
基于余弦相似度的货品属性关联度研究
2021-07-21 13:00:40孙秋天王玄平崔宏兵
起重运输机械 2021年13期
孙秋天 张 凯 王玄平 崔宏兵
北京起重运输机械设计研究院有限公司 北京 100007
0 引言
仓库管理是制造业达到供需平衡的必要一环,其中智能立体仓库以其高度自动化、高效货品流转效率可帮助企业实现货品的量化管理,从而受到医药、家具、纺织、电气等行业的青睐与推崇。智能立体仓库整合、优化了物流所需的各种资源,提高了物流行业的自动化和智能化水平,为物流行业的模式和流程带来新的变革和创新[1]。随着市场规模的不断扩大与发展,仓库中货品种类的不断增多,货品入出库体量的逐步增长,故高效而有序实现仓库货品的系统化、规范化、自动化管理是一个亟待解决的问题。高效二字也成为智能仓库研究方向的重点,合理有效地提高物流运作效率对节约企业运行成本以及提高仓库运转流畅性具有重要意义。
在仓库物流运作中,货物拣选是必不可少的一环。有研究表明,货物拣选的作业成本大约占整个仓储中心运行成本的 50%~75%,作业时间大约占整个仓储中心所有作业时间的60%,是整个仓储中心劳动最密集、运作成本最高的一环,成为牵制仓储中心整体运营效率的瓶颈环节[2]。因此,提高拣选出库效率将有助于提升仓库物流运作效率、提高自动化立体仓库的效能。
1 研究现状
在仓库管理中,货物拣选在智能仓库中扮演重要角色并起到重要作用,提高订单的拣选效率,一方面可通过购买先进的设备提高运行速度与效率,但这样也会大幅增加企业运行成本;另一方面可改进拣选策略,在单位时间内拣选更多的货品,此优化可在不增加企业运行成本的前提下提高拣选效率。因此,提高订单分拣系统的效率成为学术界和产业界关注的焦点之一[2]。
由相关文献可知,仓库拣选可分为两种模式:人到货拣选模式和货到人拣选模式,针对人到货拣选模式优化,张宇[3]提出基于时间窗约束多种群遗传拣选路径优化算法,建立以拣选路径长度最短为目标的多人作业拣选路径优化模型;王璐璐[4]采用订单分批下的路径优化拣选策略建立拣选模型,找到一条可以拣选出所有货物的最优路径;杨学春等[5]将拣货路径简化成 TSP 问题,引入C-W 节约算法改进传统拣货路径,提高了拣选效率;闫军等[6]基于遗传算法对订单进行排序,使拣货员获得较优的拣货路径;袁瑞萍等[7]建立了基于最小化货架搬运次数以及最小化机器人总拣选路程的数学模型,并设计两阶段启发式算法求解,仿真实验表明该方法有效提高拣选效率。李悦[8]基于禁忌搜索算法提出一种在不同场景下,货位分配与拣货路径协同优化的方法,使仓库更好地适应市场实时变化,提高分拣人员的工作效率。针对货到人的拣选模式优化,霍达等[9]介绍了一种食品行业中货到人系统的应用,根据业务流程和客户需求,提出了系统的难点和特点所在,设计详细、系统地解决方案;李珍萍等[10]建立了以拣选订单过程中搬运货架总时间最短为目标的整数非线性规划模型,设计了求解模型的贪婪算法和单亲进化遗传算法;Li等[11]以搬运货架总时间极小化为目标建立了混合整数规划模型,并设计了求解模型的启发式算法;Yuan等[12]在一种物品只能存放到一个分区的假设下,设计了按照物品出库速率确定物品储位分区的入库策略,提高了拣选效率。
综上所述,大多数针对拣选策略的优化会选择对拣选路径进行优化,部分会考虑货品的入库储位、搬运载体的搬运次数以及搬运总时间,但这些研究都忽略了货品本身属性对拣选效率的影响。另外,相较于人到货模式,目前主流系统更倾向于货到人模式,以降低劳动强度与人工数量。一方面人员移动的速度会低于机器的移动速度,另一方面货到人模式的运输速度有更高的提升空间,所以目前的主流研究以货到人模式为基础,提出相应优化措施提高拣选效率。考虑到以往智能仓库一个单位货架上只存放一种货物,而随着货品种类的增多,货品混放在一个托盘载体的情形不断增多,货品的混放也成为智能仓库的关注点之一。因此,本文拟在货到人拣选模式下对同一拣选订单下不同货品的属性关联强度进行深入研究,根据货品的属性关联强度对入库混放提出建议,优化同一订单拣选频率与路径,以达到减少同一拣选订单下不同货品拣选时间的目的,从而提高拣选效率与准确率。
2 货品关联度计算
2.1 余弦相似度计算
众多周知,两个向量的夹角越小其相似度越高。余弦相似度正是基于这个思想,用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0°,也就是两个向量越相似,这就叫余弦相似性。
以二维空间为例,a和b是两个向量,如图1所示,用余弦定理计算夹角,则有
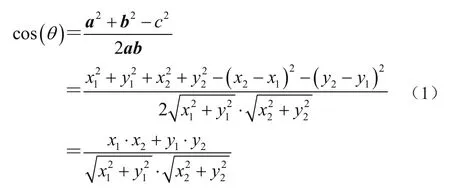
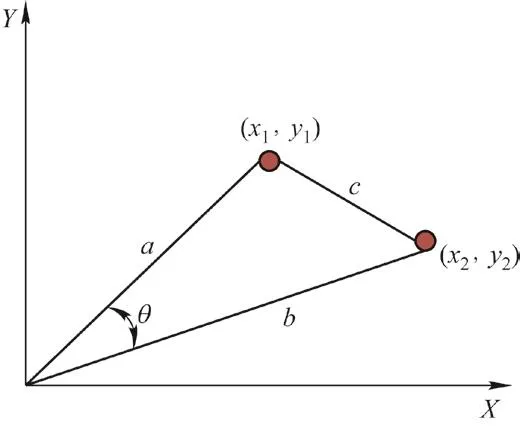
图1 二维向量余弦计算
余弦定理也可以应用于n维向量上,假设A和B是两个n维向量,如图2所示,A为[A1,A2,…,An],B为[B1,B2,…,Bn],则A与B夹角θ的余弦可表示为
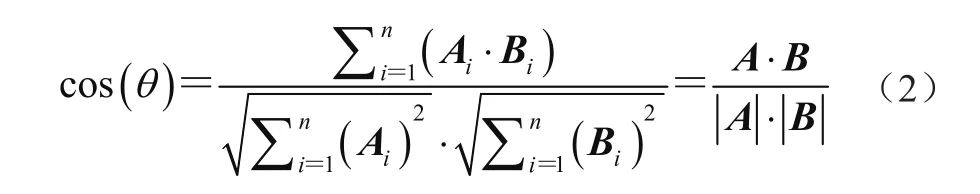
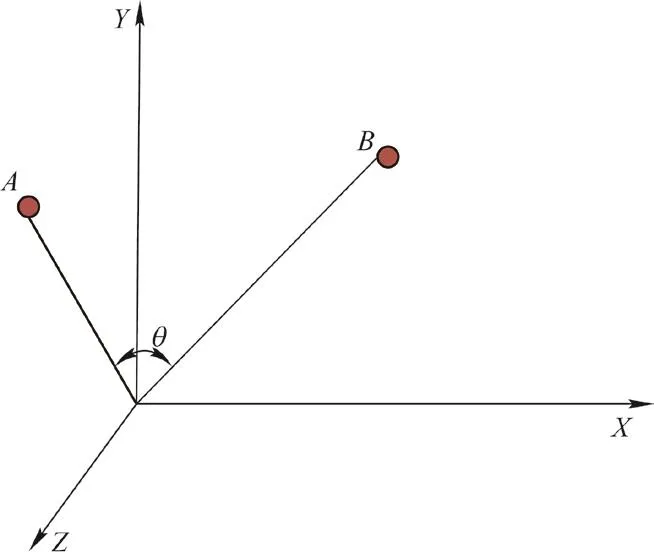
图2 n维向量余弦计算图例
余弦相似度计算源于向量余弦计算的思想,通过测量两个向量内积空间夹角的余弦值来度量它们之间的相似性,常用于机器学习中对文本的处理过程。计算两段文本的相似度首先需要将文本分词,清除标点符号以及停用词,对文本中涉及的词进行统一数字编码,根据编码将文本中的词频向量化,再用余弦定理计算两个向量的余弦值,即可得到两段文本的相似度。因此,可将余弦相似度计算的思想用于货品属性关联度的计算上。
2.2 货品属性关联度计算
货品属性包括物料规格、物料单位、物料逻辑储位、物料描述、物料类别等,这些属性皆以文本形式存在数据库中,故可借鉴余弦相似度的计算方法对货品的关联度进行计算。本文设计了一种基于余弦相似度的货品属性关联度计算方法。
首先,对货品的属性文本进行分词,分词结果记做集合C,去除标点符号及停用词后得到词典Dic1={w1,w2,…,wn},计算词典Dic1中的每个单词的TF-IDF值,作为单词的权重,TF-IDF值计算过程可表示为
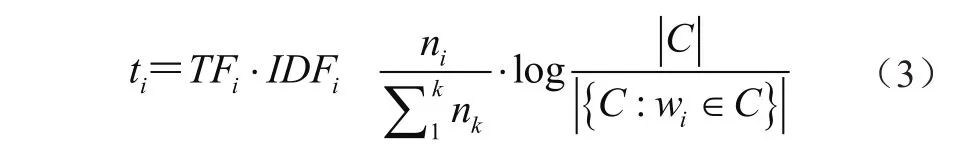
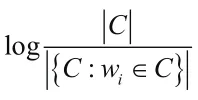
然后,将货品A的属性文本AttributeAtext与货品B的属性文本AttributeBtext作为向量空间模型(VSM),这两段语料的向量空间可表示为
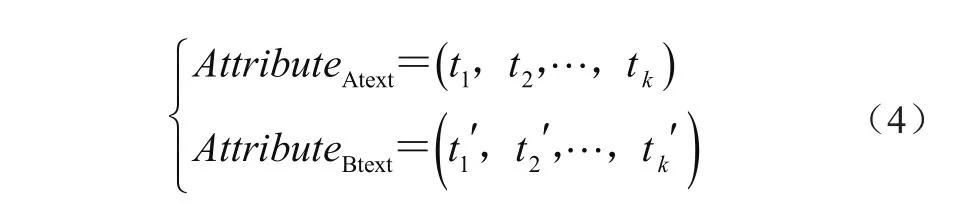
将货品A属性文本AttributeAtext与货品B属性文本AttributeBtext的向量空间模型余弦值作为货品关联度的度量值Similarity,Similarity值越大,货品关联度越大。由向量余弦值计算可得到2个货品的属性关联强度为
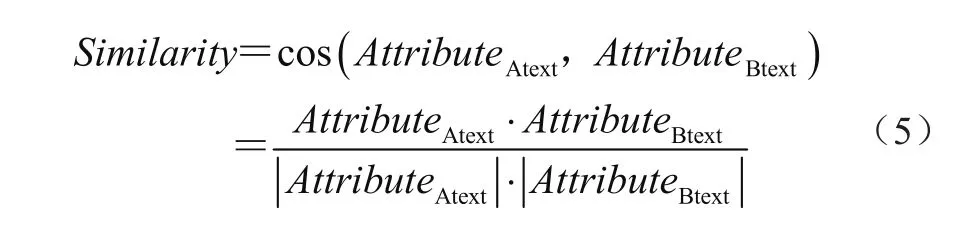
3 实验与结果
3.1 数据集与预处理
选取某企业的数据库作为实验数据集,数据集中出库单据log_Erp_Out表中包含15 459条出库单据,其中2 507条单据数据包含多个行号。为验证同一单据下不同货品的关联度,选取这2 507条数据作为实验数据集。在这些数据中,同一单据下最多有26行的出库数据,最少有2行出库数据。与此同时,需要结合货品信息log_Material表中货品的各种属性信息,计算货品的属性关联强度。
3.2 实验结果
通过设计相应算法,计算每个单据下所有货品的属性关联强度。对同一单据计算两两货品间的关联强度后求和取均值,作为某一单据下所有货品的属性关联强度。假如单据A下有n行出库记录,则需计算n(n-1)/2对关联强度,然后对n(n-1)/2对关联强度求和取均值,作为单据A下货品的关联强度。表1为部分实验结果。
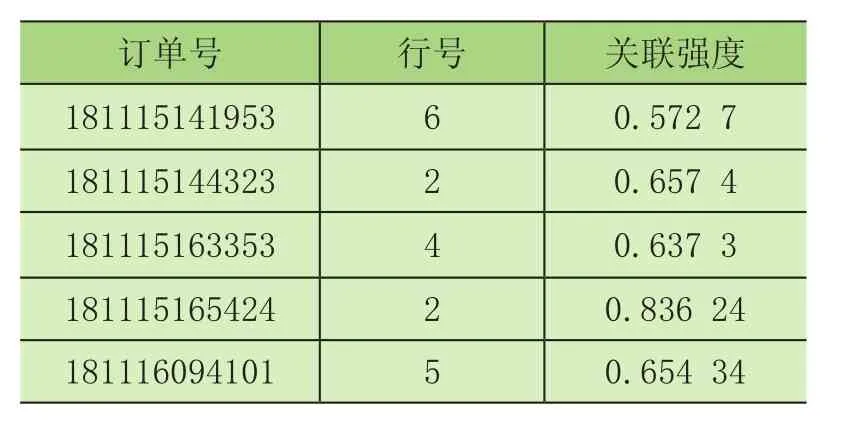
表1 不同单据的关联强度
在此,利用散点图显示值集之间的关系,2 507条单据数据中货品的属性关联强度分布如图3所示。

图3 不同单据的关联度散点图
由图3可知,大多数同一出库单据的货品属性关联度处于0.5~0.7之间,表明大部分同一出库单据下的货品具有较大关联强度。由于某些单据下不同行的货品为同一货品,虽出现的概率较少,少部分单据在仓库正常运转过程中出现关联强度为1的情况。另外,有少部分单据出现关联强度较低的情形,在实验数据集中有19.585%的出库单据中货品关联度低于0.5,在实验数据集中有7.020%的出库单据中货品关联度低于0.4,在实验数据集中有2.074%的出库单据中货品关联度低于0.3,在实验数据集中有0.479%的出库单据中货品关联度低于0.2,在实验数据集中有0.479%的出库单据中货品关联度低于0.2,在实验数据集中有0.359%的出库单据中货品关联度低于0.1,故只有少部分单据存在同一出库单据下货品关联度较低的情形。
由此可见,同一出库单据下货品关联强度通常较大。据此,如果入库时存在货品混放的情形,即同一托盘载体可以存放不同货品,操作人员可尽量将货品属性关联度较大的货品混放在同一托盘载体上,这样出库拣选时即可在同一托盘载体上找到所需货品种类,达到减少堆垛机的工作时间及频率、减少工作人员等待时间、提高仓库的拣货效率的目的。
如果允许存在混放的情形,考虑到同一托盘载体的容量有限,只能存放有限的货品,入库操作员在进行多种货品的混放时可查询货品间的属性关联强度。通过手持PDA入库操作员输入两个货品的编号,点击关联度查询,即可查询到两个货品的属性关联强度,操作简单容易上手。入库操作员根据查询结果,尽可能将关联强度较大的货品混放在同一托盘载体,这样出库操作员在拣选时可在一个托盘载体中取得更多货品,提高了拣选出库的效率以及仓库运行的整体效率。手持终端程序界面如图4所示。
图4 RF手持关联度查询操作界面
4 结语
为了提高出库拣选的效率,本文验证了同一出库单据下不同货品的属性关联度,设计了一种基于余弦相似度的货品属性关联度计算方法,实验数据表明,同一出库单据下货品的关联强度通常较大。根据这个结论,操作人员可以在允许混放入库的情形下可尽可能将货品关联度较大的货品放置在同一托盘载体,以在出库拣选时有效提高工作人员的拣选效率。
猜你喜欢
科学技术与工程(2022年26期)2022-11-01 05:40:14
中国船检(2021年11期)2021-12-04 14:02:26
中国外汇(2019年15期)2019-10-14 01:00:46
中国外汇(2019年7期)2019-07-13 05:45:00
中学数学杂志(高中版)(2016年6期)2017-03-01 18:53:58
中国外汇(2016年20期)2016-12-28 22:17:25
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:40
职业技术(2015年8期)2016-01-05 12:16:46
系统工程学报(2015年5期)2015-02-28 19:54:16
中国外汇(2015年11期)2015-02-02 01:29:38
