
基于类重叠度区分的大规模云平台任务终止状态预测
2021-07-29 02:08:02代丽萍王敬雄李为丽刘春红程渤
中国传媒大学学报(自然科学版) 2021年2期
代丽萍,王敬雄,李为丽,刘春红,2*,程渤
(1.河南师范大学计算机与信息工程学院,河南新乡 453007;2.智慧商务与物联网技术河南省工程实验室河南新乡 453007;3.北京邮电大学网络与交换技术国家重点实验室北京 100876)
1 引言
大规模云平台运行着成千上万项应用,云集群管理系统调度各种资源,以保障应用的正常运行,并提高云资源的利用率[1]。目前,云资源调度策略的优化已成为提高资源利用率的重要手段。其中,基于机器学习的任务终止状态预测结果,作为调度器采取相应调度策略的决策依据,已成为云资源管理优化的研究热门[2‑10]。
在分布式云平台的调度管理中,用户的应用请求以作业的形式提交到数据中心,每个作业由调度器分配计算和存储资源,作业的一次调度运行,称为任务。作业包含一个或多个任务。其中,任务终止状态包含驱逐、失败、完成和被杀[1]。提前预测任务的终止状态,对不能成功完成的任务采取相应的调度策略,可有效节约资源,缩短任务的运行时间,提高资源的利用率[6‑7,9‑10]。
云平台失败任务预测研究分为任务终止状态影响因素的分析和终止状态预测方法两个领域。任务终止状态影响因素的分析从失败预测的可行性、任务和资源请求等属性的相关性以及故障表征研究等进行分析[3‑6]。Jassas 等人[2]探索了失败作业与CPU 资源请求等因素之间的相关性。Islam 等人[3]对task 进行了故障表征研究,并探索云平台进行失败预测的可行性。基于机器学习技术的终止状态预测是近年来的研究热点。利用云平台的监视日志收集作业/任务的属性和运行状态数据,在任务终止状态影响因素研究的基础上,使用机器学习技术,建立终止状态预测模型。目前常用支持向量机(SVM)[4],集成模型[5]和神经网络(NN)[7]进行预测。P.Padmakumari等人[5]使用bagging 集成学习策略,集成多个弱分类器进行失败预测,并获得较好的预测精度。越早期的失败预测会带来更好的收益,然而,越早期预测提供给预测模型的运行状态信息量越少。Chen 等人[8]选择在任务运行的1/2时刻,使用递归神经网络(RNN)模型预测,但预测时期相对较晚,且精度不高。Liu 等人[9]提出了利用作业间的结构化信息,弥补早期预测时信息量的不足,在任务执行1/3时刻进行预测的联合预测方法,但该方法将任务终止状态简化为成功和失败两类。
为了更准确地对云平台不同终止状态任务采取不同的调度策略,需要进一步对任务的终止状态预测进行细分,即不仅预测任务是成功还是失败,还需要进一步细分失败是驱逐、失败或被杀的状态,从而采取提前终止或继续运行等不同的调度策略。Rosa等人[7]提出的嵌套神经网络(Nested Neural Network,Nested Prediction)预测方法,进行任务多种终止状态的预测,并分析了作业终止状态对任务终止状态的影响。但是,该方法预测准确率不高,如果某作业终止状态对应的任务数量很少,则可能导致更低的准确率。
本文以Google 云平台的计算调度系统Borg[1]为研究对象,利用Google 公开的Borg 代表性工作负载监控日志(由https://github.com/google/cluster‑data 下载),该日志有一个月的监控数据,统计分析其失败和被杀的任务,其中,任务有多个事件在规定时间内,最后一个事件的终止状态被认为是任务的最终终止状态。任务的事件是指提交、调度、运行和终止这四个状态之间的转换,运行过程中各个事件的最终执行概率,统计结果如图1所示。
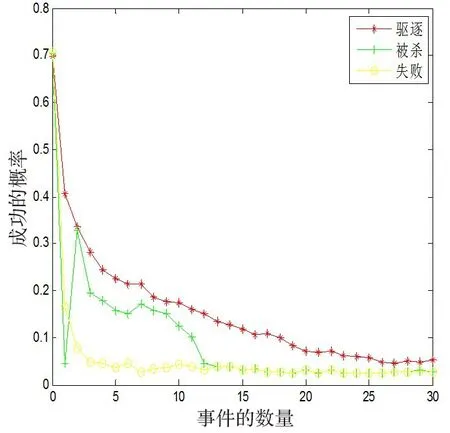
图1 各种事件对应的任务成功执行概率
由图1 可见,事件成功执行的概率随着驱逐和失败事件的增加而下降。由于驱逐的任务多是由于任务前期所请求资源不足或优先级过高导致,任务运行后期可能会被满足,可以再次重新调度。失败的任务是因为任务本身出现问题而终止,所以即使重新调度,失败的概率依然很高,而被杀的任务多是因为被用户自己取消或者所依赖的任务失败,可以再次重新调度,但如果调度后仍不能执行,则最终终止的概率很大。
因此,对于不同任务终止类型需要采取不同的调度策略,可以提高机器运行效率、节约资源。为了对任务态采取更细粒度的调度策略,需要构建多种终止状态的预测模型。
任取3 天的监控日志数据,统计分析任务的终止状态。任务终止状态中,驱逐、失败、完成、被杀的比例为1∶2:3031∶343,其中,最大不均衡比例为1∶3031。终止状态为完成和被杀的任务数量远远高于驱逐和失败的任务,任务类别属于极度类不均衡(class im‐balance)。当处于极度不均衡的状态时,很难对少数类的任务,即驱逐和失败状态,进行有效的预测。极度不均衡的训练集训练出来的分类器更偏向于多数类,从而使少数类的分类性能下降。
同时,由于Borg 系统中同一个作业包含的任务,其大部分属性相同,例如静态特征优先级、调度类、CPU 请求资源、RAM 请求资源和DISK 请求资源等特征属性基本一致。而不同类别的任务往往在这些特征属性上具有相似的数值,导致数据集在极度不均衡的同时,不同的终止状态具有明显的类重叠,四种终止状态类的重叠程度如图2所示。图2将失败预测特征使用PCA降维,选择任务的主要二维特征作为横纵坐标,不同颜色的点区分任务的不同终止状态,图2可见,驱逐和失败状态被成功状态覆盖,成功和被杀状态有大面积的重叠。

图2 四种终止状态的重叠图
由于极度不均衡和类重叠的问题,常用的多分类预测方法不能获得良好的预测性能。针对该问题,本文提出了自定义步长‐提升决策树(Self Paced‑Gradi‐ent Boosting Decision Tree,SP‑GBDT)模型,对极度不均衡的原始数据集进行扩展比例的自定义步长欠采样之后,选取重叠度较低的最优二类组合,构建梯度提升决策树模型,将欠采样之后的数据进行多分类。该方法能有效解决数据集的不均衡程度和类重叠程度,筛选出信息含量更为丰富的数据,提高模型对于少数类任务的正确分类能力,获得很好的分类性能。
2 基于类重叠度区分的不均衡多分类
为实现任务不同终止状态的准确预测,提出了SP‑GBDT预测方法。算法架构图如图3所示。
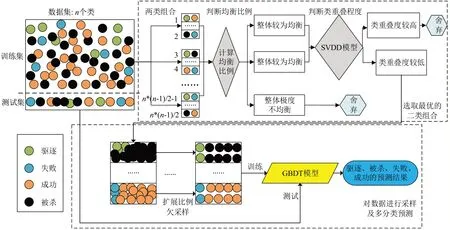
图3 SP⁃GBDT架构图
设待预测数据共有n类,为计算各个任务不同终止状态之间的重叠度,以及更好地对二类组的任务数据进行自定义步长的欠采样,将不同任务的多个终止状态分为若干个二类组。首先将不均衡的数据集按7∶3 的比例,随机分为训练集和测试集。将训练集分为n(n-1)/2 二类的组合,并根据各个二类组合的平衡比例和类重叠程度,选择最优的二类组合;然后针对数据集极度不均衡的情况,扩展欠采样的比例,以获取更多的信息含量丰富的任务,同时使得多类和少类的数据具有较为平衡的比例;最后使用欠采样后的新训练集训练模型,使用原始测试集进行多分类预测。
2.1 类重叠度区分
数据集X 包含n个任务,其中X={x1,x2,...,xn} 。任务xi包含了静态和动态特征,i={1 ,2,⋅⋅⋅,n},n∈N+。标签Y包含n个任务的终止状态,即Y={y1,y2,...,yn} 。任务的终止状态yi由一维类别标签组成,其中yi∈{2 ,3,4,5},2 表示任务终止状态为驱逐,3表示任务执行失败,4 表示任务执行成功,5 表示任务在执行过程中被杀。
任务各个终止状态的重叠程度对其可分离性是有一定程度的影响的。至少有两个类C1、C2同时出现在区域A 的概率大于0,即对任意的重叠任务数据xi,。如果重叠区域较大,则分类器的性能指标便会降低。
为降低不同类别的重叠度,利用支持向量数据描述算法(Support Vector Data Description,SVDD)[11]方法识别互相重叠的任务数量,从而确定重叠区域。然后选取均衡比例较好且重叠度最低的二类组合为最优的组合。
SVDD模型的决策函数如公式(1)所示:
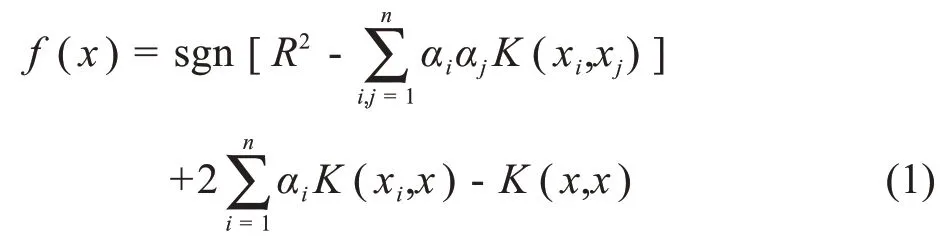
其中sgn(⋅)是阶跃函数,取值在‑1、0、1之中。
将任务数据输入到SVDD 模型中,其决策函数的值若满足以下条件,则可对任务是否为重叠样本进行判定。其中,SVDD算法参数默认选择为0.5。

利用SVDD 算法对任务数据中的每个终止状态类别进行单类学习,基于各个单类模型的决策函数f(x)进行计算比较。若任务样本数据在至多一个单类模型上的决策函数值大于或等于0,则它处于非重叠区域;若任务在至少两个单类模型上的决策函数值大于或等于0,则它处于重叠区域。
以计算任务终止状态为完成和失败的两类样本的重叠度计算为例说明:第一步,完成样本和失败样本分别训练了SVDD 的模型为M1和M2。第二步,合并完成和失败两类样本,将合并后的数据分别输入M1、M2模型中,得到决策函数的值。第三步,根据一个样本中至少两个决策函数值大于等于0 即为重叠区域,计算完成和失败两类中重叠样本个数。第四步,重叠样本个数比上合并样本总数即为完成和失败两类的重叠比例。
2.2 SP⁃GBDT
SP‑GBDT 使用SP 欠采样(Self‑paced under‑sam‐pling)[12],减少带有各类比例不均衡的任务数据对模型的影响。采用GB 算法和决策树(CART)作为基学习器,其中,决策树能最大化拟合训练数据。将GB算法和CART 决策树模型结合,得到GBDT 模型。GB‐DT 模型能通过梯度提升的方法集成多个决策树,损失函数是deviance,且将负梯度作为上一轮单颗决策树犯错的衡量指标,在下一轮学习中通过拟合负梯度来纠正上一轮犯的错误。因此,SP‑GBDT 模型解决极度不均衡的同时,增加边界样本的重要性。
SPE 欠采样中硬度函数和自定义步长的定义如下:
(1)硬度函数:硬度函数的定义如公式(3),每个任务样本具有一个硬度值,将多类的任务数据按照硬度值分成k个箱子,其中k是超参。每个箱子都有一个特定的硬度级别,通过保持每个箱子中的总硬度值相同,对数据集进行欠采样,使其达到一个平衡的程度。硬度函数如公式(3)所示:
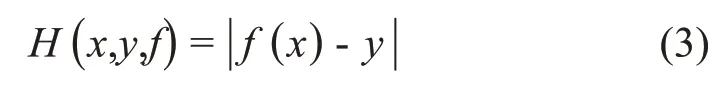
其中,f(x)为GBDT 模型的目标函数,即硬度函数的值和使用的模型相关。
然而在训练过程中,只通过协调箱子的硬度值,使分类器逐步对训练集进行拟合,会导致信息含量并不丰富的任务数据样本的数量不断增加。而且这些样本由于信息量较小,大大降低了迭代的学习过程。因此,本文引入“自定义步长因子(Self‑paced 因子)”来自动协调上述不足。
(2)自定义步长因子:Self‑paced 因子,记为η,能协调各个箱子的硬度值,且能逐步调控箱子的抽样概率。当η变大的时候,模型更加关注分类较为困难的样本,而不是只简单的协调硬度值。
首先,将多类任务样本分为多个二类组合,根据其不均衡比例和类重叠度选出最优的二类组合;然后分别对二类组合进行SP 欠采样;最后进行多分类预测。具体步骤如下所示:
Step 1:将二类组合中任务样本的数据集分为训练集和测试集,根据训练集中任务不同终止状态的数量,分为多类和少类。
Step 2:第i=1次迭代,其中i=1,2,⋅⋅⋅,M
1)初始化GBDT集成模型f0(x)。
2)根据硬度函数H(x,y,f)和f0(x),将训练集中的多类切分成k个箱子,分别是B1,B2,⋅⋅⋅,Bk。
3)第j个箱子平均硬度值为
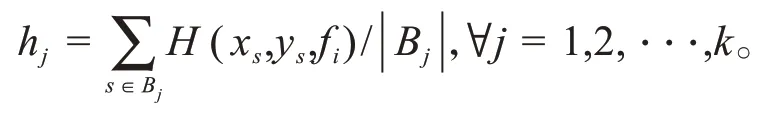
5)第j个箱子的非标准化采样权重。
7)使用最新的欠采样数据子集对GBDT 模型fi(x)进行更新训练。
Step 3:在fM(x)=,x∈R jm时,得到最终的集成模型,将测试集输入到训练好的集成模型中,得到多分类的结果。
2.3 算法描述
SP‑GBDT 模型针对云平台任务终止状态预测时,不同终止状态的极度不均衡和类重叠的问题,首先根据均衡比例和重叠度,得出训练数据集的最优二类组合,然后构建模型,将二分类欠采样扩展为多分类欠采样。算法描述如算法1所示。

3 实验结果与分析
采用大型通用云平台Google 的监控日志数据集进行验证。筛选了Google集群日志前三天的数据,该样本数据集中共有10473个job,包含1665280个任务。
验证实验分为3 组:(1)类重叠度的计算和最优欠采样比例的选择;(2)欠采样参数的选择;(3)预测结果的比较和可视化分析。
实验在集群系统上进行,该集群由两个E5‑2630 CPU,32 G RAM 和两个Tesla K20m 图形卡。在Py‐thon 3.6和MATLAB R2016a环境下运行。
3.1 数据预处理及评价指标
由于云平台数据集从真实环境中采集获取,数据集存在部分噪声和缺失值等问题,首先进行数据的清洗处理。清洗过程如文献[6]所示。
接着进行归一化。由于任务各个特征属性的度量单位不同,通过Z‑score 函数将由任务样本数据标准化。其中Z‑score函数的如公式如(4)所示:
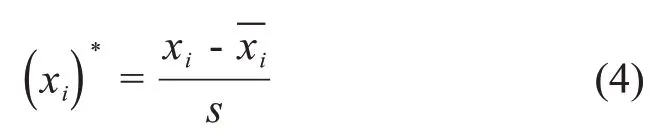
其中s是特征的标准差,是任务特征的平均值。
多分类评价指标分为宏平均(Macro‑average)和微平均(Micro‑average),以召回率(Recall)为例,Mac‐ro‑R 表示宏平均的Recall,Micro‑R 表示微平均的Re‐call。其中Macro‑R 为将n分类的预测值拆成n个二分类的预测值,计算每个二分类的Recall,n个Recall的平均值即为Macro‑R。Micro‑R 为将n分类的预测值拆成n个二分类的预测值,将n个二分类评价的TP、FP、TN、FN对应相加,计算Recall。针对极度不均衡的多分类来说,Macro‑R 受样本数量少的类别影响较大,比Micro‑R更合理。所以本文在测试数据集上,选择宏平均来度量分类器性能,更侧重对小类判别的有效性评价。
G‑mean 是评价不均衡多分类模型的常用指标,正例准确率与负例准确率的综合指标。因为数据集极度不均衡时,模型可能会对多类数据产生过拟合现象,导致实验结果的预测精度很高,但此模型对少数类的预测正确率将会很低。
多分类各评价指标的计算公式如(5~9)所示。

3.2 类重叠度的计算
将任务样本各个终止状态分为若干种二类组合,使用SVDD 模型计算各个二类组合的不均衡比例以及重叠度,以获取不均衡比例较低且重叠度最低的二类组合。具体数值如表1所示。
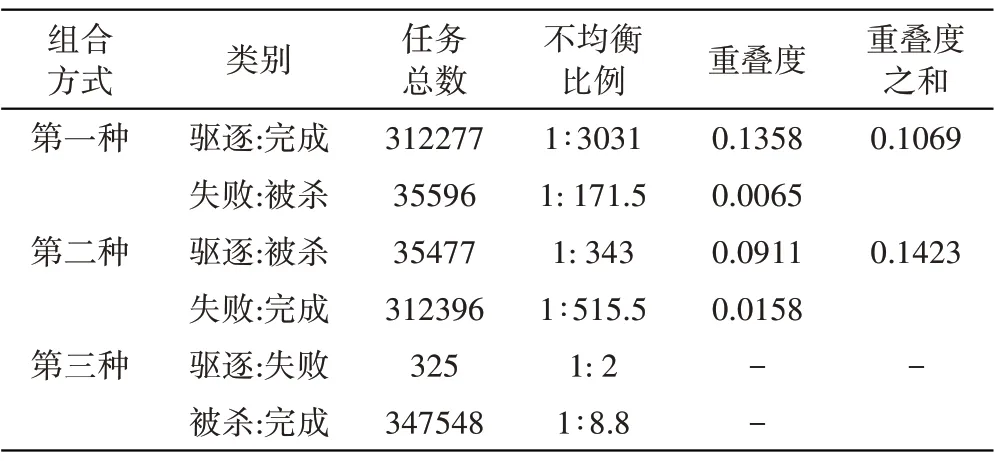
表1 各种二类组合的不均衡比例及重叠度
由表1 可知,四类终止状态可分为三种组合方式,首先判断三种方式整体的均衡比例,第三种方式整体并不均衡,比例为1∶1069.4,而第一种和第二种方式的比例大约为1∶8.77 和1∶8.81,所以排除第三种组合。然后根据SVDD 算法,计算各个二类组合的重叠度,比较其重叠度之和,其中第二种组合方式的重叠度比第一种高了3.54%,所以排除第二种组合。因此,选择了驱逐、完成和失败、被杀的第一种二类组合方式。
3.3 欠采样参数的选择
对比实验分为两组:(1)选取欠采样过程中使用箱子个数的最优值K;(2)选取SP欠采样的最优比例。
(1)选取欠采样过程中箱子个数的最优值K
SP 采样不是简单地平衡正/负数据或直接分配权值,并根据硬度分布迭代地选择信息量最大的大多数数据样本。采样过程中,将数量较多类的任务分为K个箱子,根据硬度函数去筛选信息含量更为丰富的一个箱子。分类模型使用GBDT 模型。将SP 的采样比例固定在1∶1,然后选取最优的K值,其中K 的取值范围为[1,15]。K参数的确定实验如图4所示。
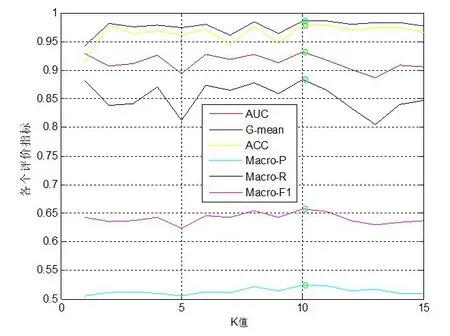
图4 不同箱子个数下各个评价指标的值
将各个评价指标画为折线图,折线图上绿色圆点为此条折线图的最高值。从图4可知,虽然随着K值的变化,各个评价指标的值是没有固定变化趋势,但是各个评价指标的最优值均在K=10的时刻。其中,Macro为宏平均,是更加针对少数类预测结果正确与否的方法。综上,SP欠采样过程中,最终选取的K值为10。
(2)选取SP欠采样的最优比例
由于Google数据集中数据量大,且任务终止状态最大不均衡比例为1∶3031,属于极度不均衡。如果只是按照1∶1 比例进行欠采样,会使得原始数据大量丢失。针对上述问题,将采样比例进行了扩展。为选取SP的最优采样比例,本组实验从1∶1递增到1∶15进行测试。实验使用的多分类模型为GBDT 模型,实验结果如表2所示。
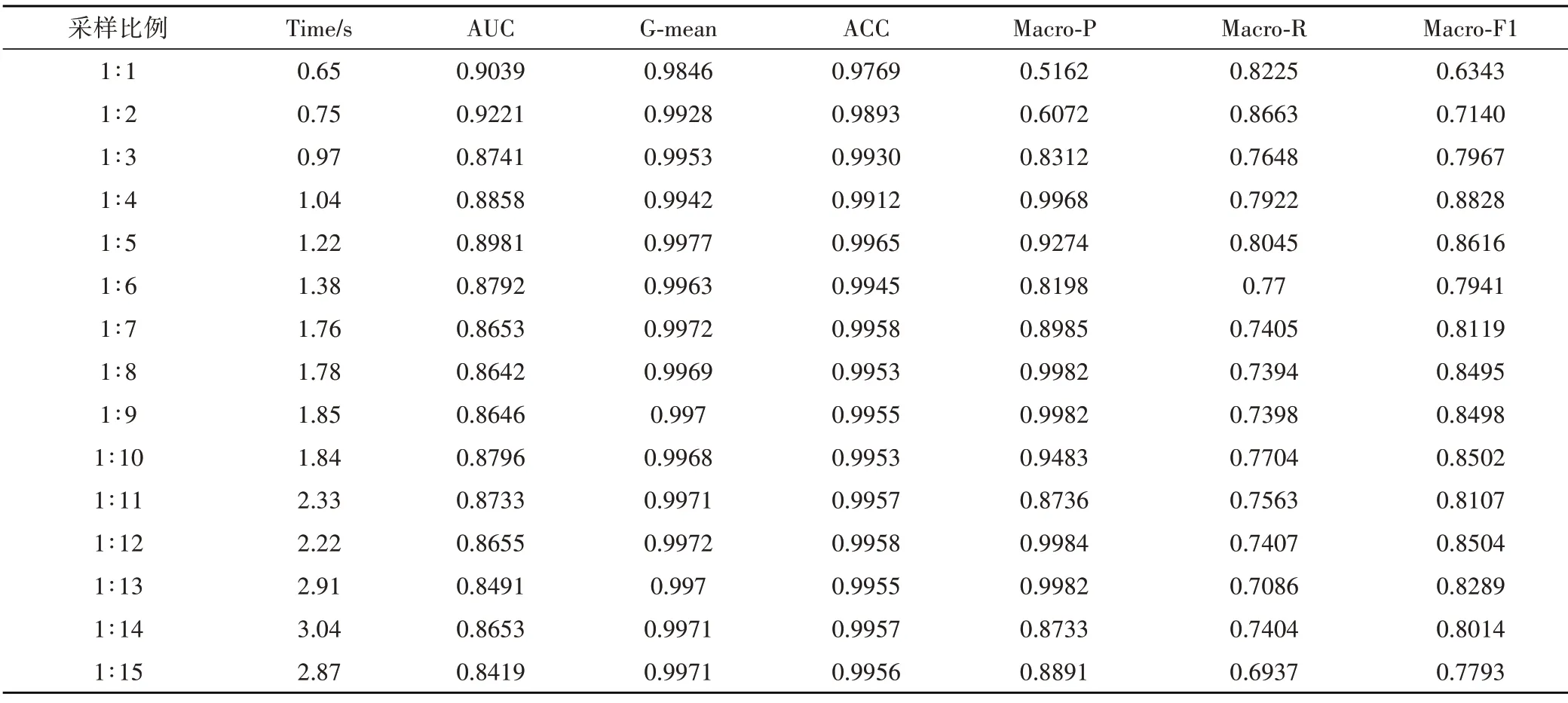
表2 不同采样比例的对比实验
欠采样的扩展比例不宜过高或过低,因为扩展比例过高的话,数据集还会处于不均衡的状态,如果扩展比例太低,则所筛选的数据量太少。其中训练集经过SP 欠采样时,扩展比例为1∶1 以及1∶4 的数据分布对比如图5所示。
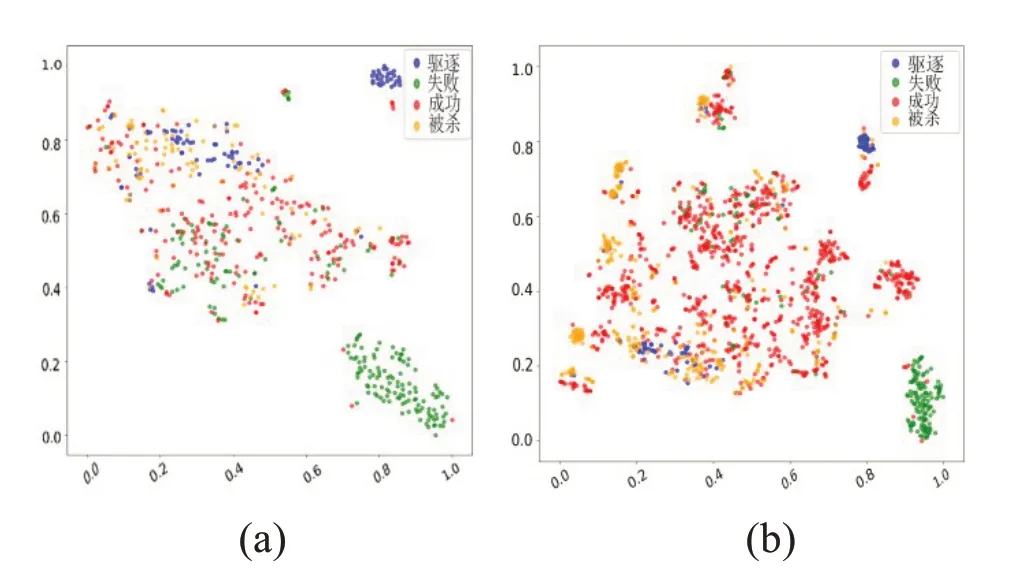
图5 SP欠采样扩展比例的数据分布对比图(a) 1∶1 (b)1∶4
从图5 可以看出,采样比例为1∶1时,训练集的重叠度已经明显减少,但其包含的任务数量明显较少。根据表2,选择了将1∶4 的扩展比例。1∶1 的欠采样比例扩展为1∶4 之后,训练集中包含的数据量明显增加,在保证筛选信息含量丰富的数据同时,也要保证原始数据不被过度删除,充分保留原有数据的底层分布特征。由表2 可知,在欠采样比例为不断增加时,AUC、Macro‑R、Macro‑F 和Macro‑P 的值逐渐升高后慢慢降低,G‑mean、ACC 和时间性能的值逐渐提升。
因此综合考虑各个指标的最优值,选取的SP 欠采样比例为1∶4。
3.4 多分类预测结果的分析
实验分为两组:(1)当前常用采样方法和所提方法对比,以及(2)多种分类模型和所提分类模型的对比。
采样算法:采样方法的对比采样算法有不采样、欠采样和过采样。其中5种欠采样方法分别为随机过采样(Random Over‑Sampler,ROS)[13]、自适应综合采样(Adaptive Synthesis Sampling,ADASYN)[14],以及两个基于合成少数类的过采样技术(Synthetic Minori‐ty Over‑sampling Technique,SMOTE)[16]的改进过采样方法,即borderline‑SMOTE1(bd‑SMOTE1)和border‐line‑SMOTE2 (bd‑SMOTE2)[17]。2种欠采样方法有Cluster Centroids (CLC)和随机下采样(Random Un‐der Sampler,RUS)。
多分类模型:选取了两类模型,即2个单分类模型和3个集成模型进行试验。单模型有DT、SVM,集成模型有AdaBoost[18]、Bagging[19]、随机森林(Random Forest,RF)[20]集成模型。其中Bagging 集成方法通常考虑的是同质弱学习器,相互独立地并行学习这些弱学习器,并按照某种确定性的平均过程将它们组合起来。
(1)采样方法的对比结果及分析
分别对数据进行不采样、欠采样、过采样和SP 的1∶4 欠采样比例。其中各个采样方法在进行多分类时,采用分类模型为GBDT模型。
对比结果如表3 所示,由于云平台数据集数据量大,过采样会导致模型的训练时间普遍较长。其中在随机过采样之后,原本训练集的任务数量从608个变成了104362个,导致模型的训练时间显著变长。而SP 的1∶4 欠采样训练模型所用的时间为1.04s,时间性能明显优于其他采样方法,极大地节省了云平台的调度等待时间。
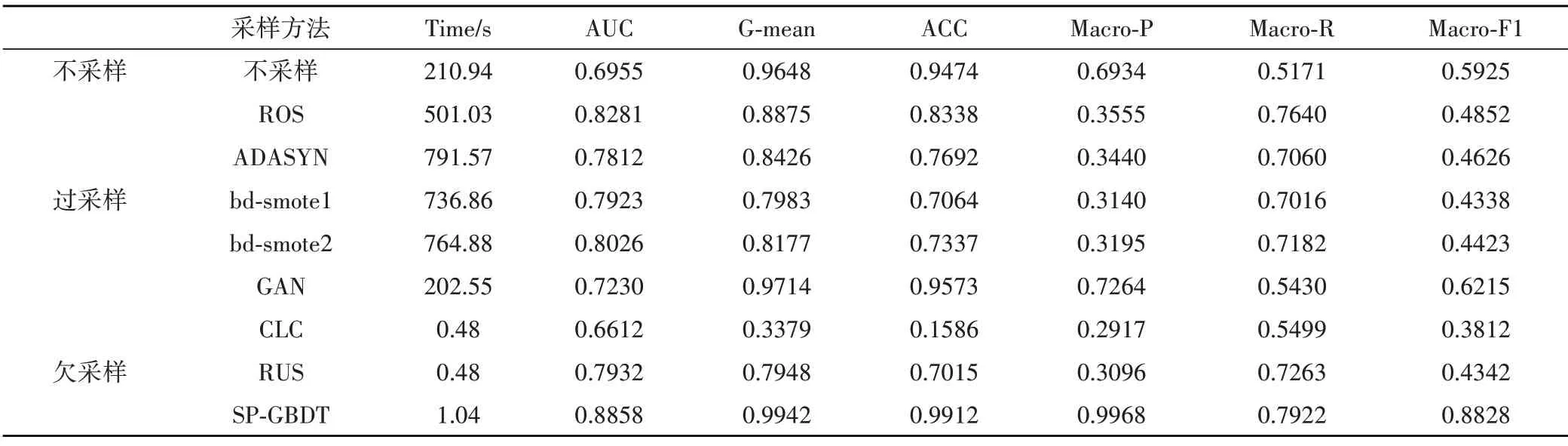
表3 各种采样方法的终止状态预测结果
将数据集按7∶3 的比例分为训练集和测试集。训练集不采样的数据分布以及训练集经过SPE 的扩展比例欠采样之后,数据分布如图6 所示。其中为了将高维数据可视化,将其进行了t‑SNE(t‑dis‐tributed stochastic neighbor embedding)降 维[21]处理。
对比图6(a)中未采样的数据分布,图6(b)中ROS 的过采样方法虽然缓解了数据的不均衡程度,但数据的重叠程度依然很高,导致模型的效果并不理想。图6(c)中数据的重叠程度明显减少,但普通的欠采样方法,只是简单的将多数类样本随机剔除,被剔除的样本可能包含着一些重要信息,导致,实验效果均不理想。
由于RUS 欠采样方法大量删减了信息含量较高的数据,导致欠采样后的模型进行训练时,数据缺乏,使得模型效果较差。图6(d)中可明显看出,本文方法有效降低了样本重叠度,且使得各个终止状态的样本数量保持均衡的情况下,将欠采样比例放宽到1∶4,且利用硬度函数筛选信息含量丰富的任务样本,使得模型获得良好的结果。
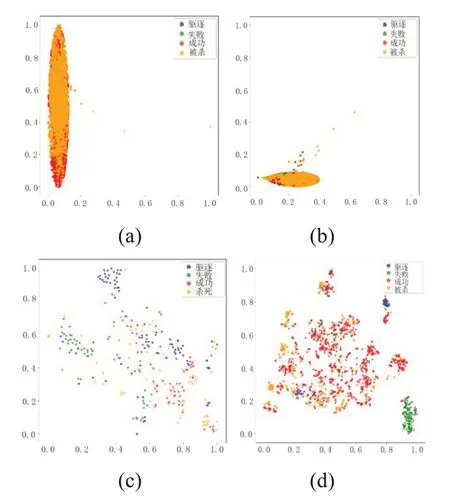
图6 经过采样方法之后的训练集数据分布(a)未采样(b) ROS (c) RUS (d) SP⁃GBDT
(2)预测结果的对比与分析
在对数据集进行欠采样之后,将其输入模型中进行多分类。表4 对比了各种预测模型的终止状态预测结果。其中,GBDT 模型中弱学习器的最大迭代次数为20,损失函数为对数似然损失函数,决策树最大深度为默认值3。
由表4 可见,在单模型中,DT 模型对缺失值数据不敏感,且决策树的信息增益倾GBDT模型,其中Macro‑F 指标差值达到了27.68%。由于SVM 模型在数据集含有较多噪声和缺失值的情况下,对缺失值非常敏感,且不能有效处理含有较多噪声的数据,因此SVM 模型的各个评价指标均低于GB‐DT。在3种集成模型中,AdaBoost 模型实现了多颗决策树的加权运算,但不能有效处理数据不均衡的分布,导致各个指标较低。由于Bagging 模型拟合程度差,使得各个指标较低。RF 模型虽然能有效处理不均衡数据,但其可能具有相似的决策树,不能得到真实的多分类结果,导致其Macro‑P和Macro‑F1 指标较低。GBDT 将gradient boosting算法和CART 决策树结合在一起,其各个评价指标,在结果上基本上是较为优于各个集成模型。
针对数据集不均衡程度和类重叠度会在一定程度上影响模型对少类预测值的问题,对少类(驱逐,失败)的预测准确度进行了进一步的分析,结果如表5所示。
表5 显示,在数据处于极度不均衡的状态下,SP‑GBDT 模型对于少数类任务样本的预测仍具有良好的准确性。
4 结束语
大型异构云计算平台上,针对任务终止状态的预测遇到数据集极度不均衡的问题,提出了一种重叠度区分的任务终止状态预测模型,且通过实验选取了最优的参数,并验证了所提方法的优越性。对于实验结果进行了深入分析。实验结果表明,SP‑GBDT 模型能在极大提升时间性能的基础上,获取更好的分类性能。同时,对任务的终止状态进行细粒度的多分类结果,便于云平台系统的调度决策,提升云平台的运算性能。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
小学生学习指导(高年级)(2021年3期)2021-04-06 08:49:44
铁道通信信号(2020年10期)2020-02-07 01:01:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:10
三门峡职业技术学院学报(2019年1期)2019-06-27 07:32:58
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
红土地(2016年7期)2016-02-27 15:05:54
中国卫生(2014年7期)2014-11-10 02:33:04
