
多重因子分析技术在食品饮料行业感官分析中的应用
2021-07-23 07:30许晓青苏庆宇朱保庆
食品工业科技 2021年13期
许晓青,苏庆宇,王 冬,宋 昊,朱保庆,
(1.中国人民大学统计学院,北京 100872;2.北京林业大学生物科学与技术学院食品科学系,林业食品加工与安全北京市重点实验室,北京 100083;3.北京一轻食品集团有限公司,北京 102600;4.北京一轻研究院,北京 101111)
多重因子分析是一种能够用于描述和总结具有复杂结构和多方来源的多元数据的统计方法[1−2]。该统计手段在食品饮料和化妆品的感官分析以及消费者调研中广泛应用。本文将从多重因子分析方法的原理和步骤、该方法在感官分析上的应用(包括自由选择剖面、Napping等)、探索消费者感官驱动因素分析等方面进行综述,以期为感官分析从业者和相关领域科学研究人员提供参考。
1 多重因子分析介绍
多重因子分析(Multiple Factor Analysis,MFA)是一种多元统计方法,同主成分分析(Principle Component Analysis,PCA)有紧密的关系,可以看作是一种能够运用于多组多维数据上的主成分分析。主成分分析是指通过正交变换将多个变量转换成少数几个线性不相关的变量(称为主成分),从而达到降维的目的。多重因子分析是主成分分析的扩展,在主成分分析基础上考虑了各组不同类型变量的贡献[1−2]。在多重因子分析的基础上,也有学者衍生出了层次聚类的多重因子分析(Hierarchical Multiple Factor Analysis,HMFA)[3−5]。本文将以多重因子分析为核心来进行介绍。
1.1 多重因子分析的数据类型
能够用于多重因子分析的数据通常包含多个样本,每个样本有多组不同类型的变量[1−2,6],每组变量可以具有不同的数量甚至是不同的数据类型例如定性变量和定量变量。例如:a.食品饮料分析:每个食品/饮料是一个样本,感官分析的相关指标是一组变量,化学性质相关的指标为一组变量,物理性质相关指标是另一组变量[7−9],通过多重因子分析能够找到样品的特征[10];b.生态学:每个观测地点为一个样本,土壤相关的指标为一组变量,而植被相关的指标为另一组变量[11−12];c.调查分析:每个个体即为一个样本,每个问题就是一个变量,调查问题又可能会根据主题分为不同的组[13]。
1.2 多重因子分析的主要步骤
多重因子分析可以分为五步(见图1):a.将样本的变量分为多组;b.对样本的每组变量分别进行主成分分析,并获得每组变量各个主成分的特征值;c.利用各组变量第一主成分的特征值对各个组的变量进行标准化,将每个元素除以其第一组成分的奇异值;d.将标准化后的多个表格合并;e.对所有标准化过的数据进行全局主成分分析,并获得主成分的得分和因子载荷。多重因子分析还可以得到每组变量的局部因子得分,这样能够从各组变量的角度来观察样本[2]。
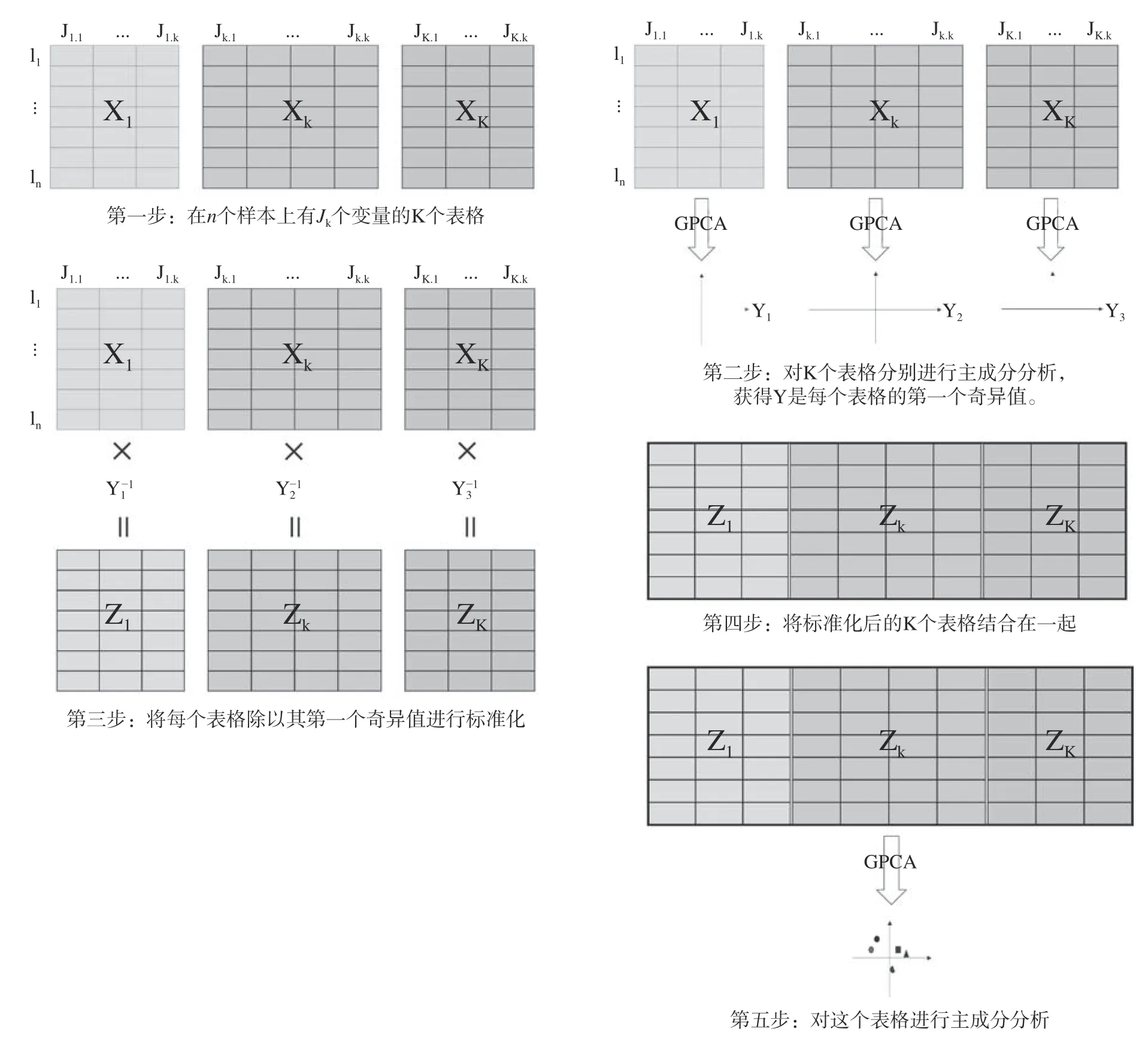
图1 多重因子分析步骤的可视化Fig.1 Visualized steps in Multiple factor analysis
2 MFA在食品饮料行业的感官分析中的应用
多重因子分析主要应用于以下几种感官分析方法的数据分析中:多个样品的感官分析比较[14]、感官分析多维度数据的比较[15]、Napping和投影地图[16]、多组感官数据的分析[17−20]、自由选择剖面或快速剖面[9]、消费者喜好的感官驱动因素的分析[21−23]等。后续将着重介绍该方法在自由选择剖面、投影地图和消费者喜好驱动因素分析中的应用。
2.1 投影地图
投影地图(Projective mapping)是一种快速测量产品的相似性并把产品投影到一张地图上的方法[24−26]。该方法引导经过或未经培训的评价员根据自身对样品感官特性的理解将样品在一张二维的长方形纸上排布[27];样品的位置和距离能够代表样品感官特性之间的异同,即样品在长方形纸上的位置越近就越相似[24]。由于评价员摆放样品的依据完全来自自己的理解,因此能够通过这种方法了解对于评价员而言真正重要的感官属性。这一方法是由Risvik和同事在1990 年代介绍的,直到Pages及同事在2000 后使用了Napping一词重新介绍了该方法(Napping在法语中表示桌布)[14],才得以广泛应用。目前该方法(Project mapping或Napping)已经被用于很多个食品饮料的若干品类上[26],例如奶酪[28−29]、葡萄酒[9,14,30]、橘子汁[31]、巧克力[32]、冷萃咖啡[8]和苹果[29]。Projective mapping或Napping近年来也发展出衍生的方法,例如结合了消费者喜好的Projective mapping方法[33]和排序的Napping(Sorted Napping)方法[34−35]。
从Projective mapping或者Napping中可以获得每位品评员各自对测试样品在长方形纸张上的位置信息,即样品坐标;此外Napping还允许品评人员对测试样品进行开放的文字描述,这对于了解品评员所绘制的样品图的维度是至关重要的。该方法所获得数据就是一组多元坐标定量数据集(见图2)。目前能够被用来分析Napping数据的多种方法已被报道,例如多元因子分析、广义适应分析(Generalized Procrustes Analysis,GPA)、INDSCAL[36]、STATIS[37]和Tucker法[38]。Nestrud等曾报道在他们的研究中,13 个柑橘汁被一组有经验丰富的厨师和未经训练的消费者品尝,并使用GPA和MFA分析同样的数据获得了非常相似的结果[39]。Tomic等[40]于2015 年曾对MFA和GPA两种方法应用在多个napping数据集上进行了比较分析,通过研究RV系数、个体差异指数(index of individual difference)以及布局散点图来考量两个方法的异同,该研究主要集中在二维分析结果的比较上;研究结果表明,两种方法在不同数据集上能够获得较为相似的结果,均能找出数据背后的共有结构,且两种方法的结果具有较高的RV系数,但两种方法在个体差异的分析和解读上存在区别;GPA揭示出的个体差异要小于MFA,而MFA因其能够提取大于2个以上的主成分使得该方法可能优于GPA。随后Tormod等[16]又用模拟数据和真实的Napping数据对INDSCAL和MFA方法进行了比较,结果发现两种方法在前两个维度的分析上表现出了非常相似的结果,SMI指数——一种基于奇异向量的用于比较一致布局(consensus configuration)的新的指标被用于方法比较,结果表明MFA要略优于INDSCAL。
已有大量文献报道使用MFA于Projective mapping或者Napping的数据分析上。Page`s在其研究中对来自法国卢瓦尔河谷的两个葡萄品种的10 款白葡萄酒被用于Napping品尝,文中对几个品尝员的桌布的使用进行了预查,发现品评员基本能够较好地使用整个桌布,但也发现通过肉眼很难直观地找到品评员对样品的排布规律。随后作者使用了MFA对数据进行分析,获得了10 款白葡萄酒的综合布局图,发现相对而言2 个品种的白葡萄酒各自聚集在一起。文章还结合专家组给出的感官轮廓分析结果对MFA综合布局图进行了解释,对品评员的Napping之间的差异等进行了讨论,并提出,当产品多于12 个将不适合使用本方法进行分析[14]。Nestrud等[39]曾报道在他们的研究中,一组有经验丰富的厨师和一组未经训练的消费者分别品尝13 个柑橘汁,使用napping的方法获得每个品尝员对产品的感官数据,并使用GPA和MFA对数据分析。Dwiranti等[8]对冷萃咖啡的工艺对感官的影响进行了研究,在他们的实验中,对采用了不同静置时间的6 款冷萃咖啡进行投影地图感官评价,75 名未经任何训练的品评员被要求在一张60×60 cm的纸上对冷萃咖啡样品根据其异同进行排布,并对每个样品给出简要的感官描述词,包括气味、风味、酸度、余味、颜色和醇厚度。文章中使用MFA对投影地图结果进行分析。结果表明品评员能够将多款冷萃咖啡区分开来,且气味和风味是重要的贡献因素。实验还表明,静置1 和3 d的样品最接近无静置处理的对照样品。在Napping方法的基础之上,衍生出了Sorted Napping的方法,同Napping数据的差异在于除了品评员对产品要给出坐标之外,品评员还需要给产品进行排序,因此通过Sorted Napping还能够获得产品的排序数据,因此应运而生的Hierarchical Multiple Factor Analysis(HMFA)就可以被用来分析这样的数据。HMFA是MFA的衍生方法,适合应用于存在嵌套的分组数据上,通过Sorted Napping不仅获得了品评员给出的产品坐标数据、语言描述词,还获得了每个品评员对产品的分组结果。Pages等[34]的文章中选取了来自2 个品评的各4 种口味的一共8 个奶昔产品,24 个品评员被要求品尝这些奶昔,并按照Sorted Napping的方法将产品放置于桌布上,即当品评员认为产品较为接近时,这些产品将离得比较近,反之,产品则在桌布上的位置距离较远。同时,品评员也被要求将他们认为可以放到一组的产品画一个圈标识起来并给出感官描述词。品尝结束后,工作人员收回结果并作整理,将得到如Napping的数据,在Sorted Napping中,还可以获得每个品评员对每个样品的分组情况。对于这样的数据,文章建议使用HMFA的方法来进行分析,原因是HMFA能够一方面平衡各个品评员的结果,另一方面又能够平衡考虑每个品评给样品的二维平面的排布和对样品的分组结果,这使得这一方法能够综合利用Sorted Napping中获得的全面数据而获得一个具有综合考量效果的样品布局结果[34]。
2.2 MFA用于分析不同来源的食品饮料的感官数据
MFA还经常被应用在同一组样本的不同来源的感官数据的比较上,这里的不同来源的感官数据可以是感官方法的不同,也可以是不同的品评小组对同一组样品的感官描述的异同,也可以是不同的感官评价方法对同一组样品的分析,也可以是不同的品评员,例如MFA在自由选择剖面方法中的应用。
Gutiérrez-Salomón等[18]比较了两种不同的样品准备和呈送给品尝员的流程对品尝员使用CATA(Check-All-That-Apply)方法的品尝结果的差异,使用了MFA对这两组不同来源的感官数据进行了分析,MFA结果表明样品准备和呈送的方法对消费者感官测试的结果没有显著影响。Reinbach等[41]使用MFA对三种基于消费者的感官分析方法CATA、带有强度的CATA和Napping进行了比较,文中使用了MFA生成了一个综合了三种感官方法的样品感官图并同每种方法给自生成的样品地图进行比较,除了可视化的样品地图,MFA中获得的RV系数的比较也指示了三种方法在样品的差异性上表现出的一致。
除了多个来源的感官数据,某些描述性的感官分析方法例如自由选择剖面分析法,由于其方法的特点在一个实验中就类似于获得了不同来源的感官数据。自由选择剖面分析法(Free Choice Profiling,FCP)是一种描述性的感官分析方法,感官评价员可以自由选择自己用于描述的词汇,并对样品的该特征打分。感官品评员不受限于固定的感官词汇[9,42]。通过FCP获得数据结构如图3 所示。目前已报道有多种统计方法可以用于对FCP数据的分析,如广义适应分析[43−44]、INDSCAL法[16]和MFA[1−2,16]。多重因子分析在FCP数据上的优点主要在于,能够平衡各组数据来获得一个全局的分析结果,这里各组就指的是每个品评员,由于品评员给出的描述词汇不尽相同,保证没有任何一个或某几个品评员给产品的描述词以及打分主导最终产品差异的评价结果就非常重要了[45]。快速剖面是FCP方法的变种。同FCP类似的是,在FP中品评员能够自由使用自己的语言来评价产品,但不同的是,他们要根据样品的在这些指标上的差异对样品进行排序,更加强调产品的相对差异。因此FP同样产生了来自多个品评员通过不同维度评价样品的数据集,因此MFA也可以应用在快速剖面数据集的分析。

图3 自由选择剖面数据结构Fig.3 Data structure in free choice profiling
当研究中不仅仅有感官数据,还有其他来源或者类型的数据时,例如样品的物理分析或者化学分析的数据,MFA还非常适用于联合分析这些不同类别的数据。He等[46]的报道中对腐乳进行了多个维度的分析,其中包括来自两种感官分析方法获得的感官数据(QDA和FP)、GC-MS靶标挥发性化合物分析以及物理性质分析,MFA在该文中被用于解释这三类指标之间的关系以及物理化学指标对感官的贡献。
2.3 MFA用于分析消费者对食品饮料产品的喜好感官驱动因素
当分别获得了产品的专家定量感官描述分析数据(如QDA数据),以及消费者的产品喜好得分,如何能够充分利用这两种数据来解释和理解消费者对测试产品的感官喜好呢?目前已经有几种可行的方法,例如投影地图、相关性分析、回归分析、偏最小二乘法以及多重因子分析等[20,47-48]。其中,产品偏好地图又分为内部产品偏好地图(Internal Preference Mapping)和外部产品偏好地图(External Preference Mapping)[48]。内部产品偏好地图是建立在消费者喜好地图上的偏好地图,将产品的专家感官描述映射到的消费者喜好地图上;外部喜好地图则是在外部指标(例如感官描述或者物理化学分析指标等)的基础上构建二维地图,并将产品喜好得分通过PCR做回归反映在地图上。这两种方法各有利弊,例如内部偏好地图法的局限在于,消费者可能对感官上来看完全不同的多个产品表现出相同的喜好,从而无法客观挖掘喜好驱动因素;而外部产品喜好则通过两个的维度的外部数据(例如感官)来代替了全部的产品特征数据,而这两个维度尽管涵盖了产品差异的主要信息,但导致消费者喜好的因素可能不能被这两个维度所涵盖。因此随后就产生了能够兼顾感官数据和喜好数据的以偏最小二乘(PLS)为基础的分析方法,而PLS的局限性在于PLS通常会将喜好得分平均化,即丢失了个体差异[49]。因此需要一个能够保留个体的喜好差异并能够结合两种不同类型的数据一起分析的方法,MFA能够更好的满足这种需求。目前这种方法已经在多个产品品类中应用于寻找驱动消费者喜好的感官因素,进而帮助产品开发人员和市场人员为开发新产品或者改进产品口味提供数据依据[47,50]。
以下以R的包SensoMineR自带数据集鸡尾酒数据cocktail为例进行分析(数据来源:http://sensominer.free.fr/cocktail.htm)[51]。该数据集包含两个表:鸡尾酒的感官数据和消费者对鸡尾酒的喜好数据。数据中对16 款鸡尾酒样品进行了分析,感官分析包含13 个感官变量,喜好数据中包含了100 名消费者对这些样品的打分。
通过对这两部分数据使用MFA进行分析,结果见表1,第一个特征值为1.71(接近2 组数据下的特征值最大值2),这说明感官数据维度的差异与喜好数据维度的差异具有较大程度的吻合性。进一步考察能够用来衡量两组变量的相关性的RV系数,计算得到RV系数为0.59,这说明样品的喜好数据和感官数据具有一定相关性,但该系数并没有非常高,仍说明这两组数据中的一组并不能完美的被另一组数据解释。此外,还可以通过Ng或者Lg系数来评估两组变量的关联程度,其中Ng系数能够表明某组变量内部的维度性(dimensionality);Lg系数表明这组变量共同特征的丰富程度[48,52]。在本例的数据中,喜好数据比感官数据相比具有略更高的维度性(Ng(hedonic)=1.31,Ng(Sensory)=1.25),Lg(Sensory*Hedonic)=0.75,同喜好数据自身的维度性相比,能够一定程度地解释喜好数据,但仍有一部分未能被解释(见表1)。

表1 鸡尾酒数据的感官数据和喜好数据的Ng和Lg结果Table 1 Ng and LG results of sensory data and preference data of cocktail data
进而,将局部维度的代表性(partial axes representation)进行可视化,获得图4A,从图上可以看到,MFA的第一和第二维度同感官数据和喜好数据高度相关,这进一步证实感官数据和喜好数据的关联性,为利用前两个维度来解释喜好数据提供支持。然后,绘制样品个体因子地图(Individual factor map)(图4B),从图中可以得知,样品3 在感官维度和喜好维度表现出最大的不一致,而样品9 则表现出最强的一致性。最后,用前两个维度的MFA结果中的感官数据对喜好数据作回归,这里使用了二次模型,并以消费者的平均喜好程度作为可接受程度的参考,就获得了如图4C的响应面地图;基于此,发现在样品11、样品2 和样品3 位置附近的产品能够赢得高于80%的消费者喜爱。
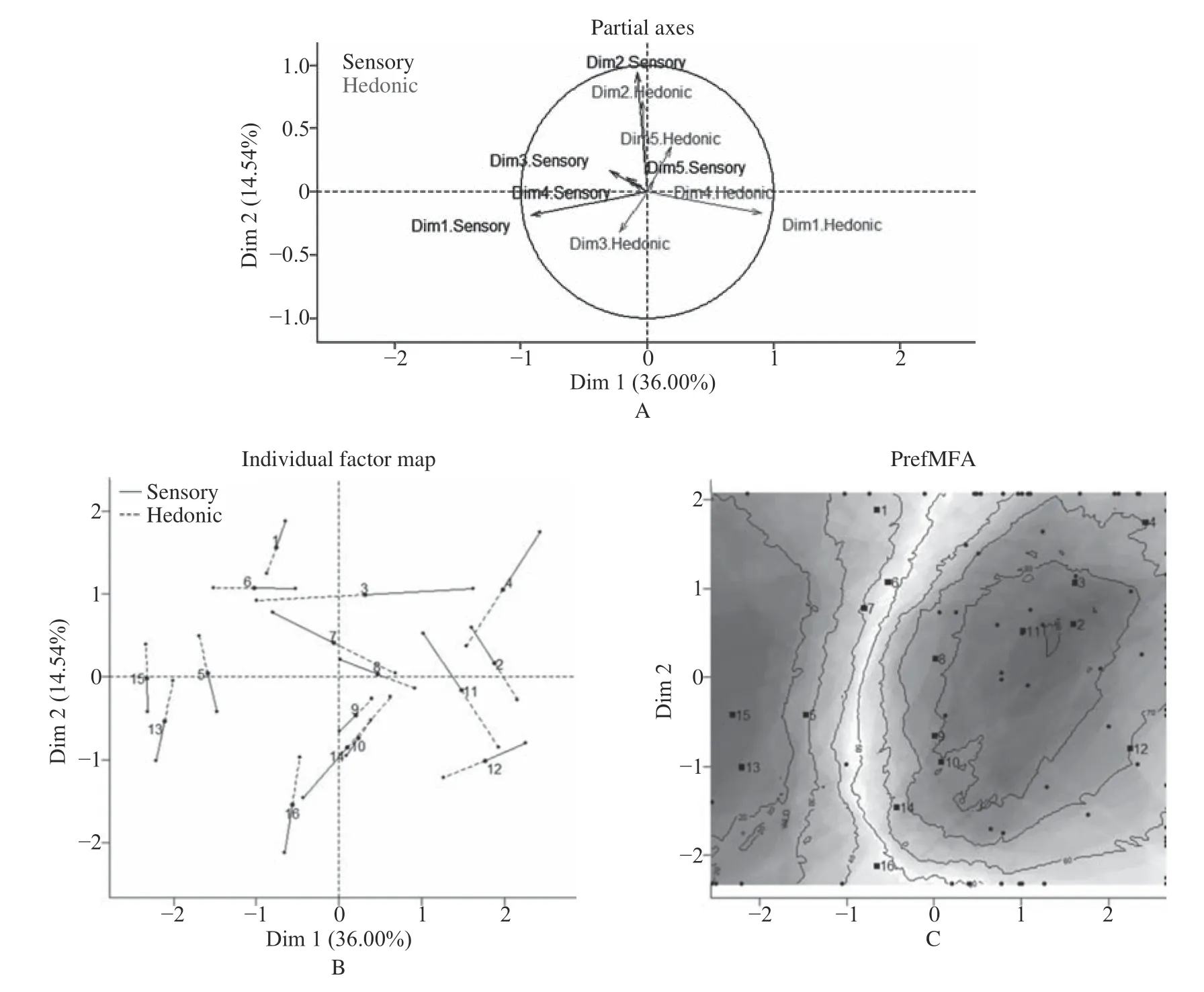
图4 鸡尾酒数据多重因子分析结果Fig.4 Multiple Factor Analysis on cocktail data
目前已有多篇研究报道了类似的方法在食品饮料行业各种品类上的应用。Ares等[47]的研究中有80 名消费者对8 种香草牛奶甜品进行了品尝,对每个样品给与9 分制的喜好得分,并使用4 个词描述每个样品,这些样品也被受过训练的品尝员进行描述分析。MFA被用于结合消费者的描述词、消费者给出的喜好得分和专业品评员的感官描述数据绘制了综合的产品图,这一方法提供了另一种分析同消费者喜好最相关的感官特征的途径,同时还能够了解感官数据和消费者喜好之间的关系。Partida-Sedas等[50]研究了Garnica咖啡豆采后处理技术对咖啡饮料的感官特点以及消费者喜好的影响,MFA被用于分析专家品评员的感官数据和消费者给出喜好数据的关系以及综合的产品地图的绘制,同时还能够看到三种不同采后处理技术对结果的影响,随后PrefMFA被用于获得消费者理想喜好地图,对采用合适的技术以获得消费者喜欢的咖啡具有重要数据指导意义。
3 结论
多重因子分析是一种可以适用于多种感官分析技术的多元统计分析技术,其核心是主成分分析,但能够兼顾多个不同数据类型、多种数据来源的数据进行分析并对结果进行描述和展示。多重因子分析在食品饮料感官分析中具有很大的作用,例如在自由选择剖面分析、Napping或者投影地图以及消费者喜好感官驱动因素分析中都能够被应用,且通过对结果的展示可以对产品的特征进行描述、通过产品特征的不同对产品进行分类以及找到潜在消费者喜好驱动因子。在使用MFA的案例中,对数据结果的正确解读尤为重要。此外,在MFA基础上延展而来的方法有:层次多重因子分析(Hierarchical Multiple Factor Analysis,HMFA)、双多重因子分析(DUAL-MFA)、普式多重因子分析(Procrustes MFA)等,因篇幅和内容重点的考虑本文暂未纳入上述内容,这些技术在感官技术和消费者研究数据分析中的应用同样值得探讨。
猜你喜欢
当代陕西(2022年4期)2022-04-19
北方水稻(2021年6期)2021-02-17
当代陕西(2020年22期)2021-01-18
食品安全导刊·中旬刊(2020年11期)2020-12-28
食品安全导刊(2020年32期)2020-12-02
中华诗词(2019年7期)2019-11-25
文理导航·科普童话(2017年4期)2018-02-10
文理导航·科普童话(2017年2期)2017-05-31
未来英才(2016年13期)2017-01-13
吐鲁番(2014年2期)2014-02-28
