
基于遥感影像的植被覆盖度提取方法研究综述
2021-07-29 06:43:08王泽赵良军牛凯张芸杨号
农业与技术 2021年14期
王泽 赵良军 牛凯 张芸 杨号
(四川轻化工大学计算机科学与工程学院,四川 自贡 643000)
引言
植被是植物学、生态学、农学或地球科学中的一个术语,包括许多植物。不同的气候条件形成不同类型的植被特征。光照、气温和降雨都会影响植物的生长和分布,形成不同的植被群落。植被群落在生态系统中通过光合作用生成有机物,吸收CO2,释放O2,实现碳存储[1],在生态系统中发挥至关重要的作用[2]。植被能够抑制空气中细菌和病毒的传播,植被的根部、茎部以及叶面与土壤空气接触中,植物会将附着的细菌、尘埃、颗粒物质等有害物质吸收。植被群落具有净化空气、控制地表湿度等作用;覆盖面积较广的植物群落,能够发挥减少降水对土壤中有机质的冲刷,具有减缓地表水土流失等作用[3]。植物的根系可以吸收土壤水分,涵养水源,植物的叶片具有蒸腾作用,能够减少土地干旱的情况,防止土地沙漠化。植被覆盖度与植被在地面的垂直投影面积占比具有极强的相关性[4]。因此,特定区域的植被生长状况可以通过其植被覆盖度估算来表示[5]。
近年来国内外众多学者提出了大量的植被覆盖度提取方法,依据技术手段和数据来源的不同,主要分为实地测量和遥感影像提取。然而对植被覆盖度的实地测量需要消耗大量的人力、物力、财力以及时间成本,不适合做推广使用且研究意义不大。随着遥感技术的快速发展与进步,其对植被覆盖度提取的高效、精确、快速等优势愈发显著。更重要的是,遥感影像信息丰富、成本低、可读性强,客观真实的反应地理空间分布状况,且基于遥感卫星监测和估算特定区域植被覆盖度不会受到自然和人为因素的干扰[6],是当前估算区域植被覆盖度的最有效手段之一。鉴于此,本文针对基于遥感影像的植被覆盖度研究方法进行了分类总结,详细阐述其原理以及应用;从使用范围、优劣势以及影像因子等方面进行综合分析,提出未来针对植被覆盖度提取方法的方向与趋势,对未来的研究工作开展提供一定的可参考性。
1 基于模型法
1.1 回归模型法
地表的植被和土壤在遥感影像数据中反射率具有明显的差异性和分辨性,利用此特征拟合分析建立回归模型,估算研究区的植被生长状况。依据回归模型法拟合系数和方法的不同,分为线性和非线性两种[7]。对遥感影像数据和光谱波段进行拟合回归分析,针对特定的研究地区创建特定的线性回归模型。North等人[8]利用ATSR-2反射率测量值和相应的植被参数构建线性回归模型,发现拥有4个光谱波段值的线性回归分析模型效果更好。非线性回归模型是将遥感影像的波段或者植被指数与植被覆盖度(FVC)拟合,构建出非线性化的回归模型。Boyd等人[9]在计算美国太平洋西北部的针叶林覆盖度时,根据遥感影像中植被不同的光谱波段值建立非线性回归模型,得出该研究地区针叶林覆盖度68%(99%的置信水平)。
1.2 像元分解模型法
像元分解模型是基于遥感影像中最基础的植被覆盖度估算方法之一,因为在遥感影像中植被和裸土的反射率存在巨大的差异性,则在像元分解模型中可以精确划分植被和非植被,外推计算像元总面积,得到研究区的植被覆盖度。因为像元存在规则性、均匀性、复杂性以及光谱响应特征的不同,像元分解模型分为像元二分模型和混合像元模型。
1.2.1 像元二分模型
像元二分模型主要对规则、均匀、单一的像元进行植被覆盖度提取[10]。其原理是判定一个单位像元由植被与非植被2部分组成,而遥感影像中光谱波段组合由这2个组成部分权重线性合成,各因子的权重等于总像元中所占的比例,总像元中植被权重的集合与植被覆盖度具有很强的相关性[11]。此方法的特点是减少了遥感影像中大气辐射、土壤色泽和植被种类波段差异化等因素的干扰,极大提高了植被覆盖度的提取精确度。
基于遥感影像得到的全部像元信息S由地表植被覆盖信息Sveg和地表土壤覆盖信息Ssoil2部分组成,公式:
S=Sveg+Ssoil
(1)
该像元单位中植被覆盖的像元比例大小公式:
Sveg=fc×Sveg
(2)
式中,fc表示在此遥感影像的一个像元中地表植被覆盖信息所占的比例大小。
该单位像元中非植被覆盖度信息公式:
Ssoil=(1-fc)×Ssoil
(3)
式中,1-fc表示单位像元中非植被覆盖信息比例。
通过公式(2)和公式(3)带入到公式(1),可得:
S=fc×Sveg+(1-fc)×Ssoil
(4)
公式(4)转换后得到像元二分模型中的植被覆盖度(FVC),公式:
(5)
郭芬芬等[12]建立适用于昌都县的像元二分模型,并进行植被盖度估算,根据实测植被盖度数据对估算结果进行精度验证,实测值与估算值的相关系数为0.8624,平均精度82.5%。表明该方法适用于研究植被的生长状况,且具有较高的精确度。孟沌超等[13]构建特定的像元二分模型进行田间冬小麦的覆盖度提取,充分发挥了该模型方法高效、快速、精确等特点。齐亚霄等[14]通过依据地理空间分布特征以及面积加权重心构建像元二分模型,提取2001—2015年天山北坡的植被覆盖度动态变化情况。刘广峰等[10]利用构建像元二分模型提取乌素沙地的植被覆盖度,经过与地面实测数据进行比较验证,两者线性相关系数达到0.92,整体精度达到79.4%。
1.2.2 混合像元分解模型
在遥感影像中像元的地表覆盖几乎是不规则的、不均匀的、不单一的[15],不同的地表覆盖类型具有不同的光谱响应特征[16]。所以在获取遥感影像数据的过程中,由于地物的复杂性以及遥感影像的误差性导致在简单的单位像元中很难做到植被覆盖度的精确估算,不能精确反映出该地区的植被生长情况。混合像元分解模型能够将植被、土壤以及其它复杂的像元信息进行分类,并估计出光谱波段的混合模式、光谱组成和混合像元的比例,利用混合像元分解模型分析得到研究区域的植被覆盖度[17]。
李晓松等[18]通过构建混合像元分解模型对甘肃省民勤绿洲-荒漠过渡带的植被进行覆盖度提取,得到的荒漠植被覆盖正确率达到了95%以上。证明该方法对植被覆盖度的估测具有较高的精确度和可靠性。刘勇等[19]通过混合像元分解模型从ETM+融合影像上提取城市植被盖度,最后利用SPOT影像进行精度检验。因此,像元混合分解模型方法适合用于提取建筑物和道路占比偏高的城镇地区的植被覆盖度。陈彦兵[20]利用混合像元分解模型对潘阳湖湿地的植被生长状况进行估算,得到的估算精度相比于像元二分模型有显著提升,更能真实、客观地表现出潘阳湖的植被生长状况和生态环境质量。
2 基于植被指数法
地表植被是水平和垂直分布生长,不同种类的植被颜色和形状各不相同[21]。所以,基于遥感影像中有关植被的信息主要是通过改变植被光谱带的特征及其差异来获得的。不同的植被特征能被不同的光谱波段识别分析。植被指数的原理是利用不同的光谱波段结合不同的计算方法来估算植被覆盖度。利用植被指数进行植被覆盖度估算时一般选取信息量大且相关性弱的光谱波段[22,23],这样提取光谱波段进行分析时不会存在较大偏差性,能够确保植被覆盖度具有较高的精确性。植被指数对区域植被覆盖度的提取和研究具有高效性、快速性,且不受区域和时间限制。鉴于此,本文针对当前使用最频繁且高效的几种植被指数法进行总结和分析。
2.1 归一化植被指数(NDVI)
NDVI由Rouse在1973年提出[24],是当前使用最多的一种植被指数方法。原理是增加植被中绿叶近红外波段光谱通道与红色波段光谱通道之间叶绿素吸收的差异性。公式:
(6)
式中,NDVI值的范围是-1~1;NIR表示近红外波段反射率,R表示红外波段反射率[25]。NDVI<0代表地面上覆盖的水、雪以及冰川等成分;NDVI=0表示如沙漠、岩石或裸露地面的成分;NDVI>0表示地表植被生长情况。归一化植被指数与植被覆盖度呈正相关关系,绿色植被指数范围一般为0.2~0.8。
宫兆宁等[26]为了提取北京野鸭湖湿地自然保护区的植被覆盖度,利用归一化植被指数在反映植物生长状况、覆盖程度以及区分地表覆盖类型方面的优势,通过对原始Landsat TM影像增加NDVI数据维对影像进行维度扩展。该方法充分反映了北京野鸭湖湿地自然保护区区域内地物间的光谱差异,进一步提高了植被覆盖度估计的准确性。马保东等[27]利用NDVI分析神东矿区1999—2008年10a间矿区植被覆盖度的动态变化,发现该矿区植被指数趋于上升,表明神东矿区土地荒漠化情况好转,植被生态得到改善,矿区土地荒漠化问题得到改善。当植物为中低水平时,NDVI值随覆盖率的增加而迅速上升,并且在达到一定的覆盖率后将缓慢增长。因此,NDVI是估算中低覆盖率作物的理想选择。
2.2 比值植被指数(RVI)
RVI值等于近红外波段和红外波段2个通道反射的比例值,间接反映研究区域的植被覆盖和树木生长状况。RVI的原理是比较红色区域中绿叶在红外系统中的分布情况,该系统接近于吸收叶绿素的红外系统。因为,近红外波段具有极高的反射率,而红光波段具有极低反射率,所以RVI值的范围较大[28]。公式:
(7)
式中,R表示近红外波段;NIR表示红外波段;RVI值的范围是0~30;一般绿色植被区的范围是2~8。
何霜等[29]对攀枝花地区进行植被覆盖度估算,结果表明,植被指数与植被覆盖度之间的拟合相关系数较大,具有很强的关联性。尹芬等[30]利用RVI提取长沙地区的植被覆盖度,结果表明,该方法在植被生长茂盛且覆盖面积大的区域具有较高的灵敏度,该方法的灵敏度转换峰值是50%。当RVI趋近于1时,则说明该地区为建筑物、土壤、水域等非植被地区,而当RVI>2时,说明该地区的植被覆盖度很高。
2.3 土壤调整植被指数(SAVI)
SAVI是在NDVI原理的基础上增加了土壤调节因子L,进一步弱化土壤、大气等因素对植被光谱反射率造成的干扰。公式:
(8)
式中,ρNIR代表近红外波段;ρR代表红光波段;L代表土壤控制指数。SAVI在NDVI基础上,考虑到了遥感影像中地表表面植被覆盖情况的差异性,加入了土壤控制指数L。L值不是固定不变的,取值范围为0~1,L=0说明地表土壤表面没有植被覆盖,L=1表明土壤控制指数对植被覆盖提取的影响较大。对于不同的研究区域和不同的植物覆盖率,选择的土壤控制指数各不相同。
付刚等[31]利用SAVI估算西藏高原的青稞在受到红外增温的情况下的植被覆盖度。池宏康等[32]对黄土高原地区提取植被信息的研究中发现,SAVI对于中等密度植被覆盖提取有更好的效果。高志海等[33]发现,SAVI消除了土壤背景影响以及适应区域内植被密度变化的能力强,提取的植被覆盖度精确度高。
2.4 增强型植被指数(EVI)
在SAVI基础上再添加1条蓝光波段,以改善植物信号并纠正如土壤底部和气溶胶分布等因素的影响。增强型植被指数适用于植被生长状况良好[34]的研究区。公式:
(9)
式中,G为增益因子;L为背景调整因子;C1和C2为拟合调整因子;ρB代表蓝光的光谱反射率;ρR代表红光的光谱反射率;ρNIR代表近红外波段的光谱反射率。
王正兴等[35]利用增强型植被指数反演草地植被生物量,发现EVI不适合提取典型草地和沙地草地等植被覆盖度适中的地区。卢远等人[36]利用增强型植被指数和陆地表面温度(Ts)构建EVI-Ts特征空间,并以该特征空间计算的温度植被干旱指数(TVDI)作为干旱监测指标,分析广西2006年秋旱分布。基于EVI构建的特征空间更适合于我国南方干旱地区的植被生长状况评价。曹燕萍等[37]利用EVI对2002—2016年华北平原植被生长和水文因子进行相关分析,得出华北平原植被生长与降水和土壤蓄水量呈正相关关系,这有助于消除植被生长的不利因素,为区域生态环境产生积极的影响。
3 基于神经网络
神经网络是计算机模拟人类学习的过程,依靠极强的模拟学习能力,使其适用于众多研究方向和领域[38]。近些年神经网络方法发展迅速且应用广泛,在基于遥感影像数据源的植被覆盖度提取中,该方法有极强的容噪能力和非线性处理能力,能解决数据饱和时存在的局限性问题。
张亦然等[39]结合U型神经网络构建针对植被覆盖度提取的深度学习模型,该模型由编码器和解码器构成,编码器由4个编码层和2个卷积层组成,解码器由4个解码层和1个softmax层组成。使用跳跃链接的手段,将源图像输入编码器进行数据特征提取,再由解码器解析得到原尺寸大小的植被覆盖区域,该深度学习模型提取植被覆盖度精度达到0.86。Voorde等[40]利用感知层神经网络对随机选取的训练样本进行植被覆盖度提取[41],估算出布鲁塞尔的植被覆盖度(FVC)。
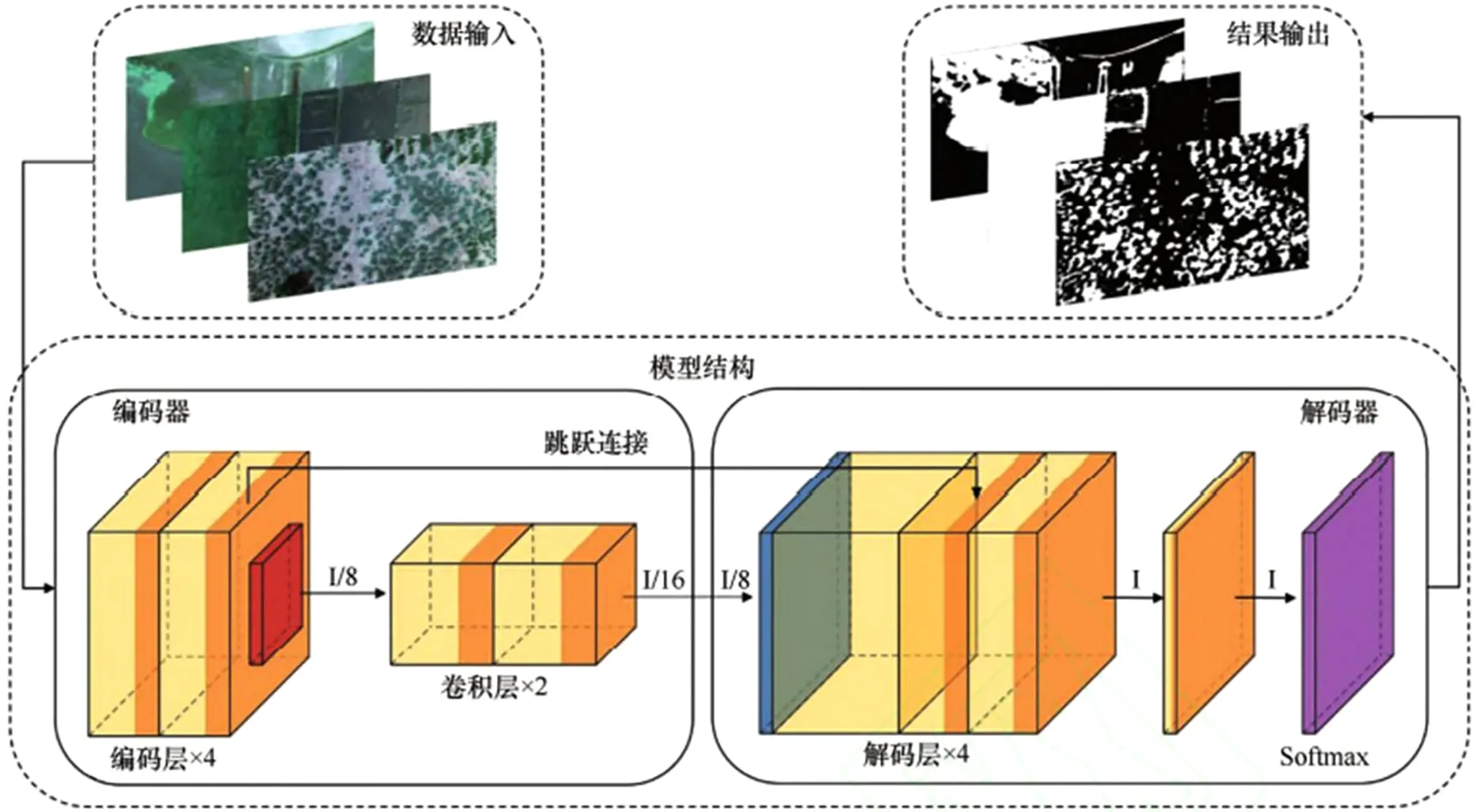
图1 基于神经网络法提取植被覆盖度过程
4 讨论
虽然模型法对植被覆盖度的提取精度较高,但其适用范围具有一定的局限性,仅适用于小范围研究区域,而且对实地测量数据具有较强的依赖性,所以模型法的规模化使用不易实现。像元二分模型虽然削弱了遥感影像中大气、植被类型、土壤背景等影响因子且能够提取较高精确度的植被覆盖度,但其仅适用于单一、规则、均匀的像元。反之,像元混合分解模型克服了地物的复杂性以及遥感影像的误差性,适用范围大且估算精确高,但像元中组成成分复杂且多样,故时间成本较高。
与模型法对比而言,植被指数法更适用于对范围广以及任何遥感影像源的研究区域植被覆盖度提取,且估算精度也更高。但植被指数的精确度很容易受到土壤亮度、土壤颜色、大气辐射、遥感器光谱响应、双向反射等影响。所以在实际应用中,不同的植被覆盖情况以及地物分布情况,需要基于不同的植被指数法来构建一个特定空间和区域的方法,这会大大提高提取植被覆盖度的精确度。
结合神经网络构建的深度学习模型是植被覆盖度提取新的趋势和方法,不受适用范围、实测数据以及遥感源的影响,能够对特定区域构建特定深度学习模型,精确提取该研究区域的植被覆盖度。但神经网络算法具有一定主观性和黑盒子性质,且当前该方向研究内容较少,缺少一定的可靠性和可参考性。
5 展望
本文对利用遥感影像提取研究区域植被覆盖度中使用频率最多和使用范围最广的方法进行分类总结,为地区植被生长状况评估提供一定的参考性。目前在植被覆盖度的提取中,通过结合植被指数和土壤、降水和温度等影响因素建立特定的植被覆盖度提取模型是应用最多的方法,不仅不受范围、信息源等限制,还大大提高了提取精度。由于地表分布是沙漠、湿地、丘陵、河流、城市、沙甸、森林和山地等不同地形地貌组成,造成了不同区域拥有的植被特征差异性较大,所适用的植被覆盖度提取方法也各不相同。所以,未来对一个地区的植被覆盖度的提取,需要考虑其地表特征和植被覆盖类型,削弱相应的影响因子对植被覆盖度提取的影响。
猜你喜欢
印制电路信息(2022年11期)2022-11-30 03:40:58
科学技术创新(2022年30期)2022-10-21 14:01:24
海洋通报(2022年4期)2022-10-10 07:40:26
光谱学与光谱分析(2022年4期)2022-04-06 03:44:38
农业与技术(2021年23期)2021-12-14 09:03:32
原子与分子物理学报(2020年5期)2020-03-17 06:59:18
水土保持研究(2018年5期)2018-10-12 05:29:52
中国农业信息(2018年2期)2018-07-28 08:02:10
电子器件(2017年2期)2017-04-25 08:58:37
西藏科技(2015年1期)2015-09-26 12:09:29
