
DKTwMF:一种融合多特征的知识追踪模型
2021-08-02 03:47盛宇轩冀星昀
计算机技术与发展 2021年7期
王 斌,盛宇轩,冀星昀
(中南大学 计算机学院,湖南 长沙 410083)
0 引 言
近年来,随着在线教育逐渐被人们认可,慕课网、网易云课堂、Coursera和Khan Academy等大型在线开放式网络课程(massive open online courses,MOOC)平台由于其高质量的在线课程,吸引了全球范围内的大量用户注册使用[1]。特别是在疫情防控期间,教育部要求在确保全体师生健康的基础上做好“停课不停学”工作,各地高校利用各大MOOC平台,开展了大规模的线上教学[2]。利用从这些平台收集的数据,研究人员能够深入了解学生的学习过程,进而为教师、学生提供个性化服务,这引发了对教育数据挖掘(educational data mining,EDM)的更多关注[3-5]。
知识追踪是教育数据挖掘领域的一个重要研究课题[6-7],其目标是随着时间推移不断对学生知识掌握状态进行建模,通过估计学生的知识掌握程度[7],预测学生在后续练习中的表现状况。知识追踪模型被广泛应用于教育系统中,实现了学习评价的智能化,有助于推进个性化教育。知识追踪的方法主要分为三类[8]。第一类是基于概率图模型的知识追踪,代表性模型是贝叶斯知识追踪模型(Bayes knowledge tracing,BKT)[9-10]。该模型使用隐马尔可夫模型(hidden Markov model,HMM)学习学生知识状态,用一组二进制变量表示学生是否掌握相应的知识。BKT可以通过严格的公式推导得到学生知识掌握情况、下次作答的预测结果,具有很强的解释性。但是由于该模型需要对各个知识单独建模(即只保留了练习的相对顺序),模型不能充分考虑知识之间的相互作用。第二类是基于矩阵分解的知识追踪,如概率矩阵分解(PMF)。该算法是推荐系统领域的经典算法之一,由于推荐领域与知识追踪的相似性,部分学者将这一算法改进以用于知识追踪领域。第三类是基于深度学习的知识追踪。
2015年斯坦福大学的Piech等人[11]在NIPS上提出深度知识追踪模型(deep knowledge tracing,DKT)。相比其他模型,DKT能够利用学生的历史作答数据挖掘出各个练习之间的隐藏联系。与BKT相比,DKT首次出现便达到了25%的AUC增长[11]。尽管一些研究人员发现通过适当的扩展,BKT可以达到和DKT相近的性能[3],相信通过适当扩展DKT性能仍能够明显提升。传统的DKT模型只使用了知识点ID和作答结果作为模型的输入,它并没有考虑其他特征,如作答时间、作答次数、上次作答结果等。这些特征不仅表示了学生的作答行为,更为知识诊断提供了额外的信息,充分利用这些额外信息能够更加准确地评估学生知识掌握情况。
文献[12]提出一种基于手动选择特征、离散化连续特征的方法来提升DKT模型效果。文献[13]通过获取学生能力,并以固定时间间隔将学生动态分配至具有相似能力的不同组别中,再将这些信息送入DKT中。但这些方法受到两个方面的限制:(1)需要足够的专业知识来理解数据。当对数据理解不足时,模型的构建可能会产生较大偏差;(2)当数据巨大时,方法费时费力。与DKT模型类似,另一种EERNN(exercise-enhanced recurrent neural network)模型[14]也是通过LSTM网络来追踪学生知识掌握的情况。不同的是,EERNN模型更加注重于充分利用题目当中的文本信息,以解决冷启动问题。同时,该模型还引入了注意力机制,通过考虑题目之间的相似性来提升在学生未来表现预测中的准确性。除了上述三种基本方法外,近年来,基于知识图谱的知识追踪也在不断发展[15]。
为了解决上述DKT模型中的问题,该文提出一种融合多特征的知识追踪模型(deep knowledge tracing with multiple features,DKTwMF)。首先,提出基于邻域互信息和随机森林的混合特征选择算法(neighborhood mutual information and random forest,NMIRF),来提取巨大数据中的重要特征,然后将这些重要特征数据以及学生表现作为LSTM模型输入对学生的知识水平进行建模。同时,当数据维度增大时,循环神经网络的训练代价相当昂贵,因此提出一种新的多特征编码方案(multi-feature encoding,MFE),通过使用交叉特征、one-hot编码对多特征输入进行编码,兼顾了输入数据维度和模型效果。之后,再通过自动编码器(auto encoder,AE)对数据进行降维。
1 融合多特征的知识追踪模型
1.1 模型架构
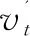
1.2 NMIRF混合特征选择算法
单一的特征选择算法都有各自的局限性,因此该文提出一种NMIRF混合特征选择算法。如图2所示,该算法首先使用方差选择过滤法对所有变量进行初步筛选,计算各个变量之间的方差,然后根据阈值(一般使用0,即不存在变动的数据),选择方差大于阈值的特征,得到k个候选特征集合。然后,使用邻域互信息算法对计算各个特征之间的相关性。由于教育数据集中存在分类数据(如知识点ID、题目ID等)和数值数据(如响应时间),因此使用邻域互信息能够很好地计算k个特征之间的相关性。最后,结合特征相关性使用随机森林对特征进行精选,得到该模块的最终结果。
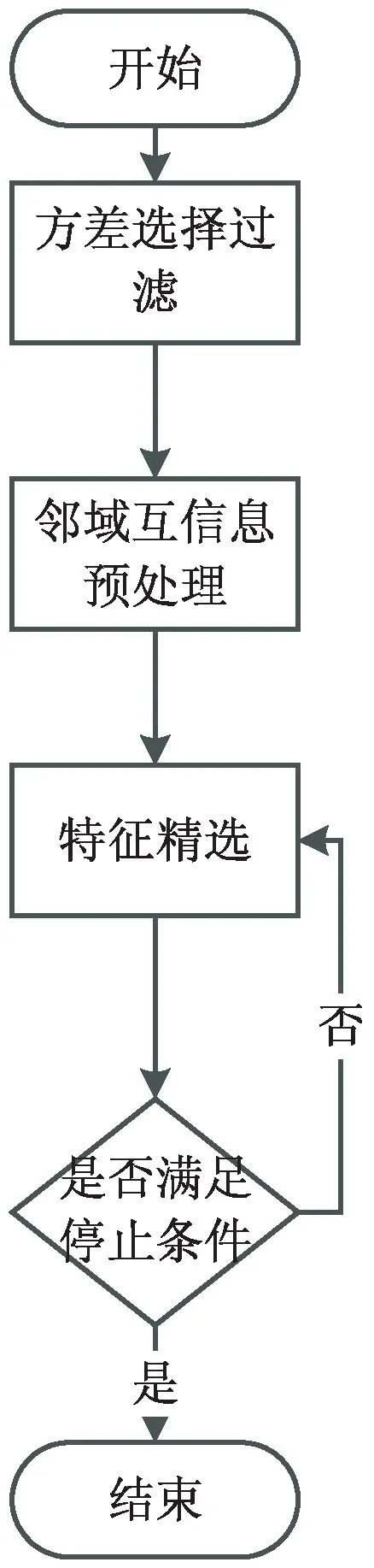
图2 NMIRF混合特征选择算法
评估变量特征重量性(variable importance measures,VIM)是随机森林的一个重要特征,常规计算方法有两种[16-17]:(1)基于基尼指数的评估方法;(2)基于袋外数据(out of bag sets,OOB)分类准确率的评估方法。当数据中同时包含连续变量和分类变量时,基于基尼指数的评估方法比基于OOB分类准确率的评估方法效果差,因此,该文使用基于袋外数据分类准确率的变量重要性度量,即袋外数据变量特征值发生扰动后的分类正确率与未发生扰动的分类正确率的平均减少量。变量特征x重要性计算公式如下:
(1)

在特征精选模块,该文提出一种基于序列后向选择法的混合特征选择算法,即不断从特征子集中删除不重要的特征,直至达到截止条件。为更准确地评估变量的重要性,需要逐步剔除最不重要的变量,然后重新构建随机森林,并在新的随机森林上重新对待筛选特征子集中特征的重要性进行排序。数据集中可能存在相关性很高的特征,即使在其他变量(除待评估变量之外)特征不发生扰动的情况下,其他特征也可能对待评估变量特征重要性评估产生影响,因此该文结合相关性矩阵与随机森林决定是否剔除该特征。具体特征精选算法描述如下:
(1)初始化待选择特征子集U,使用邻域互信息计算各个特征之间的相关性矩阵S。
(2)根据数据集构建包含M棵决策树的随机森林,初始化决策树i=1。
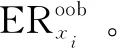
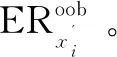
(5)对于i=2,3,…,M,重复步骤(3)~(4),计算特征x的重要性vimx。
(6)对待选择特征子集U中的每个特征重复(3)~(5),并对特征重要性进行排序。
(7)选择特征重要性排序中最不重要的特征y,相关性矩阵中与特征y相关性高于阈值δ的特征集合W。如果集合W为空,更新待选择特征子集U=U-y,跳转至第(8)步;否则,对于W中任一特征,分别计算在使用U-W+w集合时随机森林的袋外分数,最大袋外分数对应的特征记为w,更新待选择特征子集U=U-W+w。
(8)根据新的特征子集重新构建随机森林,重复步骤(2)~(7),直到剩余两个特征,确定最终特征子集。
1.3 MFE多特征编码
由Piech等人提出的DKT模型只考虑了知识点ID和作答结果,该文考虑加入更多的特征作为神经网络输入,为此提出多特征编码方案MFE(multi feature encoding)。通过对多个单独特征的编码进行拼接,从而构建模型的输入。MFE方案中的多特征编码构建公式如下:
C(st,ct)=st+[max(s)+1]*ct
(2)
vt=O(C(st,ct))⊕O(C(ft,ct))⊕O(ft)
(3)
其中,C()表示使用交叉特征,O()表示one-hot编码,⊕表示将编码结果进行拼接。公式(2)、公式(3)中st代表知识点ID,ct代表对应练习的作答结果(1表示作答正确,0表示作答错误),ft代表通过特征工程模块选取的重要特征对应的取值。
交叉特征是将两个或多个特征通过一定规则编码成一个特征的方法。例如,两个单独特征的交叉特征编码方式如下:
C(f,g)=f+[max(F)+1]*g
(4)
C(g,f)=g+[max(G)+1]*f
(5)
式中,f、g分别表示需要编码的两个特征,F、G分别表示特征f、g的取值集合。文献[18]中指出使用交叉特征相比使用单独特征可以明显提高模型性能。如图3所示,假设知识点数为6种,作答结果为2种(正确/错误)。如果不使用交叉特征,神经网络中每个隐藏节点与6+2个节点进行连接,对应6+2的连接权重。使用交叉特征神经网络中每个隐藏节点与6*2个节点进行连接,此时对于每个知识都有单独作答正确权重、作答错误权重与之对应,而不是所有知识点共用正确权重与错误权重。使用交叉特征而不是单独特征的关键原因是:神经网络中的权重不平衡,从而导致模型效果下降。

图3 交叉特征
(6)
2 实验与分析
2.1 数据集
为验证DKTwMF模型的有效性,该文使用三个教育相关的公开数据集进行了对比实验。这三个数据集分别来自不同的智能教育系统,每个系统都对学生练习的交互信息进行了记录。
Assistments 2009-2010:Assistments是一个基于计算机的学习系统,可以同时评估学生的掌握水平和教师的授课水平。该文使用的数据集是从Assistments skill builder集合中收集的,这些集合是学生在类似的问题(同一个知识点)上不断进行练习,直到能正确地回答n个连续的问题(其中n通常是3)。当系统认为学生掌握相应的技能后,学生通常不会重复练习同样的技能。与其他数据集不同,该数据集中学生的作答记录可能不连续,在实验中,通过预处理,将所有属于一个学生的记录连接在一起。
KDD 2010:该数据集是ACM的知识发现和数据挖掘小组(knowledge discovery and data mining)在2010年发布的竞赛题目使用的数据集。该次竞赛以基于学生在线做题记录,预测学生认知能力(学习成绩)为目的。该数据集来自2005年至2009年卡内基学习认知诊断系统。数据集包含574名学生,437个知识点,809 694条学生作答记录。与Assistments平台不同的是,该平台记录了学生的详细操作数据,学生的每一个行为都可能是评估学生知识的依据。使用数据集中的KC(knowledge component)作为知识点,对于多个KC组合的情况视为新的知识点。
OLI F2011:开放学习计划(open learning initiative,OLI)是卡内基梅隆大学的一个计算机学习系统,该系统用于为在校学生提供在线课程。OLI系统在学生许可的情况下收集了学生课堂学习记录和网络学习数据。该文使用2011年秋季学期大学工程力学的数据作为实验数据,包含335名学生,361 092条学生练习记录。该系统详细记录了学生的操作情况,即学生在练习过程中的鼠标点击、翻页、保存等信息。实验中对数据记录进行了删减,只保留了学生的最终作答记录。
针对多知识点题目,不同的系统处理方法也不相同。其中,Assistments中的数据对于多知识点题目,会生成多条记录。而KDD提供的数据只会生成一条记录,系统采用KC(knowledge component)记录题目关联的知识点,知识点之间采用~~串联起来。例如,题目Q1关联了知识点k1、k2,题目Q2关联了知识点k1。假设学生S1参与一次作答,其中Q1作答错误,Q2作答正确。
Assistments生成的记录如表1所示,KDD生成的记录如表2所示。

表1 Assistments记录样例

表2 KDD记录样例
2.2 评价指标
模型的评价标准采用AUC(area under the curve),即ROC曲线线下面积。ROC曲线每个点反映模型对同一信号刺激的感受性,横轴为负正类率(false positive rate,FPR),纵轴为真正类率(true positive rate,TPR)。对于二分类问题,所有实例可以被划分为正类、负类。这里将作答结果为正确的归为正类,作答结果为错误的归为负类,对应的FPR取值为FP/(FP+TN),TPR取值为TP/(TP+FN)。

表3 二分类AUC指标
2.3 实验对比方法
该文将数据中的学生随机分成5组,依次取其中一组作为测试数据集进行实验,最终使用五次实验结果的平均值作为评价结果。通过五折交叉验证得到的实验数据更趋于稳定值,结果能够更让人信服。实验使用TensorFlow中的LSTM Cell实现循环神经网络模型,为消除其他因素的影响,各模型均采用Adam梯度下降算法,神经网络包含200个隐藏神经元,dropout概率设置为0.4。为保证得到的是稳定性结果,实验采用五折交叉的方式进行验证,模型评价标准采用AUC[11]。实验使用基本DKT作为基本模型,分别通过AE降维、NMIRF自动特征提取对模型进行扩充。一些研究人员发现通过适当的扩展,BKT可以达到和DKT相近的性能[3],因此实验也与BKT及其扩展模型进行比较。更具体的对比模型介绍如下:
DKT:该模型为基本模型,如文献[11]所述,即只对skill ID和correct进行one-hot编码,然后使用编码数据对LSTM网络进行训练。
DKT+AE:在基本DKT模型的基础上,使用自动编码器对DKT模型的输入进行预处理,降低输入维度。
DKT+NMIRF:首先使用NMIRF算法对数据集进行筛选,然后将筛选后的多特征数据使用MFE编码,最后使用编码结果作为循环神经网络输入,并对网络进行训练。
DKTwMF:该文提出的模型,将经过NMIRF筛选的多特征数据使用MFE算法进行编码,然后使用AE进行预处理,最后使用LSTM神经网络进行训练。
BKT:经典贝叶斯知识追踪模型,该模型中知识一旦被掌握就不会遗忘。
BKT+F:在经典BKT模型的基础上扩展了知识遗忘属性,该模型中知识可以在掌握和未掌握之间相互转化,该项扩展有助于对于同一知识的预测。
BKT+S:在经典BKT的基础上扩展了技能发现。经典BKT对各知识点单独建模,未对技能之间的交互进行建模,该模型将独立的BKT相互关联起来。
BKT+A:在经典BKT模型的基础上扩展了学生潜在能力属性,针对不同的学生设置个性化的猜测、失误概率,该项扩展有助预测学生从一个知识到另外一个知识点的能力。
BKT+FSA:该模型同时扩展了知识遗忘、技能发现、潜在能力。
2.4 结果分析
本节对在不同数据集下,不同模型的AUC结果进行比较分析,目的在于通过实验验证DKTwMF模型效果。
对于Assistments数据集,各模型的AUC评价结果如图4所示。

图4 Assistments数据集AUC结果
从图4中可以发现,基本BKT的AUC值仅有0.73,通过不同的扩展方式模型效果均得到了不同程度的提升;扩展知识遗忘之后的模型BKT+F达到了略优于基本DKT的效果,AUC值达到0.83;BKT+FSA由于过多参数导致该模型效果略差于BKT+F。从图5中可以发现,通过加入多特征(DKT+NMIRF)、对输入进行降维(DKT+AE)都能在一定程度上提升原模型DKT的效果;DKTwMF在Assistments数据集上达到了最优的结果0.867,达到所有模型中最优效果。
对于KDD数据集,各模型的AUC评价结果如图5所示。

图5 KDD数据集AUC结果
从图5中可以发现,BKT在该数据集上仅达到0.62的AUC值,BKT+F相比基本BKT模型效果没有明显提升,扩展知识遗忘后AUC值仅增加0.01;在BKT系列模型中,BKT+FSA达到最好的预测效果,并且AUC值稍大于基本DKT模型;DKT模型的AUC值为0.79,在扩展多特征后DKT+NMIRF达到与BKT+FSA相当的预测效果。不同于Assistments数据集,在该数据集上DKTwMF模型相比基本DKT模型虽然没有明显的效果提升,但仍然达到了所有模型中的最优效果。
对于OLI数据集,各模型的AUC评价结果如图6所示。

图6 OLI数据集AUC结果
从图6中可以发现,BKT系列模型中AUC值最好的是BKT+FSA,但是该模型仍不如未经改进的DKT模型。而DKTwMF模型的AUC值相比DKT模型又增加了0.04,DKTwMF模型相比BKT模型效果提升了11%。
通过上述实验可以发现:对于BKT系列模型,针对不同数据集不同模型的表现效果大不相同,想要得到适合该数据集的BKT模型需要不断的尝试验证。虽然BKT+FSA能够达到不错的效果,但是过多的参数可能导致效果下降(Assistments数据集)。对于DKT系列模型,可以发现通过加入多特征输入、数据降维都可以在不同程度上提升模型效果。DKTwMF模型同时具备了这两种优化方法,因此模型具有更高的AUC值、能够更准确地预测学生表现情况。无论是多知识点生成多条记录(Assistments)的场景,还是多知识点生成一条记录(KDD)的场景,该模型均能达到不差于其他模型的表现。并且,相比于BKT系列模型,该模型不需要专家知识的指导就可以完成建模,建模效果优于一般手动选择特征。综上所述,该文提出的模型能够智能、高效、准确地对学生知识水平进行建模。
3 结束语
相比其他知识追踪方法,提出的模型主要有以下优点:(1)智能性。通过NMIRF自动对特征进行选择,不需要专家的领域知识的指导。模型不需要知识之间的关系图,模型中的神经网络可以通过数据自动学习各知识之间联系;(2)精准性。通过上述实验证明,DKTwMF模型相比其他模型能够更准确地对学生的知识掌握状态进行建模;(3)高效性。DKTwMF模型采用NMIRF算法对特征进行自动选择,大大节省了了手动特征选择然后验证的时间。同时,使用AE降低数据维度也能降低模型的训练时间。但目前,DKTwMF模型也有以下不足:(1)由于模型采用深度学习的思想,需要大量数据对模型进行训练,因此该模型不适用于少量数据的情况;(2)可解释性不足。BKT模型采用概率的方式表示学生的知识掌握状态,每个知识点都对应明确的函数表示,而神经网络会自动学习神经元之间的相互作用,没有明确的函数表明学生对每个知识的掌握程度。因此,针对这些不足,未来还有待进一步完善。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国典型病例大全(2022年7期)2022-04-22
阅读与作文(英语初中版)(2019年8期)2019-08-27
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
电影新作(2014年2期)2014-02-27
小学生作文辅导·看图读写(2009年5期)2009-06-11
