
密集池化连接和短语注意力下的文本分类算法
2021-07-19 09:58黄卫春陶自强熊李艳
科学技术与工程 2021年17期
黄卫春,陶自强*,熊李艳
(1.华东交通大学软件学院,南昌 330013;2.华东交通大学信息学院,南昌 330013)
文本分类任务是自然语言处理中的基础性任务,该问题初期被视作是一些简单的匹配性问题,例如,数据集中存在不同类别的文本,只要事先搜集一些与每个类别相关的词汇,当新样本中有这个词语,就判定它是对应类别即可。但是这种做法显然忽略了句子的整体语义和语境,从而导致文本分类的准确率低等问题。同时,文本分类又是组合了语义信息、语序信息和语境信息的复合型任务,传统的机器学习方法难以对非结构化文本数据进行理解[1-2]。而文本表示方法同样对分类效果有很大影响,李舟军等[3]针对自然语言处理中词语的分布式表示进行了说明。近年来,由于深度学习算法针对非结构化数据处理的优势逐渐明显,开始成为解决文本分类问题的热门选择。
卷积神经网络(convolutional neural network, CNN)在语音识别、自然语言处理和计算机视觉等领域都有很大的应用,并且取得了很好的效果。Kim[4]首次提出将卷积神经网络应用于文本分类处理之中。陶永才等[5]构建了一种基于压缩激发块的卷积神经网络文本分类模型,可以结合文本整体与局部关联性进行语义分析。Wang等[6]提出了一个基于卷积神经网络的框架,该框架结合了两种不同的词语表示方法进行分类。Conneau等[7]提出了一种文本处理体系结构,使用小规模卷积和池化操作,并且证明该模型的性能随卷积深度而增加。Duque等[8]对卷积神经网络进行压缩,评估了时间深度可分离卷积和全局平均池对结果的影响。但是使用卷积神经网络进行文本分类未能解决卷积神经网络在深度增加时所造成的梯度弥散现象,从而导致深层卷积网络训练效果不好。
为了解决CNN模型在深度增加时,信息缺失程度越来越重,训练误差反而随深度增加而增加的情况。He等[9]提出了一种称为残差网络的架构,这种方法可以有效地防止信息的缺失,同时也可以缓解过拟合问题。同时,许多研究人员提出了将注意力机制运用于文本分类模型中,在自然语言处理中,Bahdanau等[10]首次将注意力机制在encode-decode的基础上应用到机器翻译。姚苗等[11]加入了堆叠双向LSTM和自注意力机制的方法,优化了文本表示。Yin等[12]提出通用的基于注意力的卷积神经网络,通过三种注意力机制方案,将句子之间的影响整合于CNN。但是,现有作用于文本的注意力机制只能得出句子中词语和词语之间的联系,却无法灵活地得到不同阶短语之间的联系,导致短语维度不匹配问题,从而干扰分类效果。
为了有效进行特征选择,解决梯度消失问题,降低冗余特征干扰分类结果,同时可以灵活捕捉不同层次短语之间的联系,从而获得更好的分类效果,现采用密集池化连接解决模型特征丢失以及梯度消失的问题,以及对序列信息特征提取不敏感做出优化。改进传统注意力机制,采用短语注意力模型灵活地得到不同阶短语信息,解决传统注意力机制短语维度不匹配问题,重新组合关系密切的短语信息提高分类准确率。以新闻分类数据集为例,设置三组对比实验,对模型收敛性和测试集评估指标进行分析,以证明模型的有效性。对实验部分的超参数进行优化调整,以使得模型结果达到最优值。
1 模型设计
密集池化连接和短语注意力机制(dense-pool convolutional neural networks with phrase attention,DPCNN-PAtt)模型由词嵌入层,密集池化连接层,短语注意力机制层,全连接层由4个部分组成,模型总体结构如图1所示。

图1 模型整体框架
1.1 词嵌入层
词向量Glove[13]用于词语的表示,Glove融合了全局矩阵分解和局部上下文窗口两种方法,在加快训练速度的同时,也可以控制词语权重,代价函数为
(1)

(2)
xmax=100,α=0.75时的效果最好,直接使用语料库进行训练。针对集外词(out of vocabulary, OOV)词汇,随机化相同维度TOKEN加入词典随网络训练。
1.2 密集连接池化层
密集池化连接分为残差网络和池化层两个部分,残差网络内进行多次卷积,同时可防止梯度消失,之后使用池化层保留权重大的特征值,实现特征复用。假设残差网络卷积结构式为
(3)

在残差网络之后卷积短语特征,再在层与层之间使用池化,表达式为
(4)
式(4)中:Xl∈Rn×k;Wl∈Rw×k为单个卷积核维度;w为卷积窗口大小,共有k个卷积核,每次仅在此时对卷积窗口w个词语进行卷积,池化后得到第l层的输出结果Xl,in。
网络结构如图2所示,随着密集池化连接层数的增加,其提取的短语维度ngram也不断增加,图中第一层只能表示单个词语的语义信息,而第二层通过卷积可表示相邻两个词语组合的短语信息。
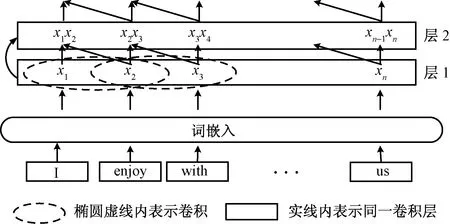
图2 密集连接池化结构图
之前的研究者在使用卷积神经网络时,一般直接使用上一层的输出作为输入。这种方式会随着卷积层数的增加而导致梯度消失,从而使参数无法有效更新。
假设层内采用常规网络,梯度更新表示为
(5)

(6)
当连乘部分为若干个(0,1)区间内的数,则梯度会趋向于0,又由于学习率的限制,梯度会变得更小,以至于后面的参数无法获得有效梯度。
在层内加入残差连接以后,可得
(7)
(8)
通过改变梯度传播方式,从连续乘积变成了累加形式,这样梯度可以稳定地从第M层传入第m层,从而缓解梯度消失的情况,密集连接池化流程如图3所示。

图3 密集连接池化流程图
1.3 多尺度短语注意力机制层
如图4所示,图4(a)中“奇妙”为正向情感词,而“枯燥”为负向情感词,因为常规注意力机制只能提取出词与词之间的关系,无法得出否定词“不”和“枯燥”的短语含义,则无法很好地理解两个词对主语的情感倾向。如图4(b)和图4(c)所示,先通过卷积获得高阶短语维度特征信息,再使用注意力机制组合短语特征,可正确理解语义信息。
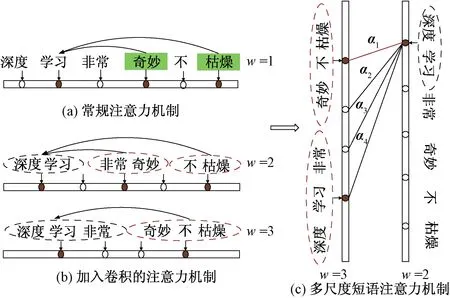
图4 注意力机制对比
如图2所示,由于每一层所提取的短语信息维度不同,由低维逐渐转向高维。通过短语注意力机制可以利用不同维度短语信息,从而表示出它们的关系。具体过程如图5所示,分为两部分,首先是短语特征重构,其次是短语特征注意力关系矩阵提取。
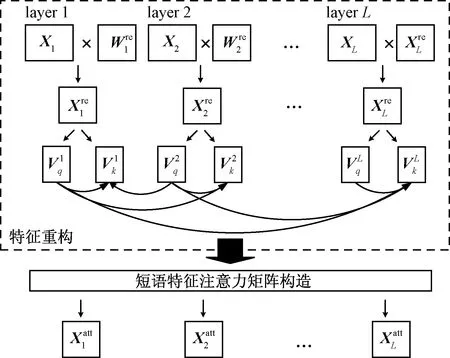
图5 短语注意力机制示意图
在短语特征重构部分,先对不同卷积层的短语特征进行降维,这有利于后续注意力机制处理,公式为
(9)

(10)
(11)

(12)
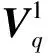

图6 短语特征注意力矩阵构造
在得到不同层之间权重矩阵以后,将每一层输出的短语特征与权重参数相乘,再累加获得组合不同阶的短语特征信息,公式为

(13)
由于将不同层之间的特征相加,为了防止维度过大,需要除标度L进行限制。通过这样的方式,可以求得不同层之间的关联,从而有指向地处理关联度高的短语特征向量。
1.4 全连接层
(14)
训练的目标是最小化损失函数,损失函数采用交叉熵(cross entropy)为损失函数,同时加入L2正则化防止过拟合,公式为
(15)
2 实验与分析
2.1 数据集
使用的实验数据集为新闻分类数据集(AG),以新闻文章作为样本,划分为4种不同的新闻类别,分别为World、Sports、Business、Sci/Tech,具体信息如表1所示。

表1 数据集信息
2.2 实验设置
实验环境配置和参数设置分别如表2、表3所示。

表2 实验环境配置
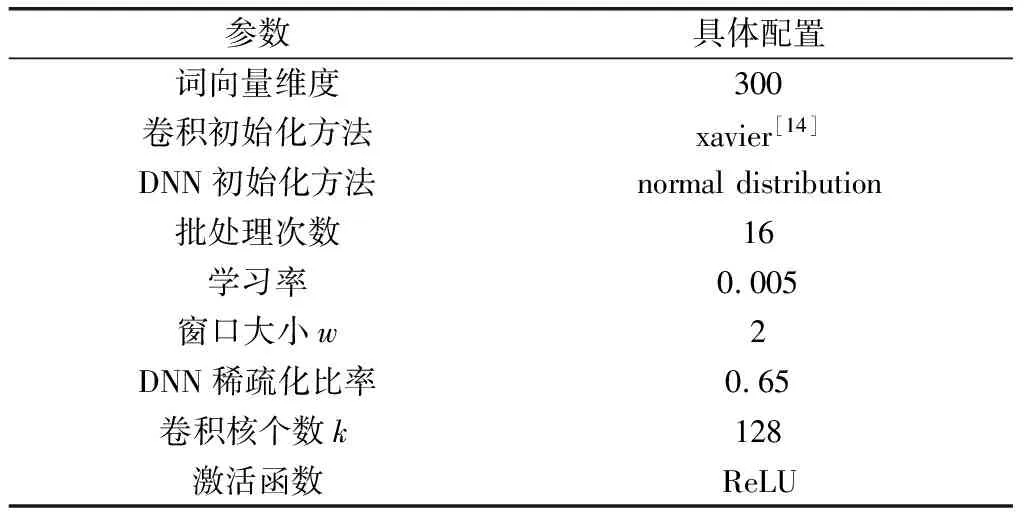
表3 参数设置
2.3 实验结果对比
分类效果评估标准采用准确率(precision,P)、召回率(recall,R)和F1值进行衡量,定义如下。
(16)
(17)
(18)
根据分类结果所建立的混淆矩阵如表4所示。

表4 混淆矩阵
2.4 实验对比及分析
为了对比在不同情况下模型的效果,设置了3组对照实验模型,实验设置与2.2节介绍一致,以新闻数据集(AG)为实验数据集进行对比。
(1)仅使用卷积神经网络CNN。
(2)使用密集池化连接(dense-pool connection convolutional neural network, DPCNN),但是不使用短语注意力机制。
(3)使用短语注意力机制(convolutional neural network with phrase attention,CNN-PAtt),但是不使用密集池化连接网络。
通过对比3种不同模型的loss下降程度以及准确率,结果如图7所示。

图7 4种模型的准确率和损失值对比试验图
通过图7(a)对比发现,在相同实验条件下,本文模型准确率均高于3种对比模型,模型准确率比CNN-PAtt模型高0.9%~1.5%,比DPCNN高0.5%~0.8%,比CNN高2.5%~3%。通过图7(b)可以发现,本文模型loss值下降较快,相对稳定,取得了很好的收敛结果,而对比模型收敛性相对较差,尤其是CNN-PAtt和CNN模型,这也是因为没有加入密集池化连接从而产生梯度消失的缘故,但是CNN模型在迭代次数变高时准确率和损失值表现均比CNN-PAtt模型更好。综上可得,本文模型可以有效缓解梯度消失,同时提高准确率,降低损失值。
通过实验具体对比了4种模型的准确率、召回率和F1值,不仅对总体性能指标进行计算,还对新闻数据集4个不同类别分别计算其分类效果,结果如表5所示。

表5 对比实验结果
由于准确率和召回率只能表达部分模型性能,通过F1值综合考量,DPCNN-PAtt模型的F1值比以上3个对比模型分别高出3.34、0.81和2.69,模型性能得到有效提升,具体如图8所示。

图8 F1值比较
2.5 超参数设置
2.5.1 网络层数对结果影响对比
结果如图9所示,可以看出网络层数选取第4层时,数据集准确率最高。也并非层数越深,分类结果越好,网络层数偏高时提取出的短语语义偏差会增加。

图9 网络层数对结果的影响
2.5.2 不同池化方式对比
比较最大池化和平均池化两种池化方式对结果的影响,密集连接层数以2、4、6、8层进行实验,结果如图10所示。对比可得,采用最大池化精度提升更大,平均池化最优准确率为0.922,而最大池化方式可以达到0.927。这也是因为最大池化可以提取出特征区域中最重要的特征,而当使用平均池化提取特征时,重要特征的权重会因为层数的增加而变小,所以其语义特征也相应弱化,从而引起分类效果变差。

图10 不同池化方式对准确率影响
2.5.3 句子长度对结果影响
由于数据集中样本长度不一致,需要将样本处理成统一长度进行处理。首先需要得出数据集中样本长短的分布情况,对新闻分类数据集(AG)进行分析,图11为数据集样本长度分布。
由图11分析可知,样本中词语数在[40,60]区间内较多。取句子长度为30开始实验,在[30,80]区间内进行实验,实验结果如图12所示,取60表现最优。
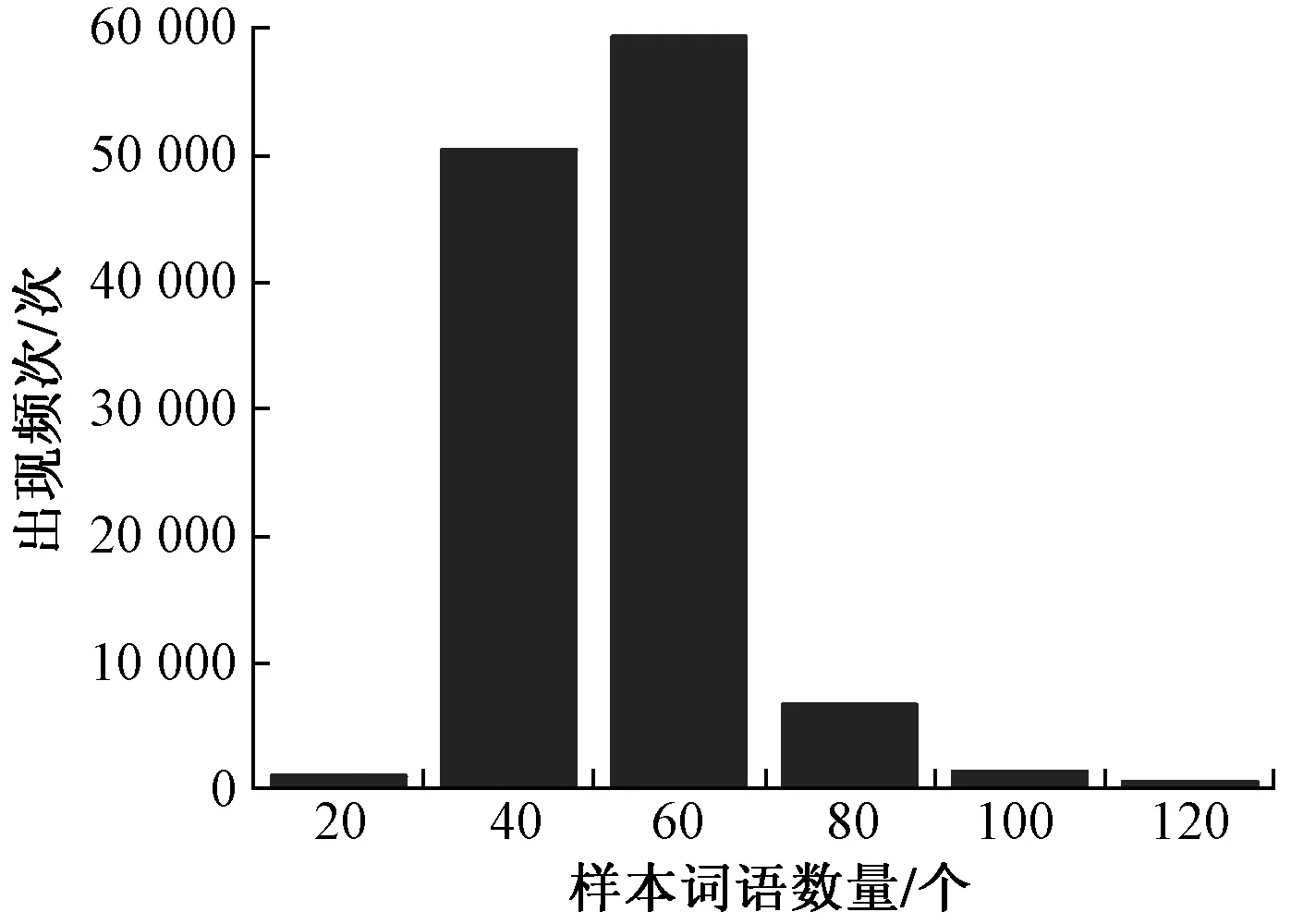
图11 AG数据集样本长度分布
3 结论
通过对比模型实验结果得出以下结论。
(1)在密集池化连接中通过残差网络防止由于层数增加而导致的梯度消失问题,并在残差网络后加入池化层复用重要特征,可以有效缓解梯度消失的问题。
(2)同时改进常规注意力机制,使用短语注意力机制可以更充分地利用不同尺度的短语特征信息,并且对其进行组合,获得不同阶短语之间的关系,并通过对比实验得出模型的有效性。
但对于深层次信息语义信息的提取,以及上下文序列信息处理,还存在一定局限性。可以尝试使用更好的词向量预处理模型,比如Bert模型,也可以加入循环神经网络进行实验,这可以作为之后的研究方向。
猜你喜欢
计算机应用(2022年9期)2022-09-25
九江学院学报(自然科学版)(2022年2期)2022-07-02
软件导刊(2022年3期)2022-03-25
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
