
联合多重卷积与注意力机制的网络入侵检测
2021-07-28 04:51:52朱金奇马春梅邹馨雨
天津师范大学学报(自然科学版) 2021年3期
曹 轲,朱金奇,马春梅,杜 恬,邹馨雨
(天津师范大学计算机与信息工程学院,天津300387)
随着网络技术的不断发展,网络渗透、网络入侵和网络病毒等网络安全问题的出现愈加频繁,给网络的正常使用带来极大隐患.因此,网络安全成为人们关注的焦点[1].目前,入侵检测是确保网络信息安全的主要手段,其目的是识别网络数据流中的恶意流量和拦截网络攻击.然而,由于因特网业务量的爆炸式增长,网络流量类型日益复杂,尤其在5G网络大规模应用后,网络流量类型更加多样,给入侵检测技术带来了巨大挑战[2-3].如何高效识别恶意流量,并准确区分不同类型的恶意流量,是衡量入侵检测系统性能的关键.
现有的入侵检测系统可分为两类:传统方法或基于机器学习的方法[4-9]和基于深度学习的方法[10-15].早期的入侵检测研究多使用模式匹配算法,文献[7]对入侵检测中的模式匹配算法进行了总结.模式匹配方法存在低准确率、高误报率的缺陷.随后机器学习方法被用于入侵检测.文献[8]提出基于支持向量机(SVM)的特征选择和分类方法,并在NSL-KDD cup 99数据集上进行实验.文献[9]在最近邻结点算法KNN分类器的基础上结合k-均值聚类设计入侵检测系统,使用NSL-KDD数据集进行实验,结果表明所提方法大大提高了KNN分类器的性能.但上述方法需要进行大量的数据预处理和人为特征选取,所以基于机器学习的入侵检测模型仍有很多不足.随着人工智能的发展,深度学习算法在图像分类、机器翻译和人体行为识别[16]等任务中表现出较好的性能,一些基于深度学习理论的入侵检测方法也被提出.文献[10]将循环神经网络(recurrent neural networks,RNN)应用于入侵检测,并使用RNN的变体构建入侵检测模型.文献[11]建立了长短时记忆(long-short term memory,LSTM)网络[17]对入侵流进行分类.但上述研究缺少对数据流深层关键特征的提取,仅单纯进行了数据流特征的学习.文献[12]搭建卷积神经网络(convolutional neural networks,CNN)进行入侵检测,并使用UNSW-NB15数据集[18]进行实验,实验结果表明,除攻击类、模糊类和通用类数据流外,其他类型攻击流均无法被检测出来.因此,CNN虽然可以提取数据流的深层特征,但对数据流的分类检测能力不强.文献[13]基于双向长短时记忆网络(BLSTM)设计入侵检测模型,并在NSL-KDD数据集上进行实验,但其实验所用数据集不完全具备最新的网络入侵流特征.文献[14]从UNSW-NB15数据集中选取样本,建立双向RNN网络,选择5个特征进行数据流分类,该工作只选择了部分数据集并且选取的入侵流特征不全,因此其检测能力不具有代表性.文献[15]构建稀疏自编码器进行数据降维,搭建RNN模型进行特征提取,使用时序生成器处理数据,得到了较高的入侵流识别准确率,该模型的数据预处理、模型预训练以及特征选择工序比较复杂,且自编码器对数据的处理是有损的,只能处理与训练样本类似的数据,在处理海量且复杂多样的入侵流时存在不足.
本文联合多重卷积、注意力机制(attention mechanism)[19]和基于CuDNN(深度神经网络的GPU加速库)加速的LSTM网络,建立了一种入侵检测模型CAL(Convolution-Attention-LSTM).该模型结合网络流的结构特点与网络攻击突发性的特点,在多重卷积后加入注意力层进行数据流深层关键特征的自动提取;通过池化计算压缩特征,加速模型收敛,以提高模型泛化能力,防止过拟合;使用LSTM充分学习数据的上下文特征和时序信息,以提升相关入侵流的检测能力.将CAL模型在完整的UNSW-NB15数据集上进行实验,并与已有的检测模型进行对比,结果表明,CAL模型在入侵流检测准确率和入侵流类型检测分类方面均优于已有模型.
1 模型构建
本文建立的入侵检测模型CAL结构如图1所示.模型由输入层、多重卷积层、注意力层、池化层、基于CuDNN的LSTM层和多重全连接层等部分组成.输入层以网络流数据作为模型的输入;多重卷积层使用3层多卷积核的卷积神经网络对数据进行特征提取,得到数据流的深层特征;注意力层得到卷积层提取的深层特征后,运用注意力机制计算数据的注意力权重,加权平均细化数据特征,并从中提取出具有判别性的关键特征;池化层通过池化计算来压缩从注意力层得到的数据,以提高下层网络的处理效率,加速模型收敛;为进一步提高模型的特征学习能力和处理效率,在池化层后加入基于CuDNN加速的LSTM层学习数据内的上下文和时序特征;最后将处理后的向量特征输入多重全连接层进行特征融合,以softmax逻辑回归层进行最终分类,输出分类结果.
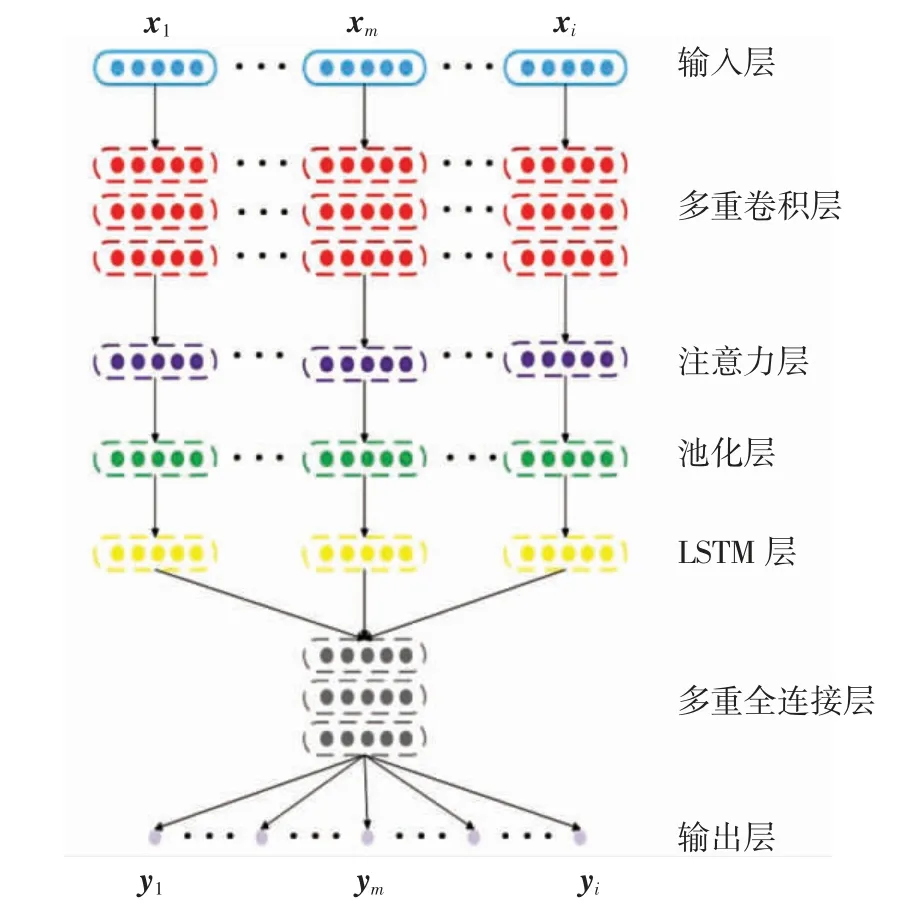
图1 CAL模型结构Fig.1 Structure of CAL model
1.1 数据预处理
由于网络流特征较为复杂,大都以浮点数为主,而网络协议、状态和服务这3个特征的值是英文表达.为便于处理,将网络协议、状态和服务这3个特征的所有特征值映射到0至200范围的整数值上,然后对这3个以整数值表示的特征和其他以浮点数表示的特征进行数组化表示,以符合神经网络的输入标准.同时,为避免数据过大而导致的数据溢出或权重不平衡,将数据规范化处理到0至1范围内,这样有利于消除原始数据对模型训练的影响.
1.2 多重卷积层
卷积层包含连续的3层卷积,第1层卷积负责提取一些低级的边缘特征,第2和第3层卷积利用低级的特征进行迭代提取,获得数据流全局的更深层更复杂的特征.第1层卷积使用双曲正切激活函数,第2和第3层使用指数线性单元激活函数,具体如下:
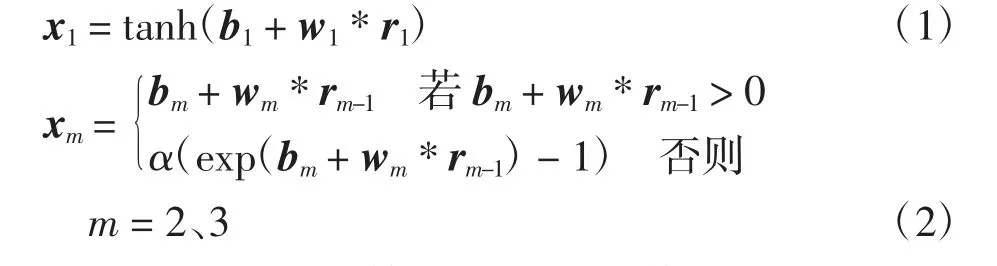
式(1)和式(2)分别为第1层卷积和第2、3层卷积的的计算过程,其中:xm为第m层卷积的输出;bm为偏置参数;rm为数据特征值;wm为卷积核;“*”表示卷积运算.
1.3 注意力层
为获得对入侵流具有判别性的关键特征,提高检测精度,本文引入注意力层以使模型可以动态地关注有助于执行当下决策的数据特征.注意力层负责计算多个向量或向量组的加权平均.注意力机制对每个从卷积层输出的数据流向量组计算注意力分布,得到注意力权重,最后加权得到数据流最终的向量表示.注意力权重系数αi为

其中:xiT为网络流深层特征的特征向量;xw为上下文相关的选择向量,用来评估xiT的重要性.加权得到的向量特征s为

1.4 池化层
池化计算用来压缩数据和减少参数数量,以减小计算量,提高下层网络的处理效率,同时防止过拟合,提高模型整体的泛化能力和收敛速度.池化层的操作与卷积层基本相同,下采样的卷积核对输入的向量取对应位置的最大值,其计算过程为
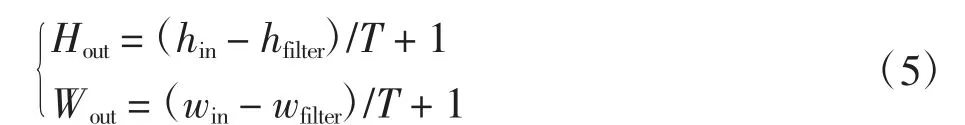
其中:Hout和Wout为输出向量的高度和宽度;T为滤波器每次扫描的步长;hin和hfilter分别为输入向量和滤波器的高度;win和wfilter分别为输入向量和滤波器的宽度.
1.5 CuDNN-LSTM层
为进一步提高模型对网络流的分类能力,引入基于CuDNN的LSTM网络来学习数据流的上下文特征和时序信息.当信息进入LSTM层后,神经元判断它对决策是否有用,无用信息则会被遗忘门遗忘,门控循环单元通过不同的时间信息计算隐藏单元在时间步长t的激活值[20].LSTM内部的计算流程如图2所示,其神经元的计算过程为
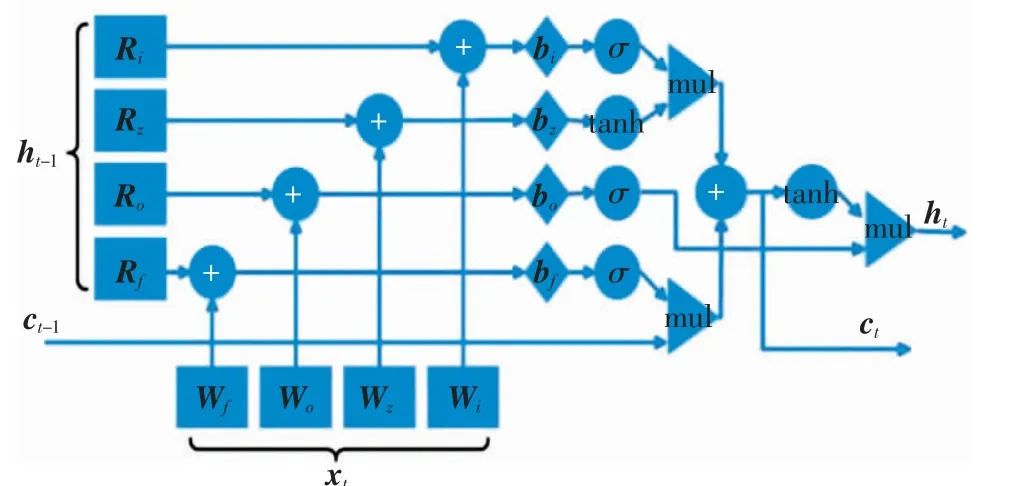
图2 LSTM计算流程Fig.2 Computing flowchart of LSTM

其中:xt为当前时刻上层神经网络输入的特征;Wi、Wf、Wo、Ri、Rf和Ro为权重矩阵;bi、bf和bo为偏置向量;σ和tanh为激活函数;ht和ht-1分别为当前时刻和上一时刻的输出;it、ft和ot分别为输入门、遗忘门和输出门的输出;ct为细胞状态;⊙表示矩阵的Hadamard积.
作为一种非竞争性的NMDA受体拮抗剂,有效剂量的氯胺酮可以抑制NMDA受体活性,对电针刺激不反应的Nep模型进行逆转,并联合脊髓电针对疼痛治疗,可以进一步将疗效增强。最新研究也显示[4],将低于1 mg/kg的氯胺酮应用在缺血性疼痛与癌痛治疗中,容易取得较为明显的疗效,可以减少阿片类镇痛药物的用药,从而将不良反应减少,达到减轻患者痛苦。其他非选择性NMDA受体拮抗剂,包括美金刚、去甲右美沙芬等灯光,这些对于NeP患者也可以发挥显著的镇痛效果。
2 实验与性能分析
2.1 UNSW-NB15数据集
UNSW-NB15数据集样本数量大,特征复杂,所含攻击类型多,是入侵检测的基准数据集之一.该数据集涵盖1种正常类和9种攻击类共10种网络流类型,9种攻击类分别为分析类(Analysis)、后门类(Backdoor)、拒绝服务类(DoS)、攻击类(Exploits)、模糊类(Fuzzers)、通用类(Generic)、侦察类(Reconnaissance)、外壳代码类(Shellcode)和蠕虫类(Worms).UNSWNB15数据集分为训练集和测试集,共257 670条数据,训练集共175 340条数据,测试集共82 330条数据,数据集中的记录没有冗余.每条数据具有44个特征,如表1所示,特征1~30是从数据包中收集的综合信息,31~37是网络连接特征,38~42是通用特征,43为攻击类型,44代表是否为攻击流的标签信息.本文使用UNSW-NB15的训练集训练模型,使用其测试集评估模型性能.

表1 UNSW-NB15数据集特征列表Tab.1 List of features for UNSW-NB15 dataset
2.2 实验评估与设置
使用准确率(accuracy,ACC)、检测率(detection rate,DR)、虚警率(false alarm rate,FAR)和假阳性率(false positive rate,FPR)[21]等4个指标评估入侵检测模型的性能.表2为用于评估实验的混淆矩阵.

表2 混淆矩阵Tab.2 Confusion matrix
ACC、DR、FAR和FPR的计算公式为
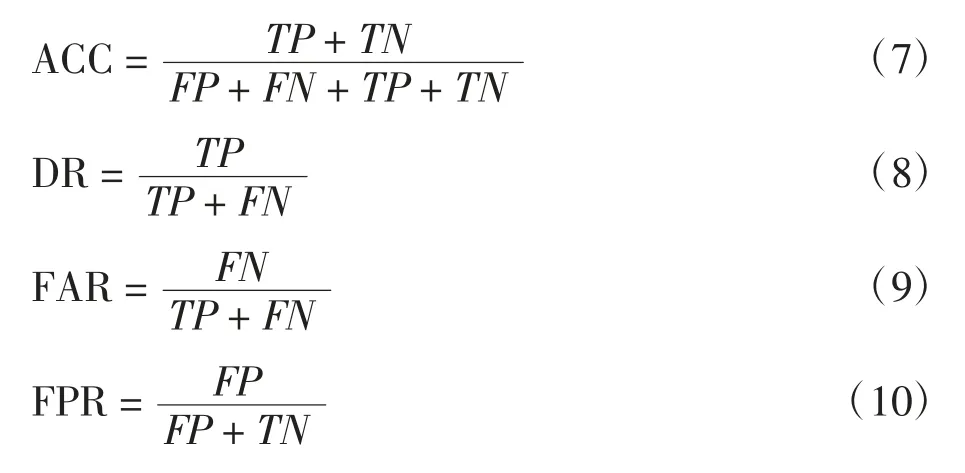
实验采用基于TensorFlow的深度学习框架Keras,使用python编程,python版本为3.6,服务器显卡为NVIDIA RTX2080TI,显存为10 GB.
2.3 模型训练
模型训练包括前向传播和后向传播.在前向传播中,输入的数据顺次经过多重卷积层、注意力层、池化层和CuDNN-LSTM层,前向传播完成后得到网络流分类的结果.模型的反向传播过程使用Adam优化器优化,学习率设置为0.001.由于UNSW-NB15数据集中有部分特征数据为0,所以本文使用稀疏多分类对数损失函数减小数据的稀疏性对损失评估的影响.模型利用前向与后向传播获得目标函数对于各网络层权重的导数后,通过随即梯度下降来最小化目标函数,从而完成训练过程.在数据集上进行了100次迭代训练,从中选择准确率最高的参数作为模型参数,并在测试集上进行实验.
2.4 实验结果分析
2.4.1 二分类实验
二分类实验是将数据流的预测结果分为2类:正常和攻击.表3为CAL模型在UNSW-NB15测试集上生成的混淆矩阵,可见大多数的样本数据位于混淆矩阵的对角线上.由二分类混淆矩阵的数据计算得正常样本的FPR为2.33%,攻击样本的DR为97.67%.

表3 CAL模型的二分类实验混淆矩阵Tab.3 Confusion matrix for dichotomous experiment of CAL
图3为模型在训练集和测试集上进行100次迭代的准确率,由图3可见,迭代84次时,模型在测试集上的准确率达到90.37%,同时在训练集上的准确率达到94.41%.以上结果表明CAL模型在二分类实验中体现了良好的检测性能.
2.4.2 多分类实验
多分类实验将数据流的预测结果细分为前述的10种数据流类型(1种正常类和9种攻击类).图4为这10种数据流类型的混淆矩阵,由图4可见,Normal、Exploits、Reconnaissance和Generic等类型的大多数样本都在矩阵对角线上,而Analysis、Backdoor和DoS类型因为样本数量太少没有体现出很好的检测率.
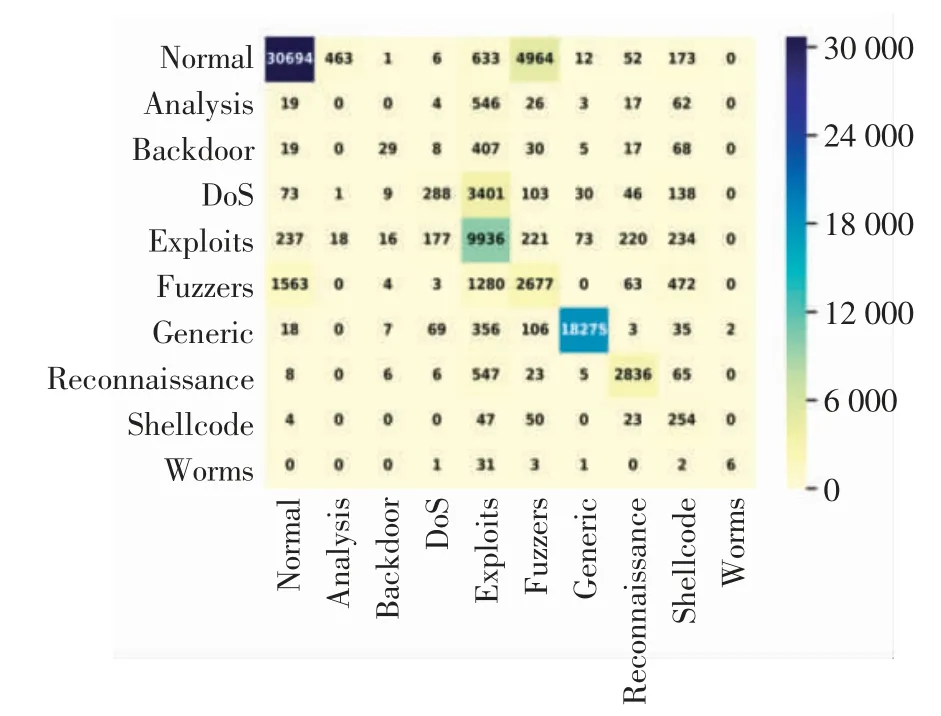
图4 CAL模型的多分类实验混淆矩阵Fig.4 Confusion matrix for multi-type intrusion experiment of CAL
表4为每个类型对应的DR和FPR,由表4可见,Generic入侵流检测率最高,为96.84%,而Analysis入侵流因为样本数量太少导致特征并没有被很好地学习,因此未被检测出.此外,10种类型都显示出较低的FPR,其中Backdoor、Generic和Worms入侵流的FPR几乎为0%,而最高的Exploits为10.18%.
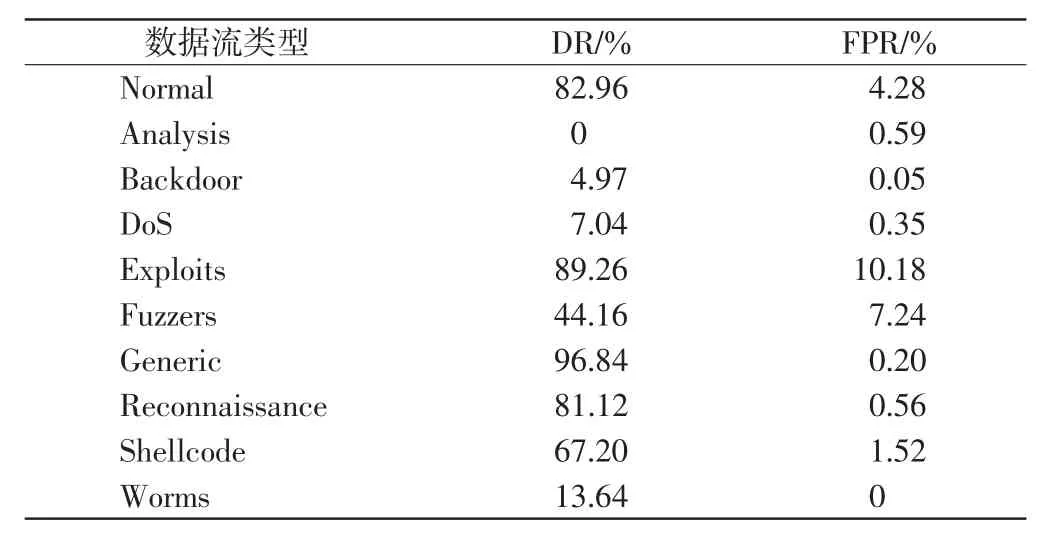
表4 CAL模型多分类实验的DR和FPRTab.4 DR and FPR of multi-type intrusion experiment of CAL
图5为模型在训练集和测试集上进行100次迭代的准确率,由图5可见,迭代59次时,模型在测试集上的准确率为78.94%,在训练集上的准确率为82.90%.多分类实验相比二分类实验检测难度要高出许多,并且其中一些类型因为样本数量太少导致检测失效,所以模型检测性能有所波动.
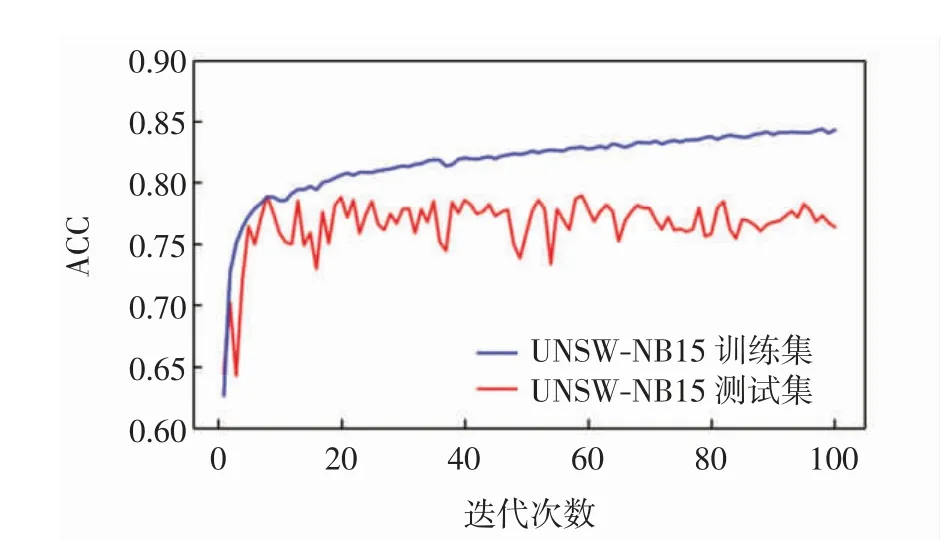
图5 CAL模型多分类实验的准确率Fig.5 ACC of multi-type intrusion experiment of CAL
2.4.3 与其他方法的比较
将本文所提入侵检测模型CAL与其他方法进行实验比较,包括HNGFA[22]、SVM[23]、LR(logistic regression)、DT(decision tree)、NB(naive Bayes)、RF(random forest)[24]和LSTM模型,在UNSW-NB15测试集上进行实验.
表5给出了二分类实验中不同模型的ACC和FAR.由表5可见,CAL模型的性能均为最优,CAL模型的ACC仅略高于HNGFA模型,但CAL模型的FAR为10.46%,显著低于HNGFA的13.03%,说明CAL模型具有优势.
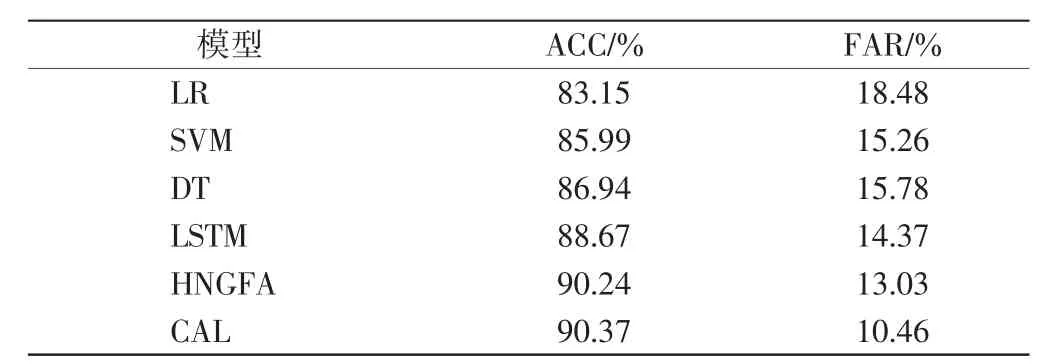
表5 不同模型的二分类实验结果Tab.5 Results of dichotomous experiment of different models
表6给出了多分类实验中不同模型的ACC和FPR.由表6可见,CAL模型在多分类实验中的ACC和FPR均优于其他方法.与其他方法相比,CAL模型在处理复杂困难的数据流分类时,因为采用了卷积层和注意力层进行特征提取,并且引入LSTM层学习数据的上下文和时序特征,使得模型对数据流关键特征的提取能力更强,因此性能表现优于其他方法.
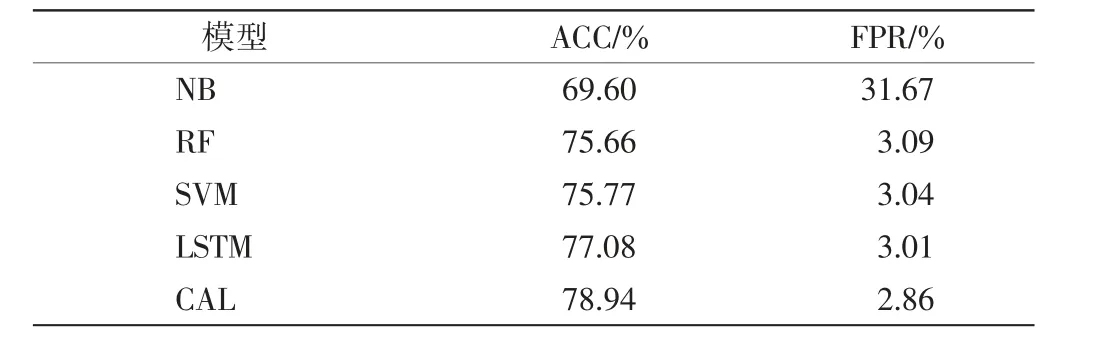
表6 不同模型的多分类实验结果Tab.6 Results of multi-type intrusion experiment of different models
3 结语
针对目前网络流类型的多样性和网络攻击的突发性,提出入侵检测模型CAL,该模型能够提取数据流深层的关键特征,在完整的UNSW-NB15数据集上进行实验,结果表明,CAL模型的识别准确率为90.37%,性能表现优于其他已有方法,并能以较高的准确率识别各种类型的入侵流.此外,CAL模型的数据预处理、模型预训练以及特征工程比较简单,适合在复杂多变的网络环境中进行入侵检测.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
汽车维修与保养(2020年11期)2020-06-09 05:42:22
数学物理学报(2019年6期)2020-01-13 06:08:16
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电脑与电信(2018年12期)2018-03-23 02:37:36
数学物理学报(2017年5期)2017-11-23 07:51:31
西北工业大学学报(2015年3期)2015-12-14 13:08:48
中国卫生(2014年7期)2014-11-10 02:32:54
