
人脸识别系统的活体检测综述
2021-07-22 17:02马玉琨徐姚文王泽瑞
计算机与生活 2021年7期
马玉琨,徐姚文,赵 欣,徐 涛,王泽瑞
1.河南科技学院 人工智能学院,河南 新乡 453003
2.北京工业大学 信息学部,北京 100124
3.河南科技学院 信息工程学院,河南 新乡 453003
近年来,人脸由于其唯一性和稳定性,被广泛用于在线身份认证,而人脸识别技术的发展[1-2]也促使了人脸身份认证系统在越来越多场合下的应用[3-4]。然而在线的人脸身份认证系统极易受到各种蓄意的攻击[5],即外部攻击和内部攻击[6]。外部攻击也称作呈现攻击[7],指的是对采集传感器的假体人脸攻击[8-10],将合法用户的人脸生物特征伪造物呈现给传感器[11-13],如图1 所示,其目的是干扰生物识别系统的获取操作[7]。内部攻击指的是攻击者侵入人脸识别系统内部,替换或篡改系统中各种关键模块或数据。

Fig.1 Several types of face presentation attack图1 常见的几种人脸假体攻击类型
相对于内部攻击,外部攻击即假体攻击更加容易实施,是因为一是很容易生成合法用户人脸伪造物并呈现给传感器。实际上,这种呈现攻击的生物特征样本极其容易被获取,并且对人脸识别系统产生了极大的威胁。随着社交网络的发展,人脸已经不再是私密特征,人们都乐意将自己的人脸图像或者视频放在社交网络中,比如微信朋友圈、微博、脸书等。攻击者可以零努力地、低成本地获取并复制这些人脸样本,并且攻击者也很容易将这种生物特征呈现给系统传感器。二是不需要了解人脸识别系统中算法的任何细节,仅仅需要使用更真实的呈现媒介来呈现人脸样本。因此,人脸识别系统的主要威胁来源于呈现攻击。
针对假体攻击为人脸识别系统带来的安全问题,人脸活体检测技术应运而生[9]。人脸活体检测技术旨在判断系统采集的人脸数据是否为真实的人脸,以防止伪造的假体人脸攻击[14],如图2 所示。完善的人脸活体检测技术是人脸身份认证系统进一步普及应用的前提条件,可广泛应用于大型集会、特殊组织和场合,包括刷脸支付、人脸解锁、公共安防以及各种在线人脸识别系统等,具有重大的社会意义。

Fig.2 Face presentation attack detection图2 人脸活体检测示意图
近年来,假体人脸的攻击逐渐成为人脸认证系统得以应用的瓶颈,也是研究者们关注的重点和热点,国际上也举办了多次关于人脸活体检测的竞赛[15-16]。在过去的几十年中,国内外大批顶尖的研究机构和学者对此开展了研究,该领域的科研成果也频繁出现在国际权威的学术期刊与会议上,有大量文献对人脸识别系统中数据捕获子系统和活体检测方法进行了深入分析和研究。文献[17]对可见光谱下的人脸活体检测方法进行了综述;文献[18]全面综述了2014 年前关于人脸识别中反欺骗的先进性方法以及数据库,同时还介绍了生物识别反欺骗通用性方法。文献[6]对人脸呈现攻击类型与活体检测的国际标准给出详细解释,并且对2017 年前的人脸活体检测方法、数据库以及竞赛进行了综述。
2017 年以来,多个新的人脸呈现攻击数据库被公布,且涌现了许多新颖的检测方法,因此有必要对最新的发展进行总结与分析。本文在概述人脸活体检测早期的研究工作基础上,系统地介绍了最近几年的研究进展,并对数据库的发展进行了总结,补充了对评价方法的综述,对活体检测的未来发展趋势进行了展望。
1 人脸活体检测方法
主流人脸活体检测方法根据是否利用辅助信息可以分为利用辅助信息的方法和不利用辅助信息的方法。
辅助信息指除可见光下的人脸图像信息外的其他可以用来检测呈现攻击的信息,其中包括基于用户配合的方法和利用其他模态信息的方法。利用用户配合信息的方法需要用户做出随机给出的指令,如头部转动[19],或让用户读出指定数字[20],眨眼等。基于用户配合的方法其用户体验较差,且等待时间较长,效率低下。另一方面,随着虚拟视频生成技术的发展与深入,很容易由一张静态图片生成虚拟的动作视频[21-22],攻破基于用户配合的活体检测算法。利用其他模态辅助信息的方法采用光场相机[23-24]、双目相机[25]、近红外相机[26-27]、结构光等[28]设备采集可见光人脸信息不具备的有用信息,比如深度信息[29]。该类方法准确度较高,但另一方面提高了产品的成本,限制了其应用场景和推广进度。
考虑到基于辅助信息方法的局限性,本文重点分析无需辅助信息的方法。该类方法仅仅根据可见光下人脸图像进行活体检测,该类方法的研究进展分为两个阶段,深度学习发展之前大多采用传统手工定义的特征进行检测,深度学习普及之后涌现了很多基于深度特征的检测方法。本文分别对这两类方法进行分析讨论。
1.1 基于手工特征的人脸活体检测算法
基于手工特征的人脸活体检测算法又可进一步分为基于静态特征的方法和基于动态特征的方法。
基于静态特征的活体检测方法探索真假人脸的颜色、纹理等差别。区别于真实人脸,照片或者视频攻击需要二次成像及额外的展示过程,会丢失图像的细节纹理信息,可使用纹理特征与局部形状特征进行检测[30-31]。该区别反映到频域上为高频信息的损失,同时会引入额外的噪声[32],如图3 所示。该方法具有一定的局限性,随着成像和打印技术的逐渐成熟,照片人脸和真实人脸在细节部分的差异越来越小,因此频域差异也越来越小。

Fig.3 Difference between genuine face and photo face in frequency domain图3 真实人脸和照片人脸在频域的区别
此外,2015 年Garcia 和Patel 等人分别提出利用二次成像的摩尔纹(Moire patterns)信息检测基于电子屏幕的照片或视频假体人脸攻击[33-34]。由于电子屏幕基于固定重复模式的纹理元素合成各种颜色,因此二次成像含有摩尔纹特征,如图4 所示。基于此特点,利用摩尔纹可以检测恶意的屏幕展示攻击。然而设备开发者也在尽力避免摩尔纹的产生,例如适马的X3 和腐蚀的X-Trans 传感器等。因此基于摩尔纹的方法也有一定的局限性。

Fig.4 Several examples of Moire图4 摩尔纹的几个例子
基于动态特征的方法主要利用人脸的运动信息进行活体检测,可利用的运动信息包括人类固有的动作和生理行为。如Pan 等人对眨眼行为进行建模,判断是否为活体人脸[35];Kollreider等人利用光流法[36]模拟人脸表情微动作信息[37],以此检测照片攻击;Li等人[11]通过检测液晶显示屏的抖动进行重放攻击检测。基于动态特征的方法只检测某个特定的动作,或者相邻两帧的差别,但对于具有真实人脸动作信息的视频攻击较难检测。
1.2 基于深度学习的人脸活体检测
随着深度学习技术的发展,许多研究者尝试将深度学习技术用于人脸活体检测问题,并取得了较好的性能,如直接应用AlexNet做活体检测二分类[38],将迁移学习应用于活体检测分类网络解决数据量不足的问题[39],对人脸图像进行预处理改进网络输入的方法[40-41]。
基于深度学习的方法利用数据驱动的训练方式,能够较好学习大量训练数据中包含的模式信息,在性能上相比于传统方法有了显著提升,但深度特征的含义难以解释,提取过程难以控制,不易关注到真伪脸差异的本质,阻碍了基于深度特征的方法性能进一步提升,也容易过拟合到数据集中与活体信息无关的设备、光照信息等。在实验验证中表现为较好的库内测试准确率,但跨库测试准确率非常低,即算法泛化性较差。如利用MSU-MFSD 和Idiap Replay Attack 数据集进行训练,在第三个数据集CASIA 上测试的半错误率为41.02%[42],这对于二分类任务几乎不可用,说明在真实场景中的泛化性仍然是较大的挑战[43-44]。近期针对活体检测的研究进展集中在算法的泛化性上,本文将这些方法分为如图5 所示五类。
1.2.1 基于辅助监督信号的方法
基于辅助监督信号的方法认为已有方法把活体检测看作二分类问题,直接让分类模型学习的方法学习到的特征泛化性和区分度不够,因此引入如人脸深度图、远程光电体积描记术(remote photoplethysmography,rPPG)信息、假体介质轮廓等辅助监督信号指导特征的提取,提高特征的可解释性。
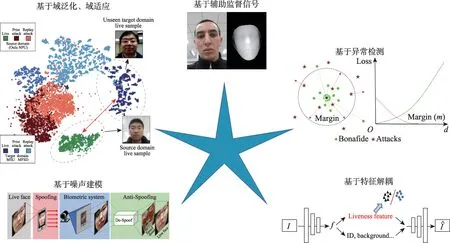
Fig.5 Deep learning-based face presentation attack detection analysis图5 基于深度学习的活体检测分析
Atoum 等人认为视频攻击和照片攻击的立体分布和真实人脸具有较大差异,因此将人脸深度图作为活体与非活体的差异特征[45],设计基于分块人脸和人脸深度图的活体检测框架。
rPPG[46-47]在2016年被首次用于活体检测。为了使该微弱变化具有更明显的可视性,Lakshminarayana等人提出利用时空映射的方法[48],将时域内的肤色周期性变化映射到单张图像,如图6 所示,增强了该变化的可视性。rPPG 对于面具攻击和纸张攻击效果很好,但是对于视频翻拍攻击效果一般,因录制的视频人脸上也带有被弱化的rPPG 信息,故不好区分。

Fig.6 Spatio-temporal mapping results in different situations图6 不同情况下的时空映射结果
在以上对rPPG 研究的基础上,2018 年,Liu 等人[49]首次将活体检测看作特征监督问题,设计深度框架预测出脉跳和深度图信息,进而进行活体检测分类。该方法的性能首次超越传统手工提取特征的方法。Liu 等人利用rPPG 信号对3D 面具攻击进行了检测[50]。
除深度图和rPPG 等信息外,每种攻击类型的假体都有其特有的轮廓,如面具攻击的假体轮廓为人脸轮廓,而重放攻击的轮廓为电子屏的矩形轮廓,该假体介质轮廓加以利用作为辅助监督信号,因此Zhu等人将活体检测的分类任务转化为假体介质轮廓(spoofing medium contours,SMCs)的检测问题[51]。该方法要求拍摄范围能够覆盖所有假体,当拍摄距离较小时具有一定局限性。
基于辅助信号监督的方法虽然通过约束所提特征的含义范围来增强其可解释性,但这一约束也导致网络忽略了其他可能的鉴别线索。如何在保留其他线索的前提下加入辅助信号可作为该类方法的进一步研究方向。
1.2.2 基于域适应、域泛化的方法
伪脸不仅存在由攻击类型不同导致的类间差异,还存在同种攻击类型内的类内差异,如采集设备差异、呈现设备差异、打印媒介的材质差异、背景光照差异等。针对伪脸类间、类内差异较大的问题,采用域适应、域泛化技术,提高人脸活体检测算法在跨域情景下的性能。
该类方法使用域的概念表示活体检测问题中的不同攻击类型、场景、数据库等。针对活体检测方法在不同攻击类型之间的泛化性问题,Shao 等人提出了多对抗性域泛化机制[52],用统一的提取器提取各域图片的特征,针对每个域均训练一个单独的鉴别器,通过生成对抗的训练形式,学习多个库之间共存的具有区分度的广义特征空间特征,增强算法在未知数据库上的泛化性。传统的三重挖掘约束只在各自域内进行,但域泛化方法依赖多个域间的交互,因此提出双向的三重挖掘约束,不仅关注单个域内的正负样本,也在域间进行约束,即不同域间的样本对距离也要小于域间的样本对距离。基于域适应的方法通过使鉴别器无法判断生成器所提特征的域来源,迫使生成器提取的特征去域化。域泛化的方法无需目标域的样本,但通常需要多个源域,实际上是丰富了样本的多样性。
而域适应的方法通过少量目标域的样本调整源域训练的特征提取器,使特征更接近目标域的特征分布[53-55]。Jia 等人认为活体检测的最终目的是选出真实人脸,因此只需提取真实样本的去域化特征即可,不必要也不易于将多个域的伪脸样本特征约束至紧凑空间[53],提出利用非对称三重挖掘的概念不仅要求真实人脸与伪脸分离,同时要求所有域的真实人脸彼此聚集,不同域的伪脸彼此分离。Wang 等人用源域、目标域的编码器分别提取各自域图片的特征,通过生成对抗的训练形式,使鉴别器无法判断所提特征的域来源,迫使两个编码器提取的特征分布更接近。再使用共享参数的解码器进一步拉近两者的分布并嵌入到真伪辨别空间,从而将在源域学习的分布信息迁移至目标域[56]。域适应的方法本质上属于迁移式学习,训练时需要目标域的少量样本,泛化性也因此受限。
1.2.3 基于特征解耦的方法
基于特征解耦的方法将真伪判别信息与用户身份、背景环境等真伪无关信息相分离,解耦出更有辨别力的活体检测特征[42,56]。Wang 等人认为已有方法对未见场景不泛化是因为特征过拟合了人的身份信息,拥有相似外貌的用户样本会更倾向于聚在一起,从而增加了以真伪为标准的聚类难度,影响活体检测性能。当测试样本与训练样本来自不同域的时候该问题更为严重。因此,为避免因身份信息过拟合而导致的模型泛化能力下降,提出将特征中的身份信息和活体信息解耦[42],使用解耦后的活体信息单独进行活体检测,其具体方法为在两个域内分别预训练真伪分类特征提取器和身份特征提取器,交换两个域的真伪分类特征提取器,利用重构图片验证身份信息,利用分类器验证真伪分类信息,通过交换分类特征提取器后重构验证的方式,迫使提取器提取的特征更具有泛化性。
Zhang等人认为,除了身份信息以外,特征还包含了如环境、设备等内容,因此将人脸提取的特征空间划分为活体空间和内容空间,从高维特征空间获取活体信息[57],通过交换真伪分类特征后重构验证的方式,迫使真伪分类特征与身份、背景等特征更无关。值得一提的是,该工作用LBP(local binary pattern)、深度图作为辅助信息约束真伪分类特征,使其更具有真伪辨别力。该类方法解耦后的几部分应具有独立、完备且互补的特性,而目前已有解耦方法较难在理论上证明满足该特性。且对活体特征造成干扰的因素多种多样,如身份信息、光照、设备、运动等。如何设计合理的解耦方法使得所提活体特征从各种干扰中分离,是该方向的难点。
1.2.4 基于噪声建模的方法
伪脸是攻击者使用合法用户的真实人脸图像,基于一定的伪造媒介(打印设备、视频播放设备、3D面具等)制作的伪造物,因此伪造过程不可避免地会引入一些与媒介强相关的噪声。基于噪声建模的方法受启发于去噪和去抖动的思想,认为成像噪声包括颜色失真、显示降质、呈现环境噪声、采集设备噪声等,将活体人脸图看作原图x′,而非活体人脸图看作活体人脸图加了噪声的结果,用x表示,即x=x′+N(x′)。自编码器提取输入图片的噪声图N(真实人脸图片的噪声图为0),通过x′=x-N得到合成的真实人脸图片,利用VQ(visual quality)网络判断输入图片是否为虚拟合成,DQ(discriminative quality)网络判断输入图片是否为真实人脸。噪声建模的概念将活体检测任务转化为估计噪声的任务,然后利用噪声模式特征进行分类决策,通过对噪声建模研究伪造媒介的影响[58-59],进而对人脸进行去攻击操作。噪声模式隐藏在网络中,无法直观体现各攻击类型与真实人脸间差异的本质,尤其是在成像过程中引入的噪声和假体人脸攻击伴随的噪声难以彻底区分。
1.2.5 基于异常检测的方法
基于异常检测的方法将活体检测问题看作真实人脸的异常检测,利用手工特征将真实人脸建模为标准生成模型,测试过程中将模型之外的分布看作假体攻击。Nikisins 和Pérez-Cabo 等人提出在训练阶段只学习真实人脸的特征[60-61],测试阶段判断所见人脸是否符合该特性,一方面避免了数据收集阶段的繁琐,另一方面对未见攻击类型具有一定泛化性。2019 年,Liu 等人提出,人脸假体欺骗的类型多种多样,且将来会层出不穷,因此针对未知攻击类型的检测即零次学习(zero-shot learning)应作为未来研究趋势[62]。Baweja 等人针对以往异常检测的方法需要分阶段学习的问题,提出在CNN(convolutional neural network)训练过程中引入伪负类,考虑到假体攻击人脸和真实人脸的相似性,在真实人脸的特征分布上生成伪负类特征,辅助训练特征的提取和分类,实现异常检测的端到端学习[63]。伪负类特征辅助的方法需要在理论上解决两个问题,一是伪负类特征如何避免与正类特征重叠,二是如何证明伪负类特征具有负类信息。针对这两个问题,目前尚未有解决方法。
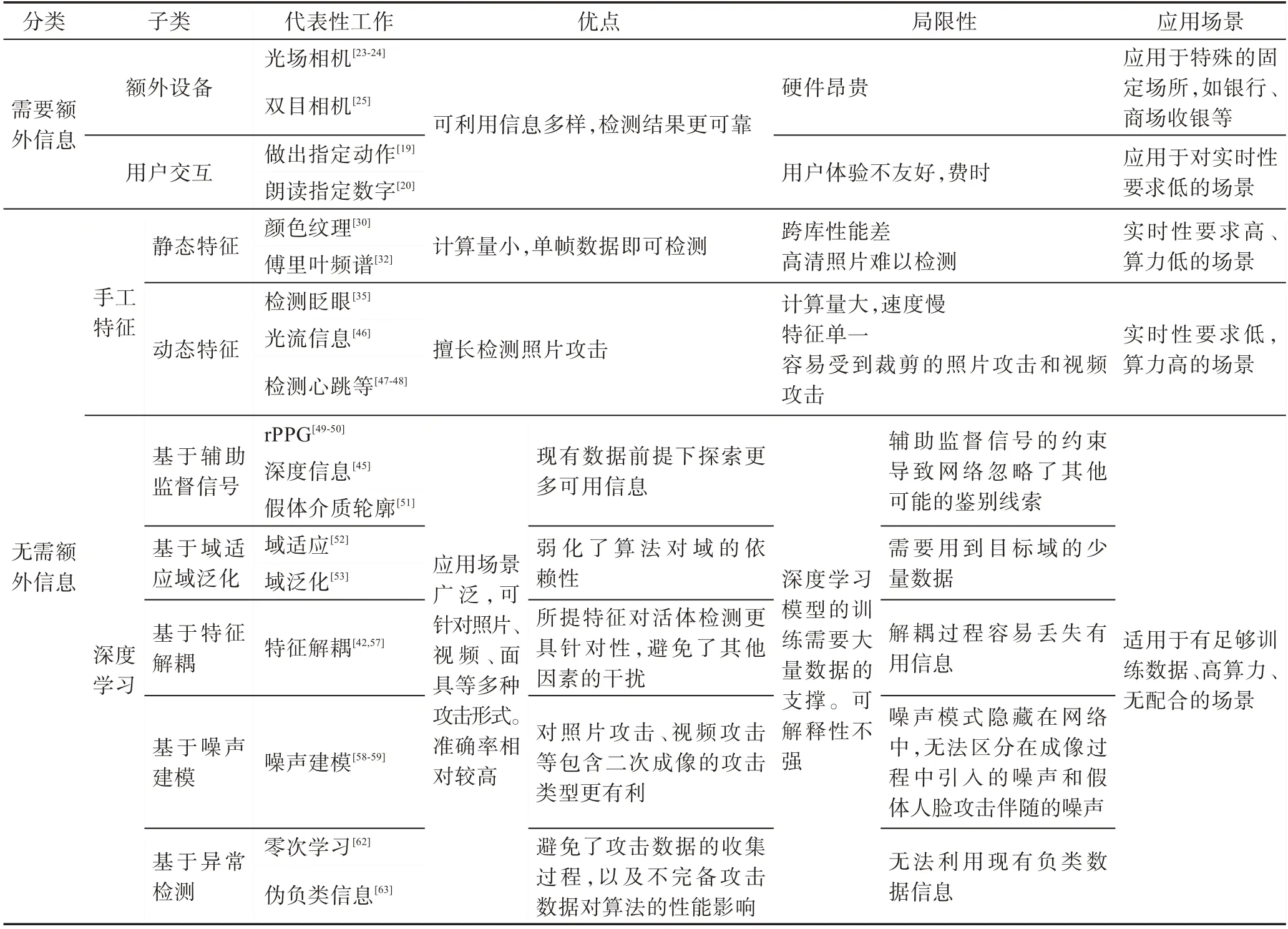
Table 1 Comparison of different face presentation attack detection methods表1 不同人脸活体检测方法比较
以上介绍了不同的活体检测方法。表1 分析了各类方法的优点、缺点、应用场景等。实际应用中经常将多种方法相结合用于提高算法准确性。
2 活体检测的评价
2.1 数据库
随着活体检测技术的进步,以及对评价方法要求的不断提高,目前已有多个数据集公开并用于方法测评,由于数量较多无法在本文中一一列出。而2017 年之前已有对活体检测方法的综述文章,其中包括对数据集的介绍,因此本文重点介绍2017 年之后最新发布的数据集,包括SiW-M、CASIA-SURF、ROSE-YOUTU 等。这些数据集在数量和多样性上都有了较大的提升,并在最新的文章中被广泛应用[6]。
SiW-M 数据集收集了493 个人的真实和假体视频,共660 个真实视频,968 个假体视频,且包含13 种攻击方式[60],如照片攻击、视频攻击、3D 面具攻击、化妆攻击、部分遮挡攻击等。相比已有数据集,SiW-M增加了攻击类型的多样性。
CASIA-SURF 数据集[29]于2019 年完成,包含21 000 个视频中的1 000 名中国人,覆盖不同的性别、年龄、是否戴眼镜/无眼镜等特性,以及6 个不同攻击方式。照片裁剪方式裁剪下照片中人脸的不同区域。该数据库使用Intel Real Sense SR300 相机同时捕捉RGB、深度和红外(IR)视频,使用A4 纸打印彩色图片。在照片拍摄过程中,测试者需要做一些动作,例如向左或向右转,向上或向下移动,走进或远离相机。此外,测试者的面部角度要求小于30°,测试者站在距离相机0.3~1.0 m 的范围内。Real Sense SR300 摄像机记录多模态视频流,最后进行融合得到除去背景以外的面部区域。而该数据集的升级版CASIA-SURF CeFA 已于2020 年发布[64],增加了跨种族的志愿者身份,以测试算法在种族间的泛化性。
ROSE-YOUTU 数据集由YouTu 收集[65]。它涉及20 个参与者,每个参与者有25 个真实的和150~200个假脸视频。收集的数据多种多样,覆盖了5 种不同的光照条件。并使用5 台移动设备(神州手机、华为手机、中兴手机、iPad、iPhone 5s)采集数据。此外,在ROSE-YOUTU 数据库中,除了打印的照片(静止、颤抖)和视频(联想LCD 屏和Mac 屏显示)之外,还包括各种纸面面具攻击示例。这种攻击可能包含3D 信息,这在已有的数据集是未出现过的。
随着越来越多,越来越庞大的数据集被发布,其发展趋势体现在攻击手段、展示设备、摄录设备越来越多样,而假体数据采集的代价越来越高,且假体的数据量远远无法与真实数据达到平衡,因此2019 年Yang 等人提出利用虚拟合成的方法获得负样本数据[66],弥补负样本不完备或难以获取的问题,在一定程度上缓解了对数据收集的强烈需求。
2.2 评价指标
人脸活体检测算法的性能评价指标同时考虑活体人脸与假体人脸的识别率。常用的性能评价指标主要有两套:
一是错误接受率(false acceptance rate,FAR)、错误拒绝率(false rejection rate,FRR)、等错误率(equal error rate,EER)以及半错误率(half total error rate,HTER)。错误接受率(FAR)指算法把假体人脸判断成活体人脸的比率,FAR=假体人脸判断为活体人脸的次数/假体人脸攻击总次数。错误拒绝率(FRR)指算法把活体人脸判断成假体人脸的比率,FRR=活体人脸判断为假体人脸的次数/活体人脸请求总次数。FRR 与FAR 的均值即为半错误率HTER。当FRR=FAR 时,即为等错误率EER。
第二套评价指标是攻击分类错误率(attack presentation classification error rate,APCER)、善意提示错误率(bona fide presentation classification error rate,BPCER)以及平均错误率(average classification error rate,ACER)指标[7]。攻击分类错误率(APCER)指针对某一具体攻击类型的假体人脸分类错误率,善意提示错误率(BPCER)指活体人脸分类错误率。APCER 与BPCER 同第一套评价指标中的FAR 与FRR 类似,但是FAR 和FRR 把所有类别的假体人脸混合在一起计算性能,APCER 是为每一种类别的假体人脸分别计算,比如照片类假体、视频类假体、3D面具类假体,最后活体检测算法总的APCER 是所有类别假体中识别率最差的结果。
2.3 测试方法
目前对人脸活体检测方法的测试分为三类,分别是库内测试、跨库测试和实际应用场景测试。
库内测试指算法的训练和测试来自同一个数据集中的不同数据。库内测试在一定程度上反映了算法的有效性。但由于单数据集中的攻击方式、设备以及场景较为单一,因此无法反映算法在多样化真实场景下的性能。在无人为干预下,数据驱动的算法很容易学到数据集所独有的特性,如人脸尺寸、相机特性等,而非真假人脸的差异。因此一旦这些条件发生变化,算法有效性将大大降低。
为解决库内测试的局限性,近期的活体检测方法在原有库内测试的基础上,加入了跨库测试性能的比较。训练阶段使用已有的一个或几个数据集训练,测试时针对另外的数据集进行测试。跨库测试是目前研究最为广泛的测试方法。
除库内和跨库测试外,一部分研究者认为在数据集上的表现无法体现实际场景中的性能,因此将算法的评测放在实际人脸应用系统中,这也最大程度上符合人脸活体检测的应用目标。
3 难点与挑战
随着研究的不断深入,人脸活体检测算法的性能不断突破新高,但仍面临着很多难点与挑战。
(1)不断出现的新的攻击方式。“道高一尺魔高一丈”,相对于主动的假体攻击研究,活体检测为针对具体假体攻击形式的被动研究。而新的攻击方式不断涌现,对活体检测提出新的挑战,如为了躲避眨眼检测和动态信息检测,出现了弯曲照片攻击和裁剪照片攻击等形式,虚拟动作合成的视频攻击也应运而生[67],如图7 所示,对基于用户配合的检测方法提出了挑战。

Fig.7 New presentation attacks图7 新的假体攻击方式
(2)类间距离小,类内距离大。不同于普通的分类问题,人脸活体检测的真假两类具有较大的相似性,相当一部分视频即使人眼也很难分辨真伪。而对于较小的类间距离,由不同身份的人脸差异带来的类内距离较大。如何应对小类间距离和大类内距离,是人脸活体检测的难点之一。
(3)受成像以及展示设备的影响较大。实际应用中真实人脸和假体攻击的成像结果区别受成像及展示设备影响较大,当设备更换时,特征也会有较大差异,学术研究中该问题体现在跨库测试性能较低。
针对以上难点与挑战,未来工作可以在以下几个方面开展:大型人脸活体检测数据集的创建进一步推动相关研究;提高人脸活体检测算法的实时性,提高检测效率;在实际应用中结合一些额外的设备,针对性地提出解决方法,以提高其实用性。
4 结束语
随着互联网应用的飞速发展,基于人脸特征的认证技术具有广阔的应用前景,如脸部识别技术引爆刷脸时代。如何找到一种模式,既可以利用人脸信息进行身份认证,又能保证用户和系统的安全性,将是近期亟待解决的问题。本文对近年来人脸活体检测的主要算法进行了综述,并对人脸活体检测研究存在的问题进行了分析,也对进一步研究方向进行了展望。可以看出,已有的人脸活体检测方案离实际应用还有一定距离,需要进一步深入细致的研究。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
文萃报·周五版(2021年4期)2021-09-13
奥秘(2021年5期)2021-06-15
华人时刊(2020年21期)2021-01-14
设计(2020年24期)2020-01-25
课外生活(小学1-3年级)(2018年2期)2018-02-10
医学美学美容(2016年8期)2016-10-18
米娜·女性大世界(2016年8期)2016-08-17
奇闻怪事(2014年5期)2014-05-13
中国美容医学(2004年1期)2004-08-11
