
基于Stacking集成学习的夏玉米覆盖度估测模型研究
2021-07-30 01:38张宏鸣陈丽君韩文霆张姝茵
农业机械学报 2021年7期
张宏鸣 陈丽君 刘 雯 韩文霆 张姝茵 张 凡
(1.西北农林科技大学信息工程学院, 陕西杨凌 712100; 2.西北农林科技大学机械与电子工程学院, 陕西杨凌 712100)
0 引言
玉米是我国重要的粮食作物,为了保证我国玉米产业的快速平稳发展,需要对玉米相关生长参数进行有效监测。植被覆盖度(Fractional vegetation cover,FVC)通常指植被(包括叶、茎、枝)在地面的垂直投影面积占统计区总面积的百分比[1-2]。植被覆盖度反映植物进行光合作用的面积以及植被生长的茂盛程度,在一定程度上能够体现植被的生长状态和生长趋势[3-6]。因此,估测玉米覆盖度对指导生产管理和进行农业生态系统评价具有重要意义[7]。
植被覆盖度测量主要有地表实测法和遥感监测法[8-9],由于受到人力物力的限制,地表实测法已逐渐被遥感检测法替代[10-11]。植被覆盖度的遥感估算方法主要包括混合像元分解法、统计模型法和数据挖掘法[12]。混合像元分解法一般应用于缺乏地面实测数据的情况[13],主要有线性模型、概率模型、几何光学模型、随机几何模型和模糊分析模型等,其中线性模型应用最为广泛[14],混合像元分解法要求植被具有较为明显的区域特点,且估测精度不高[15]。统计模型法主要利用遥感数据的某一波段、波段组合或遥感植被指数与地面FVC测量值进行统计分析,建立两者之间的数值模型,可分为线性回归模型和非线性回归模型,前者应用较为广泛[16-17]。统计模型法简单、容易实现,但只适用于特定区域与特定植被类型,且精度依赖于地面实测数据,对遥感数据空间分辨率要求高,大区域植被覆盖度估算可能失效,具有较大的不确定性和局限性,不宜推广[12]。数据挖掘法是从大量不完整且含有噪声的随机观测数据中估测潜在信息和知识的过程,目前,决策树、支持向量机和随机森林等非参数回归算法已在植被覆盖度反演中得到应用[12]。支持向量机在解决小样本、非线性及高维模式识别等问题中表现出很好的泛化能力,近年来也应用于植被覆盖度的估算中[18];决策树可避免数据冗余,提高计算能力,有效地挖掘数据潜力;与参数回归等方法相比,随机森林模型无需对变量的正态性和独立性等假设条件进行检验,估测效果较好[19]。
大多数研究使用单一机器学习方法估测植被覆盖度,其中线性回归对非线性以及特征空间大的数据性能表现不足,传统的机器学习模型也容易陷入过拟合。过度依赖一种学习模型很难全面考虑覆盖度变化的特点,从而无法避免估测精度不高、模型鲁棒性不强的问题。
基于以上问题,本文建立基于Stacking集成学习的夏玉米覆盖度估测模型,利用无人机获取夏玉米的多光谱影像,使用随机森林算法进行特征选择,去除冗余特征,集成随机森林、梯度提升树、支持向量机、岭回归等4种学习器,并与其他集成学习框架以及单一学习器模型进行对比,以验证模型的有效性。
1 材料与方法
1.1 研究区概况
研究区位于内蒙古自治区鄂尔多斯市达拉特旗昭君镇,地势南高北低,南部为丘陵山区,库布其沙漠沿腹部穿过,北部为肥沃的黄河冲积平原。地块中心地理坐标为(40°25′N,109°36′E),实验区面积约为1.13 hm2,属典型的温带大陆性气候,大陆度指数为75%,干燥少雨,冬寒夏热,昼夜温差大,年均日照时数约3 000 h,年均气温6.1~7.1℃,无霜期135~150 d,年均降水量240~360 mm。粮食作物主要以小麦、玉米为主,本实验区域种植作物类型为夏玉米,属于春播中晚熟期,一年一熟制,播种时间为5月中旬,收获时间为9月。由于当前的预期量无法满足玉米生长的需求水量,主要的供水方式为喷灌机灌水。实验研究区无人机可见光影像示意图如图1所示,圆形实验区域以喷灌机为中心,平均分为5个扇区,并在每个扇区内部等距离处设置3个6 m×6 m的实验样方(绿色正方形标记),实验区域共计15个样方。
1.2 数据获取及处理
实验时间为2018年6月26日—8月23日,共采集子空间数据117条。遥感数据的采集包括多光谱影像以及在同一时间内低空拍摄的可见光图像。多光谱图像利用六翼无人机搭载五通道多光谱相机RedEdge进行拍摄,无人机轴距900 mm,速度5 m/s,相机质量150 g,焦距5.5 mm,47.2°水平视场,5个谱带对应的中心波长分别为蓝(475 nm)、绿(560 nm)、红(668 nm)、近红外(840 nm)以及红边(717 nm),其他参数如表1所示。

表1 多光谱相机主要参数
利用大疆精灵4Pro型无人机进行低空高清可见光图像采集,光圈值为f/5.6,曝光时间为1/1 600 s,焦距为9 mm。为避免光照条件不均匀不一致产生的干扰,实验天气需晴朗无云,选取太阳光辐射强度稳定的11:00—13:00,相机镜头垂直向下进行数据采集。无人机需按照固定航线飞行。其中多光谱图像分辨率为1 280像素×960像素,单次采集数据图像1 780幅,可见光图像分辨率为5 472像素×3 648像素,单次采集数据图像15幅,同时配备光强传感器以及具有固定反射率3 m×3 m的灰板。
将无人机搭载RedEdge采集的TIFF格式图像,以日期为索引导入到Pix4Dmapper软件中,导入位置与姿态系统(Position and orientation system,POS)数据,采用CGCS2000_3_Degree_GK_CM_ 111E,D_China_2000坐标系,导入地面控制点(Ground control point,GCP)文件,样区范围共布设5个地面控制点,使用实时动态定位(Real-time kinematic,RTK)进行精度检测。同时用这些点来检测影像集合定位精度,保证校正影像在作物覆盖度估测中的基本应用需求。在软件中进行初始化处理,几何校正,构建三维模型,提取纹理以及构造地物特征,根据不同要求设置参数进行图像拼接,得到的多光谱影像空间分辨率为4.731 cm。将生成的高清多光谱影像导入ENVI软件,利用不同植被指数的计算公式分别生成对应植被指数的灰度图,并在ENVI中对拼接预处理之后的原始图像进行裁剪,将根据可见光影像制作的XML实测区域像控点文件导入,每一块实测区域对应实验样地的每一小样方,取裁剪后每一小样方内全部像素点的各项植被指数,最终以均值来确定每个小样方对应的各项植被指数[20-22]。
将同步采集的高清可见光遥感图像作为夏玉米覆盖度参考值,且在Photoshop软件中求算夏玉米覆盖度,将拍摄的JPG格式图像导入软件中,按不同图像需求人工选择色彩范围并不断调节容差将植株和背景分离开来,最终以夏玉米所占像素数与整个小样方的总像素数之比作为该小样方的覆盖度[23-24]。
1.3 特征变量提取及选择
植被的反射光谱为植被本身、下垫面(土质、土壤亮度、湿度、颜色等)、阴影和环境等的综合表现,且其易受大气和季节等的影响[25]。由于植被和农作物在红光波段强吸收和在近红外波段强反射的特性,大量的研究证明这两个波段与作物覆盖度有很好的相关关系。因此,在综合考虑各遥感卫星光谱范围差异的基础上,结合本研究所使用的遥感影像以及研究区域的特点,选择红光、蓝光、绿光和近红外波段组合出9种植被指数作为特征变量进行植被覆盖度研究。分别为比值植被指数(RVI)[26]、归一化差值植被指数(NDVI)[27]、土壤调节植被指数(SAVI)[28]、改进的土壤调节植被指数(MSAVI)[29]、增强植被指数(EVI)[30]、优化土壤调节植被指数(OSAVI)[31]、重归一化植被指数(RDVI)[32]、差值植被指数(DVI)[33]和三角植被指数(TVI)[34]。
上述特征集可能存在信息冗余或泛化性较差的问题,因此需要进行特征选择,找出与植被覆盖度高度相关的特征变量,选出能够充分估测植被覆盖度且数目最少的特征变量集。本文综合考虑皮尔森相关系数与随机森林反向验证权重因子,避免单一线性相关评价的局限性,获得综合考量重要性指标,提取出精要项特征,并对上述筛选方法最终精简效果进行回归验证。
1.4 模型构建
1.4.1Stacking集成学习模型
Stacking由WOLPERT[35]提出,其实质上是一种串行结构的多层学习系统。Stacking方法前期使用交叉验证的方式把原始特征转换为二级特征,然后再对变换得到的二级特征运用元学习器进行常规的训练和拟合。不同于传统的集成框架引导聚集算法(Bagging)和提升方法(Boosting),Stacking框架是将不同基础学习器组合起来进行模型融合。
训练过程为:①利用Stacking集成学习方法调用不同类型的学习器对数据集进行训练学习。②将各分类器得到的训练结果组成一个新的训练样例作为元分类器的输入。③最终第2层模型中元学习器的输出结果为最终的结果输出[36-37]。
1.4.2随机森林
随机森林(Random forest,RF)是一种监督学习算法,在每棵决策回归树进行分支时,从总特征集的子空间中选取最优特征进行分支。该方法保证了各决策树的独立性和多样性,一定程度上避免了过拟合。
1.4.3梯度提升树
梯度提升树(Gradient boosting decision tree,GBDT)是基于Booting算法的一种改进。该方法既能处理连续值,也能处理离散值,对各种类型的数据适应能力极强。具有可灵活处理各种数据、估测准确率高、使用损失函数和对异常值具有很强的鲁棒性等优点,可有效进行回归估测。
1.4.4支持向量机
支持向量机(Support vector machine,SVM)可将低维数据映射到高维空间中,使低维空间的数据在高维空间中形成估计函数,实现回归模型的精度和计算复杂度间的平衡。该方法对于解决小样本分类、回归类问题效果理想,特别适用于时间序列等数据分析挖掘,具有较强的泛化性能。
1.4.5岭回归
岭回归(Ridge regression,RR)实质上是通过改良最小二乘法,放弃最小二乘法的无偏性产生有偏估计,允许以损失部分信息、降低精度为代价获得更实际更可靠的回归系数。该方法通过损失无偏性,对最小二乘回归进行补充,换取较高的数值稳定性,从而得到较高的计算精度,且建模速度快,不需要复杂的计算过程。
1.4.6夏玉米覆盖度估测模型
Stacking集成方法可以集成多种学习器的估测结果。考虑基学习器的预测能力,本文在Stacking集成学习模型第1层选择学习能力较强和差异度较大的模型作为基学习器,有助于模型整体的预测效果提升。其中,随机森林和梯度提升树分别采用Bagging和Boosting的集成学习方式,具有出色的学习能力和严谨的数学理论。支持向量机对于解决小样本和非线性以及高维度的回归问题具有优势。岭回归算法因其稳定性强和训练高效等特点,有着良好的实际应用效果。第2层元学习器选择泛化能力较强的模型,用于纠正多个学习算法对于训练集的偏置情况,防止过拟合效应出现。综上所述,经多次实验组合,本文最终采用RF_1、RF_2、GBDT、SVM和Ridge等5个模型作为基学习器,利用岭回归作为元学习器进行融合得到集成模型。其中RF_1和RF_2均使用RF算法进行训练,两者仅参数设置不同。通过对多种算法的结合,克服单个模型缺陷,优化岭回归的输入,提升了估测结果。本文提出的Stacking集成学习夏玉米覆盖度模型框架(图2),算法步骤如下:
(1)输入数据集。获取初始数据集,并对数据进行特征获取及选择,得到数据集T={(yi,xi);i=1,2,…,m},xi为第i个样本的特征向量,yi为第i个样本对应的预测值,并按照2∶1的比例随机抽取训练集T1和测试集T2,T=T1∪T2,T1∩T2=∅。
(2)学习并生成新的数据集。设第1层选用n个基础学习器,并采用k折交叉验证来训练第1层模型,n种模型扩展之后生成第2层训练集T′1。在基学习器模型进行k折交叉验证过程中,对测试集进行k次计算,将k次计算得到的结果平均,n种模型扩展之后生成第2层测试集T′2。
使用新训练集和测试集构成新数据集,T′=T′1∪T′2,T′={(yi,z1i,z2i,…,zni);i=1,2,…,m},zni为第i个样本新的特征向量。
(3)将得到的T′1用于训练第2层元学习器模型,并用T′2验证Stacking模型性能。训练得到最终Stacking集成学习模型,并对模型进行参数优化。
采用RF_1、RF_2、GBDT、SVM和Ridge等5个模型作为基学习器,利用岭回归作为元学习器,并进行5折交叉验证,步骤(2)中利用每个基础模型(以模型1为例)进行5折交叉验证的详细过程见图3,即训练集取其中的4折作为训练集,另外一折作为测试集,每次交叉验证都基于测试集训练生成的模型对其进行估测,这部分估测值合成下一层模型的训练集。同时每次交叉验证也对数据集原来的整个测试集进行估测,最后将各部分估测值取算术平均,作为下一层模型测试集。把模型1的训练集估测值并列合并得到的矩阵作为训练集,模型1的测试集估测值并列合并得到的矩阵作为测试集,代入下一层的模型,再基于它们进一步训练。
1.5 评价指标
采用决定系数(Coefficient of determination,R2)、均方根误差(Root mean squared error,RMSE)、平均绝对误差(Mean absolute error,MAE)3种常用的评估指标进行模型精度评价,其中R2反映模型拟合优度,越接近1表示所拟合的回归方程越优;RMSE用来衡量模型估测与实际值之间的偏差,越接近0说明模型越准确;MAE能更好地反映估测值误差的实际情况,越接近0说明模型越精确。同时平均绝对百分比误差(Mean absolute percentage error,MAPE)更能直观反映估测结果和真实值之间的差距,越接近0%说明模型越准确,因此选取MAPE来进一步评价模型评估的准确性。
2 结果与讨论
2.1 特征变量的提取及其选择
使用特征变量提取及选择方法,利用波段组合提取9种植被指数。提取测试样本9个特征值,并与相应样方的植被覆盖度进行相关性分析。从皮尔森相关性分析结果(表2)可以看出,与FVC相关性最高的NDVI相关系数为0.953,相关性最低的DVI相关系数为0.904,FVC与9种植被指数相关系数均在0.90以上,且均在P<0.01水平呈极显著相关。但TVI、RVI、DVI与植被覆盖度的相关性与其他特征相比有较明显偏低,因此利用相关系数选择特征集后的结果为选用NDVI、OSAVI、EVI、RDVI、SAVI和MSAVI这6种特征变量。随后基于随机森林模型默认参数进行实验,使用全部特征组合进行训练得分为0.923 2,使用以上6种特征组合进行训练得分为0.922 4。
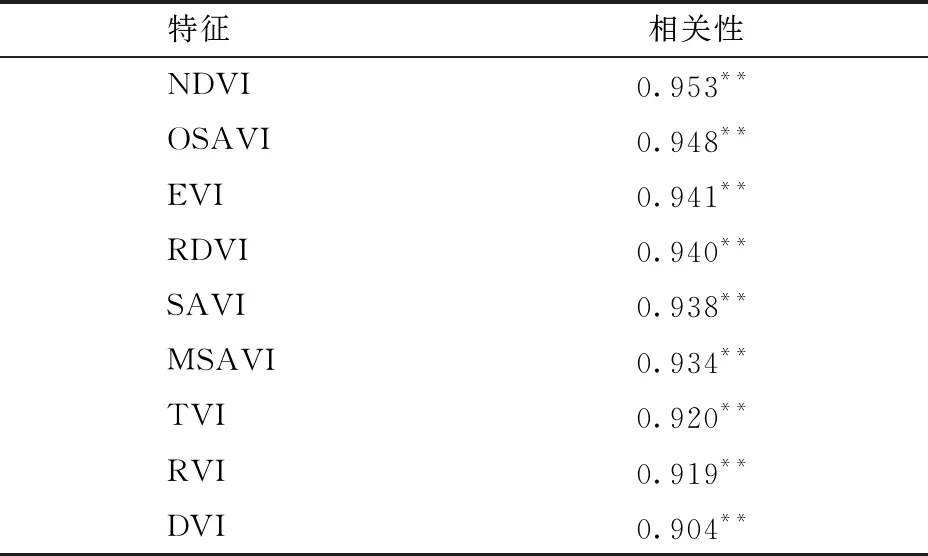
表2 测试样本特征变量与FVC相关性分析结果
随机森林能够度量每个特征的重要性,依据重要性指标可进一步选择最重要的特征(表3),EVI、SAVI和NDVI重要度在0.20~0.25之间,而其他特征重要度在0.12以下,与前3种植被指数差距较大。因此通过重要性分析选取出重要性依次降低的3种特征组合(EVI、SAVI和NDVI)。基于随机森林模型默认参数进行实验,使用上述3种特征进行训练得分为0.921 8。与皮尔森系数法选择的特征组合相比,得分相差仅为0.000 6,同时利用重要性排序选择更少的特征变量进行组合训练,得分在0.90以下,与前者相比得分有明显下降。最终选定3种特征组合(EVI、SAVI和NDVI)。
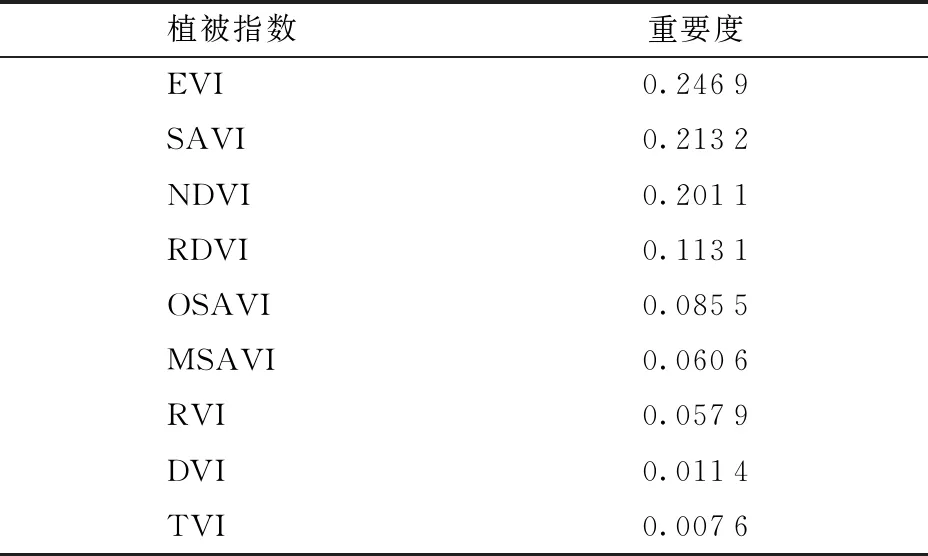
表3 植被指数重要度
2.2 模型参数设置
利用随机搜索和网格搜索相结合的方法进行参数优化以提高训练速度和精度。首先利用随机搜索对在较大范围内用大步长进行粗搜索选择出最优点。然后在最优点附近利用较小的步长划分网格进行搜索,从而选择出全局最优解。重复以上步骤,直至网格间距或目标函数变化量小于给定值。优化后各基学习器的主要参数见表4。

表4 各基学习器主要参数
2.3 夏玉米覆盖度估测结果
利用所构建的Stacking集成学习模型对整个研究区的夏玉米覆盖度进行估算(图4)。从整体上来看并不是所有区域长势都均匀,由于每个区域都进行了不同程度的水分胁迫,影响了夏玉米生长,从而对夏玉米覆盖度也产生了影响。5个区域真实均值分别为0.412 7、0.551 5、0.543 7、0.638 6、0.561 1,而预测结果也大部分集中在0.36~0.61之间。另外结合夏玉米植被覆盖度估测结果(图4a)和当日实拍无人机可见光影像(图4b)对比发现,估测结果与真实情况基本吻合。
2.4 不同模型结果比较
为了验证模型的性能,将Stacking集成学习的夏玉米覆盖度估测模型与单一学习器模型作对比。通过对模型构建与调参得到最优的模型,将测试集分别代入建立好的RF模型、GBDT模型、SVM模型、岭回归模型、Stacking集成学习模型中估测夏玉米覆盖度;各算法对夏玉米覆盖度估测的评价指标对比如表5所示。
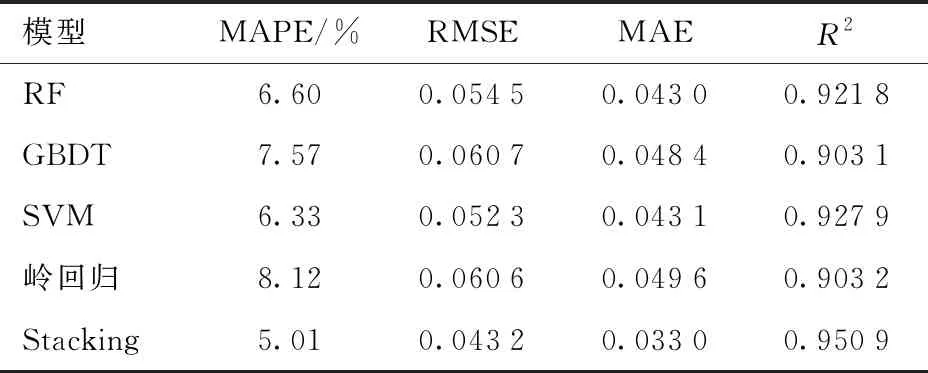
表5 单一模型与Stacking模型对比
Stacking决定系数为0.950 9,对比于RF、GBDT、SVM和岭回归分别提高了0.029 1、0.047 8、0.023 0和0.047 7,平均提高约0.036 9;Stacking平均绝对误差为0.033 0,分别降低了0.010 0、0.015 4、0.019 1和0.016 6,平均降低0.013 0;Stacking均方根误差为0.043 2,分别降低了0.011 3、0.017 5、0.009 1和0.017 4,平均降低0.013 8。即Stacking集成算法的拟合效果明显好于其他单一模型,具有更高的精度。
Stacking的平均绝对百分比误差为5.01%,对比于以上模型分别降低了1.59、2.56、1.32、3.11个百分点,平均降低约2.14个百分点;即与4个单一模型相比,Stacking集成效果最好。
同时利用其他集成学习框架及常用其他机器学习模型进行训练和测试(表6)。对比于决策树、Xgboost、Adaboost和Bagging模型,Stacking决定系数分别提高了0.042 6、0.051 0、0.030 1和0.042 9,平均提高约0.041 7;Stacking平均绝对误差分别降低了0.011 9、0.016 2、0.009 9和0.012 4,平均降低约0.012 6,Stacking均方根误差分别降低了0.027 8、0.018 5、0.011 6和0.015 9,平均降低约0.018 5。平均绝对百分比误差也分别降低了2.09、2.73、2.71、2.08个百分点,平均降低约2.15个百分点。即相对于其他集成策略的模型,Stacking集成学习模型的精度均有较大提升,结果表现较好。
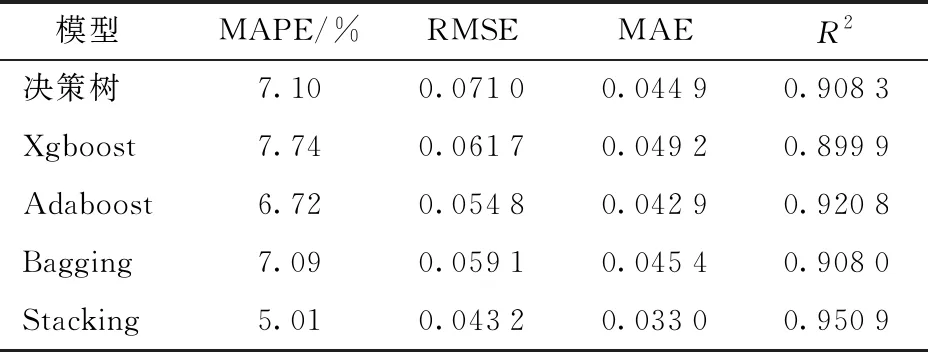
表6 与其他方法比较
为了验证Stacking集成学习模型的鲁棒性,利用不同年份采集的其他夏玉米数据集进行训练和测试,实验结果表明,相对于单一学习器,Stacking集成模型的平均绝对误差平均降低约0.010 1,均方根误差降低约0.010 1,绝对系数提高约0.049 9,平均绝对百分比误差降低约1.21个百分点;相对于上述其他模型,Stacking集成模型的平均绝对误差平均降低约0.010 9,均方根误差降低约0.012 6,绝对系数提高约0.063 8,平均绝对百分比误差降低约1.49个百分点。
3 结论
(1)利用随机森林算法与皮尔森相关系数相结合的方法简单快速地对特征进行筛选,一方面说明植被指数在反演植被覆盖度中具有重要作用,另一方面可考虑将其他的相关信息加入模型特征集合,以进一步提高模型精度。
(2)基于Stacking集成学习夏玉米覆盖度估测模型结合了多种学习器的优势,模型精度较高,仅从RMSE来看,模型误差为0.043 2,即准确度可达95.68%;仅从MAE来看,模型误差为0.033,即准确度可以达到96.70%;仅从MAPE来看,模型误差为5.01%,即准确度可达94.99%。且模型拟合程度较好,R2达0.950 9,该模型集成了多种模型的思想,进一步提高了模型整体效果。
猜你喜欢
科学技术创新(2022年30期)2022-10-21
作物学报(2022年8期)2022-05-29
作物学报(2022年6期)2022-04-08
草业科学(2022年3期)2022-03-26
农业与技术(2021年23期)2021-12-14
——以2020年为例
大麦与谷类科学(2021年5期)2021-11-09
农业与技术(2021年16期)2021-08-31
农民致富之友(2020年17期)2020-06-19
西安科技大学学报(社会科学版)(2020年1期)2020-04-01
水土保持研究(2014年2期)2014-05-05
