
融合语言学知识的神经机器翻译研究进展
2021-07-22 17:02郭望皓范江威张克亮
计算机与生活 2021年7期
郭望皓,范江威,张克亮
1.战略支援部队信息工程大学 洛阳校区,河南 洛阳 471003
2.郑州大学 信息工程学院,郑州 450001
自1954 年世界上第一个机器翻译系统问世以来,到今天已经有60 余年了。期间,机器翻译经历了百花齐放、百舸争流的盛况,也经历了万籁俱静的萧条与沉寂。主流机器翻译技术发展范式由基于规则的方法,演进到统计方法,再到时至今日的神经网络方法。随着机器翻译译文质量的提升,其应用也由实验室走向人们的日常生活之中,满足大家阅读、会谈、出行、购物等跨语言交际的需求。2013 年以来,神经机器翻译由于不需要设计复杂的特征工程,模型简洁高效得到了研究者与开发人员的青睐,加之并行计算、图形处理器、大数据的广泛应用,在学界和产业界迅速掀起了神经机器翻译的研发热潮,推动神经机器翻译向实用化、商业化方向不断迈进。尽管神经机器翻译取得了巨大成功,但是依然存在着诸如翻译不忠实,存在“过译”和“漏译”现象,罕见词(rare word)和集外词(out of vocabulary,OOV)处理困难,低资源语言表现不佳等问题[1-3]。神经机器翻译架构本身导致了上述问题的产生。表1 显示了目前神经机器翻译存在的问题及原因。

Table 1 Problems and causes of neural machine translation表1 目前神经机器翻译存在的问题及原因
为了缓解上述问题,学者们提出了诸多方法改进神经机器翻译模型[4-8]。其中一项重要的思路就是将语言学知识融合到神经网络之中,从而提升系统性能,提高翻译质量。纵观机器翻译发展史,语言学知识一直发挥着不可替代的重要作用。尤其是在早期阶段,基于规则的方法占据主导地位时,从源语言的剖析,到目标语言的生成,再到翻译规则的制定,每一步都离不开语言学知识的指导,形态学、句法学、语义学的发展一直为基于规则的机器翻译技术提供养料。在统计机器翻译发展的黄金十年内,利用层次短语解决具有长距离依赖关系的词语翻译问题,利用句法学解决目标语短语调序问题,无一不在证明着语言学知识在以数据驱动为主的机器翻译时代仍具不可替代的地位与作用。在目前主流的神经机器翻译框架中,源语言和目标语言都被当作字符串进行序列化的处理,这样做一方面使得模型变得简洁,不需要再进行复杂的切分、对齐、调序等处理流程,但与此同时也使得许多重要的语言学信息在此过程中丢失。因此,学者们希望在借鉴基于规则机器翻译、统计机器翻译的相关研究成果的基础上,通过对语言学知识进行显性建模,并与神经机器翻译模型相融合,以其能够缓解神经机器翻译面临的固有困境,改进神经机器翻译模型,进一步提升翻译的质量。
有关融合语言学知识的神经机器翻译的研究成果目前散见于与此话题相关的综述和研究性论文之中,它们要么就是简单列举、一笔带过,要么就仅关注某一方面的内容,缺乏系统性的梳理、归纳和总结。本文针对融合语言学知识的神经机器翻译这一方向,选择具有代表性的研究成果,从三方面分别介绍融合字词结构信息、短语结构信息和句法结构信息的神经机器翻译最新研究进展,展现本领域研究发展脉络,总结现有研究的特点与规律,探讨未来研究发展方向,为进一步的相关研究提供文献支撑。
1 融合字词结构信息的神经机器翻译研究
在融合字词结构信息方面,最主要的思路是通过对词以下的结构单位进行编码,降低颗粒度,从而在不改变词表规模、不增加计算时空开销的同时减少集外词的数量。由于神经网络计算量大,因此通常会将源语言和目标语言的词表规模控制在3 万到5 万,把词表外的罕见词、集外词统一处理为
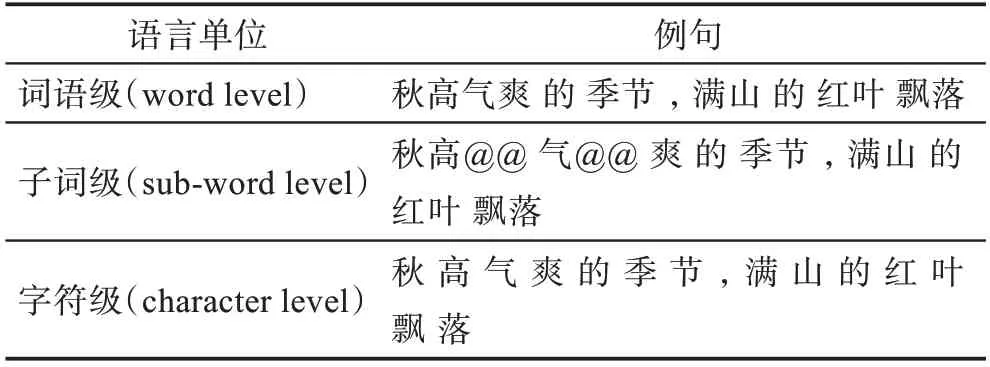
Table 2 Different levels of language units and sentences表2 不同层级语言单位及例句
采用字符作为神经机器翻译的基本语言单位,除了可以消减集外词问题之外,对于诸如汉、日、韩、泰等语言还可以避免分词带来的误差,并且受语言形态变化影响小,有助于提升形态丰富语言(德语、俄语、土耳其语等)的词语利用效率。Kim 等人、Hahn 和Baroni 的研究均涉及到利用神经网络将字符序列转化为词向量的方法[10-11]。Ling 等人[12]提出在基于注意力机制的神经机器翻译模型前后两端分别增加字符到词(character to word,C2W)的组合模块和词向量到字符(vector to character,V2C)的生成模块。组合模块利用一个双向长短时记忆网络(bidirectional LSTM)在双语两端把字符向量组合成词向量;生成模块是将字符向量、注意力向量和目标词向量进行拼接后通过另外一个单向的长短时记忆网络(long short-term memory,LSTM)逐字符生成目标语言的词语(见图1)。该模型能够学习到部分词缀(包括前缀和后缀)在原文和译文之间的对应关系,因此可以识别和生成一些词表中不存在的词形,这对于形态复杂的语言间的翻译确实有所帮助。但是,该方法需要在双语语料中为每一个单词和句子分别添加开始和结尾的标记,注意力机制仍作用于单词而非字符之上,且实验结果与基于单词的神经机器翻译模型相比未有显著提高,同时模型复杂程度高,训练所需时间长。原因在于,以字符为单位统计出的句长一般是以单词为单位句长的6 到8 倍(由于汉语字符数量多,因此不到2 倍),造成注意力机制运算量呈平方级增长,同时增加了长距离依赖学习的难度,降低了训练速度。
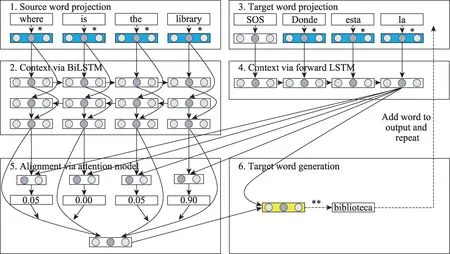
Fig.1 Illustration of NMT model with composition module and generation module图1 加入组合模块和生成模块的NMT 模型示例
针对这些问题,Lee 等人[13]提出了采用多层卷积(a stack of convolutional)、最大池化(max-pooling)操作与高速公路神经网络层(highway network layers)的处理方案。具体而言,先将输入字符映射为字符向量,再利用窗口大小不一的卷积层进行卷积(相当于学习到与窗口大小相同的N元语言模型),然后把卷积输出成分连接起来后再切分成长度固定的序列,对每个序列作最大池化操作(相当于选择最显著的特征作为分割向量(segment embeddings)),最后将这些分割向量(相当于具有语言学意义的结构单位)经过高速公路神经网络层和双向的门控循环单元(bi-gate recurrent unit,Bi-GRU,LSMT 的一种变体)进行编码。在解码阶段,注意力机制通过关注源语言的分割向量,并通过一个字符级的门控循环单元生成目标语言的字符序列。德-英、捷克-英、芬兰-英和俄-英机器翻译实验结果表明,该字符级的神经机器翻译模型在拼写错误单词、罕见词、词形变化、临时构造词翻译处理方面具有优势,同时对于像德、捷克、芬兰这些字符相近的语言,字符级神经机器翻译模型能够学习到各语言间通用的语素,可以在不增加模型规模的条件下通过共享一个编码器实现多语言(多到一,many-to-one)机器翻译。
基于字符的神经机器翻译虽然减少了集外词的数量,缓解了词表规模受限问题,但是单个字符义项增加,更容易产生歧义,并且增大了长距离依赖问题,导致长句翻译质量下滑。为此,有学者提出采用介于词语和字符之间的语言单位进行编码,其中最具代表性的工作当属Sennrich 等人[14]提出的子词(sub-word)字节对编码(byte pair encoding,BPE)方案。作者受命名实体、同源词、借词、复杂形态词(这些词大部分属于罕见词或集外词)翻译策略的启发,当专业译员遇到这些不认识的单词时往往会通过分析其组成成分预测单词的意义,因而认为将这些罕见词或集外词处理为子词有助于缓解神经机器翻译的词表规模受限问题。具体而言,这种方法将经常组合在一起的字符序列看作一个单位,如英文中的词缀“er”“ism”“dis”,词尾“ed”“ing”等。做法是将所有单词以字符划分,不断将频次最高的N-gram 进行合并操作,一直迭代至词表规模大小。实验结果显示,在WMT15英德和英俄任务上,较之于传统的神经机器翻译模型,基于子词的模型BLEU(bilingual evaluation understudy)值分别提升了1.1 和1.3。相对于基于单词的神经翻译模型和基于字符的神经翻译模型,该研究提出的子词模型在词表大小和句子长度两方面取得了平衡。由于子词单元能够在相近或者同源语言间共享词干、词缀和词尾的信息,基于子词的神经机器翻译方法得到了广泛的应用,由最初仅用来处理罕见词或集外词,发展到全部单词均切分成子词单元再喂入神经网络模型之中进行运算。这一方法也在某些语言间(如英、法、德等)的翻译系统中逐渐成为标配,著名的谷歌神经机器翻译(Google's neural machine translation,GNMT)系统[15]和Transformer 系统[16]也都采用这一设计思想和处理方式。
还有的研究工作,在源语言编码和目标语言解码两端分别使用不同层级语言单位进行建模的方案。Costa-Jussà等人[17]在源语言端通过卷积滤波器(convolution filters)和高速公路网络层(highway layers)实现了由字符到词向量的映射过程。字符级编码方式利用单词的内部信息,能够捕捉到源语言所有单词的全部表达形式,消减了源语言端的集外词问题。但在目标语言端仍以词语为单位进行解码与生成,因此这一方案仍然受到词表规模的限制。Chung 等人[18]的主要工作是在解码端使用了一种新的名为双尺度循环神经网络(biscale recurrent neural network)的结构,可以在字符和单词两个时间尺度上进行处理,不需要进行分词,直接生成目标语言字符序列。但是该研究在源语言端采用的还是子词结构。与之相似的还有Yang 等人[19]、Su 等人[20]的工作。
有的研究工作将不同层级语言单位编码后混合到同一神经机器翻译模型之中。Luong 和Manning[21]设计了一个字符-单词混合的神经机器翻译模型。整个模型主要由单词级模块驱动,当出现
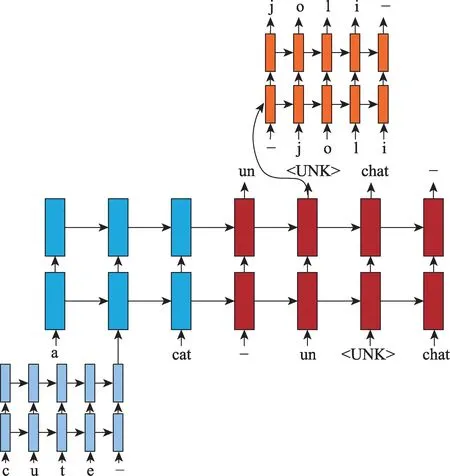
Fig.2 Illustration of word-character model hybrid NMT图2 字符-单词混合NMT 模型示例
Chen 等人[22]提出同时将字信息与词信息进行编码,即将不同颗粒度语言单位表示融合到一个神经机器翻译系统之中。在源语言端,先用两个独立的注意力模块分别学习每个单词的词内字符向量和词外字符向量,前者可提供单词内部字符间关系信息,后者提供单词边界信息;再将学到的两个字符向量通过前馈神经网络连接后嫁接到词(或子词)向量之上,形成具有字符信息的词向量;然后将此词向量喂入循环神经网络进行计算。在目标语言端,解码器采用了一个多尺度的注意力机制(multi-scale attention mechanism)模块,该模块既能采集到词向量蕴含的信息,也能够采集到字向量信息。实验表明,在汉英互译任务中,该模型表现优于单纯基于字符以及单纯基于单词的神经机器翻译模型;在英译德任务中,该模型优于采用BPE 技术的子词翻译模型。实验结果还显示,这种方法不仅可用于缓解神经机器翻译的集外词问题,而且对提升常见词翻译的准确性也有所帮助,原因在于编码器中融合了由字符提供的单词的内部信息与边界信息。Wang 等人[23]的工作也是用一个混合注意力机制模型将源语言的单词信息和字符信息分别编码,两类信息具有兼容性和互补性,该方法在汉英机器翻译实验中与传统基于单词的基线模型相比取得了1.92 个BLEU 值的提升。
除此之外,还有研究者将目光转向到比字符颗粒度更低的语言单位:亚字(sub-character)。如果说亚词能够学到词干、构词词缀和构形词缀的信息的话,在中、日等语素文字(ideographs/logograph)体系中亚字就包含了构件(如汉字的偏旁)的语义信息。现代汉语中,形声字的比重占到90%左右,也就是说绝大多数的汉字能够拆分为“声旁”和“形旁”,其中“形旁”相同的汉字往往在意义上有联系,如“桃、梅、梨、枝、株、棵”都与树木有关,这就为基于亚字的神经机器翻译模型提供了基础。另外在汉语和日语中,有时相同或者相近的字形表示相同的意义,如中文汉字“风景”和日文汉字“風景”写法相近,意义相同,因此在中日互译时其汉字组成成分间的信息可以互享,从而提高表示精度。Zhang 和Komachi[24]就进行了这方面的研究。该研究在中、日、英三种语言的翻译中开展,英语采用词向量,中、日文分别采用词向量、字向量、构件向量和笔画向量。除词以外的语言单位均采用BPE 技术切分组合而得。实验结果显示,对于中文,基于构件的表示方法能够提升模型的翻译质量,而对于日语,基于笔画的模型才是最优解。
纵观上述研究,不难发现,在神经机器翻译模型中,降低翻译单位的语言颗粒度,确实能够在以下几个方面改善翻译质量:(1)降低了由集外词和罕见词带来的负面影响;(2)对于形态变化丰富的语言,提升了词表的利用效率;(3)对于词语间无明显边界的语言,避免了由分词带来的误差。探求这些现象背后的原因,从语言学的角度来看,改变语言颗粒度大小的实质就是如何更加有效地利用不同语言自身所具备形态学特征。但从目前的研究来看,主要存在的问题是,大多数研究仅仅局限于英、法、德、俄、西、葡、捷克、芬兰等具有同源或者近源的语言之间,偶尔涉及汉、日、阿等语言,对于世界上大部分的孤立语、黏着语、多式综合语缺乏关注,因此难以取得普遍性、规律性的结论。未来的研究将视线转到但不局限于以下几个方面:(1)降低翻译单位的语言颗粒度,势必会增加长距离依赖问题,尤其对那些形态句法一致性要求高的语言来说,这一问题造成的损失甚至会超过改变语言单位带来的收益;(2)针对不同的语言,在编解码两端究竟应该采用哪一层级的语言颗粒度作为其基本翻译单位,其背后存在何种规律,是否与人类语言类型有关,能否进行合理的解释;(3)在神经翻译现有框架下,如何更好地利用形态学的信息,形态学信息如何更好地与短语信息、句法信息等相互融合,共同推进翻译质量的提升。
2 融合短语结构信息的神经机器翻译研究
短语结构的意义并非都是其组成成分的简单加和,这样的例子在各种语言中比比皆是、屡见不鲜。如英语中的“let alone(更不必说)”“by and large(总的来说)”“red tape(繁文缛节)”,汉语中的“网络水手”“买面子”“996(指每天早上9 点上班,晚上9 点下班,一周工作6 天)”等。由此可见,在翻译过程中,短语占据着举足轻重的地位和作用。统计机器翻译发展历程中也证实了这一点,正是基于短语的统计机器翻译[25-27]技术走向成熟,机器翻译才算真正地走向实用。
由于统计机器翻译在短语翻译研究方面有着较长时间的积累和较为成熟的经验,如何利用既有研究成果与神经机器翻译模型相融合就成为研究者们自然而然的想法了。Wang 等人[28]就是在神经机器翻译的解码器上增加了一个统计机器翻译模块用于生成短语。每当解码器工作到下一步时,先通过一个名为balancer 多层神经网络判断要生成的单词还是短语,如果要生成单词,那就还用神经机器翻译模块进行生成;如果要生成短语则调用统计机器翻译模块的结果。与之类似的研究还有Tang等人[29]、Dahlmann等人[30]、Rikters 和Bojar[31]的工作,但是他们的研究都借助于外部装置提取并记忆短语翻译的结果,神经机器翻译模型本身并不能处理生成短语结构。
利用神经网络进行短语结构的翻译就需要从编码器和解码器入手,通过扩充或者改造,使其具备处理短语层级信息的能力。Li 等人[32]提出的模型有两个编码器和一个解码器:两个编码器分别以单词和短语为单元对源语言的句子进行编码,解码器工作时会同时考虑单词向量和短语向量中蕴含的信息。这个简单的结构在汉英翻译任务中取得了不错的成绩,较之于传统模型平均提高了1.13 个BLEU 值。Ishiwatari等人[33]提出的模型则包含两个解码器,一个用于处理短语(文中称为组块或语块chunk)间的依赖关系,而另一个用于对短语内单词间的关系进行建模。该方法在WAT16 英日翻译任务取得了出色的成绩。Zhou 等人[34]的工作是在解码器中引入一个额外的神经网络层,实现了从短语到单词分层次的译文生成过程,在多种语言上进行的实验结果表明该方法能够显著提高翻译质量。Huang等人[35]提出了基于短语的神经机器翻译(neural phrase-based machine translation,NPMT)。他们提出的方法不需要事先准备短语,目标语言端的短语是通过一个Sleep-Wake 网络(sleep-wake networks,SWAN)和一个调序层(reordering layer)从训练语料中自动提取到的(见图3)。SWAN是Wang 等人[36]提出的一项基于分割的序列建模技术。实验结果显示,这一方法能够将目标序列切割成为具有语言学意义的短语。在IWSLT2014 德英互译、IWSLT2015 英译越数据集上BLEU 值结果显示,这种方法超越了基于注意力机制的神经机器翻译模型。

Fig.3 Illustration of phrase-based NMT model图3 基于短语的NMT 模型示例
可以看出,为了能够显式地利用短语结构信息指导翻译过程,突出短语在神经机器翻译中的作用,学者们做了两方面的努力:(1)利用统计机器翻译在处理短语结构时积累下的优势,探索统计机器翻译模型与神经机器翻译模型相互结合的方法,使得二者各自的优势都能得以充分发挥;(2)改进神经机器翻译模型,使其具备处理短语结构的能力,从而提升短语翻译效果。相较而言,这两类工作前者更侧重于工程实践,目的在于取得更高的翻译质量,后者则更偏向于科学探究,目的在于神经机器翻译模型的进化与迭代。经梳理统计发现,后者的研究主要集中在解码端,即在解码器中集成短语生成模块,而在编码端的短语识别由于涉及短语提取、短语切分等其他技术,目前还未得到充分关注。另外这类相关实验中,解码端作为目的语的语种通常是诸如德、日、捷克等语序较为灵活的语言,对于语序较为固定的分析语来说,如何在合适的位置生成短语依然面临不小挑战。其实无论在短语内部各词语之间,还是在短语外部与其他词语之间,都包含着大量的语言学知识,如何能够利用这些句法语义关系来改进神经机器翻译模型,是未来研究的一个重要方向。另外,短语结构信息与不同类型的神经机器翻译模型(Transformer、CNN(convolutional neural networks)等)融合问题,也是一个新兴且颇具挑战性的课题。
3 融合句法结构信息的神经机器翻译研究
句子并非单词的简单线性排列,它是有层次关系结构的。如:“关心孩子的母亲”,既可能是一个动宾结构“关心/孩子的母亲”,也可能是一个定中结构“关心孩子的/母亲”;“门把手弄坏了”,既可能是“门/把/手/弄/坏了”,也可能是“门把手/弄/坏 了”。因此将句法结构信息融合至机器翻译系统中有助于消解歧义,提升翻译的准确性。早在统计机器翻译时代,句法结构信息的价值就已经得到了证明[37-42]。受上述研究的启发,学者们尝试将未被显式建模的句法结构信息融入到神经机器翻译模型之中,其中主要用到的两种句法理论分别是短语结构语法和依存语法。
在源语言端融入句法结构信息的研究有:Eriguchi 等人[43]在研究英日机器翻译时发现,两种语言在语序、句法结构方面均有较大差异。一般的注意力机制模型难以处理词与短语、短语与短语之间的对齐,为此他们提出了树到序列(tree-to-sequence)的注意力机制神经机器翻译模型。其核心思想是,在编码阶段,利用中心语驱动的短语结构文法(headdriven phrase structure grammar,HPSG)对源语言进行自底向上的编码,从而获得了源语言的短语结构信息(见图4)。在WAT15 英日数据集上的测试结果证实了这种方法的有效性。

Fig.4 Illustration of tree-to-sequence NMT model based on phrase structure grammar图4 基于短语结构文法的树到序列NMT 模型示例
Chen 等人[44]在此基础上,对源语言端的单向树状结构进行了强化,变成自底向上和自上而下双向编码,在一定程度上克服了Eriguchi 等人研究中存在的顶端节点包含的句法信息多,底端节点包含的句法信息少的问题。此外,在解码端引入了基于树的覆盖率机制[45],可以有效地将源语言上下文知识整合至注意力机制之中。研究采用宾州汉语树库作为源语言的句法剖析工具。在NIST 英汉翻译数据集上的实验结果显示,该方法较之于基线神经机器翻译系统平均高出3.54 个BLEU 值,在同等条件下双向编码较之于单向编码高出0.79~0.96 个BLEU 值,而基于树的覆盖率机制的引入则提升了0.40~1.13 个BLEU值。与Chen 等人抛弃句法标签信息的做法不同,Li等人[46]的工作是将句法树转化为句法标签后与词语混合成为同一个线性化序列,这种方法的好处在于避免树的复杂网络结构(见图5)。实验结果显示,在长句翻译、词及短语对齐准确率和过译三方面均优于基线神经机器翻译模型。
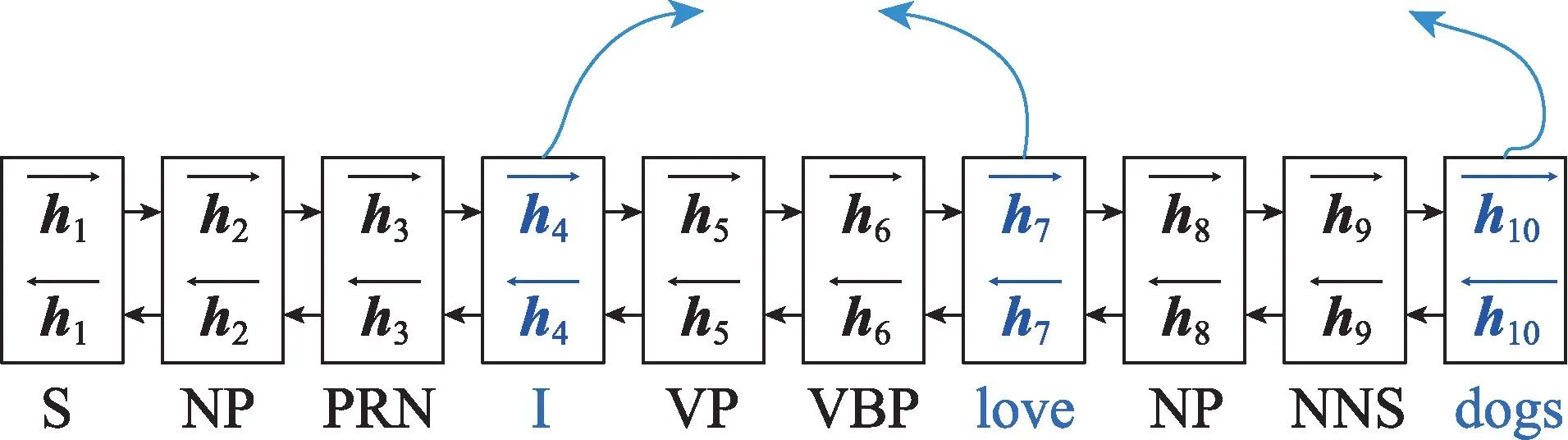
Fig.5 Illustration of syntax tags linearization图5 句法标签序列化示例
除了短语结构文法,依存文法在源语言编码方面也有不少应用。其中代表性的工作是Bastings 等人[47]利用图卷积网络(graph convolutional network,GCN,图神经网络GNN(graph neural network)的一种)对源语言的依存结构进行编码。他们的研究将GCN 叠加在CNN 之上,以CNN 编码后的隐层向量作为输入,通过依存结构信息对隐层向量进行图学习,为每一个词生成一个包含依存句法信息的向量,从而使得翻译模型获取句法知识。除此之外,在源语言融入句法知识的还有Ma 等人[48]的森林-序列(forest-tosequence)模型,Xu 等人[49]的图-序列(graph-to-sequence)模型等,Sennrich 和Haddow[50]将词性还原、词性和依存句法标签向量化后与词向量进行拼接,新的词向量就包含不同层级的语言学信息。
在目标语言端融入句法知识的研究有Nadejde等人[51]将组合范畴文法(combinatory categorial grammar,CCG)标注引入神经机器翻译的解码器端,其方法有两种:一是将句法标签与目标语言词语交叉排列,即一个词语一个对应的标签,输出序列长度增加一倍;二是借鉴多任务学习(multi-task learning)的思路,将句法标签序列与目标语言序列分别用一个解码器进行解码。在德语-英语和罗马尼亚语-英语的翻译实验证实了解码阶段加入句法知识的有效性,且第一种方法的结果优于多任务学习的方法。实验还显示,如果同时在源语言端也加入语言学知识的话,翻译性能会得到进一步提升。Aharoni 和Goldberg[52]的研究思路是,在模型训练阶段,先将目标语言句子通过句法分析器转换为其句法树线性化序列,一个既包含该句子所有单词,也包含句法结构成分标签的序列,然后将这一序列代替目标语句子与源语言进行模型训练。在翻译过程中,能够同时生成目标语言和目标语言的树结构,利用目标语言树结构的约束和限制,最终可以得到更为准确的目标语翻译结果。在WMT16 德英新闻翻译任务数据集上的结果显示该方法能够提升0.94 个BLEU 值。Eriguchi 等人、Wu等人、Le等人的工作集中在如何在解码端利用依存文法来提升模型的翻译质量[53-55]。Eriguchi等人[53]的思路是用RNNG(recurrent neural network grammars)作为神经机器翻译模型的解码器;Wu 等人[54]的方法是利用两个RNN 网络先后用以依存句法结构的生成和词语生成;Le 等人[55]的想法是将目标语言通过斯坦福依存文法分析器剖析成的句法树序列化后代替目标语言的句子进行模型训练。以上这些方法都被证明句法结构信息有助于提升机器翻译的质量。
上述研究尽管能够证明句法信息结构确实对改进神经机器翻译的结果有所帮助,但是目前这些研究仍然面临几个方面的问题:(1)树形结构的句法与序列结构的神经机器翻译模型相融合,势必增加神经网络的复杂度,从而导致模型训练难度加大,速度下降,同时也在一定程度上影响了翻译模型结构清晰简洁的特性。(2)研究采用数据规模偏小,模型训练集通常在几万到几十万不等,无法与其他神经机器翻译动辄上千万的数据模型相提并论。众所周知,翻译性能随着数据量的提升而改善恰恰是神经机器翻译这一方法的一大优势。(3)在解码器端现有研究对于句法结构信息的利用效率很低,通常只是用来线性化目标语言结构,其中蕴含的句法结构知识没有被用来指导生成目标语的句子。未来融合句法结构信息的神经机器翻译发展方向有:(1)在编解码两端同时利用句法结构知识,改变目前仅在源语言或者目标语言一端融合句法结构信息的现状。(2)句法结构信息与新的神经机器翻译模型相融合,将句法结构知识由循环神经网络拓展到卷积神经网络和Transformer 模型。(3)句法结构信息的规模、精度对于模型翻译结果影响的实证性研究。(4)借助于迁移学习等方法手段,将已有的宝贵的句法结构信息数据资源用于更多的稀缺性语言之中,以提高稀缺语言机器翻译的质量与效能。
4 问题与展望
从上文所述的研究中不难看出,融合语言学知识后的神经机器翻译模型的确能够提升翻译性能。但是,也不得不承认,目前的研究还存在以下几个问题:(1)融合语言学知识后,或多或少地增加了神经机器翻译模型的复杂度,使得模型训练需要消耗更多的资源,耗费更久的时间。(2)在通过线性化的方法加入语言学知识时,不论是在编码阶段还是在解码阶段都会使得序列变得更长,从而进一步加剧了长句处理的困难程度。这就形成了一个“怪圈”(一般而言,句子越长成分越复杂,越需要句法信息的辅助,而一旦增加了句法信息,句子序列变长,又会导致模型翻译性能下降。)。(3)融合语言学信息的神经机器翻译模型研究受到语言学理论研究和相应工具开发的限制。在模型中引入哪种类型的语言学知识,这种知识来自于何种语言学或计算语言学理论,有没有开发出高质量的标注工具,这些问题都将与最终研究结果息息相关。以句法分析为例,目前各种类型的句法自动分析工具都会产生或多或少的标注错误,这就在一定程度上限制了数据使用的规模与质量。此外,还需注意的是,文中提到的绝大部分方法都属于验证性的,其所做的实验,也仅仅用于证明其方法在某一数据集或者某一领域内有效,距离真正的实用还有相当一段距离。因此,今后融合语言学知识的神经机器翻译研究将着眼但不限于以下方面:(1)随着深度学习方法不断更新,神经机器翻译技术也在与时俱进,新的模型架构不断出现,也在不断刷新着机器翻译的最高水平。但不论如何发展,其本质都是在对人类语言进行建模,在这一过程中,无论是形态学、句法学知识,还是语义学、语用学知识都将会有用武之地。语言学知识与新模型、新框架、新技术融合的脚步不会停止。(2)目前神经机器翻译在大语种、通用领域的翻译结果无论从准确性还是从易读性来说都已经达到了一个较高的水平。如果要继续提升,就恐怕涉及语用等层面的问题了。因此,在语言学知识与神经机器翻译深度融合这一进程中,将不仅仅用到形态学、句法学这些表层的语言学知识,而且会用到语义学、语用学这些层次更深、更为抽象的知识。如何利用这些知识来改进神经机器翻译模型,提升翻译效果,是今后一段时间研究中应该关注的问题。(3)由于神经机器翻译对于大数据的依赖,往往在低资源语言翻译方面表现不佳。在数据资源有限的情况下,融合外部知识的方式是提升翻译模型性能的一个重要方法。人类的各个语言之间,往往具备千丝万缕的联系,这就恰好为语言学知识的迁移提供了桥梁。因此,利用高资源语言与低资源语言间存在的联系,将诸如字词结构信息、短语结构信息、句法学结构信息移植到低资源语言上,提升其翻译质量,也是今后的一个重要研究课题。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
电脑报(2021年41期)2021-11-04
初中生学习指导·中考版(2020年5期)2020-09-10
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
农机使用与维修(2014年10期)2014-10-23
