
基于监督注意力机制的语义标签生成图像
2021-07-26 01:59赵文仓
青岛科技大学学报(自然科学版) 2021年4期
张 幸,王 旭,赵文仓
(青岛科技大学 自动化与电子工程学院,山东 青岛 266061)
现阶段基于深度学习的传统图像生成方法大多采用编码器到解码器(enconder-to-decoder)结构的变分自动编码器VAE[1]对高维图像的特征向量或特征矩阵进行编码和解码,或采用生成对抗网络GAN[2]通过生成器和鉴别器做对抗学习,一方面提高鉴别器对真假图像的判别能力,另一方面提升生成器的生成能力。上述两种方法在一定程度上受训练样本的制约,很难生成与输入样本风格不一的图像,常用于传统的图像到图像生成任务中。
2017年,陈启峰等[3]提出一种名为级联细化网络(cascaded refinement networks,CRN)的基于语义布局的图像生成方法,该方法采用监督训练的方式,给定语义标签,通过端到端(end-to-end)结构生成接近真实场景的图片。网络采用从低级到高级堆叠精细化模块的方式从语义标签中先生成低分辨率图像,再通过层层级联的精细化模块将分辨率提高。相比VAE、GAN 等以真实图像作为训练样本的方式,CRN 结构简单,无需编码解码和对抗训练。模型能够从语义布局中学习图像生成,由于语义标签只需存储图像的布局信息,相比RGB 彩色图像,有占用内存小,样本简单,易获取的优势。只需在任意数据集做简单语义分割即可获得,获取渠道广,通过真实RGB图像或艺术作品都能得到语义布局标签。因此可以借助CRN 通过动画、游戏场景的语义布局生成贴近真实场景的照片级图像,为数据增强提供了新思路。尤其在自动驾驶领域,基于驾驶员视角的真实场景训练图像存在获取成本高、样本量少的困境,通过竞速游戏截取图像的语义标签生成贴近真实场景的驾驶图像,为丰富自动驾驶数据集提供了帮助。该模型内部通过卷积神经网络提取和处理特征,由于卷积网络存在局部连接,生成图像中语义目标有模糊失真的现象。
2017年,何恺明等[4]在非局部神经网络(nonlocal neural networks)中提出用于卷积神经网络的自注意力机制(self-attention),以加强卷积网络输出多维特征之间的全局一致性。2018年,IAN 等[5]将自注意力机制引入到GAN 图像生成模型,提出自注意力生成对抗网络(self-attention generative adversarial networks,SAGAN),克服了卷积神经网络局部连接导致的图像到图像生成任务中语义目标模糊失真的现象。
受自注意力生成对抗网络通过注意力机制加强多维特征的全局一致性,提升生成图像中语义目标清晰度和真实性的启发,本文提出一种应用于端到端结构CRN 图像生成模型的监督注意力机制。通过建立注意力方程将第一级精细化模块的输出结果与语义标签内的高级语义特征建立联系,由模型浅层输出的全局性较好的低分辨率大感受野特征和语义标签内的高级语义特征联合得到带有全局信息的注意力特征,指导网络从全局信息中生成真实感图像,提升了模型由语义标签生成图像任务中语义目标的清晰度和真实性。
1 相关工作
1.1 级联细化网络
级联细化网络以如图1所示的精细化模块(refinement module)为主体结构,以语义布局标签L∈{0,1}m×n×c为训练样本生成真实感图像,其中m×n表示语义标签的分辨率,c 为语义标签的通道,表示其中语义类别的数量。与传统图像生成模型VAE和GAN 由RGB图像作为训练样本生成图像的方式不同,级联细化网络采用归一化的c 通道语义布局标签为样本,样本中不包含原始RGB图像的底层纹理信息,占用内存小,节省了图像生成任务中样本数据集的存储空间。
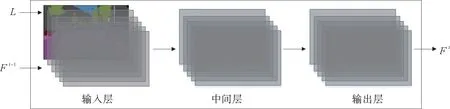
图1 精细化模块结构Fig.1 Structure of refinement module
如图1所示,精细化模块是一种卷积神经网络结构,由输入层、中间层和输出层组成,其内部结构如图2所示,包括两层卷积层、两层归一化层和两层非线性激活层。精细化模块的输入层通过卷积层1接收语义布局标签L 和上一级模块的输出特征Fi-1作为输入,经中间归一化层和非线性激活层,在最后的输出层得到该级模块的输出特征Fi。以Mi表示模型中第i 个精细化模块,每一个精细化模块输出一个固定分辨率的特征图,通过对特征图做双线性插值上采样,逐步提升图像生成的分辨率。

图2 精细化模块内部结构Fig.2 Internal structure of refinement module
通过级联精细化模块,级联细化网络由语义标签从低分辨率到高分辨率生成真实感图像,模型结构如图3所示。
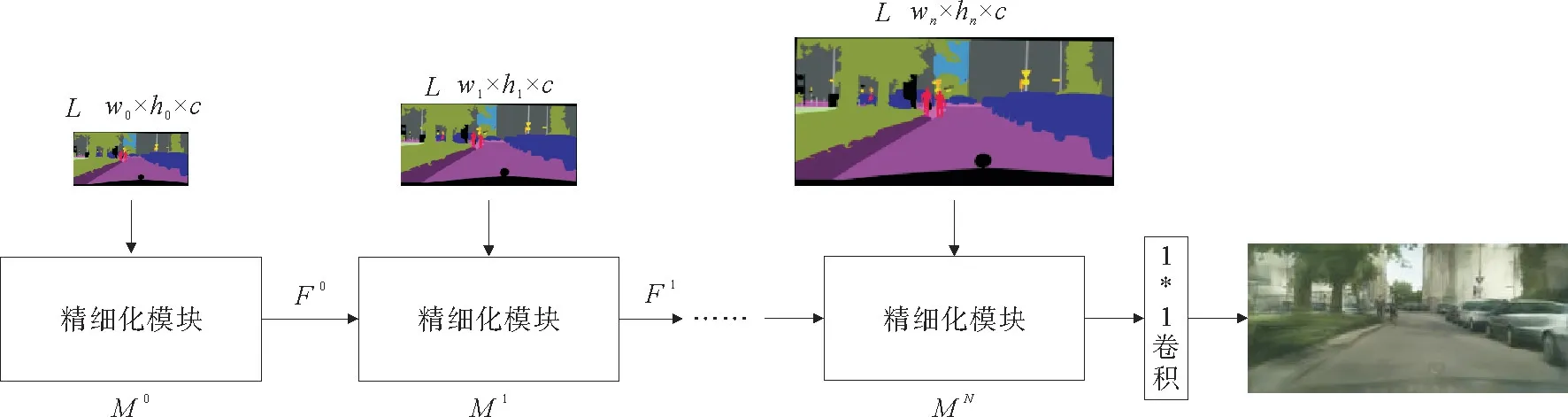
图3 级联细化网络模型Fig.3 Model of cascaded refinement networks
1.2 自注意力机制
自注意力GAN[5]模型通过引入自注意力机制,取代传统全连接层及全卷积结构,在无需为网络模型引入过多学习参数的情况下,帮助卷积网络实现了多维特征的全连接,从而获取了特征图的全局特征信息,提升了由图像生成图像任务中语义目标的清晰度和真实性。
与自注意力GAN 仅在生成的初始阶段通过鉴别器接收训练样本,中间层不再引入样本只接收输入特征的图像生成方式不同,级联细化网络模型通过语义标签生成真实感图像,在第一级精细化模块之后级联的每一级模块都同时接收上采样的输出特征以及下采样的语义标签。采用自注意力机制,在上一级输出特征中引入自身特征,难以保证该特征与语义标签中高级语义信息的全局匹配能力。本研究结合级联细化网络输入特性,对语义标签内的语义布局和几何结构特征同第一级精细化模块输出的多维特征做特征融合,通过语义标签指导第一级精细化模块输出特征在后续模块内生成更高分辨率的特征图。
2 监督注意力级联细化网络
级联细化网络是一种由低分辨率到高分辨率渐进式生成图像的模型,由于特征图低分辨率下具有大感受野,语义目标之间分布比较聚集,边缘目标被拉到了较近的特征列中表示,特征全局性较好。在第一级精细化模块输出的特征图后通过注意力机制引入语义标签与输出特征图的融合特征,能够保证多维特征较好的全局一致性。由于通过注意力机制对特征进行融合的过程,同时使用了输出特征本身和语义标签,类似由样本和标签进行训练的有监督训练方式,故本研究将这种注意力称为监督注意力(supervised attention)。
2.1 维度匹配
由于精细化模块内部卷积层的作用,语义标签L 相比第一级精细化模块输出特征F0,维度发生了改变,本研究通过network in network(NIN)模型[6]提出的1×1卷积分别作用于语义标签L 与输出特征F0,对语义标签升维的同时对输出特征降维,使二者维度保持一致。卷积神经网络GoogleNet模型[7]曾将1×1卷积加入Inception模块,对来自底层网络的特征降维,再传入后续串联的卷积核。这种1×1单核卷积的优势在于只改变特征图像的通道,而不对特征进行缩放,即不改变特征图像的分辨率。相比于传统全连接层的方式,1×1卷积大幅减少了模型的参数量。
以d0表示输出特征F0的维度,通过1×1卷积,将语义标签L 的维度由c 升维至d0//8,同时输出特征F0降维至d0//8,以保证注意力层两个输入特征的通道维度相等,使二者可做矩阵相乘,保证在合理通道下计算注意力。过少的通道可能会导致输出特征丢失细节使图像失真,过多的通道则需要引入更多参数,浪费GPU 内存。
在上述维度匹配过程,与 NIN 模型和GoogleNet模型不同,本研究仅采用1×1卷积完成升降维,并不将卷积之后的特征映射非线性激活,未引入激活函数,结构简单。
2.2 监督注意力模块
以批量大小、通道、宽、高四维张量表示语义标签L 和输出特征F0,令L∈[1,c,w,h],F0∈[1,d0,w0,h0],即每次训练采用一张c 维通道,分辨率为w×h 的语义标签,该语义标签经第一级精细化模块M0得到d0通道,分辨率为w0×h0的输出。如图4所示为监督注意力模块框图。
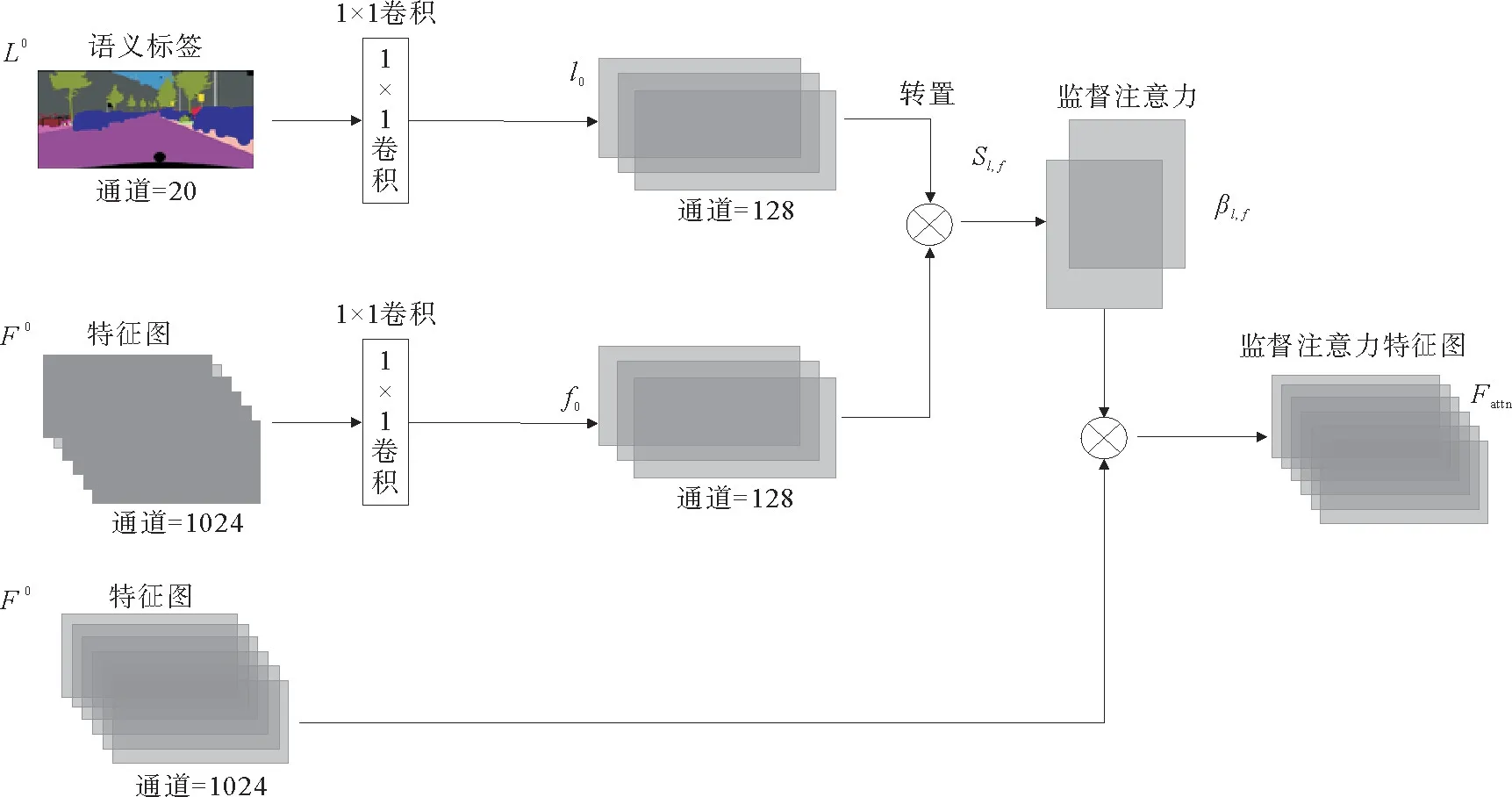
图4 监督注意力模块框图Fig.4 Framework of supervised attention module
首先,将语义标签L 下采样至分辨率为w0×h0,得到L0∈[1,c,w0,h0],L0和特征F0经1×1卷积分别映射到两个特征空间l0∈[1,d0//8,w0,h0]和f0∈[1,d0//8,w0,h0],可得到监督注意力函数:
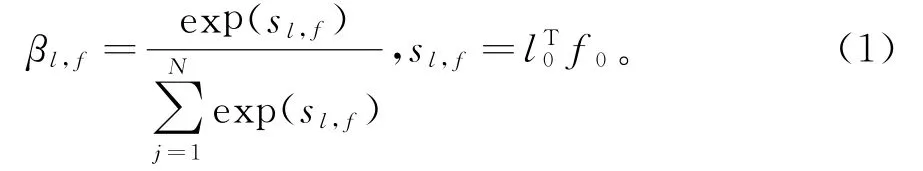
βl,f表示语义标签和第i 个精细化模块联合构成的监督注意力,其中N =w0×h0为每通道的像素点数量,矩阵sl,f表示由语义标签L 生成图像的过程中,M0输出特征F0对L 的关注程度。为方便计算,将l0和f0的每通道像素在一维展开,有l0∈[1,d0//8,N],f0∈[1,d0//8,N],则sl,f∈[1,N,N],经Softmax函数得到同维度监督注意力βl,f∈[1,N,N],相较于M0输出特征F0∈[1,d0,w0,h0],βl,f维度发生较大改变,无法直接传入下级精细化模块,还需对输出监督注意力维度还原。
将M0输出特征F0∈[1,d0,w0,h0]每通道像素点在一维展开,有F0∈[1,d0,N],本研究利用F0∈[1,d0,N]同监督注意力βl,f∈[1,N,N]矩阵相乘进行维度还原,得到监督注意力输出特征Fattn=F0βl,f,Fattn∈[1,d0,N],将一维表示的像素点还原至二维分辨率形式,有Fattn∈[1,d0,w0,h0]。
为使网络逐步适应全局特征输入,通过可学习的缩放参数α 增强带有注意力的输出特征Fattn。

其中:α 表示可学习的缩放因子,训练阶段初始化为0,经反向传播α 数值更新,逐渐增加,即网络初始训练阶段只学习简单任务,处理M0输出特征F0,随训练进行,再逐渐增加任务复杂度,学习全局特征,使网络逐步适应监督注意力。综上,得到监督注意力算法:
输入:语义标签L0,第一级精细化模块M0输出特征F0;
输出:监督注意力βl,f,监督注意力特征Fattn,可学习监督注意力特征Fout;
1)维度匹配:l0←conv2d(L0,20,128,kernel_size=1,stride=1,padding=0);f0←conv2d(F0,1 024,128,kernel_size=1,stride=1,padding=0);
2)构建监督注意力函数:sl,f←,βl,f←Softmax(sl,f);
3)输出监督注意力特征:Fattn←F0βl,f;
4)输出可学习监督注意力特征:Fout←αFattn+F0。
2.3 网络结构
本工作通过监督注意力机制在第一级精细化模块M0的输出之后引入了语义标签,通过语义标签同M0输出的每一维特征做特征融合,以此得到带有标签内语义布局、几何结构信息和每一维输出特征信息的全局监督注意力特征,保证了第二级精细化模块M1的输入特征是全局一致的。将本该下采样输入至第二级精细化模块的语义标签输入到监督注意力层,同M0输出做特征融合,提升了多维特征的全局一致性。为避免特征重复输入,本研究在第二级精细化模块M1中只输入通过双线性插值上采样的全局可学习监督注意力特征,不再单独输入下采样的语义标签,直接将上采样至分辨率8×16的1 024维可学习监督注意力输入到第二级模块。监督注意力级联细化网络模型见图5。
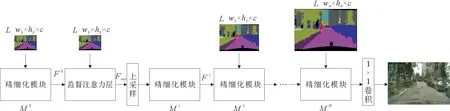
图5 监督注意力级联细化网络模型Fig.5 Model of supervised attention CRN
第一级精细化模块M0内第一层卷积接收来自数据集提供的下采样语义标签,经中间层作用输出包含局部特征的多维特征图F0,F0输入到监督注意力层,同下采样语义标签做全局特征融合,得到带有包含语义标签中高级语义特征的全局监督注意力特征,经双线性插值上采样,传入第二级精细化模块M1,通过该模块卷积层、归一化层和非线性激活层的作用,输出特征图F1,对F1上采样分辨率加倍与下采样至同分辨率的语义标签分别传入第三级精细化模块M2,经后续级联的精细化模块内部卷积层、归一化层、非线性激活层以及双线性插值做分辨率加倍的作用,最后经1*1卷积层降通道得到3通道RGB彩色生成图像。此过程同原始级联细化网络模型相同,仍旧遵循端到端结构,中间没有引入编解码器和反馈,结构简单。
3 实验及分析
3.1 实验设计及评估标准
本研究基于监督注意力级联细化网络由语义标签生成真实感图像的实验,在Linux 内核Ubuntu 16.04 系统下进行,采用一张显存为11 GB 的NVIDIA GTX 1080 Ti GPU 加速训练,编程语言基于Python 3.6.5,在Py Torch 1.0.1深度学习框架下进行。实验数据集选用Cityscapes数据集[8]和GTA 5数据集[9],训练在Cityscapes训练集2 975张精细标注的语义标签上进行,通过Cityscapes验证集[8]和GTA 5数据集[9]的语义标签测试。
级联更多精细化模块能够生成更高分辨率的图像,但同时将带来更多参数,占用更高的GPU 存储空间,受GTX 1080 Ti显存限制,实验通过语义标签生成分辨率为256×512的真实感图像。实验前,将Cityscapes训练集、验证集精细标注语义标签和真实图像缩放至256×512。实验初始化第一级精细化模块M0从4×8分辨率条件下开始生成图像,初始化M0输出特征通道d0=1 024,精细化模块内卷积层采用步长为1的3×3卷积结构,归一化层采用对纹理信息鲁棒性较好的实例归一化IN[10],以保证模型能够较好生成纹理特征。采用LeakyRe-LU 作为激活层,为网络引入非线性,防止因线性运算带来模型中间层失效。优化采用Adam 算法[11],学习率设置为0.000 1,一阶矩估计指数衰减始化为0.9,二阶矩估计指数衰减初始化为0.999,分子稳定参数设置为1×10-8,不添加权重衰减。损失优化阶段对真实图像和生成图像进行特征提取的卷积网络采用19层的VGG-19[12]。
模型训练采用单批量,遍历Cityscapes训练集200次,模型评估标准采用定性和定量3种评估方法:1)在Cityscapes验证集和GTA 5数据集语义标签上定性对比原始级联细化网络、自注意力级联细化网络和监督注意力级联细化网络生成结果;2)定量对比级联细化网络、自注意力级联细化网络和监督注意力级联细化网络训练阶段损失曲线变化;3)通过PSPNet[13]对级联细化网络、自注意力级联细化网络和监督注意力级联细化网络三种模型的生成图像做语义分割,通过平均像素精度和语义分割平均掩码交并比(mIoU)精度判断图像生成的真实度。
3.2 实验结果及分析
按照上述实验评估标准,定性对比原始级联细化网络、自注意力级联细化网络和监督注意力级联细化网络在Cityscapes验证集语义标签上的图像生成结果,如图6所示。

图6 Cityscapes验证集语义标签图像生成结果Fig.6 Images generated results in Cityscapes validation dataset
由图6,自注意力和监督注意力级联细化网络模型生成图像中的语义目标从视觉上与真实图像更为接近,语义目标相对清晰、完整。原始级联细化网络模型未对特征做全局处理,仅通过最后的全连接依靠像素矩阵简单地将局部特征图拼接组合在一起,导致生成图像中出现语义目标模糊在一起及局部语义特征丢失的现象,图像生成质量较差。原始级联细化网络模型生成的相邻在一起的汽车出现了明显的模糊重影现象。引入注意力机制的自注意力级联细化网络和监督注意力级联细化网络模型生成的汽车克服了这种失真。并且监督注意力级联细化网络生成结果相比自注意力模型在几何结构上更完整,目标更清晰,更贴近真实场景。
定性对比原始级联细化网络、自注意力级联细化网络和监督注意力级联细化网络在GTA 5数据集语义标签上的图像生成结果,如图7所示。
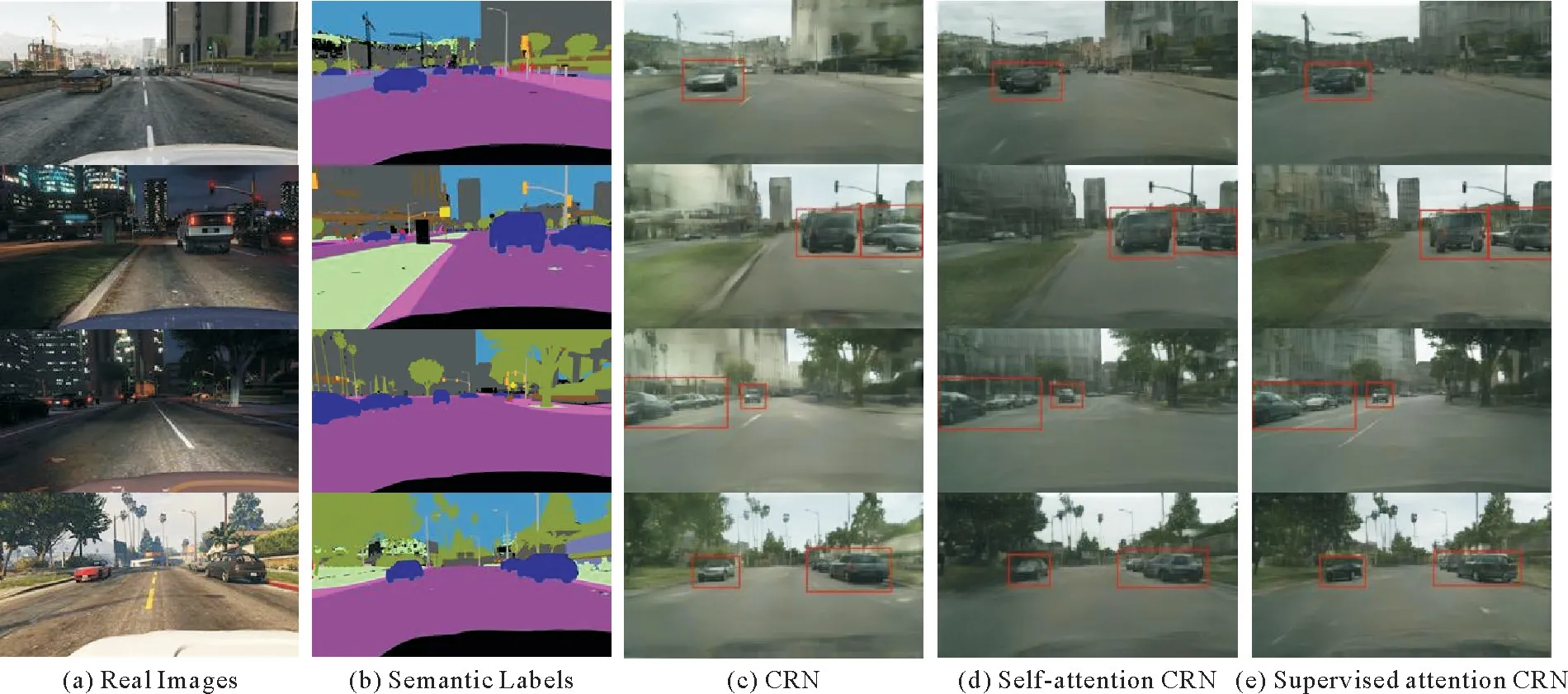
图7 GTA 5数据集语义标签图像生成结果Fig.7 Images generated results in GTA 5 dataset
由图7,GTA 5数据集图像来自游戏引擎渲染和Cityscapes图像风格差异较大,但是通过在Cityscapes数据集训练得到的CRN 模型、self-attention CRN 模型和supervised attention CRN 模型可以从GTA 5数据集的语义标签上生成与Cityscapes相同风格的图像。引入注意力机制的自注意力模型和监督注意力模型由GTA 5语义标签生成的真实感图像,相比原始级联细化网络,语义目标更清晰、完整,并且监督注意力级联细化网络的生成结果相比自注意力模型结果在几何结构上更好,极大程度地避免了语义目标的模糊重影。
根据训练阶段损失曲线变化衡量级联细化网络、自注意力级联细化网络和监督注意力级联细化网络训练生成图像对真实图像的偏离度,见图8。如图8(a)、(b)、(c)所示分别为级联细化网络、自注意力级联细化网络、监督注意力级联细化网络遍历cityscapes训练集200次得到的训练损失曲线对比。

图8 训练损失曲线对比Fig.8 Comparison of training loss
由于引入了注意力机制,对全局特征进行了调整,自注意力模型和监督注意力模型相比原始级联细化网络,经过较少次训练即可达到良好的生成效果,损失曲线收敛更快且收敛于更小值。并且由于监督注意力级联细化网络整合了更丰富的包含语义标签内语义布局和几何特征在内的全局特征,相比自注意力模型在训练阶段生成图像对真实图像的偏离度更小。
通过语义分割模型PSPNet[13]分别测试验证集生成图像的像素语义分割精度(生成图像分割掩码同语义标签的像素对比)及语义目标掩码的平均交并比精度(mIo U,对生成图像做语义分割得到的掩码和真实语义标签掩码在0.5到0.95增量为0.05的10种交并比条件下计算掩码分割精度并取算术平均),若生成图像接近真实图像,语义分割模型能将生成图像中的语义群体分割出来,并能得到较高的像素精度和mIo U 精度。表1所示为级联细化网络、自注意力级联细化网络和监督注意力级联细化网络在Cityscapes验证集语义标签上生成的图像及真实图像基于PSPNet-50[13]的语义分割结果对比。

表1 生成图像语义分割结果对比Table 1 Comparison of semantic segmentation results of generated images
在级联细化网络模型中引入自注意力机制,生成图像的语义分割像素精度相比原始级联细化网络提升了6.2%,mIo U 精度提升了22.3%。由于引入了语义标签中语义特征的几何结构信息,监督注意力级联细化网络在Cityscapes验证集语义标签上生成图像的像素精度达到了82.0%,mIo U 精度达到了70.3%,在自注意力机制的基础上像素精度提升了2.4%,mIo U 精度提升了4.4%。相比原始级联细化网络,生成图像的语义分割平均像素精度提升了8.6%,mIo U 精度提升了26.7%。监督注意力级联细化网络生成图像的语义分割结果在两种评判标准下都更接近真实图像,生成语义目标更真实。
4 结 语
结合图像语义标签改进了自注意力,提出一种应用于级联细化网络端到端图像生成的监督注意力机制,采用有监督训练的方式,将浅层网络输出低级纹理特征同语义标签内的高级语义特征结合,构建全局注意力特征。提升了级联细化网络全局信息处理能力,较大地提高了图像生成质量。无需对抗训练,可简单方便地从任意语义标签中生成真实感图像,通过为游戏截图做语义标注即可为自动驾驶数据集做大量数据增强,协助训练复杂自动驾驶模型。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
核安全(2022年3期)2022-06-29
雷锋(2021年12期)2021-04-12
有色金属材料与工程(2020年5期)2020-11-27
劳动保护(2018年5期)2018-06-05
华人时刊(2018年23期)2018-03-21
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
汽车与新动力(2014年4期)2014-02-27
