
一种卷积神经网络结合后处理的车道线检测算法
2021-08-02 07:40高海强万茂松侯长军
软件导刊 2021年7期
高海强,万茂松,侯长军
(南京林业大学汽车与交通工程学院,江苏南京 210037)
0 引言
世界卫生组织统计数据显示,在全球范围内,每年约有135 万人因道路交通事故死亡。人们逐渐意识到,成熟的自动驾驶技术会使出行更加安全、便捷和高效。自动驾驶技术作为人工驾驶的辅助,可在一定程度上减少因驾驶员注意力不集中、操作失误等因素造成的交通事故[1],甚至代替驾驶员实现无人驾驶。自动驾驶车辆需要有高精度的传感器和严格的算法,其在规避闯红灯、无故超车以及压线等危险违规操作方面比人工驾驶车辆更加可控。车道线作为机动车安全行驶的一个重要指引,是传感器的重点数据采集对象,也是车辆实现自动驾驶的基础[2]。
传统的车道线检测方法包括手工提取特征和启发式方法[3-5],提取的特征包括颜色[6]、条形滤波器[7]、脊线[8]等,提取特征后再与霍夫变换和卡尔曼滤波器相结合以识别车道线。郜瑞芹[9]提出一种针对车道线弯道的塔式梯度直方图方法,利用支持向量机对各种场景的弯道进行检测,增强了算法在雾天场景的鲁棒性;Kang 等[10]使用Sobel算子边缘检测获得带有噪声的车道线边缘特征,沿着垂直方向将道路图像分为多个子区域,采用动态规划算法进行车道线提取;Suddamalla 等[11]采用自适应阈值法,结合像素强度与边界信息提取车道线标记;门光文[12]提出一种基于Canny 算子的车道线检测方法,使用中值滤波滤除干扰信息,并使用Canny 算子提取车道线边缘信息;蒋玉亭[13]提出一种基于边缘点投影的车道线快速识别算法,根据边缘信息提取车道特征点以及梯度方向投影计数,根据置信度判断检测车道线;郭月停[14]提出一种基于区域特征MSER 的改进方法,并对累积概率的Hough 变换算法PPHT 进行了改进;叶美松[15]提出一种单目视觉的车道线检测算法,通过简单缩放与逐样本均值消减的方法对IPM 图像进行归一化处理,然后使用高斯滤波对图片进行去噪阈值化处理;Ding 等[16]提出一种基于鸟瞰图的新型车道线检测方法,并根据遥感图像中提取的道路特征改进了RANSAC 算法。
目前深度学习在图像分割与目标分类领域中广泛应用,基于深度学习的车道线检测方法已逐渐成为趋势。该方法通过对大量样本进行训练,自主学习获取特征,在光照阴影、夜间、弯道等复杂驾驶环境中均具有较强的鲁棒性。胡忠闯[17]提出一种基于CNN 的线段分类器方法,通过消失点检测对车道线进行全局筛选,具有较强的实时性和鲁棒性;Neven 等[18]提出一种基于CNN 的LaneNet 网络车道线实例分割方法,通过LaneNet 结合聚类算法完成对每条车道线的分割,提高了拟合精度;Pan 等[19]设计了一个新的结构,在长宽方向上对CNN 输出的特征图分别进行切片,并将卷积结果向后传递,以达到循环神经网络的效果;Ghafoorian 等[20]将车道线检测看作是图像分割问题,采用生成式对抗网络,其中生成器用于生成车道线的预测值,判别器判别生成器的输出与真实标签的差异,最终网络能够直接生成车道线标记位置;Kim等[21]结合CNN与RANSAC算法进行车道线预测,利用CNN 强大的表达能力进行复杂道路场景的特征提取,采用RANSAC 算法进行车道线拟合;王嘉雯[22]提出一种基于6 层CNN 的车道线分类方法,以Canny 算子结合Hough 变换的方式突出车道线特征,再通过CNN 网络对图片进行分类训练。
针对传统车道线检测方法易受环境影响且需要手工提取特征的局限性,本文构建一种基于CNN 结合后处理算法的车道线检测方法,该方法具有不需要人工调参、适用场景较为广泛以及拟合效果较好等优点。
1 图像数据预处理
车道线图像数据预处理是为了增强图像中目标的特征,使深度学习能更好地学习特征信息,获得泛化能力更强的模型。
1.1 ROI 提取
为去除多余图片信息,改善网络训练的速度与检测效果,采用固定的ROI 区域提取方法,通过OpenCV 将分辨率为720×480 的原始图像(图1)裁剪为720×240 的ROI 区域(图2)。

Fig.1 Original image图1 原始图像

Fig.2 Original image after ROI图2 原始图片经ROI 后的区域图
1.2 亮度对比度变换
对比度即最白与最黑亮度单位的比值,调节对比度可使图像更加生动。以RGB 格式图像的一个颜色通道为例,以像素当前颜色深度值I为横坐标,输出变换的颜色深度值O为纵坐标建立坐标系,传统RGB 格式图像的每个像素点都可以用0~255 的数值表示其颜色深度。
对图像的亮度和对比度同时进行修改时,其变换方程式为:

式中,J为图像亮度增加值,K为原始颜色深度比例值。
根据实际情况多次尝试,确定了图片对比度与亮度调整增加值,未经调整的原始图像如图3 所示,原始图像经过K=1、J=20 的调整处理后如图4 所示。

Fig.3 Original picture图3 原始图像

Fig.4 Effect of brightness contrast conversion图4 亮度对比度变换效果
2 车道线检测算法
本文建立的车道线检测算法主要分为两个步骤,分别为网络设计与模型训练、车道线模型后处理,如图5 所示。

Fig.5 Design steps of lane line detection algorithm图5 车道线检测算法设计步骤
2.1 模型结构设计
对VGG16 网络进行微调(Fine-tuning),在已经在其他分类问题上训练好的VGG16 基网络上添加自定义网络,然后冻结基网络,再训练之前添加的自定义部分并解冻基网络的某些层,最后联合训练解冻层与自定义添加部分,如图6 所示。在网络模型输出的最后一层加入Softmax 层对模型框架进行修改,以实现模型输出结果多通道像素点的概率分布,便于后处理算法中的聚类算法对车道线进行聚类操作。

Fig.6 VGG16 network after adding fine-tuning图6 添加fine-tuning 后的VGG16 网络
2.2 车道线像素聚类
DBSCAN(Density-based Spatial Clustering of Applica⁃tions with Noise)是一种基于密度的聚类算法,其通过对核心点、密度可达点进行聚类,将具有足够高密度的区域划分为一类。同时,DBSCAN 还能识别出稀疏的噪声数据。
对车道线分割模型输出图像的像素分布进行聚类处理,将属于同一车道线的图像像素点归为同一类。将车道线分割图像的像素点概率分布转化为3D 可视化图像,如图7 所示,其中x轴表示图像宽度,y轴表示图像长度。按照x轴值对车道线分割输出的像素点概率分布图像进行排序,分别取图像模型位置x=240、250…480 对应的y 项准确率(Accuracy)数据,然后提取概率值大于0.5 的峰值点,对其进行聚类,车道线概率值大于0.5 的峰值点输出图像如图8所示。
2.3 车道线拟合与回归
车道线拟合即对经过重新分类的车道线分割模型的像素点概率峰值点进行拟合处理,进而求得车道线的轨迹参数方程。

Fig.7 Probability map of pixel point probability distribution of lane line segmentation image图7 分割图像像素点概率分布图
曲线拟合是指对给定的m个数据点Pi(xi,yi),i=1,2,…,m,求得一条近似曲线y=ρ(x),使曲线y=ρ(x)与真实曲线y=f(x)之间的偏差最小。y=ρ(x)在点Pi处的偏差δi的计算方式为:

Fig.8 Output image of peak points with lane line probability value greater than 0.5图8 概率值大于0.5 的峰值点输出图像

式中,δi为偏差。
偏差最小化计算公式为:

最小二乘法将二次方程作为拟合曲线,并选择偏差平方和最小的拟合曲线。采用最小二乘法对给定的m个样本点进行多项式拟合,使yi=f(x)的近似曲线δi=ρ(xi)-yi经过这些样本点。
假设车道线需拟合的多项式为:

所有像素点到达近似曲线的偏差平方和为:

解多项式ai=(i=1,2,…,k),使式(6)取得最小值,表示为:

为求解参数a1,a1,…ak的多元函数极值,对变量ai=(i=1,2,…,k)求偏导公式得:
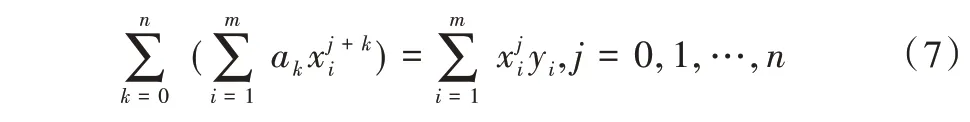
将等式变为矩阵形式:

将范德蒙矩阵化简后得到:

求解得系数矩阵Q公式为:

式(10)即为拟合曲线的关系式,利用最小二乘法对经过聚类分类的车道线像素点概率峰值点进行二次曲线拟合,拟合图像如图9 所示。将拟合曲线回归到原始车道线图像,示例效果如图10 所示。

Fig.9 Conic fitting image图9 二次曲线拟合图像

Fig.10 Lane line fitting effect diagram图10 车道线拟合效果
3 实验结果
本文算法基于Keras 深度学习框架,使用Python 语言,采用OpenCV 计算机视觉处理库,在Ubuntu18.04L TS 系统上进行测试。
采用随机梯度下降法对神经网络模型进行训练,初始学习率设为0.01,批处理大小(batch_size)设置为16,训练循环(Epoch)设置为100。在训练过程中会输出一些反映模型训练状态的参数,根据迭代轮数,提取训练过程输出参数中训练集和验证集的平均准确率与损失量,利用OpenCV 绘图函数分别绘制训练过程中平均准确率与损失量随迭代轮数变化的曲线。模型100 次迭代训练的损失量随迭代轮数变化的曲线如图11 所示,模型100 次迭代训练的平均准确率随迭代轮数变化的曲线如图12 所示。

Fig.11 Training loss curve图11 训练损失量变化曲线

Fig.12 Training accuracy rate change curve图12 训练准确率变化曲线
将模型准确率与召回率定义为评判模型分割效果好坏的依据,即准确率与召回值越大,模型分割效果越好。平均准确率acc的计算公式为:

式中,Cimg为分割正确的像素点数,Timg为整个图像标注的总像素点数。
将标注为车道线图像区域的所有像素点分为车道线像素点与非车道线像素点,两者的比值即为召回率recall。计算公式为:

式中,TP为被正确预测的车道线像素点,FN为被错误预测的车道线像素点。
经过计算,最终模型验证集的平均准确率、召回率分别为91.3%、90.6%,说明模型具有较好的分割效果。然后对不同场景下的车道线进行检测识别,夜晚场景的车道线回归如图13 所示,阴天场景如图14 所示,阴影场景如图15所示,雨天场景如图16 所示。

Fig.13 Lane line returnat night图13 夜晚场景的车道线回归

Fig.14 Lane line return in cloudy day图14 阴天场景的车道线回归

Fig.16 Lane line return in rainy day图16 雨天场景的车道线回归
针对同一实验样本,比较本文模型与其他模型的检测准确率与单帧图像耗时,结果如表1 所示。
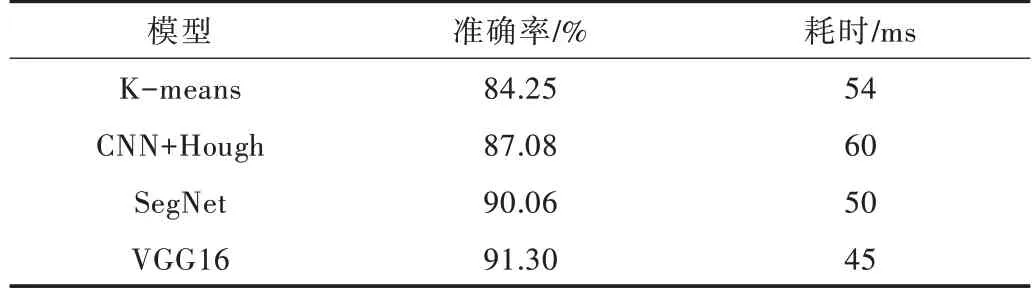
Table 1 Comparison of accuracy and time of single frame image among different models表1 不同模型准确率与单帧图像耗时对比
实验结果显示,传统车道线检测方法K-means 的准确率远不如其他结合深度学习的模型方法。CNN 结合Hough变换的方法虽然提升了检测准确率,但其处理单帧图像的平均耗时最长,与该方法相比,SegNet 模型的车道线检测准确率和平均耗时均有较大改善。相较于其他3 个模型,VGG16 模型在准确率以及单帧图像处理速度方面均有明显提升,达到了较好的图像分割效果。
4 结语
本文利用CNN 在图像特征提取领域的优势对车道线特征进行学习,并利用DBSCAN 聚类算法对车道线分割模型进行后处理,提升了该模型的准确率,优化了车道线的拟合效果。实验结果表明,与传统车道线检测算法相比,CNN 结合后处理的算法具有更高的准确性和可靠性。因此,本文提出的车道线检测算法具有一定应用价值。但该算法仍存在一些不足之处:一方面,图像在训练过程中由于自身硬件条件的限制,可能导致训练时间较长且训练结果存在一定误差,使网络模型不能充分学习到图像特征;另一方面,在进行车道线分割模型输出数据后处理时,可能会滤除少部分像素点数据,导致不能对其进行拟合,造成部分车道线漏检等情况。以上问题是下一步研究的重点方向。
猜你喜欢
卫星应用(2021年11期)2022-01-19
科学大众(2021年9期)2021-07-16
医学食疗与健康(2021年27期)2021-05-13
中国交通信息化(2020年11期)2021-01-14
上海大学学报(自然科学版)(2018年5期)2018-11-02
中国交通信息化(2018年5期)2018-08-21
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
中国交通信息化(2015年10期)2015-06-06
