
基于大数据技术的人才智能推荐方法
2021-07-27 02:59魏云东
计算机与现代化 2021年7期
魏云东
(北京市中小企业信用再担保有限公司,北京 100010)
0 引 言
就业问题是当今社会难题之一,人力资源市场提供的信息平台成为了很多求职者选择工作和企业招聘人员选择岗位相关人才的场所之一。但是在网络大数据爆炸的今天,人工查询相关岗位或人才信息的招聘和求职方式已经不能满足日益增长的求职和人才需求[1-2]。大数据技术是以大规模数据为基础,利用各种算法挖掘数据背后隐藏的具有利用价值的信息。机器对于大数据技术开发的每一个阶段都是有帮助的,因此大数据分析的每一个阶段都涉及很多传统算法以及机器学习算法[3-4]。将大数据技术应用到人力资源市场中可以帮助提高求职和人才招聘过程的智能化程度,实现智能岗位和人才匹配,促进社会就业[5-6]。鉴于此,本文将梯度提升树算法与卷积神经网络算法相结合,用于人力资源市场的人才智能推荐,以期提高人力资源市场的信息化程度。
1 人才推荐算法模型构建
1.1 基于流式分布式的人才信息采集与预处理
本文使用分布式云集群方式进行数据采集。在进行人才信息采集时,首先与合作企业进行多数据来源渠道确认,最后将数据类型按照需求类型进行数据源分类,分配多个执行线程。系统的子服务器以任务列的形式动态收集不同类型的数据,并且实时进行更新[7-8]。图1是使用流式分布式进行数据采集的流程图。
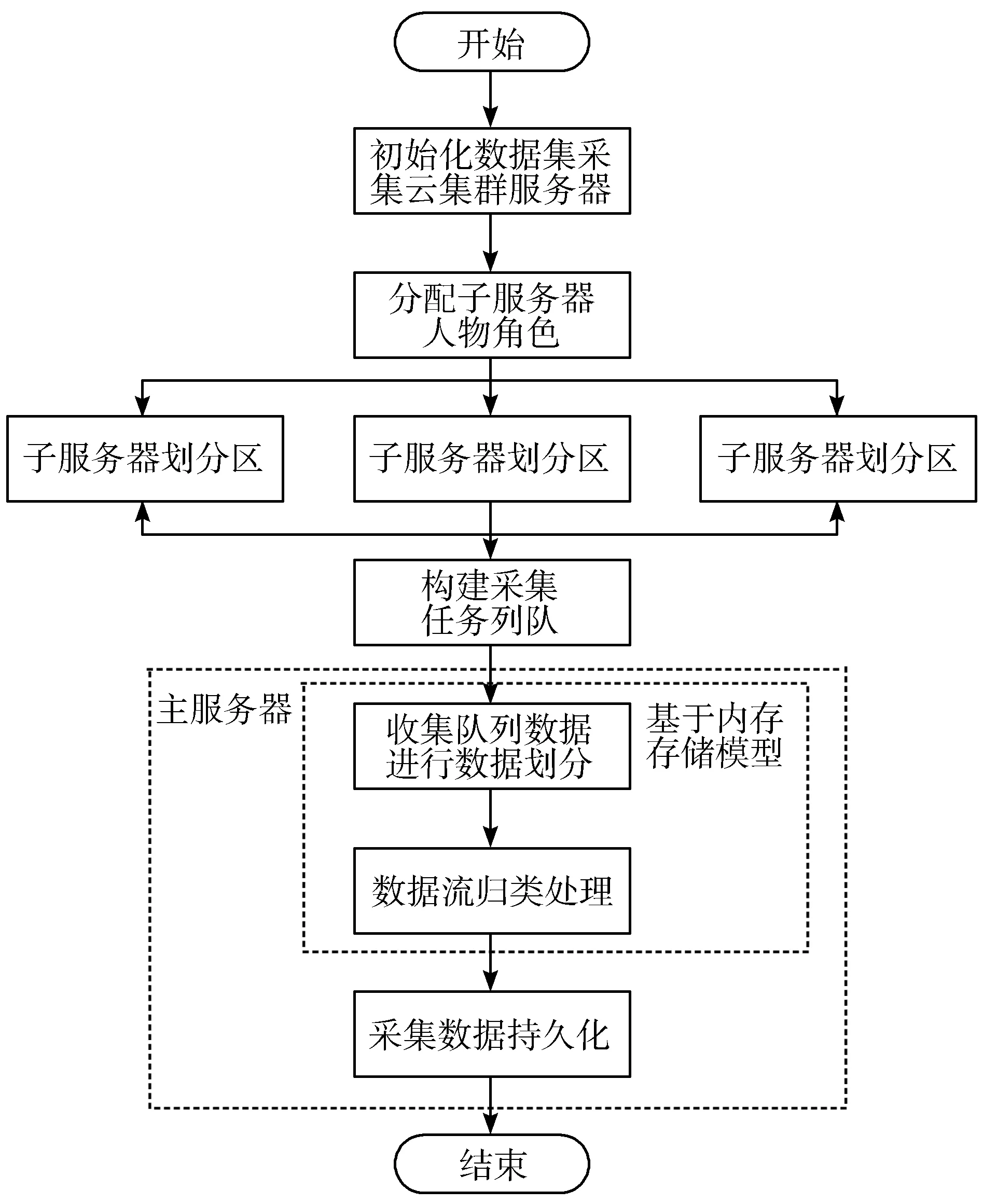
图1 流式分布式数据采集流程图
图1显示的流式分布式人才数据采集流程主要包含数据汇集模块和数据归类模块。数据汇集模块可对不同的采集来源进行分类,并根据此信息分区关联,构建相应的任务队列。数据归类模块则是以时间片为单元进行微量批处理,形成的数据流可供后续人才推荐使用。
本文采集的数据主要包括求职人员的个人信息(编号、性别、年龄、联系方式、教育背景等)、工作岗位要求基本信息(岗位类型、工作内容、工作时间等)、求职人员用户行为信息(用户行为类型、发生时间等)。但是经过流式分布式数据采集之后获取的信息不能直接用于后续算法的模型训练,部分信息可能存在重复采集、缺失不完整和无效填写等情况[9-10]。因此,数据采集完成之后需要进行数据清洗、抽取和转换的预处理,保证收集信息的可用性。
就业市场人才的数据信息包括求职岗位所属行业,包括“教育”“互联网”“销售”等;薪资取值包括“2000元以下”“2000元~3000元”等。这些信息无法被计算机系统直接识别和使用,因此需要对其进行编码转换[11-12]。图2是以求职岗位为例的人才信息独热编码化示意图,本文为每个不同类型的人才信息划定唯一的独热编码。该编码可以作为后续核心算法的输入内容。
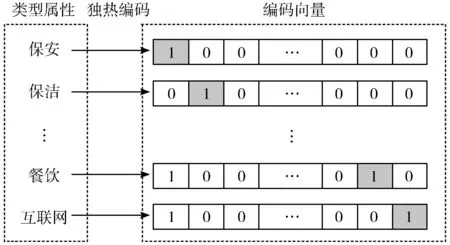
图2 岗位所属行业信息独热编码化示意图
1.2 基于梯度提升树的特征转换
对人才信息进行独热编码处理之后,编码数据可作为算法输入内容,但是由于人才信息数据量过于庞大,影响后续梯度提升树的特征转换和算法处理速度[8-9]。本文使用Embedding操作对独热编码进行降维处理。
yz=F(Wzxz+bz)
(1)
公式(1)中的yz是降维后的向量;xz为需降维的输入特征,z为其索引值;Wz表示mz×nz的矩阵;bz表示向量偏差项;F(·)是激活函数,属于非线性类型。
进行降维处理之后的人才信息使用梯度提升树的特征转换能力进行特征筛选和编码。在梯度提升树的构建中,构建每棵子树的过程是有监督的编码过程,提升树模型对特征属性进行分类的规则即为叶子节点,从根节点至叶子节点的过程便是样本划分过程[13]。梯度提升树模型中自带的属性划分规则对编码格式为0/1序列的向量进行类别特征判断,当前树模型类别特征中对应叶子节点的元素值为1,其他叶子节点元素值为0[14-15]。相似地,梯度提升模型中的多棵决策树会对降维之后的独热编码针对其类别特征进行分类,所有特征组合即可得到转换后的新特征,特征转换的操作示意图见图3。
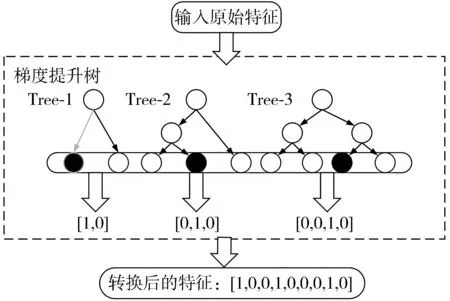
图3 特征转换流程图
图3中的3棵决策树分别对应求职人员的个人信息、工作岗位要求和行为信息。求职人员的原始信息输入梯度提升树之后,分别落在3棵决策树的第1、2、3个叶子节点上,经过决策树特征分类之后的求职人员个人信息、工作岗位要求和行为信息可分别表示为[1,0]、[0,1,0]、[0,0,1,0]。将所有的特征组合起来,形成新向量[1,0,0,1,0,0,0,1,0],该向量即可反映求职人员的所有信息。
(2)
1.3 基于混合卷积神经网络的人才推荐生成模型
对大量数据进行挖掘的时候,神经网络算法比传统算法更具优越性,数据量越大,神经网络的预测结果更加精准[16]。本文使用模型堆叠集模式训练混合卷积神经网络模型,生成最终推荐结果。
一般而言,卷积神经网络的基本结构包括特征提取层和特征映射层[17-18]。本文使用的混合卷积神经网络结构如图4所示,输入层的输入数据为经过梯度提升树处理之后的人才信息,通过多个卷积层的运算提取信息核心特征[19-20]。拼接之后的数据在卷积与局部连接混合进行高层特征抽象学习之后,得到网络的推荐预测概率pCNN和pLC。对pCNN和pLC平均化处理之后将该求职人员划分为“推荐”和“不推荐”2类。
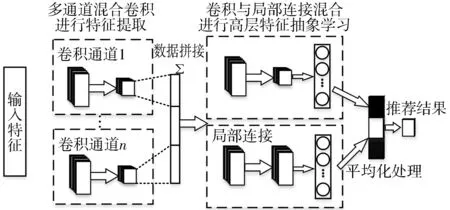
图4 混合卷积神经网络结构图
交叉熵损失函数是用于训练混合卷积神经网络的损失函数[21],其表达式如式(3):
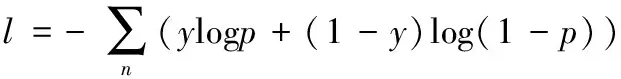
(3)
其中,p表示样本的预测概率;y表示样本实际的类别标签。
根据公式(3)可计算图4中对某一求职人员的推荐概率值和真实推荐结果之间的误差。如果模型计算结果不符合实际要求,模型反向传播,以更新参数最小化目标损失函数,获取新的推荐概率。若推荐概率符合要求,则完成本次训练;否则再次更新权重计算概率直至满足要求。
本文设计的多通道混合卷积中每个卷积通道的模型都是由2个卷积层和一个最大池化层构成,搭配ReLU非线性激活函数,因此在组成结构上是一致的,每个通道卷积操作的算法如式(4):
ci=F(Ki×X+bi)
(4)
其中,i表示第i个卷积通道,Ki表示对应卷积通道不同尺寸的卷积核,用于进行不同特征的学习;不同卷积通道的卷积处理结果用ci表示;X为输入数据,bi为对应通道卷积操作的偏置量,F(·)表示非线性激活操作。多通道卷积处理的结果为:
c=[c1,c2,…,cn]
(5)
公式(5)中的c为所有卷积处理后的组合结果。多通道化卷积操作可以将特征的整体抽象特性很好地保存下来,并且还有利于抑制过度拟合,让混合卷积神经网络模型的分类效果更好。
图4中的卷积与局部连接混合子模型主要由2个模块构成,即局部连接模块和卷积处理模块,公式(6)为局部连接操作的算法表达式:
lc=F(Kp×XT+b)
(6)
其中,b为不同卷积操作的偏置项;K为卷积操作的权值共享化过滤器,Kp为局部连接操作的非权值共享化过滤器。卷积模块包括了一个最大池化层和2个卷积层,ReLU为卷积模块的激活函数,局部连接模块的激活函数也是ReLU,该模块包含了2个局部连接层。卷积操作和局部连接操作后续都需要通过基于ReLU激活函数的全连接层,输出维度大小分别为512、256和64,并通过基于Sigmoid激活函数的全连接层得到推荐预测概率。
2 人才推荐模型效果分析
2.1 实验数据集
本文将采集的人力资源数据集划分为2类,分别为算法训练数据集和算法测试数据集,比例为9∶1。模型得出的推荐结果为“推荐”或“不推荐”,样本也对应划分为“正样本”和“负样本”。正样本表示发生了岗位浏览、申请和收藏的样本,负样本表示无任何交互行为的样本,亦或是被用户设置为对岗位不感兴趣的样本。研究构建的数据集中有11726名求职人员,由于某些求职人员对多个岗位产生求职意向,因此数据集中的工作岗位有48658个,推荐的正样本数为275362条,负样本数为182454条。经过预处理和划分处理后,推荐的正样本数与负样本数的比例约为1.5∶1,比例比较均衡。本文使用精确率、召回率以及F1-Score来评价人才推荐系统的推荐效果:
(7)
(8)
(9)
公式(7)、公式(8)、公式(9)分别是推荐精确率、召回率以及F1-Score的计算公式。FNR为推荐给求职人员不感兴趣的岗位数量;TR表示给求职人员正确推荐的他们真正感兴趣的岗位数量;FR表示错误推荐给求职人员并不感兴趣的岗位数量。
2.2 人才推荐模型的可行性验证
为了验证本文设计的基于大数据技术的人力市场人才推荐算法设计思路的可行性,将不集成梯度提升树的混合卷积神经网络算法、梯度提升树、基于梯度提升树的混合卷积神经网络算法三者进行对比实验,分别命名3类算法为A、B、C算法,对比结果如图5与表1所示。
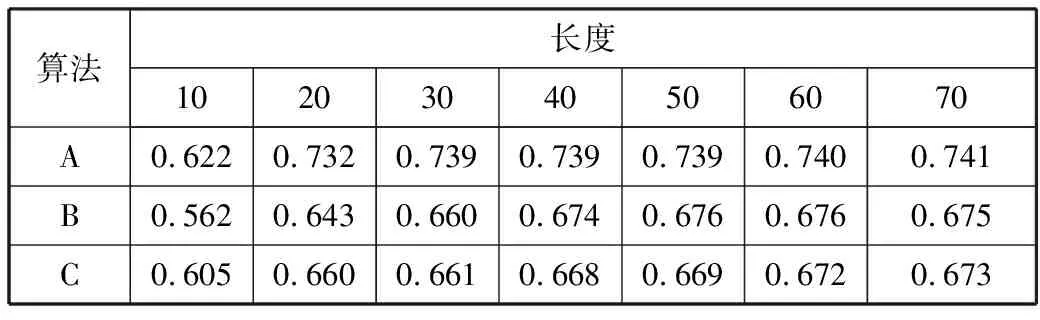
表1 3类算法推荐人才的F1-Score验证结果
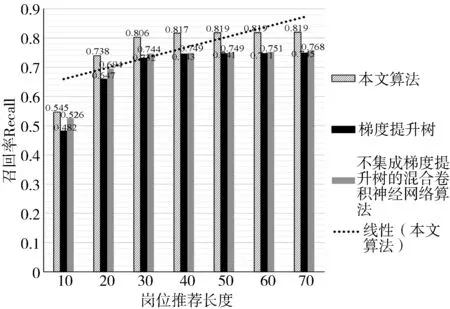
图5 算法的召回率实验对比图
从图5可以看出,在任一推荐长度下,本文构建算法的召回率均高于其他的算法,并且在一定范围内,召回率与岗位推荐长度成正比。在推荐长度为70的时候,本文设计的算法的召回率约为0.819,梯度提升树和不集成梯度提升树的混合卷积神经网络算法的召回率分别约为0.745和0.768,本文设计的算法在召回率上优于传统人才推荐算法。
从表1可以看出,当推荐长度为70的时候,基于梯度提升树和神经网络的人力资源推荐算法的F1-Score在0.741左右,而另外2种算法的F1-Score分别约为0.675和0.673。由此可以看出,本文算法优于其他2种算法。综上分析可知,在这2种推荐质量评价标准中,本文算法在召回率和F1-Score上分别至少提高了9.78%和10.1%,这表明了通过梯度提升树转换的方式可以更好地发挥卷积的作用,提高模型的推荐质量。
图6是本文算法与传统的ItemCF(Project based collaborative filtering algorithm)、PMF(Matrix decomposition based on probability)、UserCF(User based collaborative filtering algorithm)、CBF(Content based recommendation algorithm)、DNN(Four layer deep neural network)等算法的召回率对比结果。当岗位推荐长度为70的时候,本文算法的召回率约为0.821,而UserCF、ItemCF、CBF、DNN和PMF算法的召回率分别大约为0.576、0.663、0.685、0.685、0.685,由此可以看出,本文算法在召回率的指标上相对于目前常用的算法能取得更好的效果。
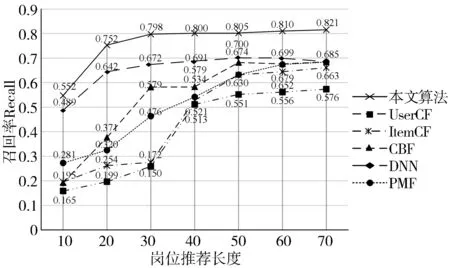
图6 各算法的召回率实验对比
从图7可以看出,当岗位推荐长度为70时,本文算法的F1-Score约为0.738,而UserCF、ItemCF、CBF、DNN和PMF算法的F1-Score分别大约为0.466、0.516、0.610、0.640、0.596,表明本文算法更具有优势。综上可知,本文验证了基于梯度提升树和神经网络的人力资源推荐算法对提高人力资源推荐质量的有效性。
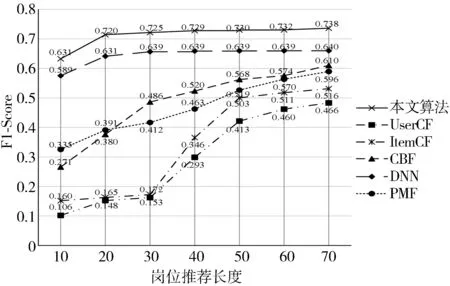
图7 各算法的F1-Score实验对比
3 结束语
目前,国内大多人力资源信息平台都使用的是搜索关键词或者岗位性质这样的传统推荐方式,不仅浪费时间,还很难实现精准匹配。本文利用大数据技术深入挖掘求职人员信息和工作岗位信息之间的联系,将梯度提升树算法和卷积神经网络算法相结合,应用于人力资源市场领域。特征的转换处理是在梯度提升树中进行的,高维抽象特征在混合卷积中进行提取,从而提高人力资源推荐质量。通过验证本文算法的性能以及与传统常用推荐算法的对比分析,当岗位推荐长度为70的时候,本文算法的F1-Score约为0.738,召回率约为0.821,高于其他算法,说明本文算法能够明显提高人才推荐质量。但是本文构建的模型缺少实际的应用测试,后续还需要进行实际应用以改进存在的不足。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
北京航空航天大学学报(2021年9期)2021-11-02
应用数学(2020年2期)2020-06-24
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
数学年刊A辑(中文版)(2018年2期)2019-01-08
北京航空航天大学学报(2018年1期)2018-04-20
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
