
基于图神经网络和语义知识的自然语言推理任务研究
2021-07-23 06:56:50刘欣瑜刘瑞芳
中文信息学报 2021年6期
刘欣瑜,刘瑞芳,石 航,韩 斌
(北京邮电大学 人工智能学院,北京 100876)
0 引言
自然语言推理(natural language inference,NLI)又称文本蕴涵识别(recognizing textual entailment,RTE),是自然语言处理的一项重要任务,关注的是假设句的语义能否从前提句中推断出来。自然语言推理模型需要理解前提句与假设句之间的语义相似性和相悖性,来判断前提句与假设句之间的语义关系,语义关系如表1所示,有蕴涵、矛盾、中立三种,因此通常可以将自然语言推理视为一个分类任务。

表1 前提句、假设句及其对应的关系实例
人工智能是研究如何应用计算机模拟人类思维过程和智能行为的学科,而推理是人工智能的一个重要研究课题。人类推理包括对事物的分解、比较、综合、分类四个过程: 首先依据日常经验把事物整体分解成各个组成部分;比较各组成部分之间的差异点和共同点;然后在人脑中把各部分联系起来,也就是把事物的个别特性、个别方面重新综合成整体;进而把事物分类。本文用外部语义知识(语义角色和同反义词)来代替人类推理所需要的日常经验,通过模拟上述思维过程来构建推理模型,处理过程如下: 首先模仿人类对事物进行分解的过程,根据语义角色知识把完整的句子拆解成不同的语义角色;再依据同反义词知识简单比较两个句子相同的语义角色是否一致;然后用模型各层提取不同方面的语义特征并融合;最后进行推断分类。
确定模型大致处理流程后,需要进一步设计模型结构,使其实现提取并融合不同方面语义特征的效果。为将人类推理思维的层次性和联想性体现出来,可把句子的各组成部分视为节点,连接相关的节点来构造一个具象的思维导图。具体来讲,以词为节点,利用外部语义知识将句子中的动词与其他词汇联系起来,利用同反义词知识把两句子之间的相关词汇匹配连接起来,构成一对句子的语义拓扑图。图神经网络[1]是一种基于深度学习,通过节点之间的信息传递来获取其中依赖关系的图分析方法,得到的语义图自然适用于图神经网络分析图结构,抽取节点间交互特征;结合常用自然语言处理方法BiLSTM获取节点时序特征。两种特征互为补充,达到提升自然语言推理效果的目的。
1 相关工作
1.1 自然语言推理模型
SNLI[2]和MultiNLI[3]等一系列高质量、大规模标准数据集的发布,推动了自然语言推理的发展, 促进了大量相关研究,深度学习开始引入自然语言推理领域,推理模型由基于统计的方法转为基于神经网络的方法,对文本的语义刻画由浅入深,取得了不错的效果。
目前基于神经网络的推理模型主要有两类:
(1)句子编码模型。先利用预先训练好的词向量来进行编码,将前提句和假设句分别编码成句子向量,然后将两个向量连接起来输入到全连通层,预测语义关系。
(2)句子交互模式。与句子编码模型架构相似,首先将前提句和假设句分别编码成句子向量,再使用句子向量来计算两个句子之间的相似度矩阵,然后利用相似度矩阵进行句子向量的增强表示,最后做出分类判断。
与句子编码模型相比,句子交互模型能够利用句对之间的语义相似度,并且能够捕获前提文本与假设文本之间的潜在语义信息,效果通常优于句子编码模型,本文重点研究句子交互模型。目前优秀的句子交互模型中大多数是BiLSTM和注意机制的不同组合。其中,Rocktschel等[4]首次将注意力机制应用于自然语言推理任务。ESIM[5]是一种基于BiLSTM和注意力机制的改进的序列推理模型,优于以往所有的句子交互模型。KIM[6]以ESIM为基线,提出基于知识的推理模型,利用WordNet[7]的大量外部知识来帮助模型在前提句和假设句之间进行co-attention对齐。袁毓林等[8]指出人类生活在常识和意义世界中,人工智能必须要做到理解自然语言的意义并进行常识推理,而利用语言知识资源可以帮助机器进行语义理解和推理。谭咏梅等[9]提出使用CNN与BiLSTM分别对句子进行编码,自动提取相关特征,然后使用全连接层得到初步分类,最后使用语义规则对分类进行修正,得到最终的中文文本蕴含识别结果。
1.2 图神经网络
近年来,图神经网络逐渐应用于自然语言处理领域。
常见的自然语言处理神经网络,如卷积神经网络和循环神经网络,只能按照特定的句子词汇顺序对词汇的特征进行叠加,而图中的节点是天然无序的,不能很好地处理这种输入数据。图神经网络忽略节点的输入顺序,通常通过节点邻域状态的加权和来更新节点的隐状态,节点的输入顺序改变不会影响模型的输出。
图卷积网络(graph convolutional network,GCN)是图神经网络的一种特殊模式,是最有效的图模型之一,通过邻居节点的信息对当前节点或边进行编码。SRLGCN[10]将图卷积神经网络扩展到带标签的有向图上,表明长短时记忆网络和图卷积神经网络的能力可以互补。WordGCN[11]通过使用图卷积神经网络将句法和语义信息整合到词向量中。图卷积神经网络还可用于提取文本关系[12],在图卷积神经网络的基础上建立了一个双仿射模型,根据节点间句法依赖性、共指性等信息对节点间的关系进行等级划分。
注意力机制已经成功地应用于许多自然语言处理的任务中,如机器翻译、机器阅读等。Graph attention networks[13]一文提出了一种图注意力网络(graph attention network,GAT),将注意力机制纳入传播步骤,通过关注每个节点的邻居节点,遵循self-attention策略来计算每个节点的隐状态。通过对自我注意层的叠加,邻居节点的特征被整合到其邻居的特征中。图注意力网络通过为邻域中的不同节点指定不同的权重进行运算,避免了求逆等复杂的矩阵运算,弥补了图卷积神经网络等方法的一些缺陷。
在本文中,我们根据自然语言推理任务的特点,引入语义角色和同反义词两种外部知识,利用BiLSTM分别结合上述GCN、GAT两种图神经网络进行推理。
2 模型
在给定前提句和假设句的前提下,利用语义角色和同反义词知识,连接相关词汇,采用图卷积或图注意力算法提取语义图空间特征,融合BiLSTM提取的上下文特征,来预测句子之间的关系类别是蕴含、矛盾、中立三者中的哪一个。
如图1所示,推理模型由图构造层、编码层、图卷积层或图注意力层、增强&融合层、分类器几部分组成。下文将详细介绍模型处理过程。

图1 基于图神经网络推理模型结构
2.1 语义图构造层
首先,在句子对输入模型之前,将两个句子之间的语义角色和同反义词等多种语义信息用图结构的方式表示出来。
语义角色标注(semantic role labeling,SRL)是一种浅层语义分析方法。语义角色,顾名思义是指句子各部分在句中某个动词触发的事件里担任的角色,通俗来讲,角色有施事者、受事者、与事者以及时间地点等一些外围语义角色,对应“做什么”“是什么”“如何做”等内容,这正好是判断两句关系的依据,可以加以利用。
如图2所示,一个句子通常包含多组“动词—论元”结构,如以动词“lean”为核心有“three women”-“lean”,“lean”-“against a metal fence”等语义关系组合,以动词“stare”为核心有“three women”-“staring”,“staring”-“to the left”等关系组合。根据句子内部的这些语义角色关系组合可以在动词与论元之间建立一条边,根据不同的角色关系,边就被赋予了不同的语义属性,如“three women”与“lean”之间的边具有“ARG0: 施事”属性,“staring”与“to the left”之间的边具有“DIR: 地点”属性。
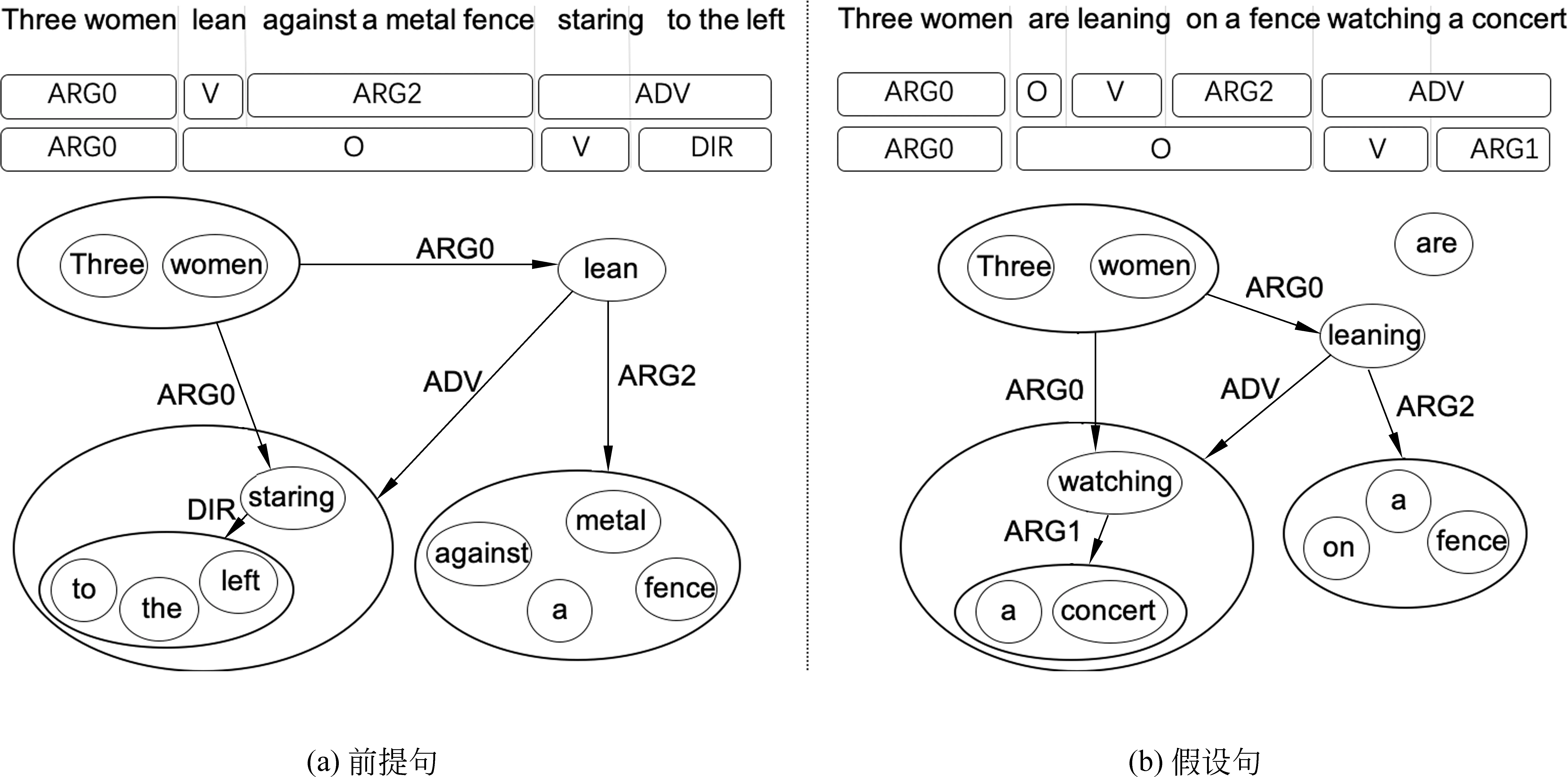
图2 语义角色标注以及句内单词连接方法示例
依据语义角色在句子内部构建好具有语义属性的边后,接下来如图3所示,根据同义词反义词知识,在两句中的同反义词之间建立具有同义或反义属性的边,把两个句子各自的语义图联系起来,得到一个包含几十个节点和多种属性边的语义图。
接下来继续详述模型处理过程。

图3 前提句和假设句的语义图
2.2 编码层
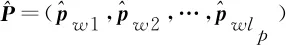
2.3 图卷积层
本文借鉴了图卷积神经网络的思路,并且在图卷积算法的基础上增加了一个可学习系数,使节点对沿着不同属性的边传递过来的消息具有不同的信赖程度,构成图卷积层。
为便于陈述,对各种语义属性进行编号,表2列举了一些常见边的语义属性及其设定的编号。

表2 语义属性及其对应的编号

(1)

(2)

(3)
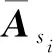
2.4 图注意力层
除了图卷积方法,本文另外尝试了图注意力算法。不同的邻居节点以及具有不同语义属性的边对当前节点的重要性是不同的,因此设计了节点—节点级和属性—节点级两种注意力机制来识别这些差异(图4)。

图4 节点—节点级、属性—节点级注意力示意图
2.4.1 节点—节点级注意力机制
与图卷积层的输入一样,依旧假设ζ=(υ,ε,χ)表示建立好的语义图。为了使不同节点对应的注意力系数更具合理性,以节点v为例,先只计算通过相同属性边指向v的邻居节点的系数。遵循图注意力神经网络[13],每个节点的输入向量xu先用共享权重矩阵W∈R2d×2d做线性变换进行初始化,然后利用可学习的参数向量aT∈R2d作节点与节点之间的self-attention运算,并在单层前馈神经网络中应用LeakyReLU(·)激活函数,得到esi,uv系数,代表在经过属性为si的边指向节点v的所有节点中,节点u所占的权重,经过softmax归一化得到αsi,uv,如式(4)、式(5)所示。
esi,uv=LeakyReLU(aT[Wxv‖Wxu])
(4)
αsi,uv=softmaxsi,v(esi,uv)
(5)
其中,式(4)中的“‖”表示拼接操作,指将两个句子初始化后的词向量合并成一个矩阵。υsi,v是经由属性si的边指向节点v的邻居节点集合。
(6)
如式(6)所示,υSi,v中节点的特征向量经过参数矩阵W进行线性变换,用对应的αsi,uv进行加权求和,得到gsi,v这一聚合了υsi,v中所有节点特征的向量,代表语义属性si对节点v的作用效果。为了进一步稳定注意力机制的表达能力,选用multi-head attention来获得最终特征。
(7)

2.4.2 属性—节点级注意力机制
在节点级注意力机制的基础上,进一步选用点积注意力方法计算节点v的向量xv与gsi,v的相似性,作为权重esi,v,表示语义属性si对节点v的重要性,并用softmax函数归一化,得到权重分数αsi,v,如式(8)、式(9)所示。
最后,如式(10)所示,利用归一化的注意力系数进行加权求和,得到节点v的最终输出特征gv,这是所有邻居节点通过不同语义属性的边到达节点v的最终特征向量。
(10)
2.5 增强&融合层
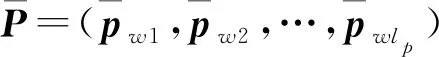
由于图卷积层、图注意力层没有输入单词位置信息,加上图处理方法的特性,图处理层的输入向量中原本包含的上下文特征被削弱,因此保留编码层输出向量,结合图处理层输出向量,以充分利用两个句子的上下文特征和语义图空间特征。因此,进一步的拼接&增强操作如式(11)、式(12)所示。
接下来进行最后的融合操作,使用BiLSTM算法来融合上述向量矩阵EP和EH各组成部分的信息,区分推理的关键特征。然后为了减轻句子长度对最终关系类别预测的干扰,将BiLSTM的输出矩阵通过平均池化和最大池化操作转化为固定长度的向量。
最后,将池化操作得到的向量输入到分类器中进行最终预测,该分类器由一个线性层、tanh激活层和softmax输出层组成。
3 实验
3.1 数据集
本文选用以下两个自然语言推理数据集来评估模型。
(1) 斯坦福自然语言推理(Stanford natural language inference,SNLI)语料库是一个包含57万对人工书写的英语句子的集合,并且给这些句子对人工标注了蕴含、矛盾和中立等标签,支持自然语言推理任务。该语料库既可以作为评价语言表征系统的基准,也可以作为开发各种类型的自然语言处理模型的数据资源。
(2) 多体裁自然语言推理(multi-genre natural language inference,MultiNLI)语料库是一个由43.3万个句子对组成的涵盖了口语和书面语多种体裁的众包数据集。
本文工作中使用了SNLI和MultiNLI两个数据集[14]评估模型。这两个数据集在WordGCN论文中被标记为PropBank[15]语料库的语义角色风格,并且另外提供了同义词反义词数据,可以加以利用,建立具有不同属性的边。本文使用与ESIM[5]工作中相同的训练集、验证集、测试集分割方式来处理SNLI和MultiNLI数据集,使用分类准确率作为评价指标。
3.2 模型训练
实验在NVIDIA Tesla T4的GPU上运行,对于基线模型ESIM,平均每一步耗时0.1s;对于结合了图卷积神经网络的模型和结合了图注意力神经网络的模型,平均每一步耗时分别为0.2s和0.15s。
本文使用预训练好的300维GloVe 840B向量来初始化词向量。OOV单词使用高斯初始化。模型使用Adam优化器进行优化,初始学习率设为0.000 4,批处理大小为32。所有前馈传播层的dropout都设置为0.5。图注意力层中LeakyReLU(·)激活函数的负值部分斜率设为0.2。
在图处理层这部分,图卷积层使用单层卷积层,图注意力层中的multi-head attention的head数量设为3,而不是常用的8。因为本任务语义图节点数很少,从一阶邻居节点聚集的信息与上下文特征结合,足以推断句子之间的关系,增加图卷积层的层数或图注意力层中的head数量,不仅不能取得更好的效果,反而需要更多的训练时间才能收敛。
3.3 实验结果
本节详细介绍使用SNLI、MultiNLI数据集评估模型的实验结果。
大多数句子交互模型都是基于注意力机制和循环神经网络或其变体的,表3和表4列举了其中几个经典的句子交互推理模型分别在SNLI和MultiNLI数据集的实验效果。
(1) LSTM Attention模型[4]是基于LSTM和注意力机制的端到端神经网络模型,使用逐字的注意力机制来推断单词或者短语之间的关系。
(2) mLSTM模型[16]对前提句和假设句也进行逐字匹配,更加重视重要的词级匹配结果。
(3) LSTMN[17]设计类似于列表结构的记忆单元和描述词与词之间相关程度的intra-attention来改进LSTM。
(4) Gated-Att BiLSTM[18]是基于stacked-BiLSTM的,并配备引入门控单元的句内注意力机制。
(5) 参考DenseNet[19],Kim等[20]提出Densely-connected Co-attentive RNN模型,该模型的突出特点是从最底层到最顶层一直保留原始信息以及利用co-attention得到的交互信息。
(6) ESIM[5]是一个增强型序列推理模型,是一个经典的自然语言推理任务基线模型。
(7) KIM[6]以ESIM为基准,从WordNet[7]引入五种外部知识,嵌入相似度矩阵中计算co-attention,收集局部推理信息,并进行推理以做出最终决策。

表3 在SNLI数据集上的准确率

表4 在MultiNLI数据集上的准确率
本文借鉴KIM,选择ESIM模型作为基线,结合外部知识帮助推理。KIM引入五种语言知识,本文只引入语义角色和同反义词两类外部语义知识,却获得更高的准确率,可见引用外部知识不在多而在精。语义角色能够表征句子中重要的语义关系,同反义词起的是连接前提句和假设句的桥梁作用,这两种知识的结合提供了比KIM所用的五种知识更精准的推理依据。根据这两种语义知识构造语义图,然后采用图神经网络算法代替ESIM中的注意力机制来交互两个句子的特征信息。
如表3所示,基于图卷积算法和图注意力机制的推理模型在SNLI测试集上的准确率分别达到89.1%和89.8%,比ESIM模型的准确率提高1.1%和1.8%。实验表明,图注意力层比图卷积层更适合于小型语义图,图注意力算法更适合自然语言推理任务,使节点更细腻的特征信息跨越句子进行交互。基于图注意力机制的推理模型也在MultiNLI的两组数据集MultiNLI-matched和MultiNLI-mismatched上获得了最高准确率,分别是77.4%和76.7%,比ESIM高0.6%和0.9%。
接下来,通过一系列消融实验,进一步分析模型各模块对于模型推理的作用。首先在基于图注意力机制的推理模型上,去除属性—节点级注意力机制,保留节点—节点级注意力机制,不区分边的属性,直接把所有邻居节点执行multi-head attention运算进行加权求和。如表5所示,去除属性—节点级注意力机制后的模型在SNLI数据集上的准确率下降到88.9%。接下来,在引入外部知识的作用验证方面,分别只引用语义角色知识、同反义词知识中的一种或零种进行实验,还可以区分其中哪种语义知识更有助于判断句子之间的关系。

表5 模型消融实验
从表5可见,只引入语义角色知识比只引入同反义词知识更能帮助推理模型捕捉句子结构信息。如果直接去除图卷积层或图注意力层,模型在SNLI测试集上的准确率下降到85.9%。综合消融实验的结果,可以看出,外部语义知识和图神经网络算法的引入对提高自然语言推理模型性能具有重要意义。
4 总结
本文提出了基于图神经网络和外部知识的自然语言推理模型。在基线模型提取的特征基础上补充了语义图空间特征,进一步提高模型推理能力,使其在SNLI和MultiNLI数据集上的性能优于以往的模型。由于基线模型ESIM应用了BiLSTM,也在一定程度上表明循环神经网络或其变种与图神经网络结合有互补的效果。
本文提出的模型有几个潜在的改进点可以作为未来的工作方向。目前最好的推理模型利用了BERT这一优秀的预训练模型生成初始词向量,取得比静态词向量更好的效果,所以可以尝试将模型静态词向量初始化方法替换为先进的预训练模型初始化方法。另外,引入的外部语义知识的种类不宜过多,过多可能会增加提取推理信息的难度,因此可以进一步研究除了语义角色和同反义词知识外,是否有更适用于自然语言推理任务的语言知识。除此之外,把其他图神经网络算法应用到自然语言推理模型中,也是一个值得期待的研究课题。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
电视技术(2014年19期)2014-03-11 15:38:20
