机选取10 个文本作为测试集,测试训练所得分类器的性能。文本分类过程如图1 所示。
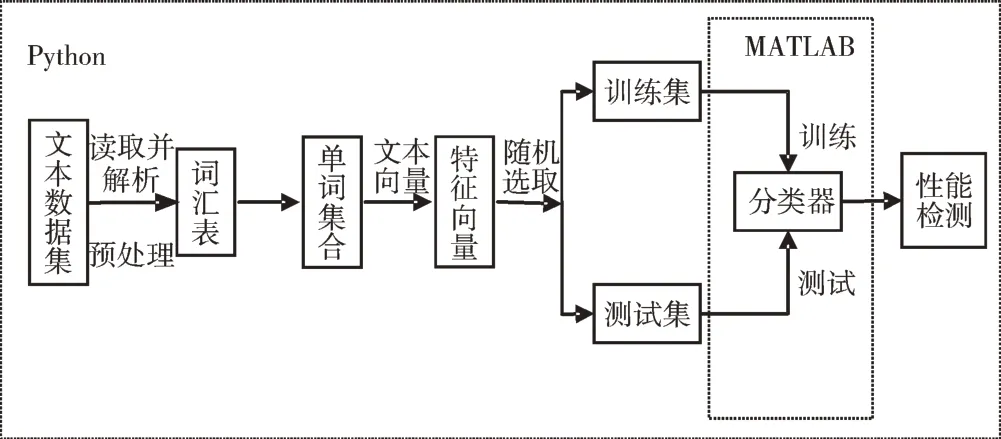
Fig.1 Process of text classification by Naive Bayes图1 朴素贝叶斯文本分类过程
3.1 文本读取与解析
读取并解析文本是将文档中的文本导入Python 中,以便于后续操作。使用Python 的open()和read()函数并结合for 循环结构,依次打开并读取存放在spam 和ham 文件夹下的短信文档。同时使用自定义文本预处理函数conten⁃tHandle 对读取的文档进行预处理,再使用append()函数将处理后的文档扩展至contentList 列表中,并使用列表classList 依次记录扩展文档类型。具体程序如下:


3.2 文本预处理
文本预处理是为了从每篇文档中选出合适的单词构成词汇表,本文的预处理过程包括文本切分、单词规范化与过滤以及单词词干提取。
调用Python 的read()方法读取文件内容时,会返回一个涵盖整个文本内容的字符串。要想得到文本中的单词,需要使用split()方法配合正则表达式切分文本字符串。切分之处为非字母和数字字符的任意字符串,切分后可得到由单词构成的词表。
文本中单词大写字母的出现位置有时会不同,对构建词表和去除停用词将有所影响,需调用lower()方法把词表中的单词全部转换成小写[12]。同时为避免空格和切分产生碎小单词,只保留长度大于2 的单词。导入NLTK 模块中的英文停用词表,返回不在停用词表中的单词[13],以提高词表的文本内容代表性。
英文中的有些单词是由一个词干衍变而来的,所以把单词转换成相应词干,利用词干建立单词集合,使单词向量能更精准地反应出文本类型,从而降低文本分类的错误率。具体程序如下:

3.3 单词集合创建
单词集合是指涵盖全部文本的单词总和,且各单词在集合中有且只有一个[14],可利用Python 集合(set)数据类型消除重复元素的功能加以实现。首先创建一个空集合,然后依次求每篇文本单词集合与已有单词集合的并集,并不断更新至已有单词集合,从而得到全部文本的单词集合。具体程序如下:

3.4 文本向量化
文本向量化是把每篇文本的单词变成单词集合的向量形式,向量每个元素为对应单词在该篇文本中的出现次数[15]。先创建与单词集合同形且值为0 的向量,循环遍历文本中的单词时,如果文本中单词出现在单词集合中,则对应单词出现次数加1,最后函数返回包含各单词在文本中出现次数的向量。具体程序如下:

3.5 分类器训练函数
分类器训练函数采用MATLAB 语言实现,该函数使用训练集产生分类所需的相关数据。函数输入参数为训练集文本单词向量(trainSet)、训练集文本类型(trainClasses),输出数据为文本属于垃圾短信的概率(pSpam)、单词集合词汇分别属于垃圾短信和合法短信的条件概率(p1V、p0V)。
在Python 环境中调用本函数时,需要在函数中对Py⁃thon 类型的输入参数进行转换,使输入参数可参与MAT⁃LAB 运算。该函数的输入参数为嵌套列表,即列表中的每个元素都为一个数字列表,MATLAB 会把该嵌套列表自动转换为一个元胞数组,需要用cell2mat 函数把元胞数组中的每个元素转换为MATLAB 矩阵。
输入参数数据类型转换完成后,先计算文本属于垃圾短信的概率,再使用for 循环遍历所有训练集中的文本。当某单词出现在某一类型文本中时,则更新该单词在对应类型文本中的出现次数,并同时更新该类型文本单词出现的总次数。最后用每个单词出现在相应类型文本中的次数除以该类型文本单词出现总数,即可得到各单词分别属于垃圾和合法短信的条件概率。具体程序如下:


3.6 分类函数
分类函数用MATLAB 语言编写实现,该函数用于分类测试集中的文本。函数的输入参数为分类器训练函数返回的数据(p0V、p1V、pSpam)和待分类文本的单词集合向量(wordsV);输出参数为文本分类结果(result),1 表示垃圾短信文本,0 表示合法短信文本。分类函数使用朴素贝叶斯分类器在训练集上训练所得参数,通过对比待分类文本属于各类别的概率判定待分类文本类别。具体程序如下:

4 利用Python 实现分类器训练及分类函数
NumPy 是Python 的第三方库,支持多类型矩阵的创建与矩阵运算,可用来存储与处理大型矩阵。作为对比实现方法,下面通过Python 调用NumPy 库实现朴素贝叶斯文本分类器训练与文本分类。安装NumPy 库后使用import 语句导入NumPy 中的所有函数定义,命令如下:

4.1 Python 实现分类器训练函数
在Python 中编写trainclassifier 函数实现朴素贝叶斯分类器训练,实现步骤和输入参数与3.5 节相似。具体程序如下:

4.2 Python 实现分类函数
分类函数classifier 利用在训练集上训练所得参数判定文本类别,实现步骤和输入参数与3.6 节相似。具体程序如下:
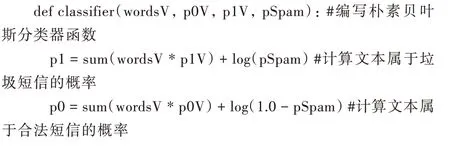

5 结果对比分析
前文分别使用混合编程方法和Python 方法实现文本分类算法,两种实现方法的文本分类错误率如图2 所示。
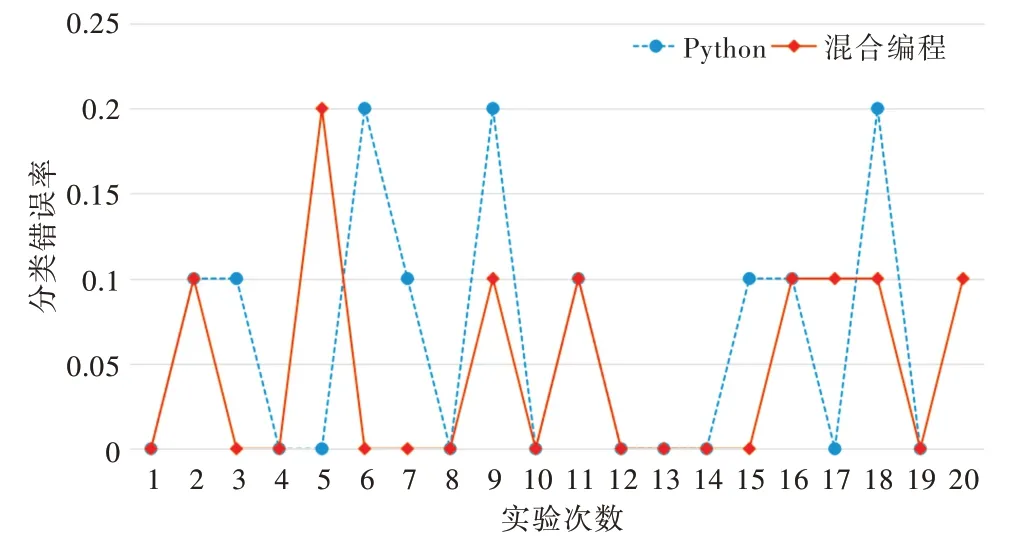
Fig.2 Comparison of classification error rate by two different methods图2 两种实现方法文本分类错误率
图2 中的横坐标代表测试分类器次数,纵坐标代表分类器分类错误率,菱形代表使用混合编程方法实现文本分类器的分类错误率折线,圆形代表使用Python 实现文本分类器的分类错误率折线。由于本文采用随机选取的短信文本测试分类器的分类错误率,所以每次分类错误率可能不一样。重复测试两种方法各20 次,计算其算术平均分类错误率,得到混合编程方法错误率为4.5%,Python 方法为6%,表明使用混合编程方法实现的文本分类器性能更稳定,分类错误率更低,当然错误率估计也与文本的随机选择及内容有关。此外,由于Python 调用第三方库的执行效率高于在Python 环境中使用MATLAB 引擎调用MATLAB函数,因此混合编程方法的程序运行时间比Python 方法长。
6 结语
本文利用Python 与MATLAB 语言混合编程实现朴素贝叶斯文本分类算法,并与Python 调用NumPy 第三方库实现方法进行对比,分析了两种实现方法的特点。Python 和MATLAB 语言各具特点,混合编程是解决问题的一种重要途径,尽管在Python 的很多应用场景下可以借助于第三方库的支持,但将Python 和MATLAB 的功能(如学科性工具箱)配合使用,可使问题求解方法更加灵活多样。结合应用案例进行Python 或MATLAB 课程教学,能使学生更深入地理解相关概念及其应用场景,促进课程教学与学科应用的进一步融合,提高学生的应用能力。
猜你喜欢
新课程·上旬(2019年1期)2019-03-18
电子测试(2018年1期)2018-04-18
教师·中(2017年3期)2017-04-20
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
试题与研究·教学论坛(2016年27期)2016-08-11
河南电力(2015年5期)2015-06-08
皖西学院学报(2015年5期)2015-02-28
电测与仪表(2014年15期)2014-04-04
中学生英语·外语教学与研究(2008年4期)2008-03-18
