
译文质量估计中基于Transformer的联合神经网络模型
2021-07-23 06:39:06李茂西
中文信息学报 2021年6期
陈 聪,李茂西,罗 琪
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
0 引言
机器译文质量估计(quality estimation, QE)是在不借助人工参考译文的情况下,自动实时地预测机器译文质量的优劣,它在机器译文的直接使用和后编辑中发挥着重要作用[1]。
在缺乏人工参考译文对照的情况下,如何准确地预测机器译文质量呢?译文质量估计方法是模仿人类外语专家的行为,通过外部资源学习各种语言知识和语言之间的关联,来对未知的机器译文质量进行预测。按照学习方法的不同,它们大致分为基于浅层语言学特征的方法[1]、基于预训练词向量[2-3]特征的方法[4-5]和神经机器译文质量估计方法[6-9]。基于浅层语言学特征的方法通过对机器译文和源语言句子进行语言学分析和词频的统计分析,提取描述译文质量的流利度特征、忠实度特征和复杂度特征[1];基于预训练词向量特征的方法,利用预训练的词语分布式表示和深度语言模型[10],分别提取源语言句子稠密表征和机器译文稠密表征,在回归模型中预测机器译文质量[4-5]。而神经机器译文质量估计方法则利用迁移学习的方法,通过在已使用双语平行语料预训练的神经机器翻译模型中提取描述翻译质量的特征[6-7],使用长短期记忆网络[8](long short-term memory network,LSTM)或卷积神经网络(convolutional neural network,CNN)预测译文质量得分。
近年来,随着深度神经网络成功地应用于序列转换建模任务中,学者们提出了基于循环神经网络(recurrent neural network,RNN)带注意力机制的编码器—解码器模型[11]和基于Transformer的编码器—解码器模型[12]用于神经机器翻译。将这两种模型应用于译文质量估计任务中,神经机器译文质量估计方法又随之进一步细分为基于RNN编码器—解码器的译文质量估计方法[6,13]和基于Transformer的译文质量估计方法[7,14-17]。针对当前基于Transformer的译文质量估计方法特征提取过程繁琐的不足,本文提出了一种简单有效的组合Transformer瓶颈层和双向LSTM层(Bidirectional LSTM, Bi-LSTM)的神经网络用于译文质量估计,该网络的两个子网络参数使用译文质量估计语料联合训练。与基线系统相比,本文所提模型不仅结构简单,而且其预测结果与人工评价相关性更高。
1 相关工作
在基于RNN编码器—解码器模型的神经译文质量估计方面,Kim等人提出了预测器-估计器方法(predictor-estimator)用于译文质量估计[6],预测器从已训练的基于RNN的编码器—解码器模型中提取描述译文中每个词生成质量的特征,估计器将词级特征转换为句子级别特征,并使用单层全连接神经网络预测译文质量;针对分别训练预测器和估计器的不足,Li等人提出将预测器-估计器组合成一个端到端的深度神经网络,并使用译文质量估计语料训练整个模型的参数[13]。
在序列转换任务中,Transformer网络模型[12]大幅度地提升了神经机器翻译的并行性和译文的质量,因此研究人员尝试将Transformer模型应用于译文质量估计中,以准确提取描述词语翻译质量的特征。Fan等人使用双向Transformer模型同步生成源语言和目标语言的潜在语义表示,以计算给定源语言知识的情况下机器译文的条件生成概率,双向Transformer模型使用双语平行语料预训练,并被称为“双语专家”,用以预测译文质量并发现译文中存在的翻译错误[7]。Hou等人提出了BiQE模型,该模型使用了两个翻译方向的Transformer翻译信息,用源语言-目标语言平行语料训练给定源语言句子的情况下描述译文质量的特征,用目标语言-源语言平行语料训练给定机器译文情况下源语言句子被描述的特征,将两个方向的特征拼接计算表征译文质量的特征[15]。Wang等人提出使用改进的Transformer模型Transformer-DLCL[16]提取描述译文质量的特征[17],Transformer-DLCL模型加深了Transformer模型的层数,能够提取更深层描述译文质量的特征。
与以上基于Transformer的译文质量估计方法不同的是,我们直接将Transformer模型的瓶颈层和Bi-LSTM网络层组成一个完整的神经网络,用于端到端的译文质量估计,该模型被称为基于Transformer的联合神经网络模型(Transformer-based unified neural network for quality estimation,TUNQE)。与双语专家模型使用两个解码器来分别关注机器译文的上文和下文信息不同,TUNQE模型仅通过修改Transformer解码器的遮挡方式来同时关注上下文信息,联合上下文信息提取高质量的译文质量估计向量。
2 基于Transformer的联合神经网络模型
在深度神经网络中,原始的样本通过多层网络逐步抽象为一个高维向量,然后将该高维向量通过全连接神经网络层映射到分类的类别空间(或回归为单点值)以进行模型构建,瓶颈层(bottleneck layer)通常定义为包含将原始样本抽象为高维向量的所有网络层[18]。在使用深度神经网络进行迁移学习时,为了将在一个任务上训练好的模型通过简单的调整或不做调整,使其适应一个新的任务,瓶颈层和瓶颈层的输出向量起着重要的作用。为了利用Transformer模型从双语平行语料中学习到的双语关联知识,我们将Transformer瓶颈层和Bi-LSTM网络层组成一个联合神经网络用于译文质量估计,如图1所示。待评估的机器译文及其源语言句子通过已训练好的联合神经网络直到瓶颈层顶端的过程,可以看作对机器译文中词语进行特征提取的过程,Bi-LSTM网络层将词语级别的特征转换为句子级别的特征,并将结果输入至全连接神经网络以预测译文质量。

图1 TUNQE模型架构
2.1 模型架构
基于Transformer的联合神经网络模型主要由特征提取模块和质量估计模块两部分组成。特征提取模块是Transformer翻译模型的瓶颈层(图1的下半部),用于提取待评估的机器译文中词的质量向量,即Transformer瓶颈层输出的词嵌入向量DN。质量估计模块使用Bi-LSTM与单层全连接神经网络组成(图1的左上半部),将提取的质量向量输入到质量估计模块,得到机器译文的质量得分。模型的数学描述如下:
为了获取译文中词语的质量向量DN,首先需要对输入的源语言句子进行编码得到编码器输出EN,如式(1)~式(3)所示。
(1)
+MultiHead(Et -1,Et -1,Et -1))
(2)
(3)

源语言句子经过编码器得到其表示EN,将EN与待估计的机器译文输入解码器,提取机器译文的质量向量,如式(4)~式(7)所示。
(4)
+Masked-MultiHead(Dt -1,Dt -1,Dt -1))
(5)
(6)
(7)


图2 两种不同的遮挡方式
将质量向量DN输入到质量估计模块,计算其质量得分QEscore,如式(8)~式(10)所示。

Transformer机器翻译模型包括自回归(autoregressive or free running)和强制学习(teacher forcing)两种训练方式。自回归方式是指解码器使用预测生成的前j-1个词生成第j个词;强制学习方式是指使用基准真相(ground truth)句子的前j-1个词预测生成第j个词。强制学习能在训练时矫正模型的预测,避免在序列生成过程中错误进一步累积。为了减小训练和测试的差异,通常会设置强制学习率来平衡自回归与强制学习。在译文质量估计中,不论机器译文中词语翻译是否正确,我们均要提取其质量向量,因此译文输入时强制学习率设置为1。
基于Transformer的神经机器翻译模型训练时通常设置元素为1的下三角矩阵(图2(a))对目标端句子进行遮挡和并行化,以模拟在解码当前词时只能用到已生成词的信息,而不能利用未生成词的信息,即下文的信息。然而,在译文质量估计任务中,不能仅通过前j-1个词来预测译文中第j个词的质量,第j个词的质量应该由整个译文句子共同决定,包括预测词的上文和下文信息。表1给出了同一个源语言句子“he is wearing a hat”的两个机器译文S1“他戴了一顶帽子”和S2“他穿了一顶帽子”来说明,为什么同时需要利用当前词的上下文信息来计算其质量向量。假设采用图2(a)的遮挡方式,译文S1和译文S2中的第三个词的质量向量都由“”“他”两个词以及源语言句子决定,这意味着特征提取模块提取的“戴”的质量向量等于“穿”的质量向量,这显然是错误的。为了充分利用上下文信息进行译文质量估计,我们使用了不遮挡的方式输入机器译文,即设置元素全为1的遮挡矩阵,如图2(b)所示,1表示特征提取时允许解码器对该位置的词进行关注。

表1 为什么需要利用上下文信息提取当前词的质量向量实例
需要说明的是,特征提取模块的解码端由6个解码器子层堆叠而成,每一个解码器子层都需要使用遮挡机制。在特征提取阶段,我们需要修改原始的遮挡方式。如果我们将所有解码器子层的遮挡方式都变更成图2(b)的遮挡方式,那么将导致特征提取模块过度关注整个机器译文,大幅度降低了对源端编码信息的关注程度,这意味着特征提取模块无法有效利用双语平行语料中学习得到的双语关联知识去提取机器译文的质量向量。为了避免这种情况,我们只修改了解码端最后两层解码器子层的遮挡方式。在消融实验中,我们比较了解码器使用不同遮挡方式时模型的性能。
2.2 模型训练
由于译文质量估计训练集的规模比较小,仅包括大约1万个训练样本(如表2所示),基于Transformer的联合神经网络模型参数不能使用它们进行有效的训练,因此,我们采用了目前主流的在上游任务上预训练、在下游任务上微调的方式进行模型优化。首先使用机器翻译的双语平行语料预训练原始未修改解码器遮挡方式的Transformer模型,使用预训练后的参数初始化基于Transformer联合神经网络的Transformer瓶颈层参数,然后使用译文质量估计训练集联合训练整个模型。联合训练过程中将特征提取模块解码器最后两层的遮挡方式进行修改,联合训练的损失函数为均方误差损失,如式(11)所示。
(11)
其中,B表示训练批次大小(batch size), 为第i个机器译文的质量估计预测分值,HTERi为第i个机器译文的人工打分结果。
基于Transformer的联合神经网络模型用PyTorch深度学习框架实现,由于Transformer瓶颈层输出的质量向量DN是张量(tensor)类型,在模型训练中进行参数反向传播优化时,当把其“requires_grad”参数设置为True时,梯度能够经由质量向量DN更新Transformer瓶颈层的参数,以实现联合训练。与之对应的是,可以通过detach函数将质量向量DN的“requires_grad”参数设置为False,把Transformer瓶颈层从计算图中分离。这时,模型训练时,参数反向传播过程中不会计算质量向量DN的梯度,因此无法更新Transformer瓶颈层参数,从而实现两个模块的单独训练。在消融实验中,我们比较了联合训练和单独训练时模型的性能。
3 实验与分析
3.1 实验设置
为了测试基于Transformer的联合神经网络的性能,我们在CWMT18句子级别译文质量估计数据集上进行了实验验证。CWMT18句子级别译文质量估计任务评价中英和英中翻译方向的机器输出译文质量,其训练集每一个样本由源语言句子、机器译文、人工后编辑译文、机器译文翻译错误率组成。为了预训练Transformer瓶颈层的参数,CWMT18评测官方发布的用于新闻翻译任务的casia2015、casict2015、datum2017和neu2017双语平行语料被用作预训练Transformer模型。为了减少双语平行语料中噪声对预训练的Transformer模型的影响,英文端句子使用了大小写转换、标记化(tokenizer)和BPE子词切分(最大操作数设为3.2万次)等预处理,中文端句子进行了中文分词。表2给出了预处理后使用的双语平行语料规模和两个方向上的译文质量估计语料的训练集、验证集和测试集语料规模。
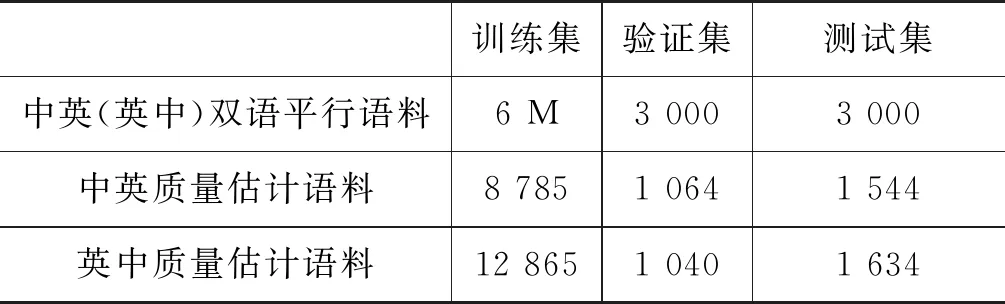
表2 语料规模统计
基于Transformer的联合神经网络在Facebook开源的Fairseq系统[19]上改进实现。Transformer模型参数设置与文献[12]中Transformer-base模型一致,Transformer瓶颈层预训练使用Adam优化器,优化器参数设置为β1=0.9,β2=0.98,ε=10-9;训练时学习率设置为lr=0.000 7,最小学习率设为min_lr=10-9;损失函数采用交叉熵损失函数。联合神经网络中Bi-LSTM网络层的隐藏层大小设置为1 024,层数为1。使用译文质量估计语料统一训练联合神经网络时采用SGD优化器,固定学习率lr=0.05。
为了评价不同方法进行译文质量估计的性能,皮尔逊相关系数(Pearson)被用来测定译文质量自动估计结果与人工评价的相关性,斯皮尔曼相关系数(Spearman)被用来测定机器译文质量自动估计结果排名与人工评价排名的相关性。皮尔逊相关系数或斯皮尔曼相关系数越大,表示模型性能越好。
3.2 实验结果
实验中我们将本文方法(TUNQE)与CWMT18句子级别译文质量估计评测任务参与的最好系统(CWMT18 1st ranked)、基于RNN编码器—解码器的译文质量估计联合模型(UNQE)[13]、融合BERT语境词向量的译文质量估计系统(CUNQEAVE4)[20]和基于双语专家的译文质量估计系统(QE Brain)[7]等进行了对比,其中QE Brain系统包括使用两种规模训练语料,分别为中等规模语料(8 M)和大规模语料(25 M+25 M)训练模型时系统的性能。对比的译文质量估计系统按照皮尔逊相关系数值由小到大进行排序。
实验结果如表3所示,我们发现基于Transformer的联合神经网络模型TUNQE在英中和中英翻译结果评估任务上皮尔逊相关系数均超过了使用同等规模语料训练的基准对比系统CWMT18 1st ranked、UNQE、QE Brain(8 M)与CUNQEAVG4,和使用大规模语料训练的QE Brain(25 M+25 M)性能相当(0.621 Vs 0.620; 0.609 Vs 0.612)。与UNQE相比,TUNQE比UNQE在英中和中英方向上皮尔逊相关系数分别提升了18.5%和15.3%;与QE Brain(8 M)相比,TUNQE比QE Brain(8 M)在英中和中英方向上皮尔逊相关系数分别提升了5.6%和8.0%。这表明,本文提出的基于Transformer的联合神经网络模型能显著地提高译文质量估计的效果。

表3 不同译文质量估计方法在CWMT18句子级别译文质量估计数据集上的性能
在利用语境词向量BERT[3]增强译文质量估计方面,李培芸等验证了融合语境词向量的方法能利用译文的流利度特征来提高译文质量估计的效果[20]。受他们工作的启发,我们采用同样措施将译文的BERT预训练词向量最后4层表示平均池化后与TUNQE方法提取的向量融合,以进行译文质量估计,记为TUNQE。实验结果表明: 融合BERT语境词向量的方法TUNQEBERT进一步提高了TUNQE模型译文质量估计的性能,TUNQEBERT比CUNQEAVG4在英中和中英方向上皮尔逊相关系数分别提升了5.2%和3.7%,这说明基于Transformer的联合神经网络模型性能还有一定的提升空间。
我们还将TUNQE模型与最新开源的基于跨语言预训练XLM-R的 TransQuest模型(1) https://github.com/TharinduDR/TransQuest进行了对比。TransQuest模型是WMT20 译文质量估计任务的参赛系统之一,在多个语言对质量估计任务上取得了优异的成绩。实验结果表明TUNQE模型在CWMT18英中和中英译文质量评估任务上的皮尔逊相关系数均超过了TransQuest模型。
3.3 消融实验
为了进一步揭示使用译文质量估计语料统一训练联合神经网络的优势,我们将联合训练模型的性能与分别使用双语平行语料和译文质量估计训练语料单独训练Transformer瓶颈层和Bi-LSTM层的方法,记为TUNQESEP,进行了对比。模型两部分分别训练的方法TUNQESEP相当于没有使用译文质量估计语料对基于Transformer的联合神经模型中Transformer瓶颈层进行微调。表4的实验结果表明: 联合训练的方法TUNQE优于两部分分别训练的方法TUNQESEP,相比于TUNQESEP,TUNQE在英中和中英方向上皮尔逊相关系数分别提升了22.2%和14.7%。
使用译文质量估计语料统一训练联合神经网络需要考虑的一个因素是,由于Transformer瓶颈层已经使用双语平行语料进行了预训练,继续使用译文质量估计语料对其进行微调,过多的训练次数将会导致Transformer瓶颈层模型对译文质量估计任务出现过拟合。为了确定合适的训练次数,我们在CWMT18句子级别译文质量估计中英验证集上进行了多次测试,不同训练次数情况下,模型在验证集上的性能如图3所示。从图3可以看出,使用译文质量估计语料统一训练2~4次基于Transformer的联合神经网络可以使模型性能达到最优,因此实验中我们将训练次数统一设置为3。

表4 联合训练模型与分步训练模型性能对比

图3 模型训练次数对译文质量估计的皮尔逊相关系数的影响

表5 模型使用不同解码器遮挡方式对应的性能
为了进一步研究Transformer瓶颈层中解码器的不同遮挡方式对模型性能的影响,我们把使用不同遮挡方式的解码器子层进行堆叠。实验结果如表5所示,TUNQE0表示不修改Transformer瓶颈层解码器遮挡方式的模型,TUNQE-1,TUNQE-2,…,TUNQE-6分别表示修改了Transformer瓶颈层解码器最后1层、最后2层……最后6层解码器子层遮挡方式的模型。实验结果表明,在联合训练过程中,仅修改最后两层解码器子层的遮挡方式优于修改其他子层的遮挡方式。当修改遮挡方式的层数超过三层时,模型的性能大幅度下降,并且其皮尔逊相关系数均低于不修改遮挡方式的模型(TUNQE0)。这是因为解码器过度关注机器译文的信息,从而无法有效利用从双语平行语料中学习得到的双语关联知识去提取机器译文的质量向量。
4 总结
本文提出了基于Transformer的联合神经网络模型,其利用译文质量估计语料统一训练由Transformer瓶颈层和Bi-LSTM组成的译文质量估计网络模型,实验结果表明该方法能显著提高译文质量估计的效果,在以后的工作中,我们将尝试把该方法应用于指导神经机器翻译译文的生成,以提高机器翻译的质量。
猜你喜欢
中国神经再生研究(英文版)(2022年2期)2022-08-08 02:11:20
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
水利经济(2020年3期)2020-02-22 11:38:33
家庭影院技术(2019年8期)2019-12-04 14:43:19
小学生学习指导(低年级)(2017年6期)2017-02-16 21:39:32
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
