
基于自然语言识别的上海市报警灾情数据识别及其气象灾害特征分析研究
2021-07-26 09:07杨辰,潘顺,严岩
自然灾害学报 2021年3期
杨 辰,潘 顺,严 岩
(上海市气象灾害防御技术中心,上海 200030)
上海是一个特大型城市,人口密度高,经济密度大,城市运行极易遭受气象影响[1-2],同时在全球气候变化的大背景下,各种自然灾害和极端气候事件的发生频率和强度也呈现出逐渐增强的趋势[3-4]。近年来,上海灾害性天气时有发生,2018年更是在1个月内接连遭遇3次台风的直接登陆,给城市的安全稳定运行带来了较大的挑战。
目前已有不少学者开展了针对气象灾害的时空特征分析及风险评估研究,但所用灾害数据大多来源于气象信息员上报及相关灾情普查资料[5-9],受制于灾情收集渠道,数据量较为有限,且从灾害发生到数据收集入库往往需要较长的时间,难以支撑对受灾情况进行快速分析研判的需要。近年来,随着互联网和社交平台的发展,利用微博来获取灾情和检测突发事件的相关研究也越来越多,但主要涉及地震等灾害的识别[10-12],专门针对气象灾害方面的研究较少[13-15],且微博数据中混杂了大量的非灾害信息,增加了信息识别和数据清洗的难度。相比之下,110灾情数据具备较为规整的地址和灾害描述信息,且数据的时效性较强,可支持基于灾情信息的准实时分析研判,对于城市运行气象风险具有较好的指征意义。因此本文利用上海市应急联动平台接报的110气象灾情数据进行挖掘分析,并基于关键词识别+LDA方法实现对气象灾情的主题建模,在此基础上,结合气象观测数据开展了灾情分布的特征分析,为气象灾害的快速识别匹配和结构化提取提供了一定的技术支撑,同时也为基于灾情信息的城市精细化管理决策提供了参考。
1 研究资料与方法
1.1 研究资料
数据资料主要包括2010-2019年的气象灾害数据及同期气象观测数据。灾害数据来源于市民电话报警,通过接警员将报警电话记录为文字描述信息录入系统,并经由上海市应急联动平台实时接入上海市气象局值班业务平台,数据字段包括日期时间、事件发生地址、接警员记录的灾情文字描述以及根据报警人所在位置识别的经纬度信息等。由于灾情经纬度识别为报警人所在位置,在异地报警的情况下,经纬度坐标会存在较大偏差,因此本文在进行空间位置匹配分析的过程中,基于百度地图开放平台[16]和高德开放平台[17]提供的接口对报警信息中记录的灾情发生地址进行经纬度解析,并剔除与原经纬度偏差大于0.05°的灾情记录。由于暴雨、大风等气象灾情主要发生在6-10月的汛期,其占比超过10a全部灾情数的95.5%,因此本研究选用6-10月的灾情数据进行分析建模,所用灾情数据共计32349条。
气象观测数据包含了2010-2019年共254个自动气象观测站记录的雨量、气温、风速、风向等信息,时间分辨率为1 h。为保证数据的连续性,研究中剔除了数据记录时段不足研究时段30%的站点,最终选取了143个自动气象站参与分析。在与降雨和大风灾情的匹配分析中,按经纬度位置分别获取距离灾情位置最近和次近的气象站信息,如距离最近的自动站点该时次缺测数据,则采用次近站点的同时次数据进行填充,用于暴雨和大风的致灾条件分析。
1.2 方法
由于110气象灾情具备较完整的案发地址和灾情文字描述,因此本文基于上述文本信息,在R语言环境下,采用Jieba中文分词引擎进行分词,并对分词后的文本进行停用词处理,在此基础上,采用关键词提取与隐含狄利克雷分布(LDA)相结合的方式对灾情描述信息进行主题聚类,识别暴雨、大风、雷电和冰雹四类气象灾种,并进一步分析气象灾害的时空特征,以及致灾的气象条件。
1.2.1 中文分词
中文分词就是将中文语料按照一定规则重新组合成词序列的过程。目前常用的中文分词工具有ICTCLAS、SegmentCN、Jieba等,本文选用JiebaR分词包进行灾情文本的分词处理,并采用混合分词引擎,即结合最大概率法和隐式马尔科夫模型的方式进行。由于该分词方法的效果与分词词典有很大关系,因此本文针对灾情描述信息采用Jieba自带的分词词典,而对于灾情地址信息的提取,则基于搜狗细胞词典中的“上海地名街道名”词库[18]进行处理。
1.2.2 停用词处理
停用词是指文本中那些没有实际意义但又可能大量出现的词项,比如“的”,“是”等等。这些词使用频率过高,往往会对分析造成干扰,因此需要进行停用词处理。本文根据110灾情信息的特点,除了识别常用的中文停用词以外,还去除了诸如“上址”、“到场”、“民警”、“通知”、“分局”等词项。
1.2.3 LDA主题聚类

注:图中α和β分别为θ和φ的超参数; θ表示文本下主题的分布; φ表示主题下词项的分布; Z表示某词项所对应的主题; wt表示构成某文本的词项; N表示词的个数; M表示语料库中文本的数量; k表示某文本所可能具有的主题数。
LDA(隐含狄利克雷分布)是由Blei等人[19]于2003年提出的三层贝叶斯主题模型,其结构包含文本层、主题层以及单词层,目的是通过无监督学习的方法从文本中发现隐含的语义维度。LDA模型的基本思想是每条文本由多个主题以多项式分布构成,每个主题又由多个单词以多项式分布构成,而多项式分布的先验概率分布为狄利克雷分布[20]。LDA目前被广泛应用于文本主题识别、文本分类、文本相似度计算等文本挖掘的热门研究领域[21]。图1为LDA的贝叶斯网络图。
本文基于关键词识别+LDA的方法对灾情描述信息进行主题聚类,由于雷电和冰雹灾情占比很少,因此首先基于关键词提取的方式,识别雷电和冰雹灾种,然后基于R建立语料库,结合LDA主题模型参数先验知识[22]得到经验性取值方法,对暴雨和大风进行文本分类。经过以上分类处理后,得到近10a中6-10月的气象灾害共32 294条,其中暴雨灾害16 866条,大风灾害14 859条,雷电灾害517条,冰雹灾害52条。
1.2.4 TF-IDF关键词提取
在对气象灾情进行分类的基础上,利用TF-IDF(词频-逆文档频率)算法提取主题对应的关键词,TF-IDF可以识别在灾情描述中出现次数较多并且很少出现在其他文本语料中的词项,从而突出不同灾种对应的灾情影响及承灾体等关键词信息。任何给定词项的逆文档频率定义为[23]:
(1)
其中,ndocuments为语料库中的文档总数,ndocuments containing term为包含该词项的文档数。
2 结果与分析
2.1 灾情类别分析
2.1.1 气象灾害分类准确度检验
根据本文预设的主题数,基于关键词识别+LDA方法共分类了暴雨、大风、雷电和冰雹四类气象灾情。为了检验模型主题分类的准确性,本文以分类灾情数为单位采用分层随机采样方法,从每一类结果中分别随机抽取10%的样本,总计3 230个样本参与人工检验判别,检验结果如表1所示。
从混淆矩阵(表1)中可以看到,基于关键词识别+LDA方法可以较好地对上海汛期的气象灾情类别进行识别和提取,分类总体精度达到98.9%,可以满足对气象灾害快速识别提取的需要。除雷电和冰雹外,暴雨、大风灾情的分类精确率分别达到98.9%和96.5%,其中风灾的误判主要集中在台风天气导致的次生灾害,如造成的道路塌陷及道路护栏被积水冲散等;而暴雨分类中同样存在部分与大风灾情的混淆。此外,人工判别还识别出部分非气象灾害,如非气象原因造成的小区停电以及水管爆裂导致的路面积水等。

表1 气象灾情分类人工检验结果Table 1 Results of the manual test for meteorological disasters classification
2.1.2 灾种对应词频比较分析
图2为暴雨和大风灾情的词项频率分布图,图中所出现的词项在暴雨和大风灾情描述中至少都出现过一次。可以看到图中接近直线的词在两类灾情中具有相似的频率,如“车窗”、“摔倒”、“路口”、“马路”,以及高频端的“台风”、“轿车”等,而远离直线的词表示在不同灾种的灾情表述中出现频率存在较大差异。例如,在大风灾情中频繁出现的“砸坏”、“刮倒”、“大树”、“广告牌”、“信号灯”等词很少在暴雨灾情中出现;同样,“抽水”、“水深”、“家中”、“进水”、“积水”等词项和描述水深的关键词(如脚踝、膝盖、大腿等定性描述以及不同数字和“厘米”或“公分”组合的定量描述)则很少在大风灾情中出现。

图2 暴雨和大风灾情词项频率分布Table 2 Frequency distribution of torrential rain and gale disaster terms
2.1.3 类型关键词及词云分析
采用TF-IDF方法分类别进行关键词提取,并基于提取的关键词进行词云分析。可以看到暴雨灾情关键词中“积水”和“进水”的占比最高,其次为“家中”、“轿车”等承灾体描述,以及“水深”、“膝盖”、“抛锚”等受灾程度的表述。同样,大风灾情中,主要关键词为“轿车”、“树”、“雨棚”、“电线”等承灾体信息以及“砸坏”、“吹倒”、“掉落”等灾害影响描述。

注:图a为所有灾种的词云,图b、c、d分别为暴雨、大风和雷电灾种对应的词云。
2.1.4 灾情共现词项分析
词项网络图(图4)可以分析灾情描述中成对出现的词项频率,并对该关系网络进行绘图。从暴雨(图4a)和大风(图4b)的词项网络图中都可以看到一些清晰的聚类,如暴雨灾情中,“积水”、“公分”、“家中”、“膝盖”、“消防”、“水深”、“轿车”等形成了比较显著的词项聚簇;而对于大风灾情,“台风”、“伤”、“树”、“轿车”、“砸”、“影响”、“交通”、“车道”等词项同样存在较强的聚类现象。分析表明灾情描述中的关键词均存在较强的共现情况,可以形成较为清晰的聚类结构。

图4 暴雨和大风灾情的词项网络Fig.4 Term network of torrential rain and gale disasters
2.1.5 灾害承灾体和受灾影响分析
基于上述关键词提取结果,文中还进行了暴雨、大风和雷电灾种的灾害承灾体分析,并进一步区分为一级承灾体和次级承灾体。结果表明,暴雨灾情中,73.9%的承灾体信息可以经由灾情描述进行识别和提取,其中,房屋、车辆和道路的受灾比例最高,占比分别达到38.6%、27.4%和13.4%;对于大风灾害,可以识别98.9%的承灾体信息,受灾比例最高的承灾体分别是树、房屋和雨棚,占比分别达到21.5%、13.1%和12.8%,此外,大风灾情描述中还可以提取出较多的次级承灾体信息,其中以大风吹倒行道树或吹落构筑物砸坏车辆的占比最高,表明大风灾情具有一定的传递作用;对于雷电灾害,可以识别97.9%的承灾体信息,受灾比例最高的承灾体分别为电力设施、房屋和电线。
在此基础上,本文还针对暴雨灾情中积水深度的定量表述进行了识别和提取,并将诸如“脚踝”、“膝盖”、“大腿”等文字描述分别转换为定量的积水深度。结果表明,积水深度以30~50 cm的频次为最多,其次为10~20 cm,对于个别区域如地下室、车库等也出现过报警描述超过200 cm的积水灾情。
2.2 灾情时间分布特征
从灾情逐年分布(图5(a))可以看到,近10a上海6-10月的110气象灾情年际差异较大,灾情发生最多的是2012年,为9 679条,最少为2010年,仅124条。近10a中受灾较为严重的年份分别是2012年、2013年和2019年,而台风和持续性强降水是造成灾情大量爆发的主要原因。2012年上海受“海葵”台风影响,2012年8月8日-8月9日,48小时接报灾情8 328条(暴雨灾情2 998条,大风灾情5 324条,雷电灾情6条),占该年度6-10月灾情总数的86%;2013年受“菲特”台风和“0913”强降雨影响,灾情数分别为4 542条和966条,占该年6-10月灾情数的85%;2019年上海接连遭遇“利奇马”、“米娜”台风影响,分别造成了4 568、1 123起气象灾害。
灾害的逐月分布(图5(b))上,8月份气象灾害发生数量最多,为18 268条,占近10a中6-10月灾情总数的56%,其次为10月份的6 144条,占灾情总数的18%,再次为6月份的3 513条,占比11%。
本文还分别统计了工作日(图5(c))和非工作日(图5(d))气象灾情的逐小时分布,可以看到工作日的灾情分布呈现出明显的双峰特征,早高峰出现在08时,近10a灾情数为1 617条,晚高峰出现在16时,灾情数为2 178条,与市民出行的早晚高峰时间基本对应;节假日的灾情时间分布同样呈现出双峰特征,但早高峰不明显,7-10时灾情都呈现出高发趋势,同时晚高峰的时间较工作日有所提前,出现在15时,灾情数为967条。
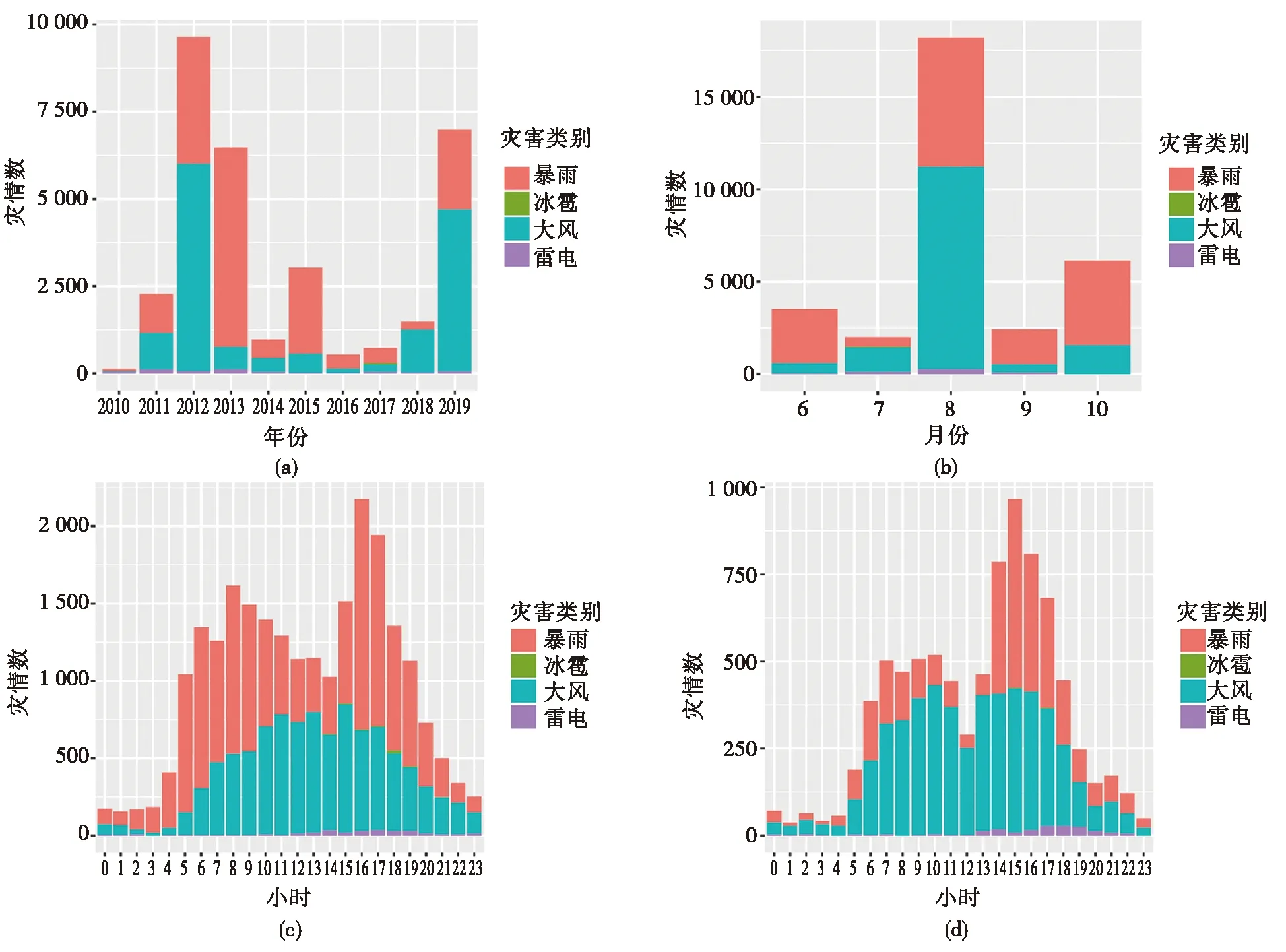
图5 2009-2018年6-10月气象灾情时间分布Fig.5 Temporal distribution of meteorological disaster from June to October during 2009-1018
2.3 灾情空间分布特征
2.3.1 灾情密度空间分析
暴雨(图6(a))和大风(图6(b))的灾情空间分布较为一致,灾情密度都以中心城区为最高,分别为77个/km2和47个/km2,其次为紧邻中心城区的外环以内区域以及各区的城市副中心,如嘉定镇、宝山友谊路街道、奉贤南桥镇、浦东惠南镇以及青浦和松江城区等,总体上看暴雨和大风灾情的高发区域都与城市人员密集区相重合。

图6 灾情核密度图Fig.6 Kernel density map of disaster
2.3.2 基于中文分词的灾情路段分析
根据搜狗细胞词典中的“上海地名街道名”词库进行受灾路段的提取,结果表明,在暴雨和大风影响下,部分路段多次受灾。其中“沪青平公路”、“共和新路”、“场中路”、“沪太路”、“浦东大道”等路段遭受暴雨和大风灾害都较为频繁,受灾年份主要集中在2012年、2013年、2015年和2019年,与灾情逐年分布趋势相吻合。除以上路段外,暴雨灾情中,“真南路”、“沪松公路”、“北青公路”等路段历史上受灾次数也较多;大风灾情中,受灾较多的路段还包括“沪南公路”、“川南奉公路”和“龙吴路”等,如图7所示。

图7 灾情发生路段频数分析Fig.7 Frequency analysis of roads where disasters occurred
2.4 气象与灾情的特征分析
2.4.1 暴雨致灾气象条件分析
分析发生暴雨灾情对应的整点时次以及灾情发生前1~23 h有观测记录的自动站小时雨强,绘制暴雨致灾雨量时序分布图。从图8中可以看出,平均小时雨强和小时雨强最大值均出现在暴雨灾情发生前1 h,说明短时强降雨是引起暴雨灾害的主要因素。此外,灾情发生前1~3 h的降雨强度呈现逐渐降低的趋势,表明暴雨致灾还存在一定的累积效应,长时间的较强降雨同样是引发内涝灾害的重要因素。

2.4.2 大风致灾气象条件分析
分析发生大风灾害对应的整点时次以及灾害发生前1-23 h有观测记录的自动站小时极大风速,绘制大风致灾风力时序分布图。从图9中可以看出,平均小时极大风速最大值同样出现在大风灾害发生前1 h,且在大风灾害发生前,随着时间推移,小时极大风速平均值逐渐减小,但风力极大值相差并不明显,表明大风报灾存在一定的延后效应,而瞬时大风是致灾的主要原因。
3 结论与讨论
研究基于R语言环境,以2010-2019年气象灾情数据为研究资料,采用Jieba中文分词引擎对自然语言描述的气象灾情进行分词,并对分词后的文本进行停用词处理。在此基础上,采用关键词提取与LDA相结合的方法对灾情描述信息进行主题聚类,识别暴雨、大风、雷电和冰雹四类气象灾害。结果表明,采用关键词提取和LDA相结合的方法可以较好地对上海汛期的气象灾害类别进行识别和提取,分类总体精度达到98.9%,可以满足对气象灾害快速识别提取的需要。
在灾情分类的基础上,本文还进一步分析了暴雨和大风灾害的词频和关键词特征。结果表明,暴雨和大风灾情中,除了部分词项在两种灾情描述中均较为常见以外,大多数的词项分布存在较为明显的差异,且高频词大多包含承灾体和灾情影响的表述信息。此外,暴雨和大风灾情词项均存在较强的共现情况,可以形成较为清晰的聚类结构。基于灾害承灾体和受灾影响的进一步分析表明,暴雨灾情中,房屋、车辆和道路的受灾比例最高,占比分别达到38.6%、27.4%和13.4%,在受灾程度方面,积水深度以30~50 cm的频次为最多,其次为10~20 cm,个别区域如地下室、车库等也出现过报警描述超过200 cm的积水灾情。对于大风灾害,受灾比例最高的承灾体分别是树、房屋和雨棚,占比分别达到21.5%、13.1%和12.8%。此外,大风灾情描述中还可以提取出较多的次级承灾体信息,其中以大风吹倒行道树或吹落构筑物砸坏车辆的占比最高,表明大风灾害具有一定的传递作用。
本文还分析了灾害发生的时空分布特征,并结合气象观测数据,分析了暴雨和大风灾害的致灾气象条件。结果表明,近10a上海市6-10月的110气象灾情年际差异较大,受灾较为严重的年份分别是2012年、2013年和2019年,而台风和持续性强降水是造成灾情大量爆发的主要原因;灾害的逐月分布上,8月份气象灾害发生数量最多,其次为10月份。灾情的逐时分布呈现出双峰特征,且工作日更为明显,早晚高峰分别对应08时和16时。暴雨和大风的灾情空间分布均以中心城区为最高,其次为紧邻中心城区的外环以内区域以及各区的城市副中心,且基于路名提取结果,“沪青平公路”等6条路段遭受暴雨和大风灾害都较为频繁,受灾年份主要集中在2012年、2013年、2015年和2019年。此外,结合气象观测资料分析,暴雨灾情中短时强降雨和长时间的较强降雨是引起暴雨灾害的重要因素,而大风灾情中,致灾主要由瞬时大风引起。
本文采用自然语言处理方法,基于110气象灾情数据进行分析,可以对影响灾种、承灾体及受灾程度等信息进行快速识别,为气象灾情的快速收集和结构化提取提供了一定的技术支撑,很大程度上解决了传统灾情收集中存在的时效性问题,也为相关研究的开展提供了一个新的思路。该研究可以对基于灾情信息的城市精细化管理决策提供一定的参考依据。此外,基于110灾情数据资料,如何采用基于数据驱动的研究方法,建立气象条件与灾情发生之间的关联,从而提高对气象灾害发生的影响预报和风险预警能力,还有待进一步研究。
猜你喜欢
东方剑·消防救援(2022年7期)2022-07-16
东方剑·消防救援(2022年1期)2022-01-17
中国石油石化(2021年16期)2021-10-14
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
哲学评论(2018年1期)2018-09-14
公民与法治(2016年17期)2016-05-17
上海理工大学学报(社会科学版)(2011年4期)2011-09-26
大家(2011年9期)2011-08-15
