
基于多语义融合的反讽识别
2021-07-23 06:39樊小超林鸿飞刁宇峰楚永贺
中文信息学报 2021年6期
樊小超,杨 亮,林鸿飞,刁宇峰,3,申 晨,楚永贺
(1. 新疆师范大学 计算机科学技术学院,新疆 乌鲁木齐 830054;2. 大连理工大学 计算机科学与技术学院,辽宁 大连 116024;3. 内蒙古民族大学 计算机科学与技术学院,内蒙古 通辽 028043)
0 引言
反讽[1]是社交媒体中常见的修辞表达方式,其所要表达的真实意义和字面含义相反,是一种带有强烈感情色彩的修辞格,通常含有否定、讽刺以及嘲弄的含义[2]。随着社交媒体和人工智能的快速发展,如何利用计算机技术识别反讽,理解蕴含在反讽字面语义背后的真实情感表达,成为了自然语言处理领域备受关注的研究内容之一。反讽识别在反语与讽刺理论的驱动下,以认知语言学为基础构建计算模型,从而赋予了计算机从更深层次理解人类情感的能力,为实现更加智能友好的人机交互环境奠定了研究基础。从应用角度来说,反讽识别的深入研究能够促进情感分析的发展,提高情感分析任务的性能。总之,反讽识别在情感分析系统、人机对话系统、翻译系统等领域中都有着广泛的应用前景。
反讽识别任务被归结为有监督的文本分类问题,目标是判别一个句子是否包含反讽的含义。现有的反讽识别方法主要分为基于规则的方法[3]、基于统计的方法[4]和基于深度学习的方法[5-6]。基于规则的方法以反讽的理论为支撑,能够反映讽刺语句的语言学特点,但是规则的制定需要领域专家,且迁移性较差。基于统计的方法以当前的语料为基础,能够反映反讽语句的统计学特征,但是特征的构建需要耗费大量的时间和精力,泛化能力较弱。深度学习方法以大规模语料训练得到的词嵌入表示为基础,能够反映反讽语句的高维潜在语义信息,但是传统的词嵌入表示不能反映同一单词在不同上下文语境中的差异。此外,目前的深度学习方法缺乏对讽刺语句修辞特征的表征,这使得将深度学习方法应用于反讽识别领域时,其性能受到了一定的限制。
本文提出了一种基于多语义融合的神经网络模型(EPSN)来识别反讽。考虑到反讽的语境特点,采用语言模型的词嵌入表示方法(ELMo)[7]在大规模讽刺语料库上进行训练,得到了反讽相关的词嵌入表示。考虑到反讽的词性特点,对反讽语句的词性特征进行了嵌入表示。基于反讽的风格特点,从字符角度对反讽语句进行了建模。在多维语义表示的基础上,分别采用了双向长短时记忆神经网络(Bi-LSTM)和卷积神经网络(CNN)提取反讽语句的高维潜在语义特征,从而对反讽语句进行识别。本文的贡献如下:
(1) 针对反讽语句同一单词在不同上下文语境时其词嵌入表示差异较大的问题,本文采用ELMo对大规模的反讽语料库进行了训练,得到了针对反讽语料的领域词嵌入表示。
(2) 针对反讽语句修辞表达的特点,本文采用了词性向量表示,并使用了Bi-LSTM提取反讽语句的词性特征。此外,本文采用CNN提取反讽语句的字符向量特征,使模型能够获取反讽语句的修辞特征,从而进一步提高了模型识别反讽的性能。
(3) 本文提出的融合语义、词性和风格等多种特征的反讽识别模型在公开数据集IAC_v2的三个子数据集上进行了实验,结果表明,本文提出的基于多语义融合的反讽识别模型能够有效地提取隐藏在反讽语句背后的语义特征,提高反讽识别的性能。
1 相关工作
反讽作为一种修辞现象,受到语言学家和认知心理学家的广泛关注。随着情感分析技术的深入研究,反讽识别成为了自然语言处理领域的热点问题之一。对于反讽识别研究,我们根据使用的方法不同,从基于规则、基于统计的传统机器学习方法和基于深度学习的方法三个方面对前人的工作进行梳理。
基于规则的方法尝试通过制定一系列规则来捕捉反讽的语义特征。Veale等[8]指出反讽和幽默明喻的强关联性,构建了词汇选择、句法结构、语义等多种规则识别反讽。Maynard等[9]认为hashtag是推特上识别反讽的一项关键特征,并对反讽和情感文本同时进行分类识别。Bharti等[10]提出了基于语法分析的词汇生成算法和基于感叹词是否出现等规则来识别反讽。Riloff等[11]提出了一种根据规则自动学习文本中的正负情感短语的反讽识别方法。基于规则的反讽需要领域专家制定大量的规则,且规则之间容易出现冲突,其迁移性较差。
基于统计的传统机器学习方法通常基于词袋模型,根据反讽语言特点构建多种反讽相关特征,并使用传统机器学习方法进行反讽识别。Farías等[1]利用多种情感词典,挖掘句子中的情感特征,并基于语义相似度和情感相关性等语义特征识别反讽。Bamman等[5]指出推特中的作者特征、回复的文本内容等上下文特征对反讽识别起到了关键作用。Rayes等[12]对比了朴素贝叶斯和决策树算法在平衡和非平衡反讽数据集上的性能。Joshi等[13]探索了4类词向量特征在反讽识别中的性能,指出词向量的引入能够大幅度提升性能。基于特征的传统机器学习方法需要耗费大量时间精力人工构建特征,且模型的泛化能力较弱。
深度学习方法是利用神经网络结构对输入的反讽语句进行逐层筛选和提取,获得具有表征能力的特征,从而对反讽文本进行识别。Amir等[14]对社交媒体中的用户信息进行了建模,构建了用户嵌入式表示,并采用CNN学习用户信息和上下文信息进行反讽识别。Zhang等[15]采用Bi-LSTM自动提取反讽文本中的句法和语义特征,并将目标推文的历史推文作为上下文信息引入模型进行反讽识别。Ghosh等[16]利用推特的上下文信息、用户信息和时间信息作为CNN和LSTM的输入,实验结果表明,本方法使反讽识别的性能得到了显著提升。Tay等[17]指出反讽通常由于积极和消极的情感冲突或字面意与比喻意的情景矛盾而产生,作者构建了一种基于注意力机制的神经网络模型识别反讽。张庆林等[18]提出了一种对抗学习框架,在模型训练的过程中应用对抗的思想生成样本,从而提高了分类器的鲁棒性和泛化能力。目前,传统的词嵌入表示已经不能满足现有反讽识别研究,同时采用深度学习方法对于反讽语句修辞特征的建模还有待进一步探索。
2 基于多语义融合的反讽识别
本节将介绍多语义融合的神经网络模型(EPSN)框架结构。基于多语义融合的反讽识别模型通过ELMo训练得到词嵌入表示、反讽语句的词性嵌入表示和字符的嵌入表示等多种语义表示学习反讽语句的潜在语义特征,从而提升反讽识别的性能。
多语义融合的神经网络模型(EPSN)框架结构如图1所示。首先,通过ELMo模型,利用大规模反讽语料库训练反讽领域相关的ELMo词嵌入表示。其次,得到反讽语句的词性标签,将其与普通词嵌入表示联合,表示反讽语句的词性信息。通过Bi-LSTM模型提取与反讽强相关的语义特征。再次,将反讽语句表示为字符嵌入式表示,利用CNN模型提取反讽语句的风格特征。最后,将三部分语义特征融合得到反讽语句的最终表示,并进行反讽识别。接下来将详细介绍每部分的具体实现。
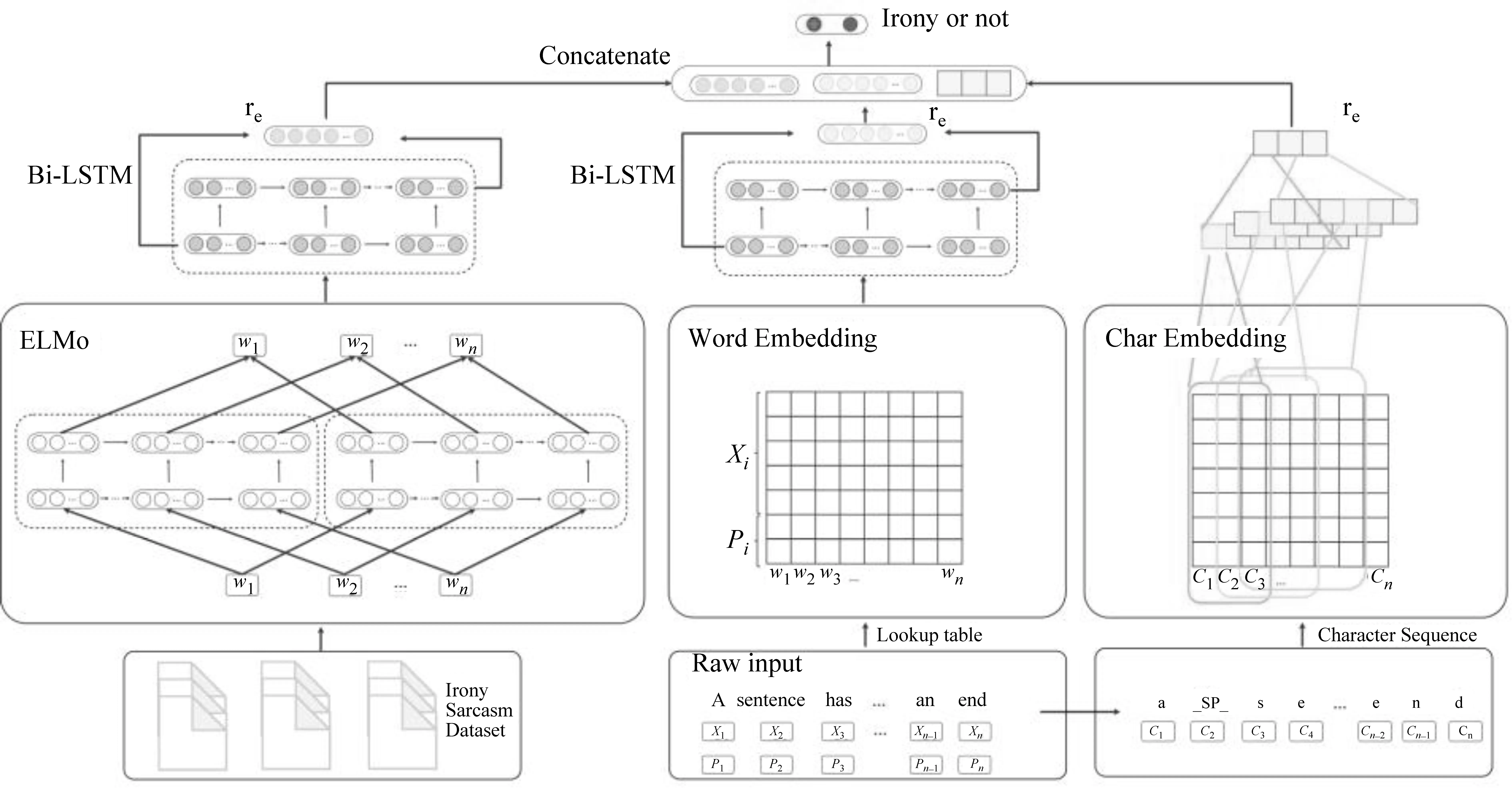
图1 多语义融合的神经网络模型(EPSN)框架结构
2.1 基于语境的反讽语义表示
传统的词嵌入表示,如Word2Vec、GloVe等,给自然语言处理任务的性能带来了巨大的提升空间,但是它们通常是上下文无关的词嵌入表示。例如,Word2Vec训练时,使用单层的神经网络模型,通过目标单词周围的若干个单词来进行预测,但是周围单词的顺序并不重要,预测结果可以认为只是统计意义上的最大概率。换句话说,传统的词嵌入表示与句法结构、特定语境、语义等关联较小。而反讽语句中,语境和语义至关重要。例如:
Visitstoadentistarefun!
其中,“fun”表示“有趣的”,通常该单词表示积极的情感,而且大多数情况下,包含“fun”的句子不包含反讽的含义。但是该句子中,“看牙医”的情景让人们普遍认为是一件不愉快的事情,因此该句为一个反讽语句。反讽语句的语境对反讽识别起着非常重要的作用,本文希望得到的词嵌入表示包含语境信息,从而更好地表征反讽语句。因此,本文采用了ELMo词嵌入表示。
语言模型的词嵌入表示(ELMo)
ELMo是一种新型的深度语境化的词嵌入表示,能够反映单词的复杂语义和语言环境信息。ELMo的词嵌入表示是整个输入语句的函数,它采用了双向语言模型来对语句信息进行建模。
对于一个给定句子的单词序列S=(t1,t2,…,tN),利用目标单词tk之前的单词序列(t1,t2,…,tk-1),即前向的语言模型计算tk的概率,计算如式(1)所示。
(1)
类似地,后向的语言模型如式(2)所示。
(2)
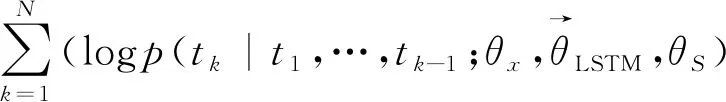
(3)
对于每一个单词,L层的语言模型计算得到2L+1的表示,如式(4)所示。
(4)
用式(5)计算特定任务的词嵌入表示。
(5)
由于ELMo学习词嵌入表示的过程不仅仅是通过目标词的窗口,而是从整个语料库学习,因此通过ELMo学习到词嵌入表示能够更好地表征特定任务的信息。本文采用了Khodak等[19]构建的大规模反讽语料库进行模型的预训练,得到反讽领域相关的词嵌入表示,该词嵌入表示包含了反讽语料的复杂语义特征,能够根据不同语境反映单词的语义信息。
2.2 基于词性信息的反讽语义表示
反讽与幽默相似,是一种文体[20],通常具有特殊的词性表达。通过词嵌入表示,模型能够自动地学习反讽语句的语义特征,但是获取的词性信息有限。
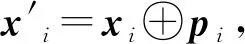
2.3 基于风格信息的反讽语义表示
风格是一种独特的表达方式,很多情况下,正是风格特征使得人们能够区分反讽文本[2]。Reyes等[12]提出风格是指多次出现的文本元素序列,这些反复出现的文本元素使得文本表现出相对稳定的特征,从而使得人们有可能识别出文本的反讽特性。该文献指出字符级的词袋模型(character n-grams)能够有效地提高反讽识别的性能。
反讽语句常采用一些修辞方法表达出反讽的效果,如押韵、重复字符、重复的标点符号等。例如:
Youhavealoooootofnerve!!!!
该句是一个反讽的语句,它采用比喻的方法表达反讽。同时,语句中采用了不规范的拼写形式“looooot”和多个感叹号加强了反讽的效果。
为了使模型能够捕获反讽语句的风格信息,本文对反讽语句的字符进行建模,将句子表示成字符的序列并最终得到句子的字符序列的嵌入表示。对于目标语句中的每个单词xi,其字符嵌入表示为xi=(c1,c2,…,cM),其中ci∈Rdc,dc为字符嵌入表示的维度。
2.4 混合神经网络模型
为了更好地提取反讽文本的特征,结合上文所述的基于ELMo、基于句法结构、基于风格的语义信息,本文提出了一种基于Bi-LSTM和CNN的混合神经网络模型。该模型主要由三部分组成: 对于基于ELMo的反讽语义表示和融合句法特征的反讽语义表示,二者均具有明显的时间序列特征,句子的语义与上下文信息紧密相关,因此本文分别使用Bi-LSTM提取二者的潜在语义信息用于反讽识别。对于基于风格信息的反讽语义表示,使用Bi-LSTM会造成长期遗忘问题,且结构化的风格信息更有助于反讽的识别,因此本文采用了CNN模型。
2.4.1 双向长短时记忆网络(Bi-LSTM)
本文利用Bi-LSTM对基于语境和基于词性的信息进行建模。LSTM由Hochreiter等[21]提出,其被广泛应用于自然语言处理任务。LSTM采用门机制和细胞的状态更新提取文本的有效信息。LSTM包括输入门it、遗忘门ft、输出门ot和细胞ct。可以用如下公式形式化地描述LSTM:
其中,xt为当前输入向量,σ为sigmoid函数,⊙表示按元素乘,W{i,f,o,c},U{i,fi,o,c},V{i,fi,o,c}为参数,ht为隐层状态向量。Bi-LSTM分别从句子的前后两个方向使用LSTM,然后合并二者的输出作为句子最终的表示。
利用Bi-LSTM对基于语境的语义信息进行特征提取,得到反讽语句的语境的高维语义表征re,同样,使用Bi-LSTM对基于词性的信息进行特征提取,得到词性的高维语义特征rp。
2.4.2 卷积神经网络(CNN)
本文利用卷积神经网络提取反讽语句的风格特征。对于反讽语句的字符嵌入表示,采用不同大小的卷积核进行卷积操作。卷积核为ω∈Rl,l为卷积窗口大小,最终得到输出特征vi,其形式化表示如式(11)所示。
rs=f(ωhi:i+l -1+b)
(11)
其中,f为激活函数,hi: i+l-1表示字符序列中第i列到i+l-1列,ω和b为参数。
利用CNN对基于风格信息的语义特征进行特征提取,得到反讽语句风格信息的高维语义特征rs。
2.5 损失函数
综上所述,本文融合基于语境信息、基于词性信息、基于风格信息的反讽语义特征,采用Softmax函数进行反讽的识别,其形式化描述如式(12)所示。
zout=Softmax(W[re;rp;rs]+b)
(12)
其中,zout∈RC为预测概率,C为类别,W和b为参数。
模型基于反向传播算法采用端到端的方式进行训练,本文采用了期望交叉熵作为损失函数。如式(13)所示。
(13)
其中,y为真实标签,y′为预测标签,i,j分别为句子的编号和类别编号,λ为正则化参数,θ为超参数。
3 实验与实验结果分析
本节首先对实验数据和实验设置进行介绍,然后详细对比分析本文提出的模型和基线模型的性能,最后通过消融实验验证所提出模型各个部分的有效性。
3.1 数据集及评价标准
本文使用了在线辩论数据集IAC的v2版本(IAC_v2)[22]。IAC_v2包含三种类型的反讽文本,包括: 普通类型(GEN)、反问类型(RQ)和夸张类型(HYP)。三个数据集均为正负例1∶1的均衡语料。数据集详细信息如表1所示。
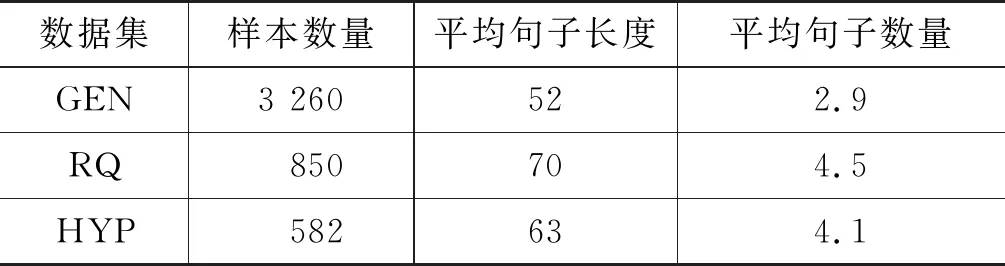
表1 IAC_V2数据集统计信息
本文采用被广泛应用于自然语言处理任务的准确率(Acc)、精确率(P)、召回率(R)和F1-score(F1)来衡量实验结果。
3.2 实验设置
ELMo训练采用了默认参数。ELMo输出的词嵌入表示维度为1 024。针对基于ELMo的语义信息和基于词性信息,本文采用了Bi-LSTM自动地学习文本特征。传统的词嵌入表示采用了GloVe训练得到的300维向量。词性标签的嵌入表示采用随机初始化方法,维度为50。Bi-LSTM隐层节点数为150,dropout为0.35。针对基于风格信息的反讽语义表示,本文采用了CNN模型。字符的嵌入表示采用随机初始化方法,维度为300。CNN模型的节点个数为100,窗口大小为[3,4,5],dropout为0.35。在训练过程中,本文采用了学习率递减策略和早停机制。本实验采用了5折交叉验证。
3.3 实验结果分析
3.3.1 不同模型的对比
为了对比本文提出的基于多语义融合的反讽识别方法的有效性,本文采用如下基线方法:
Oraby[22]: 采用n-gram和Word2Vec作为特征,使用SVM作为分类器。
S-SVMgauss[23]: 采用潜在语义分析(LSA)提取反讽文本的高维语义特征,使用支持向量机模型(SVM)进行反讽识别。
T-Log.Reg.Ll[24]: 采用潜在语义分析提取反讽文本特征的高维语义特征,使用逻辑回归模型(Log.Reg)进行反讽识别。
Poira[18]: 分别对情感、情绪和个人特征进行预训练,并采用了多个CNN的深度神经网络模型。
CNN-Adv[18]: 采用对抗生成的思想,生成对抗样本参与模型训练。
CNN-AT[20]: 基于领域迁移的对抗学习得到的反讽识别模型。
EPSN: 本文提出的基于多语义融合的神经网络模型。
表2中列出了本文提出的基于多语义融合的神经网络模型和前人工作的详细对比。
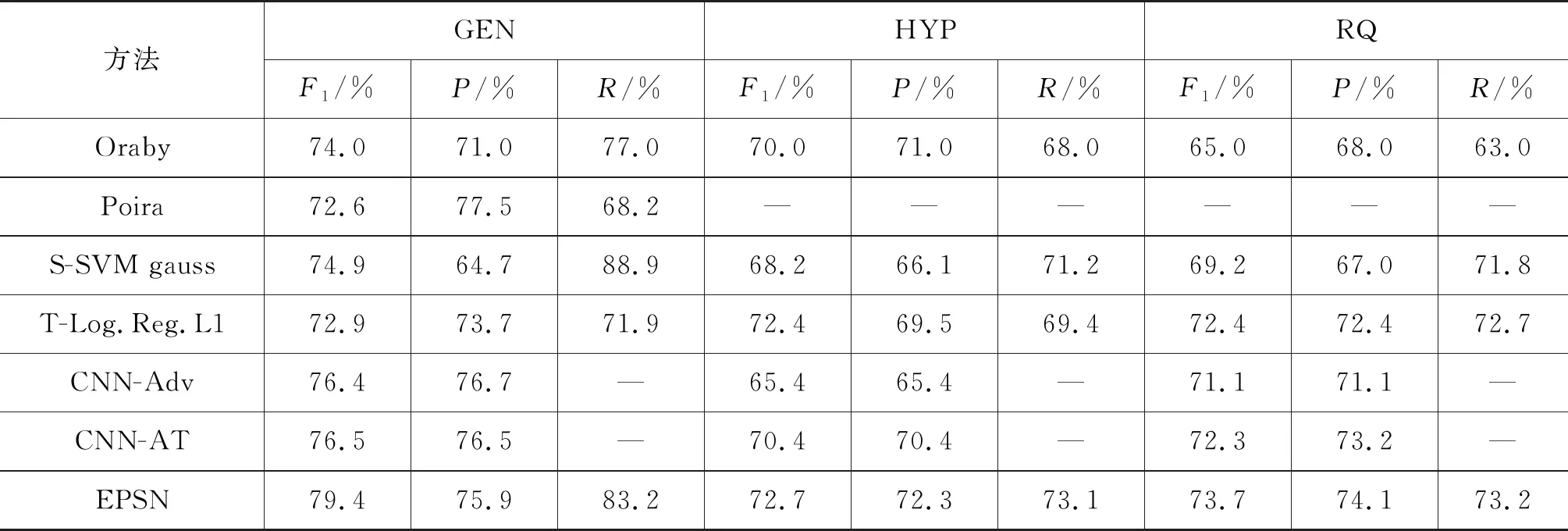
表2 EPSN验证和其他基线方法的性能对比
从表2可以看出:
(1) 基于词袋模型的传统机器学习方法性能较低,只考虑词频和简单的语义信息显然无法有效地提取反讽的特征。
(2) 采用LSA可以将词和反讽文本映射到潜在语义空间,可以在一定程度上提高传统机器学习方法的性能。Poira提出的深度神经网络模型在GEN上取得了最高的精确率,在应用了对抗生成和迁移的方法之后,反讽识别的性能在三个数据集上均有了提升,这表明基于词嵌入表示的深度学习方法能够有效地提取反讽的潜在语义特征,提升反讽识别的性能。
(3) 本文提出的方法EPSN在GEN和HYP两个数据集上的F1值提升较明显,相对于CNN-AT,在GEN上提升2.9%,在HYP上提升2.3%,而对于RQ数据提升较小,约为1.4%,这说明模型在大数据集上能够更好地学习反讽语义特征,而对于RQ数据集,其数据规模较小,采用传统的机器学习方法就能得到比较有竞争力的性能。此外,EPSN模型在三类反讽数据集上都取得最高的F1值,说明引入语境信息、词性信息和风格信息能够从不同侧面反映反讽的语义特征,提高模型识别反讽语句的性能,同时也显示出EPSN模型具有较好的泛化能力。
3.3.2 不同词嵌入表示对比
为了验证基于语境的反讽语义表示的有效性,本文对比了不同维度和不同训练方法得到的词嵌入表示的性能。对比过程采用Bi-LSTM提取高维语义特征,参数均采用相同设置。实验结果如表3所示。
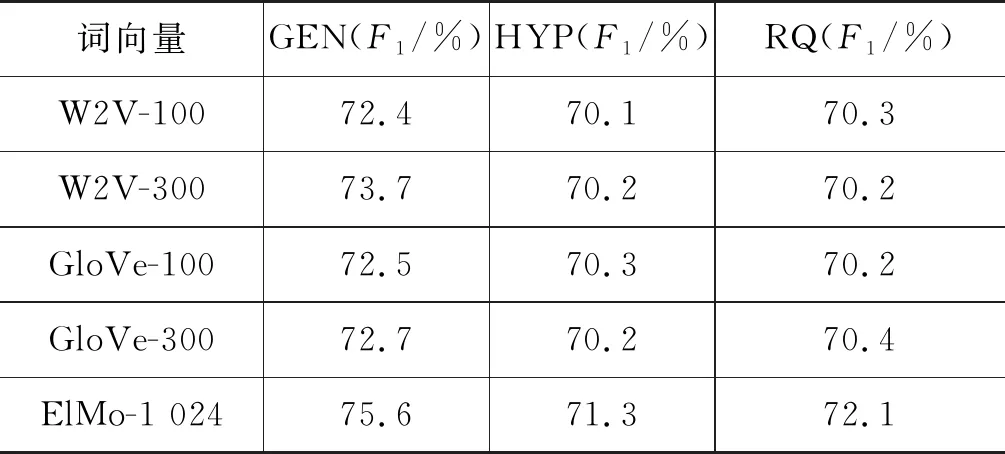
表3 不同词向量对模型性能的影响
表3中列出了使用Word2Vec词嵌入表示[25]和GloVe词嵌入表示[26]的实验结果,数字表示维度。实验结果表明,Word2Vec和GloVe词嵌入表示在三个数据集上的性能区别不大,而ELMo在三个数据集上性能提升明显,均有1%~3%的提升。说明采用ELMo在大规模反讽数据集上训练得到的词嵌入表示,能够更好地表达反讽数据中单词的分布式语义表示,且ELMo能够根据不同的上下文赋予单词不同语义特征,这也使得基于ELMo的反讽语义表示能够包含语境信息,从而提升了反讽识别性能。
3.3.3 不同语义表示的对比
为了验证基于词性信息和风格信息对模型的影响,本文对比了引入以上两类语义特征对神经网络模型的影响。EN表示仅使用ELMo信息,EPN表示使用了ELMo和词性信息,ESN表示使用了ELMo和风格信息。
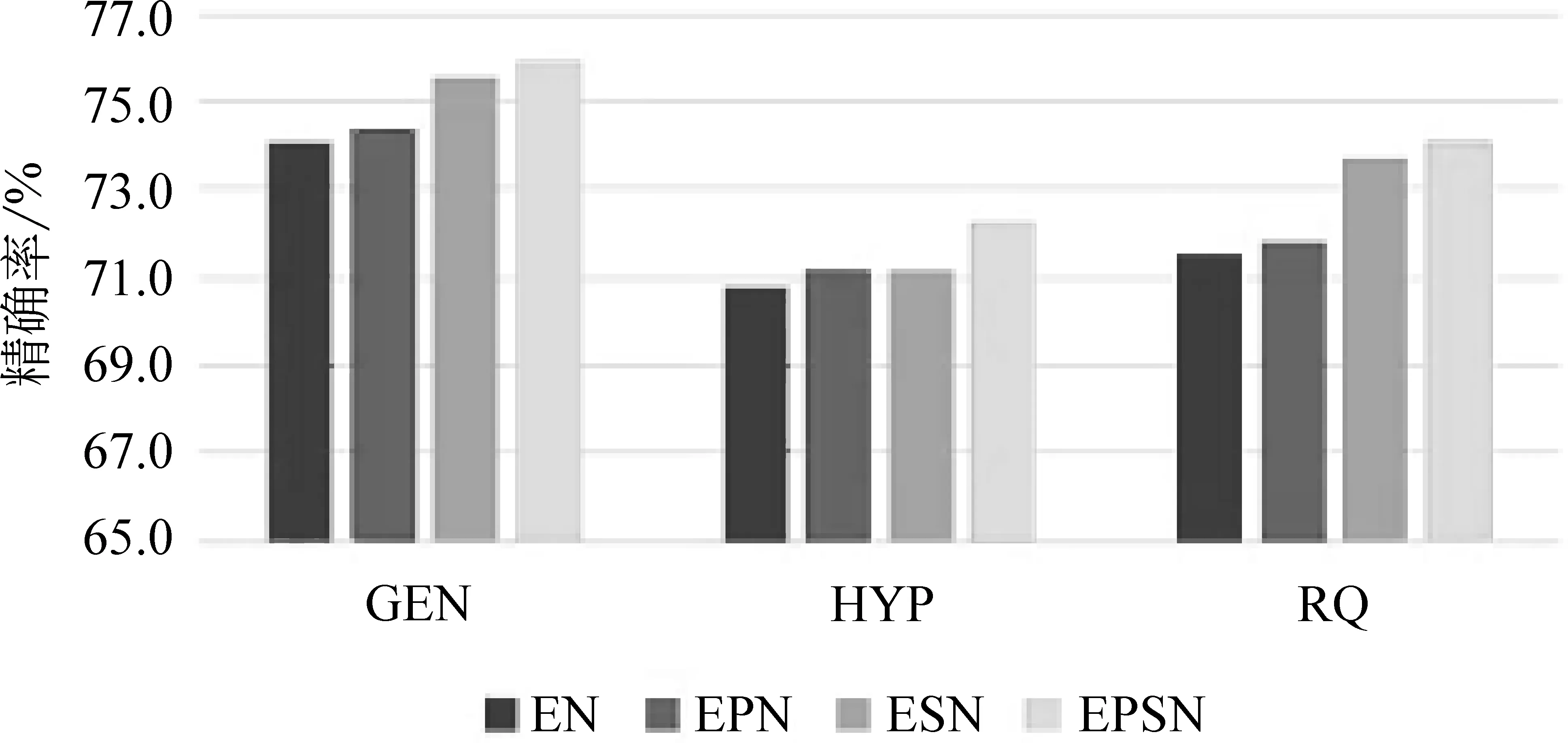
图2 多语义融合对模型精确率的影响
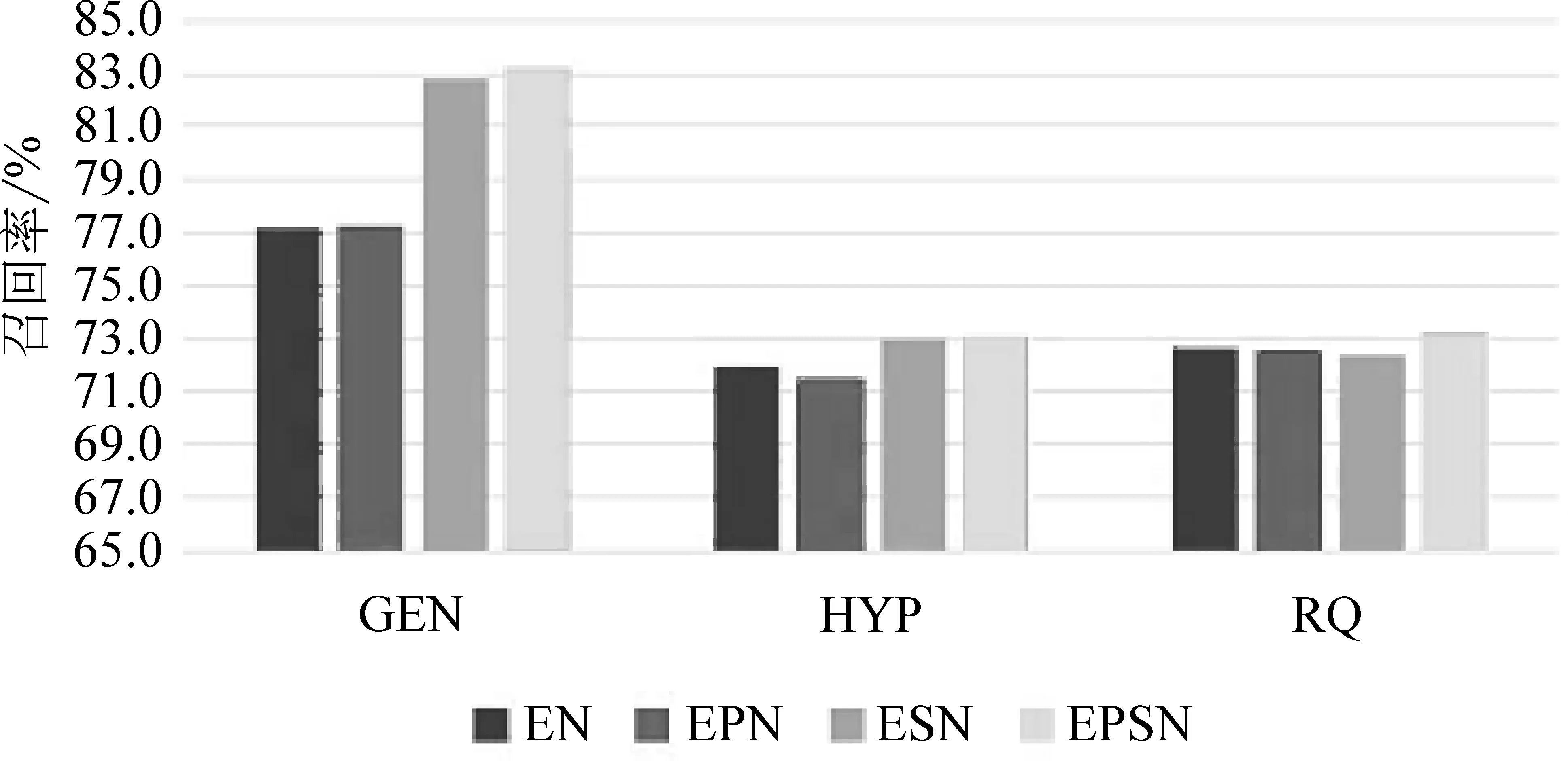
图3 多语义融合对模型召回率的影响
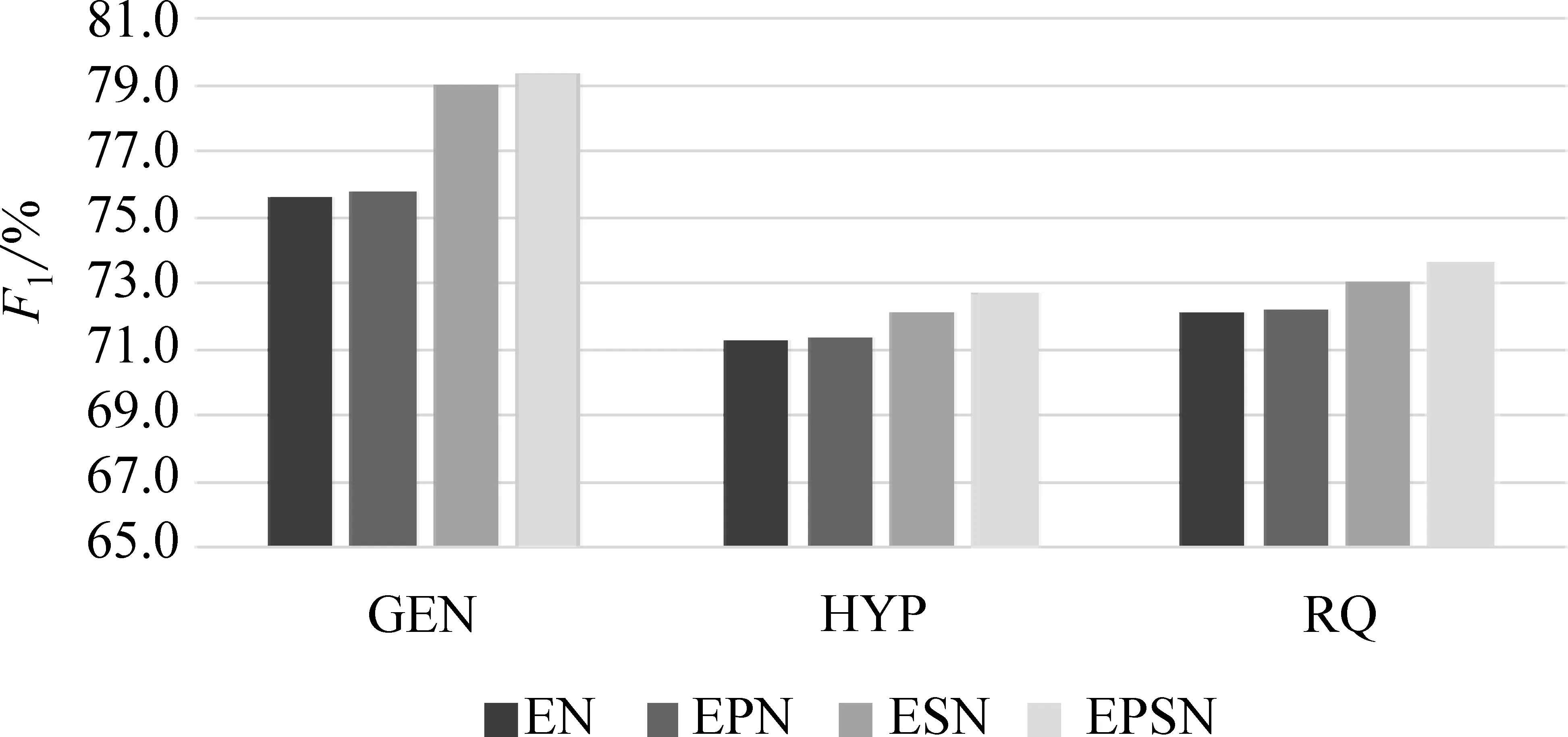
图4 多语义融合对模型F值的影响
多语义融合模型对不同评价标准的影响如图2~图4所示。首先,从图中我们发现,词性信息对三种类型的反讽数据的评价标准影响较小,这主要是由于ELMo得到的语义信息已经包含了部分词性信息,因此引入词性信息后,模型的性能只有很小幅度的提升。其次,如图3所示,引入风格信息后,GEN数据集的召回率有了极大提升,提升幅度接近6%,精确率也有小幅度提高,这表明普通类型的反讽语句包含更多的诸如押韵、重复等修辞手法。此外,基于风格信息的反讽语义特征在HYP和RQ数据集上也能够促使性能提升。风格信息的提取对模型性能的提升起到重要的作用。最后,基于多语义融合的模型在三种类型的反讽语料上都取得了最佳的性能,说明本文提出的模型能够从语境信息、词性信息、风格等多个维度学习反讽语句的潜在语义特征。
4 总结与展望
本文针对反讽语句缺乏语境信息的问题,采用ELMo从大规模反讽语料训练得到反讽领域相关的词嵌入表示,该表示能够根据反讽语句不同的上下文赋予单词不同的语义信息。此外,根据反讽语句的词性信息和风格特点对反讽语句进行信息嵌入式表示,分别使用Bi-LSTM和CNN提取词性特征和风格特征用于反讽识别。在公开反讽数据集IAC_v2的三个子集上的实验结果表明,本文提出的基于多语义融合的神经网络模型能够明显提高反讽识别性能,取得了目前已知的最佳性能。
反讽存在多种类型。对于不同类型的反讽,其语义特点相差较大,很难用统一的模型解决所有类型的反讽识别问题。在接下来的工作中,将进一步探索更多反讽相关的特征,并将它们融入神经网络模型。此外,反讽和幽默、双关等具有许多相似之处,如何进行领域迁移和联合学习也是值得关注的方向。
猜你喜欢
新世纪智能(语文备考)(2020年4期)2020-07-25
开放教育研究(2020年2期)2020-03-31
现代语文(2016年21期)2016-05-25
文学教育(2016年18期)2016-02-28
时代英语·高二(2015年1期)2015-03-16
大连民族大学学报(2015年2期)2015-02-27
河南医学高等专科学校学报(2014年3期)2014-03-11
语文知识(2014年4期)2014-02-28
天津大学学报(社会科学版)(2012年6期)2012-03-25
外语学刊(2011年1期)2011-01-22
