
基于轻量化的卷积神经网络技术研究现状
2021-07-23 10:04廖干洲
新一代信息技术 2021年7期
廖干洲
(广州大学松田学院,广东 增城 511370)
0 引言
深度学习网络,尤其是卷积神经网络(简称CNN),自从在LeNet[1]的问世以来,其实在2012年 AlexNet[2]以绝对优势问鼎 ImageNet LSVRC-2012挑战赛以后,卷积神经网络几乎成了深度学习网络的代名词,在图像、语音识别等领域上的应用具有压倒性的优势。以至于随后的VGG[3]、GoogLeNet[4]、ResNet[5]等经典网络,都是在卷积神经网络的基础上,在网络模块结结构、网络深度和训练方法等进行改进,从而得到进一步的发展应用。甚至连今年流行的目标检测(Object Detection)算法中,诸如 RCNN[6],Faster RCNN[7]、SSD[8]、YOLO[9-11]等网络,无一不是从卷积神经网络的基础上发展起来的。
尽管卷积神经网络在识别和目标检测领域上具有令人满意的效果,但是这些效果多是在实验室的高性能计算机中得到的,如YOLO-v1在2016年的计算机配置中,使用了4块Titan X显卡,每一个块显卡的算力达到6.9 TFLOPs,而移动端当前最新的处理器高通骁龙 865处理器的算力为1.5TFLOPS,不及于4年前计算机的1/4,因此最前沿的卷积神经网络的效率问题一直为人所诟病,也正因为这个原因,卷积神经网络在很长的一段时间内,都是停留在实验室当中,真正的应用较少。人们也一直致力于在卷积神经网络移动端的移植应用,但是多是停留在网络剪枝和减少网络层数等方法上,没有根本地解决卷积神经网络结构复杂的问题。直到 2016年提出 Squeeze Net[13]和 2017年 google团队提出 Mobile Net[14]后,轻量化的卷积神经网络算是有了比较明确的发展方向与路径。
近年便携式设备得到了迅速的普及,用户也对其提出了越来越多的需求,尤其在神经网络的应用上。因此,如何设计高效、高性能的轻量化神经网络是解决问题的关键。本文详细阐述了Squeeze Net,Mobile Net和 Shuffle Net[15]等三种轻量化神经网络,同时简要总结和分析了每种方法的特点,最后总结现有的方法,并给出了未来发展的前景。
1 传统CNN的限制
随着CNN性能要求越来越高,传统的网络已经无法满足大家的需求,于是乎大家纷纷提出性能更优越的 CNN网络,在 AlexNet后,有如VGG、GoogLeNet、ResNet一系列网络等。而这些网络的性能得到提升的重要原因是在于网络层数的不断增加。从7层AlexNet到16层VGG,再从16层VGG到GoogLeNet的22层,再到152层 ResNet(更有上千层的 ResNet)。虽然网络性能得到了逐步提高,但随之而来的就是效率问题。
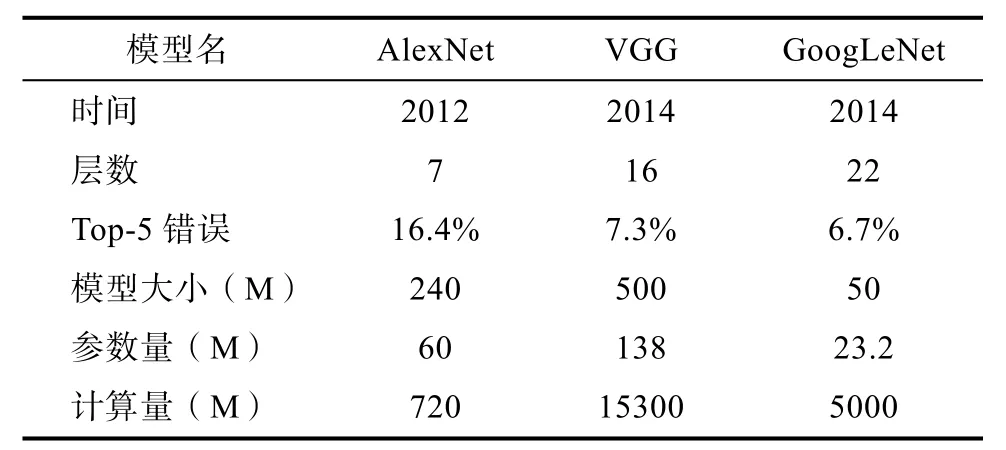
表1 几种传统卷积申请网络概况Tab.1 Overview of several traditional convolution application networks
效率问题主要是模型的存储问题和模型进行预测的速度问题。第一,存储问题。大型网络有着大量的权值参数,保存大量权值参数对设备的内存要求很高;第二,速度问题。在实际应用中,往往是毫秒级别,而在现有的移动设备的处理器来讲,很难满足此要求,因此减少计算量成为了主要的技术手段。
如何解决 CNN网络在存储上和速度上的问题,成了这些网络是否能够应用在实际场景的关键问题,因此,轻量化CNN应运而生。
2 典型轻量化模型的详述
2.1 Squeez e Net
针对不用的应用场景,在CNN的框架下重新设计每一层网络,该方法是的轻量化神经网络成为研究得热点,标志性的事件是 Squeeze Net 的提出,该方法使用了AlexNet五十分之一的计算,达到了几乎一样的效果。该方法把多个称为 Fire Module的CNN模块构建而成。所谓Fire Module是由两个模块组成,分别是 Squeeze模块和Expand模块,所谓Squeeze就是多个1×1的卷积核,借鉴了GoogLeNet的思想,使用1×1的卷积核的使得 squeeze模块变成一个瓶颈层[16],减少网络通道数,以减少计算量,然后再利用Expand模块把通道数增加,如图1所示,原128个通道输入,通过Squeeze层,变为16个输出,再通过Expand层的两个64通道,结合变为128个通道,还原为原来的尺寸大小。
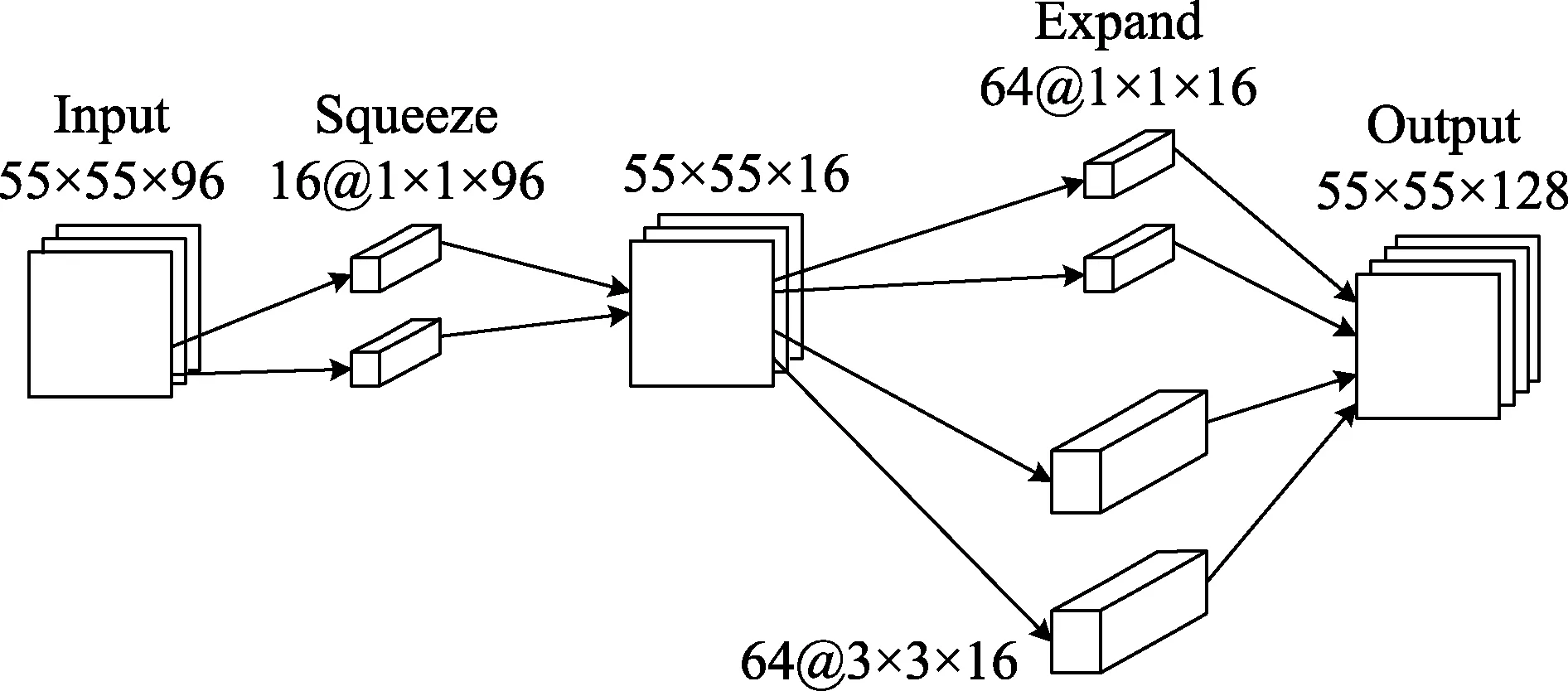
图1 某一层Fire Module的详解计算过程Fig.1 Detailed calculation process of a certain layer of Fire Module
此外,还采用了将池化层采样操作延后的方法,可以给卷积层提供更大的激活图:更大的激活图保留了更多的信息,可以提供更高的分类准确率,当然此方法是为了提高准确率,但是因为池化层的延后,对其计算量会有一定的增加。
2.2 Mobile Net
Mobile Net是google团队在2017年提出的一种新型轻量化CNN模型,Mobile Net的基本单元是深度可分离单元(Depthwise Separable Convolution)[17],分为两个部分,分别是深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)[18],如图 2。
其中深度卷积和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上,而深度卷积针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,通道之间直接没有交叉联系,因此其计算量大大减小。
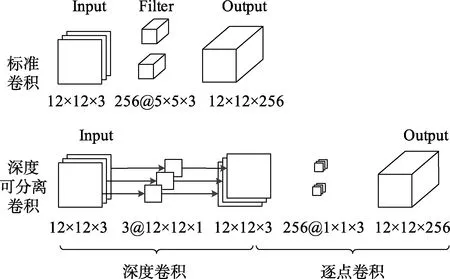
图2 标准卷积与深度可分离卷积Fig.2 Standard convolution and depth separable convolution
此外,为了进一步压缩参数数量,该方法还准备了两个参数,分别为宽度算子(Width Multiplier)α,和分别率算子(Resolution Multiplier)ρ。两个参数均为小于1的小数,分别乘以输入通道M和输出通道N,和输入图像的尺寸。减小输入、输出通道,和输入图像的尺寸,可以进一步压缩数据,也就减小的数据和计算量了。
2.3 Shuffle Net
ShuffleNet是Face++团队在2017年末提出的模型,是把前人关于轻量化模型和压缩模型的方法结合起来,核心是利用原有的ResNet,采用了通道重组(channel shuffle)、组卷积(pointwise group convolution)[19]和深度卷积(depthwise separable convolution)来修改原来的ResNet单元。
2.3.1 通道重组
分组卷积能有效减少计算量,一般卷积操作中比如输入通道的数量是 N,该卷积核的数量是M,那么M个卷积核都要和N个通道进行卷积计算,然后相加作为一个卷积的结果。利用了分组计算,设g组数为g,那么N个输入通道就被分成g个组,M个卷积核就被分成g个组,分组卷积时,第一个组的M/g个卷积核中的每一个都和第一个组的N/g个输入通道做卷积得到结果,第二个组同理,直到最后一个组。这种操作可以大大减少计算量,因为你每个卷积核不再是和输入的全部通道做卷积,而是和一个组的通道做卷积。
但是如果多个组操作叠加在一起,某个输出通道仅仅来自自己输入通道,并不包含其他通道,输出的特征会非常局限,而使用通道重组,可以解决这个问题。通道重组技术在分组时对所有的组进行重组操作(shuffle),这样每个输出的通道,便包含了所有输入通道的数据,得到更为合理的结果。
如图 3所示,为了便于理解,以颜色通道为例,从左到右分别为红色、绿色和蓝色。在未进行重组前,每一组的输出,只跟输入数据的有关系(如图a中红色部分);而在重组以后,每一输出都包含了所有的输入通道元素(如图c中,每一个输出通道都包含输入的三种颜色)。
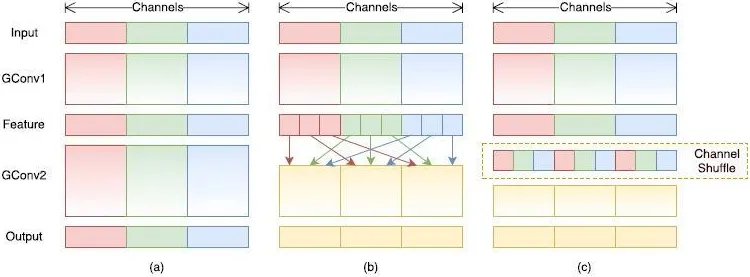
图3 分组卷积思想Fig.3 Gr ouped convolution idea
2.3.2 计算量对比
以普通二维卷积为例,设输入的数据格式为:m×m×h1,卷积核为:k×k,输出的数据格式为:n×n×h2:
参 数量:k×k×h1×h2
计算量:k×k×h1×h2×n×n
而利用分组卷积技术,假设分组大小为g,则:参数量:
(k×k×h1/g×h2/g) ×g=k×k×h1×h2/g计算量:
(k×k×h1/g×h2/g×n×n) /g=k×k×h1×h2×n×n/g
可见,参数量和计算量均为未分组的1/g。
3 轻量化网络的构建原则
从前文可知,轻量化网络基本都是在原有网络的基础上,利用各种方法进行修改,目的是为了减少参数量和计算量,从前面的几种典型轻量化网络中不难发现其构建原则。
3.1 可分离卷积的应用
CNN模型大的一个很重要因素就是参数较多,并且参数时间计算量大,几乎每个参数都有乘法和加法运算。可分离卷积是降低计算量的一个重要手段,利用可分离卷积,可以把卷积层运算分为两层(一般的轻量化卷积都采用两层)甚至更多,层数的增多可以使得参数设置上比较灵活,一般第一步采用较少量卷积与数据进行卷积运算,第二步采用1×1卷积核,把输出结构还原成输入结构。这就是所谓可分离卷积,实际是使用了瓶颈层的思想。
3.2 分组卷积的应用
众所周知,分组卷积可以大大减低计算量,而分组卷积中“分组”,根据应用场景,可以分为方法,具体有多分辨率卷积核分组、多尺度分组、多通道分组等。这几种方法在不同的轻量化卷积中都有应用到,但是在使用的时候必须注意分组的参数,如多分辨率卷积核的大小,多通道分组中分组的数量等,不能一味追求减低计算量,需要在表现和性能上做一个折中。
3.3 简单超参数的应用
轻量化网络的主要任务是对于网络的修改,但是在此以外,有一点也不能忽略,就是一些超参数的设置,在构建网络的时候,适当地设置多一些超参数,如分组的组数,输入、输出、中间数据的尺寸等。这些简单的超参数设置起来比较简单,但是有时候能在某些方面得到意想不到的结果,如减小中间层的尺寸,可能不会影响准确率,但是计算量却是能有效减小。
4 总结
根据原有CNN的基础上,构建新的网络,是近年来轻量化网络能够蓬勃发展的一个重要方法。轻量化网络的出现,将大而笨重的CNN从实验室中请了出来,逐渐走到实际的应用设备的应用中。除了该方法以外,还有CNN网络压缩[20]、基于神经网络架构搜索(Neural Architecture Search,NAS)[21]的自动化设计神经网络、基于 AutoML的自动模型压缩等一些列方法,这些方法中不泛很多简易的方法,如自动设计方法。
但是这些方法有着效果不理想,如CNN网络压缩方法,有时候并不能应用在移动设备中;而自动设计方法的难度较大,较高,并不适用于大多数的研究人员。构建新网络的方法有着门槛较低,效果较好等优点,尽管网络构建中有着很多不确定因素,但是得到较好结果的难度不大,因此在一定的时期内仍然具有旺盛的生命力。
猜你喜欢
精密成形工程(2022年2期)2022-02-22
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
小学生学习指导(低年级)(2019年3期)2019-04-22
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
小学生学习指导(低年级)(2018年9期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
小学生导刊(低年级)(2017年1期)2017-06-12
专用汽车(2016年1期)2016-03-01
