
一种基于柯西分布的网络拥塞控制策略*
2021-07-16 09:29雷岚栋池亚平张亮亮
北京电子科技学院学报 2021年2期
雷岚栋 池亚平 张亮亮
1.西安电子科技大学,西安市 710071
2.北京电子科技学院,北京市 100070
引言
20 世纪80 年代,美国劳伦斯伯克利实验室到加州伯克利的吞吐量从32kb/s 骤降至40b/s[1],其根本原因是发生了网络拥塞,随即人们对拥塞控制开展了一系列的研究,先后提出了多种策略机制和算法,其中以TCP Tahoe 和New Reno[2]影响最为广泛。 现如今,伴随着大数据、云计算乃至“互联网+”的时代到来,出现了具有挑战性的新网络环境,网络结构类型发生深刻调整且表现形式差异化,多元化网络数据体量上的发展也突飞猛进,例如千兆位以太网或卫星链路:高误码率、长传播时延、高链路容量和不对称信道。 传统的网络拥塞控制已经不能满足网络发展的要求,早期拥塞控制算法采用的加性增乘性减(Additive Increase Multiple Decrease,AIMD)[3]机制,其设计初衷旨在服务广域互联网。 而在现有网络体系下,将导致网络带宽利用率低、吞吐量下降, 而且通过接收反馈信息的判断拥塞再采取调整拥塞窗口大小的措施加大了网络拥塞反应时间,加剧了源端的负荷和不稳定性。
在任何网络系统中,回路响应时间(Round Trip Time,RTT)[4]是对系统拥塞程度最直观的刻画参数,其变化能客观真实的反应当前网络负载状况,也能作为评价当前网络性能好坏的标准,适合作为拥塞反馈信号。 为增强网络传递信息效率,提升网络性能,本文提出了一种基于柯西分布统计模型下的拥塞控制策略,其主要对RTT 进行采样,通过采样值建立RTT 的柯西分布统计模型,运用柯西概率分布函数,在拥塞反馈的阶段预测下一次拥塞发生的程度,改进调整拥塞窗口大小,进而达到提升网络性能的效果。
1 拥塞控制相关工作分析
1.1 拥塞控制主要方式
拥塞控制的主要方式从控制论的角度出发,大致可以分为开环控制和闭环控制两类[5],开环控制是通过优良的设计提前规避将要发生的问题,确保在网络运行中,不发生拥塞,而闭环主要是建立在反馈环路上。 闭环控制按反馈方式来细分,主要可分为显示反馈和隐式反馈,显示反馈是拥塞节点将拥塞信号反馈给源端,隐式反馈主要是通过对互联网内部某一个部门进行局部观测推断拥塞是否发生。
面向互联网这种复杂的系统,目前有学者试图通过开环控制,采用机器学习数据挖掘的方式构建通用网络模型,使用不同结构网络的海量数据训练模型,从而达到避免网络拥塞[6]等问题,但目前发展还很缓慢。 相比较开环控制,闭环控制或许是当前较好地选择,TCP/IP 拥塞控制采用基于窗口的端到端的闭环控制,主要通过确认信号ACK 控制分组的发送。
1.2 拥塞控制四个阶段
(1)慢启动:当拥塞窗口大小小于门限值时,每一个RTT 之内,窗口大小呈指数增长,即cwnd(x)=2x;
(2)拥塞避免:当拥塞窗口达到门限值时,每个RTT 窗口值大小都比前一次加1,即cwnd=cwnd+1;


1.3 拥塞控制研究进展
拥塞控制技术从策略方向上可以分为两类,拥塞避免(congestion avoidance) 和拥塞控制(congestion control)。 前者是一种拥塞预防机制,它的目的是尽量避免网络进入拥塞状态,而后者是一种网络拥塞恢复机制,它能够在网络发生拥塞后快速恢复到拥塞之前的状态,减少网络丢包,提升网络性能。
从核心方法上来细分,大致可以分为拥塞信号、检测拥塞的方法以及控制策略等三个方向,其中拥塞信号可以分为以丢包、显示拥塞控制(Explicit Congestion Notification,ECN)[7]、RTT、队列长度或排队事件概率,以及带宽延迟测量(Bandwidth Delay Product,BDP),检测拥塞主要是通过重复ACK 或者传输超时事件数量、统计被标记ECN 报文比例、RTT 的梯度变化、拥塞窗口和阈值的比较、与预设队列长度阈值比较等方式判定拥塞以及拥塞程度,控制策略主要是从拥塞窗口大小、发送速率或者标记ECN 等手段来对网络进行拥塞控制。
若从实时控制的位置分类,则可分为源端算法(Source Algorithm)和在链路设备上使用的链路算法(Link Algorithm),源端算法是指控制策略在主机端,由中间节点向端反馈信息,其中应用最为广泛的就是服务器端的拥塞控制协议;而链路控制算法是指在链路路由器或交换机等中间节点上执行的算法,比如Drop Tail“队尾丢弃”算法[8]。 广泛应用于路由算法、负载均衡协议以及交换机端的主动队列管理技术。 源端算法重在实现端对端的拥塞控制,它主要通过在网络的传输层改进传输控制协议来实现。 而链路控制算法更侧重于网络的路由选择、负载均衡等网络层的拥塞控制。 两类算法虽是不同的切入点,但目的都是一致的,即提升网络性能,增强网络鲁棒性。 从传统拥塞控制而言,更多的是通过端对端的拥塞控制协议来实现对网络的拥塞控制,虽然从初代的TCP Tahoe 发展到Cubic 等主流算法已经经历了多个版本,但其核心思想依旧不变。
目前TCP 拥塞控制算法大多都是在拥塞发生之后进行拥塞控制协议的改进,如通过丢包、ECN 标记或检测ACK 数量等判断拥塞,然后通过源端降低发送速率或减小拥塞窗口来进行拥塞调整,但这样网络资源和网络性能依然会受到冲击。 更优的方案是进行拥塞避免,通过提前对网络各参数的分析来判断网络运行情况,防止下一次传递信息时网络拥塞的出现。 在此基础之上,提出了一种基于柯西分布的拥塞控制策略,其主要通过预测的方式,将RTT 采样值迭代进入柯西分布函数,来预估下一次拥塞窗口的大小,从而避免网络发生拥塞。
2 柯西分布拥塞控制策略
2.1 具体策略
当前网络RTT 的样本值可以作为拥塞反馈信号,从而来预测下一次即将发生的网络拥塞,可以达到来主动调整拥塞窗口大小的目的。 在端到端的网络模型的基础上,对基于Gamma 分布的统一的RTT 分布模型进行了研究,发现在网络负载较轻时RTT 服从指数分布,在网络负载较重时RTT 服从正态分布。 并且其通过仿真验证在无线网络负载较重时的RTT 也服从正态分布。 在一定的参数条件下,Gamma 分布可以转换为指数分布或正态分布[9]。 但此模型存在一定的误差问题,即在正态分布统计模型中的统计参数均值和方差,多次代入了原本并不精确的RTT 采样值,从而计算得到的统计模型的各参数亦不精确,导致预测下一次拥塞的误差较大。
在此基础之上,通过对多种统计模型的研究和探索,提出了一种基于柯西分布的网络拥塞控制策略,柯西分布是正态分布的“兄弟模型”,但柯西分布不需要计算采样值的均值和方差,而只需RTT 采样值的中位数或众数,和最大RTT 值一半处的尺度参数来刻画,通过运用柯西概率分布函数,在拥塞反馈的阶段来改进调整拥塞窗口值,达到改进拥塞控制效果的目的。 具体流程如图1 所示。

图1 具体流程图
具体流程说明:网络在慢启动阶段,拥塞窗口大小随指数函数逐渐增大。 当拥塞窗口达到慢启动门限阈值时,TCP 进入拥塞避免阶段,对RTT 进行采样,通过RTT 样本值计算出网络拥塞因子,进而计算出柯西分布函数,并将当前RTT 的采样值代入柯西分布函数,预测下一次网络拥塞窗口的变化,从而相应对拥塞窗口的大小做出调整,如果当前RTT 的采样值大于RTO,即表示网络拥塞已经非常严重,网络需要重新进入慢启动阶段,重新传输,拥塞窗口的值将重新设定为初始值1,慢启动门限阈值减小为拥塞窗口大小的一半。 重复以上步骤,即可实时动态更新源端的发送窗口。
2.2 柯西分布统计模型
柯西分布也叫作柯西-洛伦兹分布,它是以奥古斯丁-路易-柯西与亨德里克-洛伦兹名字命名的连续概率分布,如图2 所示。

图2 标准柯西分布概率密度函数图
其概率密度函数为:

在2.1 式中:x0为定义分布峰值位置的位置参数;γ 为最大值一半处一半宽度的尺度参数。
柯西分布模型被称为正态分布的“兄弟模型”,而柯西分布仅仅只需要采集RTT 中的中位数或者众数,和最大RRT 值一半处的尺度参数,即:

特殊地,当x0=0 且γ=1 时,称为标准柯西分布,其概率分布函数为:

柯西分布的平均值、方差、或者矩都没有定义,它的众数与中值有定义都等于x0,若取表示柯西分布随机变量,柯西分布的特性函数表示为:

如果记随机变量X 的期望值为:

方差为:

则可以得到随机分布X的kurtosis,即峰态系数(尾态):

根据kurtosis 值大小,可以将概率分布分为以下三种情况:
(1)如果κ=3,称为mesokurtic。 这种情况最典型的例子是正态分布。
(2)如果κ> 3,称为leptokurtic。 其相比于正态分布,该分布有更厚重的尾部。 柯西分布即是典型的代表。
(3)如果κ< 3,称为platykurtic。 相比于正态分布,其具有更轻的尾部。
柯西分布和正态分布的最显著的差异在于,柯西分布具有更加厚重的尾部(Fat tail),这种情况下说明柯西分布下统计的RTT 采样值出现极值的可能性更大,而网络发生拥塞时,RTT 恰易出现极值。 因此,从数学的角度,柯西分布比正态分布更加契合网络拥塞的环境。
3 策略具体分析
3.1 算法分析
设RTT=x,x∈(0,∞), 具体实现的过程如下:
1、对RTT 进行采样,分别计算出x0和γ的值。
2、由x0和γ计算出柯西分布密度函数:f(x;x0,γ),其表达式为:

3、 根据x0、γ和f(x;x0,γ) 积分可以求得柯西分布函数:

4、 根据信息论,可推导出拥塞窗口的预测公式:

通过上一次拥塞窗口值来预估下一次拥塞窗口值。
以上式中的x0和γ为该模型的拥塞因子,全都由RTT 采样值计算得到,用来反映当前网络的拥塞状况。
3.2 性能分析
算法性能分析过程:
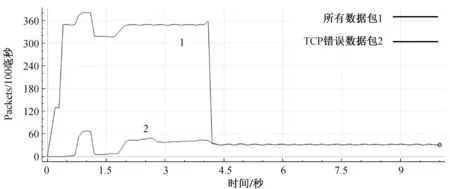
1、 在慢启动阶段:cwnd 2、 在拥塞避免阶段,cwnd>=ssthresh 时,可采用柯西分布概率预测,包括三个步骤: (1)当x=x0时, 表示当前的RTT 值与本次窗口的样本中位数值完全相同,预估拥塞程度将不会改变,无需对拥塞窗口进行调整。 (2)当x 表示当前的RTT 值比本次窗口的中位数值有所减小,预测拥塞程度已经得到缓解,可适当增大拥塞窗口的值。 窗口增大后的值可为: (3)当x>x0时, 表示当前的RTT 值比本次窗口的中位数值有所增大,预测拥塞程度可能加剧,可适当减小拥塞窗口的值。 窗口减小后的值可为: 拥塞窗口经过反复迭代,通过预测的方式来指导下一次拥塞窗口的调整,从而达到对网络进行拥塞控制的目的。 3、超时重传: 若RTT>RTO,则表示网络严重拥堵,源端再次进入慢启动,并下调网络拥塞窗口的门限值: 此时网络重新进入慢启动阶段,当达到刷新后的慢启动门限阈值时,再次进入拥塞避免阶段,拥塞窗口继续根据柯西分布函数迭代出下一次拥塞窗口预估值,直到网络停止服务或链接超时断开。 本节通过仿真验证算法的有效性,评价了算法的性能。 已有基于正态分布的拥塞控制策略采用基于NS-3 的TCP/IP 协议的拥塞发生机制进行仿真[10],仿真具有较高的可信度。 使用NS-3 作为仿真环境[11]搭建相同的仿真拓扑,图3是仿真网络拓扑结构,仿真拓扑具有代表性。 其中Source1~Source3、Sink1~Sink3 分别为发送端和接受端,其中用户与服务器之间的接入带宽为6Mbit/s,延时为4ms;服务器与服务器之间的瓶颈链路带宽为1.5Mbit/s,延时为60ms,其门限阈值取系统推荐值64KB,瓶颈链路R1 到R2 之间为单向传输且采用FIFO 的队列管理算法。 其中仿真主要包括几个模块:网络模块(节点、链路设备、Internet、数据传输)、传输模块(TCP)、拥塞控制模块(TCP New Reno、拥塞控制器)、错误模型模块、基于预测统计模型的拥塞控制模块[12,13]。 图3 仿真网络拓扑示意图 设计采用错误模型模块创建错误数据包,按照错误概率随机发送,来模拟网络拥塞。 用拥塞控制模块创建拥塞控。 TCP 的传输模块上安装应用程序持续产生流量直到应用程序停止或者已完成发送设定的数据包的数量。 该应用的一个特点是尽最大可能的发送多的数据并试图达到最大带宽。 通过tracing 用回调函数追踪一段时间内的cwnd、ssh、rtt、rto 等相关采样参数。 基于柯西分布的拥塞控制模块读取rtt 和cwnd 的数据,根据rtt 计算柯西分布,获得预估cwnd 值,从而控制链路吞吐速率[14]。 将数据进行比较,然后在网路发生拥堵时执行迭代函数改变下一个cwnd 值,并返回相应的cwnd 值和时间,清空已读列表,然后继续下次迭代,直到网络的RTT 达到超时RTO,对其重新进行赋值。 图4是基于柯西分布的拥塞控制算法的伪代码。 仿真采用对比的拥塞控制算法为TCP New Reno,通过错误模型模块随机产生丢包、误码、误比特造成拥塞信号,使拥塞控制模块进行拥控制,通过对比基于柯西分布拥塞控制算法模块和TCP New Reno 在相同仿真环境下的拥塞控制效果,在仿真稳定的情况下反复多次实验确认实验结果,与D-TCP 拥塞控制算法的仿真类似[15],分别对比在通信环境良好(拥塞不严重)的情况下(图5)和通信环境较差(拥塞严重、网络波动大)的情况下(图9)二者对于拥塞控制的效果(图6)以及各自的吞吐量图像。 图4 基于柯西分布的拥塞控制算法伪代码 图5 通信良好的情况下TCP New Reno 输出 实验结果分为以下两组对比,分别是在通信条件较好的情况下,TCP New Reno 和基于柯西分布的拥塞控制算法数据包输出情况、网络稳定时间和吞吐率的对比。 其次是TCP New Reno在优劣通信条件下自身的对比。 分析验证结果,由图5 中可以得到,在网络运行状况较好的情况下,链路的最大输出为1500packets/s,稳定带宽大约为1000packets/s。图6 是基于柯西分布的拥塞控制算法的输出,其最大输出是3650packets/s,当达到稳定时约为3000packets/s,且稳定时间较长。 图6 基于柯西分布的拥塞控制算法的输出 图7 通信良好的情况下TCP New Reno 吞吐量 图8 基于柯西分布的拥塞控制算法的吞吐量 图7 中,其最大吞吐率为2.15Mbit/s,稳定时的吞吐率为1.75Mbits/s。 而图8 基于柯西分布的拥塞控制算法的最大吞吐率能7.65Mbits/s,而且在2s 之后,依然会达到4.5Mbits/s,保持一个较好的吞吐率。 图9 是当TCP New Reno 算法在网络环境较差的条件下,网络的输出极不稳定,其最大峰值只能达到1300packets/s,且衰减迅速,且丢包率高,吞吐率最高只能达到2.3Mbits/s,且衰减极快。 图9 通信较差的情况下TCP New Reno 输出 图10 通信较差的情况下TCP New Reno 吞吐量 对比分析可以得出,发送相同大小的数据的前提下,基于柯西分布的拥塞控制算法所需的时间更短,吞吐量更大,稳定性更好,具有更优越的性能。 本文针对网络拥塞这一问题,在传统AIMD算法的基础之上,提出了一种基于柯西分布的拥塞控制策略,它采用柯西分布统计模型,将RTT的采样值的中位数或者众数代入柯西分布函数之中,通过计算函数值来预测下一次拥塞程度,并在此基础之上对窗口大小做出修正,从而保证网络具有较强的稳定性,而且能实现发送速率的自动更新。 文末,通过在NS3 上面搭建网络仿真平台和网络拓扑,将传统的TCP New Reno 和基于柯西分布的拥塞策略做对比,可以发现后者能够有效增大网络地吞吐量,而且网络中的丢包率相比前者也有所下降,拥塞窗口的稳定性较前者有所增强。 但在通信环境较差的网络中,此策略便未能发挥出有效的作用。 此外,统计模型还有很多,基于预测的方式来解决拥塞的问题还可以得到继续发展、延续,甚至可以结合深度学习,将网络各参数训练得到更好的统计模型,来预测和指导下一次拥塞窗口的调整。






4 仿真与验证







5 总结
猜你喜欢
语数外学习·高中版中旬(2020年2期)2020-09-10科技资讯(2020年14期)2020-06-27中国测试(2018年9期)2018-05-14高中生学习·高三版(2017年6期)2017-06-12中学生数理化·高二版(2016年5期)2016-05-14科技视界(2016年2期)2016-03-30电子产品世界(2016年3期)2016-03-29理科考试研究·高中(2014年11期)2014-11-26数学教学通讯·初中版(2014年2期)2014-03-21中学生数理化·高考版(2008年2期)2008-11-01
