
基于机器视觉的俯卧撑计数算法
2021-07-20 00:05徐菲陶青川吴玲敬倩
现代计算机 2021年15期
徐菲,陶青川,吴玲,敬倩
(四川大学电子信息学院,成都610065)
0 引言
当前体能训练中普遍需要将俯卧撑计数作为考核成绩[1],俯卧撑测试的成绩测量大都采用人工计数或红外设备测量,这些测量方式均存在测试标准不一致、测试效率低、裁判员工作负荷大等问题。
基于红外设备的俯卧撑计数系统主要由红外发射器、红外接收器等设备组成[2]。原理是测试人员撑起和俯卧时阻断红外发射器和红外接收器之间的信号,接收器无法接收到信号时,判定相应俯卧撑动作并进行计数。但当红外线被非测量对象遮挡后,系统也会判定是被运动员肢体遮挡,从而出现计数错误。所以红外传感测量设备普遍存在的问题是容易被异物干扰而误报成绩。
因此,采用基于机器视觉的智能算法对俯卧撑这一类传统体能训练项目进行检测计数,具有重大意义。人体姿态检测是视频智能监控的关键应用领域之一,由于人体肢体自由度较高,当人在做不同的运动时,肢体也呈现不同的状态[3]。传统人体姿态识别框架OpenPose是基于卷积神经网络和监督学习的框架上开发的开源库,可以在多种场合下实现对人体复杂姿态的估计,在机器视觉领域有广泛的应用[4]。但由于卷积神经网络复杂度过大,导致该训练框架在运行速度、内存空间诸多方面的限制,且不利于后续计数模块衔接。
针对上述问题,本文设计了一种基于机器视觉的俯卧撑计数算法,如图1所示,该算法由两个部分组成,图像采集模块和智能计数模块,图像采集模块中由摄像机完成图像采集。智能计数模块中由改进的YOLOv3算法进行对人体的目标检测,由Ultralight-Simplepose模型预测人体关键点,最后由SVM分类器实现分类计数功能,输出计数结果。
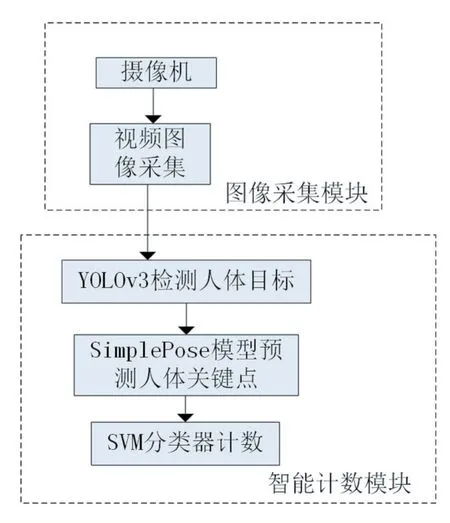
图1 算法流程图
1 俯卧撑计数算法
1.1 制作俯卧撑数据集并转换成COCO数据集格式
COCO的英文全名是Common Objects in Context,该数据集是由美国微软公司建立的一种大型的图像处理数据集,其任务信息包含目标探测、像素分割和字幕标注等。对数据集的标注信息保存在JSON格式的文件中,包括五大类注释,分别是目标检测、关键点检测、素材分割、全景分割和字幕生成。COCO API接口可以实现图像标签数据加载、解析和视频可视化功能。
因本文使用COCO API接口,将制作的俯卧撑数据集全部转换为COCO数据集格式后再进行训练和测试。脚本一开始先将数据集字典段中的info、licenses及categories进行定义,然后再遍历图像信息将其转换为对应的COCO格式,最终生成相应的JSON文件。
1.2 基于改进的YOLOv3检测人体目标
YOLOv3是针对YOLO模型的又一次改进版本,主要包括以下几个方面:
(1)YOLOV3使用多个分类标签预测来不同的目标,能适应更加多样性的场景。与传统的识别模型不同,它采用了单独的逻辑分类工具,在训练过程中使用二元交叉熵损失函数来分类目标。
(2)用于目标检测的YOLOv3边界框有3种不同的尺寸,但提取不同尺寸的特征时运用的是同一种算法。在基于COCO数据集的实验中,YOLOv3的神经网络分别为每种尺寸预测了三个边界框,得到的边界张量T的公式是:
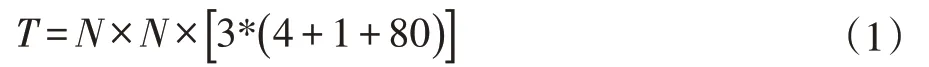
张量T中包含4个边界框角点位置、1个目标预测以及80种不同类型的目标分类预测。N×N表示检测框的参考位置信息,3是3个不同尺寸的先验框。之后将不同图层中得到的特征图进行卷积、上采样、图层连接,获得其上采样特征和细粒度特征,提高检测精度。
(3)YOLOv3在YOLOv2的基础上进行了提升,同时融合其他新型残差网络,由连续的3×3卷积层和1×1卷积层组合而成,其中还添加了几个近路连接。YOLOv3与YOLO系列以前的网络对比,权值更大,层数更多,其卷积层数共有53个,所以命名DarkNet-53,如图2所示。

图2 DarkNet-53示意图
DarkNet-53在检测精度上比传统的YOLO模型更加精确,同时计算量更加精简,耗时更短。与ResNet-101相比,DarkNet-53的效率提升了近1.5倍,ResNet-152和它功能相当,但运行时间却是其2倍[5]。
YOLOv3算法可以检测多姿多态的物体,而本文只需要检测人体。YOLOv3有三个不同尺寸的边界框,大小分别为13×13、26×26、52×52。小尺寸的特征图像更适合定位目标较大的目标,而大尺寸的特征图像更容易检测目标较小的物体。对于只检测人的任务,YOLOv3网络相对复杂,影响算法的检测效率,系统负担较大。因此,在结构上对YOLOv3网络进行了优化,改进后的网络结构如图3所示。

图3 改进后网络结构示意图
改进后网络模型在整体结构上与原YOLOv3模型类似,仍然运用了卷积层和残差块来进行特征提取,调整了开始的卷积层的尺寸和步长,减少计算量。
在检测网络部分,因为检测目标尺寸为近景人体,不存在较小目标,将特征图从原来的3个缩减为1个,只保留最小尺寸的特征图。
改进后输入尺寸为416×416,权值大小为122.3Mb,大小相对于原始YOLOv3减小了约2倍,GPU平均耗时7.2ms。改进后的GPU平均耗时,速度均有明显提升。
本文运用改进的YOLOv3进行人体目标检测,如图4所示,预测出人体的感兴趣区域(ROI),圈定该区域以便进行进一步处理。

图4 人体目标检测结果
1.3 基于Ultralight-SimplePose预测人体关键点
Ultralight-SimplePose是一种超轻量的人体关键点预测框架,主要运用的是Simple Baseline算法[6]。与传统人体姿态检测框架相比,具有速度快,精度高的优势。采用自上而下的策略,先进行目标检测(人),再对每个检测到的人进行单人的关键点检测(单人姿态估计),输入图像是1.2小节中改进后的YOLOv3检测到的人的ROI。
Ultralight-SimplePose算法中提出的Simple Baseline结构如图5所示。ResNet是图像特征提取中常用的一种主干网络,该算法在主干网ResNet最后一个卷积阶段插入了几层名为C5的反卷积。默认情况下,使用三个具有批处理规范化和由线性函数激活的反卷积层,每层有256个4×4核滤波器,步幅是2。最后加入1×1的卷积层,生成人体关键点预测图。
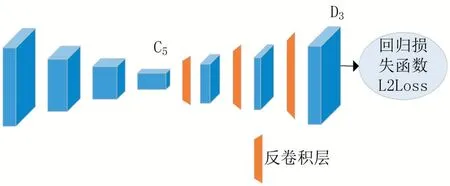
图5 baseline结构图
该算法与Hourglass[7]和CPN[8]在生成高分辨率特征图的方式上有所不同,后两者都使用上采样来提高特征映射的分辨率,并将卷积参数放入其他块中。而Simple Baseline的方法是将上采样和卷积参数以更简单的方式组合到反卷积层中,而不使用跳层连接。
该算法在姿态追踪方面具体有如下几点:
(1)光流联合传播:光流(Optical Flow)是指运动的目标在连续多帧图像上的像素移动的瞬时速度,光流矢量是图像上相应的坐标点灰度的瞬时变化率。对于前一帧中的检测到的人体各个关节点,计算光流矢量,然后确定一个边界框,作为传播到当前帧中的人体预测。当由于运动模糊或遮挡而丢失检测时,该算法可以从之前的帧中正确预测出当前帧的人体的边界框。
(2)基于光流的姿态匹配:帧间追踪某个目标时,需要计算目标前后帧的匹配度,在运动较快或者密集场景下,使用边界框IoU(Intersection over Union)作为相似性度量(SBbox)效果不好,此时框不重叠,且与实例没有对应关系;当两帧间的姿态相差较大时,使用对象关节点相似性OKS(Object Keypoint Similarity)效果也不好,无法进行有效匹配。该算法就利用了光流,先计算下一帧的加上光流偏移后的姿态,然后再计算OKS,考虑到两帧之间可能有各种原因造成的不连续情况,所以这里可以计算连续多帧的OKS。给定帧Ik中的一个实例和帧Il中的一个实例,基于流的姿势相似性度量表示为:

(3)基于光流的姿态跟踪算法:首先将(1)中说的联合传播中得到人像预测和检测模型得到的预测做非极大值抑制(NMS),然后进行单人姿态估计,之后计算如(2)中所述的两帧之间的对象关键点相似性(OKS),并进行贪婪匹配,完成姿态跟踪。
以上是关于Ultralight-SimplePose框架人体姿态预测的算法原理简述,调用Ultralight-SimplePose进行训练,得到俯卧撑状态下的人体关键点预测模型。该算法中人体关键点共有17处,分别为鼻子、左眼、右眼、左耳、右耳、左肩、右键、左肘、右肘、左腕、右腕、左臀、右臀、左膝、右膝、左踝、右踝。将以上17个点进行预测,并分别记录其二维平面点坐标。图6为实验中人体俯卧撑时关键点预测图,其中人体关键点预测精度为0.945。

图6 人体俯卧撑时关键点预测图
1.4 基于SVM分类器的俯卧撑计数
支持向量机SVM(Support Vector Machines)是一种二分类模型[9]。SVM的基本算法是对于线性可分的数据集,求解一个超平面,该超平面能够将训练数据集划分为正类和负类,并最大化其几何区间[10]。本文需要分类的数据集为提取人体关键点后计算出的角度特征数据,属于非线性可分数据集,此时要通过函数变换使坐标数据映射到更高维度的空间里,在高维度空间里再求解一个超平面进行线性分类,将分类结果映射回原本的数据集中。
这种非线性的映射在SVM里由核函数来实现,核函数的作用是简化高维空间中的映射计算量,本文采用高斯径向基核函数(Gaussian radial basis function kernel)来实现输入空间到特征空间的映射,设训练数据集T={(x1,y1),(x2,y2),…,(xN,yN)},坐标点数据xi∈Rd,d为样本空间维度,学习目标yi∈{- 1,1}为二元变量,i,j=1,2,…,N。
输入实例为Xi、Xj,核函数表达式为:
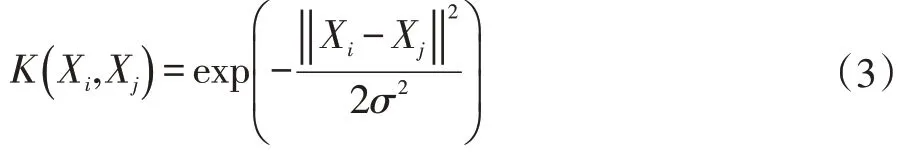
通过核函数求解凸二次规划问题,在高维度空间里分类决策函数为:

上式中b为偏置项,其中α的值,也就是求解关于对偶问题的最大值,其中C(C>0)为惩罚因子,由下面公式计算得出:

将核函数K代入(4)式中,得到基于高斯径向基核函数的SVM最优分类函数:

本文将1.3小节中所获得的人体17个关键点坐标数据集进行处理,为减少计算维度和计算量,去除与俯卧撑动作无关的脸部点位,只提取手肘夹角、肩肘夹角、臀腰夹角等特征,输入SVM分类器进行训练。分别将以下三种状态进行标注:标准俯卧撑状态下的撑起状态,俯卧状态,以及不标准俯卧撑状态。为了完成俯卧撑计数的同时实现对俯卧撑动作标准化的监督,使用二叉树法依次分类样本[11],如图7所示,SVM先将标准俯卧撑和不标准俯卧撑进行分类,以便在计数过程中筛除不标准姿态,随后分类标准俯卧撑状态下的撑起状态及俯卧状态。

图7 多分类SVM俯卧撑计数模型
训练出检测俯卧撑计数的SVM分类器后,设置计数器,若实例动作不标准,则不予计数,当图像遍历撑起、俯卧、撑起三个状态时,则计数器加一,实现俯卧撑计数功能,如图8所示。

图8 俯卧撑计数界面
2 实验与分析
本文实验环境为PyTorch 1.4.0、Python 3.6、Ubuntu 18.04.4LTS、MXNet 1.5.0;处理器为Intel Core i5-7400,CPU频率为3.0GHz;内存8GB;GPU显卡为NVIDIA GTX 1080TI,显存12GB。
本文选择hmdb51[12]、UCF50[13]人类行为数据集中俯卧撑视频,自制俯卧撑训练视频等抽帧作为训练数据集,选取其中3000张图片作为数据样本。
实验测试由视频测试,抽帧得到的图片数据传递至智能计数模块开始计数,每张图片检测耗时125ms。本实验以计数准确率作为评价标准,实验测试结果见表1。

表1 计数算法测试结果
根据实验结果所示,该算法完全正确率大于99%,可以实时地,准确地进行俯卧撑体能训练及测试计数。
3 结语
本文设计了一种基于机器视觉的俯卧撑计数算法,能准确实现体能训练及考核中俯卧撑计数,比人工计数更准确,节省人力成本;比红外感应计数更便捷、安全、不易被异物干扰。本文的算法及网络框架还可以推广到其他体能测试计数需求,如仰卧起坐、引体向上等项目,有较强的应用性。该算法在极少数的条件下的检测还是存在漏计和误计的情况,因此仍需要扩充数据集,并且对网络进一步优化。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高二数学(2022年3期)2022-04-29
建材发展导向(2022年3期)2022-04-19
计算技术与自动化(2022年1期)2022-04-15
建材发展导向(2022年2期)2022-03-08
上海师范大学学报·自然科学版(2019年5期)2019-12-13
数学大王·低年级(2019年8期)2019-08-27
广东教育·高中(2017年10期)2017-11-07
新高考·高一物理(2015年5期)2015-08-18
